Archive
Workshop on data analysis for software developers
I’m teaching a workshop on data analysis for software engineers on 22 June. The workshop is organized by the British Computer Society’s SPA specialist group, and can be attended remotely.
Why is there a small registration charge (between £2 and £15)? Typically, 30% to 50% of those registered for a free event actually turn up. It is very frustrating when all the places are taken, people are turned away, and then only half those registered turn up. We decided to charge a minimal amount to deter the uncommitted, and include lunch. Why the variable pricing? The BCS have a rule that members have to get a discount, and HMRC does not allow paid+free options (I suspect this has more to do with the software the BCS are using).
It’s a hands-on workshop that aims to get people up and running with practical data analysis. As always, my data analysis hammer of choice is regression analysis.
A few things are being updated since I last gave this workshop?
While my completed book Evidence-based Software Engineering was not available when the last workshop was given, the second half containing the introductory statistics material was available for download. There has not been any major changes to the statistical material in this second half.
The one new statistical observation I plan to highlight is that in software engineering, there is a lot of data that does not have a normal distribution. Many data analysis are aimed at the social sciences (the biggest market), and they frequently just assume that all the data is normally distributed; software engineering data is different.
For a very long time I have known that most developers/managers do not collect and analyse measurements of their development processes. However, I had underestimated ‘most’, which I now think is at least 99%.
Given the motivation, developers/managers would measure and analyse processes. I plan to update the material to have a motivational theme, along with illustrating the statistical points being made. The purpose of the motivational examples is to give attendees something to take back and show their managers/coworkers: Look, we can find out where all our money/time is being wasted. I assume that attendees are already interested in analysing software engineering data (why else would they be spending a Saturday at the workshop).
I have come up with a great way of showing how many of software engineering’s cited ‘facts’ are simply folklore derived from repeating opinions from papers published long ago (or derived from pitifully small amounts of data). The workshop is hands-on, with attendees individually working through examples. The plan is for examples to be based on the data behind some of these ‘facts’, e.g., Halstead & McCabe metrics, and COCOMO.
Tips, and suggestions for topics to discuss welcome.
LLMs and doing software engineering research
This week I attended the 65th COW workshop, the theme was Automated Program Repair and Genetic Improvement.
I first learned about using genetic programming to automatically fix reported faults at the 1st COW workshop in 2009. Claire Le Goues, a PhD student at that workshop, now a professor, returned to talk about the latest program repair work of her research group.
COW speakers are usually very upbeat, but uncertainty about the future was the general feeling I got from speakers at this workshop. The cause of this uncertainty was the topic of some talks and conversations: LLMs. Adding an LLM into the program repair process can produce a dramatic performance improvement.
Isn’t a dramatic performance improvement and a new technique great news for everyone? The performance improvement increases the likelihood of industrial adoption, and a new technique creates many opportunities for new research.
Despite claiming otherwise, most academics have zero interest in industrial adoption of their work, and some actively disdain practical uses of their work.
Major new techniques are great for PhD students; they provide an opportunity to kick-start a career by being in at the start of a new research area.
A major new technique can obsolete an established researcher’s expensively acquired area of expertise (expensive in personal time and effort). The expertise that enables a researcher to make state-of-the-art contributions to an active research area is a valuable asset; it can be used to attract funding, students and peer esteem. When a new technique dramatically improves the state-of-the-art, there is a sharp drop in the value of what is now yesterday’s know-how.
A major new technique removes some existing barriers to entering a field, and creates its own new ones. The result is that new people start working in a field, and some existing experts stop working in it.
At the workshop, I saw this process starting in automated program repair, and I imagine it’s also starting in many other research fields. It will probably take 3–5 years for the dust to start to settle; existing funded projects have to complete, and academia does not move that quickly.
A recent review of the use of LLMs in software engineering research found 229 papers; the table below shows the number of papers per year:
Papers Year
7 2020
11 2021
51 2022
160 2023 to end July |
Assuming, say, 10K software engineering papers per year, then LLM related papers should be around 3% this year, likely in double figures next year, and possibly over 50% the year after.
Is research in software engineering en route to becoming another subfield of prompt engineering research?
A zero-knowledge proofs workshop
I was at the Zero-Knowledge proofs workshop run by BinaryDistict on Monday and Tuesday. The workshop runs all week, but is mostly hacking for the remaining days (hacking would be interesting if I had a problem to code, more about this at the end).
