Archive
Running Average Power Limit: a new target for viruses
I have been learning about the Running Average Power Limit, RAPL, feature that Intel introduced with their Sandy Bridge architecture. RAPL is part of a broader framework providing access to all kinds of interesting internal processor state (e.g., detailed instruction counts, cache accesses, branch information etc; use PAPI to get at the numbers on your system, existing perf users need at least version 3.14 of the Linux kernel).
My interest in RAPL is in using it to monitor the power consumed by short code sequences that are alternative implementations of some functionality. There are some issues that need to be sorted out before this is possible at the level of granularity I want to look at.
I suspect that RAPL might soon move from a very obscure feature to something that is very widely known and talked about; it provides a means for setting an upper limit on the average power consumed by a processor, under software control.
Some environmental activists are very militant and RAPL sounds like it can help save the planet by limiting the average power consumed by computers. Operating systems do provide various power saving options, but I wonder how widely they are used aggressively; one set of building based measurements shows a fairly constant rate of power consumption, smaller set showing a bit of daily variation.
How long will it be before a virus targeting RAPL appears?
Limiting the average power consumed by a processor is likely to result in programs running more slowly. Will the average user notice? Slower browser response could be caused by all sorts of things. Users are much more likely to notice a performance problem when watching a high definition video.
For service providers RAPL is another target to add to the list of possible denial-of-service attacks.
Unique bytes in a sliding window as a file content signature
I was at a workshop a few months ago where a speaker pointed out a useful technique for spotting whether a file contains compressed data, e.g., a virus hidden in a script by compressing it to look like a jumble of numbers. Compressed data contains a uniform distribution of byte values (after all, compression is achieved by reducing apparent information content), your mileage may vary between compression techniques. The thought struck me that it would only take a minute to knock up an R script to check out this claim (my use of R is starting to branch out into solving certain kinds of general coding problems) and here it is:
window_width=256 # if this is less than 256 divisor has to change in call to plot
plot_unique=function(filename)
{
t=readBin(filename, what="raw", n=1e7)
# Sliding the window over every point is too much overhead
cnt_points=seq(1, length(t)-window_width, 5)
u=sapply(cnt_points, function(X) length(unique(t[X:(X+window_width)])))
plot(u/256, type="l", xlab="Offset", ylab="Fraction Unique", las=1)
return(u)
}
dummy=plot_unique("http://shape-of-code.com/2013/05/17/preferential-attachment-applied-to-frequency-of-accessing-a-variable/")
dummy=plot_unique("http://www.shape-of-code.com/R_code/requirements.tgz") |
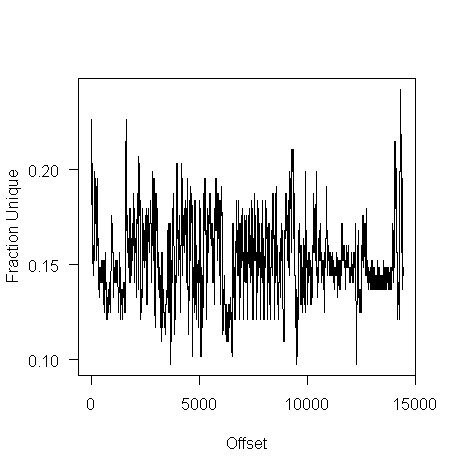
The unique bytes per window (256 bytes wide) of a HTML file has a mean around 15% (sd 2):
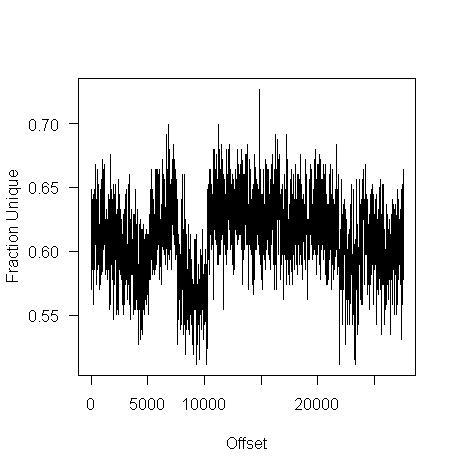
while for a tgz file the mean is 61% (sd 2.9):
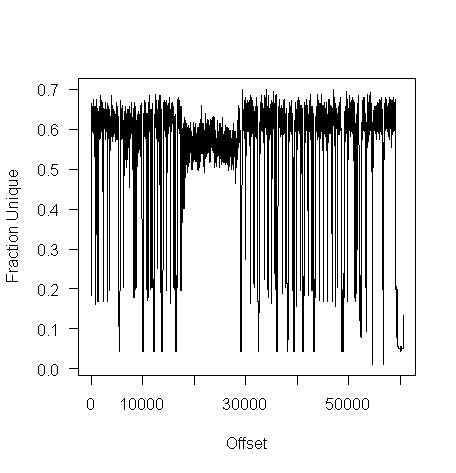
I don’t have any scripts containing a virus, but I do have a pdf containing lots of figures (are viruses hidden in pieces all all together?):
Do let me know if you find any interesting ‘unique byte’ signatures for file contents.
Recent Comments