Zero-knowledge proofs allow person A to convince person B, that A knows the value of x, without revealing the value of x. There are two kinds of zero-knowledge proofs: an interacting proof system involves a sequence of messages being exchanged between the two parties, and in non-interactive systems (the primary focus of the workshop), there is no interaction.
The example usually given, of a zero-knowledge proof, involves Peggy and Victor. Peggy wants to convince Victor that she knows how to unlock the door dividing a looping path through a tunnel in a cave.
The ‘proof’ involves Peggy walking, unseen by Victor, down path A or B (see diagram below; image from Wikipedia). Once Peggy is out of view, Victor randomly shouts out A or B; Peggy then has to walk out of the tunnel using the path Victor shouted; there is a 50% chance that Peggy happened to choose the path selected by Victor. The proof is iterative; at the end of each iteration, Victor’s uncertainty of Peggy’s claim of being able to open the door is reduced by 50%. Victor has to iterate until he is sufficiently satisfied that Peggy knows how to open the door.
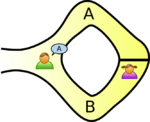
As the name suggests, non-interactive proofs do not involve any message passing; in the common reference string model, a string of symbols, generated by person making the claim of knowledge, is encoded in such a way that it can be used by third-parties to verify the claim of knowledge. At the workshop we got an overview of zk-SNARKs (zero-knowledge succinct non-interactive argument of knowledge).
The ‘succinct’ component of zk-SNARK is what has made this approach practical. When non-interactive proofs were first proposed, the arguments of knowledge contained around one-terabyte of data; these days common reference strings are around a kilobyte.
The fact that zero-knowledge ‘proof’s are possible is very interesting, but do they have practical uses?
The hackathon aspect of the workshop was designed to address the practical use issue. The existing zero-knowledge proofs tend to involve the use of prime numbers, or the factors of very large numbers (as might be expected of a proof system that is heavily based on cryptographic techniques). Making use of zero-knowledge proofs requires mapping the problem to a form that has a known solution; this is very hard. Existing applications involve cryptography and block-chains (Zcash is a cryptocurrency that has an option that provides privacy via zero-knowledge proofs), both heavy users of number theory.
The workshop introduced us to two languages, which could be used for writing zero-knowledge applications; ZoKrates and snarky. The weekend before the workshop, I tried to install both languages: ZoKrates installed quickly and painlessly, while I could not get snarky installed (I was told that the first two hours of the snarky workshop were spent getting installs to work); I also noticed that ZoKrates had greater presence than snarky on the web, in the form of pages discussing the language. It seemed to me that ZoKrates was the market leader. The workshop presenters included people involved with both languages; Jacob Eberhardt (one of the people behind ZoKrates) gave a great presentation, and had good slides. Team ZoKrates is clearly the one to watch.
As an experienced hack attendee, I was ready with an interesting problem to solve. After I explained the problem to those opting to use ZoKrates, somebody suggested that oblivious transfer could be used to solve my problem (and indeed, 1-out-of-n oblivious transfer does offer the required functionality).
My problem was: Let’s say I have three software products, the customer has a copy of all three products, and is willing to pay the license fee to use one of these products. However, the customer does not want me to know which of the three products they are using. How can I send them a product specific license key, without knowing which product they are going to use? Oblivious transfer involves a sequence of message exchanges (each exchange involves three messages, one for each product) with the final exchange requiring that I send three messages, each containing a separate product key (one for each product); the customer can only successfully decode the product-specific message they had selected earlier in the process (decoding the other two messages produces random characters, i.e., no product key).
Like most hackathons, problem ideas were somewhat contrived (a few people wanted to delve further into the technical details). I could not find an interesting team to join, and left them to it for the rest of the week.
There were 50-60 people on the first day, and 30-40 on the second. Many of the people I spoke to were recent graduates, and half of the speakers were doing or had just completed PhDs; the field is completely new. If zero-knowledge proofs take off, decisions made over the next year or two by the people at this workshop will impact the path the field follows. Otherwise, nothing happens, and a bunch of people will have interesting memories about stuff they dabbled in, when young.
Is it worth attending an academic conference or workshop?
If you work in industry, is it worth attending an academic conference or workshop?
The following observations are based on my attending around 50 software engineering and compiler related conferences/workshops, plus discussion with a few other people from industry who have attended such events.
Short answer: No.
Slightly longer answer: Perhaps, if you are looking to hire somebody knowledgeable in a particular domain.
Much longer answer: Academics go to conferences to network. They are looking for future collaborators, funding, jobs, and general gossip. What is the point of talking to somebody from industry? Academics will make small talk and be generally friendly, but they don’t know how to interact, at the professional level, with people from industry.
Why are academics generally hopeless at interacting, at the professional level, with people from industry?
Part of the problem is lack of practice, many academic researchers live in a world that rarely intersects with people from industry.
Impostor syndrome is another. I have noticed that academics often think that people in industry have a much better understanding of the realities of their field. Those who have had more contact with people from industry might have noticed that impostor syndrome is not limited to academia.
Talking of impostor syndrome, and feeling of being a fraud, academics don’t seem to know how to handle direct criticism. Again I think it is a matter of practice. Industry does not operate according to: I won’t laugh at your idea, if you don’t laugh at mine, which means people within industry are practiced at ‘robust’ discussion (this does not mean they like it, and being good at handling such discussions smooths the path into management).
At the other end of the impostor spectrum, some academics really do regard people working in industry as simpletons. I regularly have academics express surprise that somebody in industry, i.e., me, knows about this-that-or-the-other. My standard reply is to say that its because I paid more for my degree and did not have the usual labotomy before graduating. Not a reply guaranteed to improve industry/academic relations, but I enjoy the look on their faces (and I don’t expect they express that opinion again to anyone else from industry).
The other reason why I don’t recommend attending academic conferences/workshops, is that lots of background knowledge is needed to understand what is being said. There is no point attending ‘cold’, you will not understand what is being presented (academic presentations tend to be much better organized than those given by people in industry, so don’t blame the speaker). Lots of reading is required. The point of attending is to talk to people, which means knowing something about the current state of research in their area of interest. Attending simply to learn something about a new topic is a very poor use of time (unless the purpose is to burnish your c.v.).
Why do I continue to attend conferences/workshops?
If a conference/workshop looks like it will be attended by people who I will find interesting, and it’s not too much hassle to attend, then I’m willing to go in search of gold nuggets. One gold nugget per day is a good return on investment.
Happy 10th birthday to CREST
Most university departments run regularly seminars and in July 2001 I attended a half day workshop run by Mark Harman at Brunel University. Over the years the workshop has changed names, locations and grown into a two day event with a worldwide reputation.
When Mark became professor of software engineering at University College London, the workshops became known as the CREST Open Workshops and next month the 47th workshop will celebrate 10 years of the CREST centre. Workshops vary from being mostly theory oriented to mostly practice oriented; the contents is always leading edge stuff. For many years the talks have been filmed and the back catalog contains plenty of interesting material.
If you are interested in the latest software engineering related issues, at a rather technical level, then keep an eye out for upcoming CREST workshops. The theory/practice orientation of a workshop is usually easy to guess from the style of papers written by the speakers. There are other software engineering groups dotted around the world; I have no experience of their seminars/workshops, but I’m sure they will make you feel welcome.
So, here’s to another 10 years of interesting workshops.
Some CREST related blog posts:
Human vs automatically generated source code: an arms race?
Machine learning in SE research is a bigger train wreck than I imagined
Hardware variability may be greater than algorithmic improvement
Workshop on App Store Analysis
p-values for programmers
Data analysis always contains a degree of uncertainty, in statistics this uncertainty is often expressed through the concept of p-value and possible interpretations of the data tested using the ideas behind null hypothesis testing. What is the best way of explaining the concept of p-value and null hypothesis testing to software developers?
For the empirical software engineering workshops I have been running, p-values get both a broad brush description and a use case in the form of null hypothesis testing (expressed as code). The broad brush approach to p-values worked and the null hypothesis as-code approach flopped miserably.
The broad brush approach defines p-values as a measure of uncertainty and leaves it at that, no mention of what exactly is uncertain. I quickly move on to discuss the more important point, from the real-world point of view, of selecting a p-value. Choice of p-value is one side of a cost/benefit business decision; would you sit in a lecture theater that had a 1 in 20 chance of collapsing? It all depends on what benefits accrued from sitting there.
Developers understand code and expressing the operations around the use of null hypothesis testing, as code, will obviously make everything clear. Perhaps my attempt to fit everything on one slide concentrated things a bit too much, or perhaps being firehosed with stuff to learn had left people yearning for the lunch that was fast approaching. The following function, accompanied by me babbling away was met with many blank stares.
The following function is my stab at explaining the operation of the null hypothesis and the role played by p-values. I hope that things are a bit clearer for readers who have not had me teaching them R in 15 minutes, followed by having a general what you need to know about probability and statistics in 30 slides.
void null_hypothesis_test(void *result_data, float p_value) { // H set by reality, its value is only accessible by running the appropriate experiments if ((probability_of_seeing_data_when_H_true(result_data) < p_value) || !H) printf("Willing to assume that H is false\n"); else printf("H might be true\n"); } null_hypothesis_test(run_experiment(), 0.05); |
Workshop on survival and time series analysis in empirical SE
In January the material in my book on Empirical software engineering using R had its first exposure to professional software developers at a one day workshop (there was a rerun last week; slides here). The sessions were both fully booked, but as often happens on half turned up, around 15 at each workshop. A couple of people turned up expecting to be taught R and found themselves in a software engineering workshop that assumed the attendees could learn R in 10 minutes (because professional developers are experienced enough to learn the basics of programming in any language in that amount of time).
The main feedback was that people wanted to see more code, something to give them a starting point for the hands-on sessions (I hate seeing reams and reams of code on slides and had gone too far in the minimalist direction).
The approach of minimizing what developers have to learn/remember, even if it means using more computer resources (e.g., always using glm), went down very well.
The probability & statistics material, in the session before lunch, had a mixed reception; this is partly because I have not come up with a clear message and I’m trying to get over several disparate ideas, i.e., sampling issues, life is complicated and p-values. People were a bit unhappy about the life is complicated, data is messy and you have to think about what you are doing message.
I think the regression model building material was a hit. People saw the potential in fitting curves to data and found it easy to do once the parameters to plot, lines, glm and predict were sorted out. There was lots of interesting discussion around interpreting the fitted models, with me continually hamming on the point that p-value selection was a business risk factor decision and what constituted a good model depended on what it was going to be used for.
Those attending wanted to learn more, which is great since the main aim was to show people what useful things could be done to motivate them to go off and learn more (relatively little may be known about empirical software engineering, but there is more than can be fitted into a one day workshop)
There is a part-2 workshop in March and the plan is to cover survival analysis, time series analysis and if there is time something else. It will be assumed that people have the skill level of those who attended the first workshop, e.g., can write basic R and fit a simple regression model.
Thanks to The Rise for sponsoring the venue for all three workshops.
Machine learning in SE research is a bigger train wreck than I imagined
I am at the CREST Workshop on Predictive Modelling for Software Engineering this week.
Magne Jørgensen, who virtually single handed continues to move software cost estimation research forward, kicked-off proceedings. Unfortunately he is not a natural speaker and I think most people did not follow the points he was trying to get over; don’t panic, read his papers.
In the afternoon I learned that use of machine learning in software engineering research is a bigger train wreck that I had realised.
Machine learning is great for situations where you have data from an application domain that you don’t know anything about. Lets say you want to do fault prediction but don’t have any practical experience of software engineering (because you are an academic who does not write much code), what do you do? Well you could take some source code measurements (usually on a per-file basis, which is a joke given that many of the metrics often used only have meaning on a per-function basis, e.g., Halstead and cyclomatic complexity) and information on the number of faults reported in each of these files and throw it all into a machine learner to figure the patterns and build a predictor (e.g., to predict which files are most likely to contain faults).
There are various ways of measuring the accuracy of the predictions made by a model and there is a growing industry of researchers devoted to publishing papers showing that their model does a better job at prediction than anything else that has been published (yes, they really do argue over a percent or two; use of confidence bounds is too technical for them and would kill their goose).
I long ago learned to ignore papers on machine learning in software engineering. Yes, sooner or later somebody will do something interesting and I will miss it, but will have retained my sanity.
Today I learned that many researchers have been using machine learning “out of the box”, that is using whatever default settings the code uses by default. How did I learn this? Well, one of the speakers talked about using R’s carat package to tune the options available in many machine learners to build models with improved predictive performance. Some slides showed that the performance of carat tuned models were often substantially better than the non-carat tuned model and many people in the room were aghast; “If true, this means that all existing papers [based on machine learning] are dead” (because somebody will now come along and build a better model using carat; cannot recall whether “dead” or some other term was used, but you get the idea), “I use the defaults because of concerns about breaking the code by using inappropriate options” (obviously somebody untroubled by knowledge of how machine learning works).
I think that use of machine learning, for the purpose of prediction (using it to build models to improve understanding is ok), in software engineering research should be banned. Of course there are too many clueless researchers who need the crutch of machine learning to generate results that can be included in papers that stand some chance of being published.
Workshop on analyzing software engineering data
I am teaching a workshop, analyzing software engineering data, on 16 January 2016. If you meet the assumed level of know-how (basic understanding of maths to GCSE level, fluent in at least one programming language {i.e., written 10k+ lines of code} and will turn up with a laptop that has R installed), then you are welcome to sign up, its free. The event is being organized by ACCU London.
The focus is on extracting information that is useful to practicing software developers for creating software systems; statistics is used as a tool to find patterns in the data (R is used for this and the programs have the form: read_data(); format_data(); appropriate_statistical_function(); plot_results() and are usually contained in 10-30 lines).
The maths/programming requirements are there because the focus is on the software engineering ideas implied by the data; people need to implicitly understand how an equation fits together (not because there will be lots of algebra, there isn’t) and to be able to pick up and use a new language quickly.
The material is based on a book I am working on.
Its a hands-on workshop, with me talking for an hour or so and then everybody analyzing data for an hour, repeating until end-of-day. I have plenty of data for you to work on, but if you do have some software engineering data that you are willing to share with everybody, please bring it along.
The workshop is something of an experiment; as far as I know there are no books or courses aimed at software developers interested in analyzing software engineering data (there are a few books containing an assortment of academic papers). If the material is too easy I can speed up, if it is too hard then I will slow down; if the material is of no practical use we can all leave early.
The plan is to start at the beginning and cover all the important topics in software engineering. Obviously this requires more than a one day workshop. If there is enough interest there will be more workshops covering different topics (assuming I have time to organize the material and an available venue permitting).
Predictive Modeling: 15th COW workshop
I was at a very interesting workshop on Predictive Modelling and Search Based Software Engineering on Monday/Tuesday this week, and I am going to say something about the talks that interested me. The talks were recorded, and the videos will appear on the website in a few weeks. The CREST Open Workshop (COW) runs roughly once a month and the group leader, Mark Harman, is always on the lookout for speakers, do let him know if you are in the area.
- Tim Menzies talked about how models built from one data set did well on that dataset but often not nearly as well on another (i.e., local vs global applicability of models). Academics papers usually fail to point out that any results might not be applicable outside the limited domain examined, in fact they often give the impression of being generally applicable.
Me: Industry likes global solutions because it makes life simpler and because local data is often not available. It is a serious problem if, for existing methods, data on one part of a companies’ software development activity is of limited use in predicting something about a different development activity in the same company and completely useless at predicting things at a different company.
- Yuriy Brun talked about something that is so obviously a good idea, it is hard to believe that it had not been done years ago. The idea is to have your development environment be aware of what changes other software developers have made to their local copies of source files you also have checked out from version control. You are warned as soon your local copy conflicts with somebody else’s local copy, i.e., a conflict would occur if you both check in your local copy to the central repository. This warning has the potential to save lots of time by having developers talk to each about resolving the conflict before doing any more work that depends on the conflicting change.
Crystal is a plug-in for Eclipse that implements this functionality, and Visual Studio support is expected in a couple of releases time.
I have previously written about how multi-core processors will change software development tools, and I think this idea falls into that category.
- Martin Shepperd presented a very worrying finding. An analysis of the results published in 18 papers dealing with fault prediction found that the best predictor (over 60%) of agreement between results in different papers was co-authorship. That is, when somebody co-authored a paper with another person, any other papers they published were more likely to agree with other results published by that person than with results published by somebody they had not co-authored a paper with. This suggests that each separate group of authors is doing something different that significantly affects their results; this might be differences in software packages being used, differences in configuration options or tuning parameters, so something else.
It might be expected that agreement between results would depend on the techniques used, but Shepperd et al’s analysis found this kind of dependency to be very small.
An effect is occurring that is not documented in the published papers; this is not how things are supposed to be. There was lots of interest in obtaining the raw data to replicate the analysis.
- Camilo Fitzgerald talked about predicting various kinds of feature request ‘failures’ and presented initial results based on data mined from various open source projects; possible ‘failures’ included a new feature being added and later removed and significant delay (e.g., 1 year) in implementing a requested feature. I have previously written about empirical software engineering only being a few years old and this research is a great example of how whole new areas of research are being opened up by the availability of huge amounts of data on open source projects.
One hint for PhD students: It is no good doing very interesting work if you don’t keep your web page up to date, so people can find out more about it
I talked to people who found other presentations very interesting. They might have failed to catch my eye because my interest or knowledge of the subject is low or I did not understand their presentation (a few gave no background or rationale and almost instantly lost me); sometimes the talks during coffee were much more informative.
Recent Comments