Archive
semgrep: the future of static analysis tools
When searching for a pattern that might be present in source code contained in multiple files, what is the best tool to use?
The obvious answer is grep, and grep is great for character-based pattern searches. But patterns that are token based, or include information on language semantics, fall outside grep‘s model of pattern recognition (which does not stop people trying to cobble something together, perhaps with the help of complicated sed scripts).
Those searching source code written in C have the luxury of being able to use Coccinelle, an industrial strength C language aware pattern matching tool. It is widely used by the Linux kernel maintainers and people researching complicated source code patterns.
Over the 15+ years that Coccinelle has been available, there has been a lot of talk about supporting other languages, but nothing ever materialized.
About six months ago, I noticed semgrep and thought it interesting enough to add to my list of tool bookmarks. Then, a few days ago, I read a brief blog post that was interesting enough for me to check out other posts at that site, and this one by Yoann Padioleau really caught my attention. Yoann worked on Coccinelle, and we had an interesting email exchange some 13-years ago, when I was analyzing if-statement usage, and had subsequently worked on various static analysis tools, and was now working on semgrep. Most static analysis tools are created by somebody spending a year or so working on the implementation, making all the usual mistakes, before abandoning it to go off and do other things. High quality tools come from people with experience, who have invested lots of time learning their trade.
The documentation contains lots of examples, and working on the assumption that things would be a lot like using Coccinelle, I jumped straight in.
The pattern I choose to search for, using semgrep, involved counting the number of clauses contained in Python if-statement conditionals, e.g., the condition in: if a==1 and b==2: contains two clauses (i.e., a==1, b==2). My interest in this usage comes from ideas about if-statement nesting depth and clause complexity. The intended use case of semgrep is security researchers checking for vulnerabilities in code, but I’m sure those developing it are happy for source code researchers to use it.
As always, I first tried building the source on the Github repo, (note: the Makefile expects a git clone install, not an unzipped directory), but got fed up with having to incrementally discover and install lots of dependencies (like Coccinelle, the code is written on OCaml {93k+ lines} and Python {13k+ lines}). I joined the unwashed masses and used pip install.
The pattern rules have a yaml structure, specifying the rule name, language(s), message to output when a match is found, and the pattern to search for.
After sorting out various finger problems, writing C rather than Python, and misunderstanding the semgrep output (some of which feels like internal developer output, rather than tool user developer output), I had a set of working patterns.
The following two patterns match if-statements containing a single clause (if.subexpr-1), and two clauses (if.subexpr-2). The option commutative_boolop is set to true to allow the matching process to treat Python’s or/and as commutative, which they are not, but it reduces the number of rules that need to be written to handle all the cases when ordering of these operators is not relevant (rules+test).
rules: - id: if.subexpr-1 languages: [python] message: if-cond1 patterns: - pattern: | if $COND1: # we found an if statement $BODY - pattern-not: | if $COND2 or $COND3: # must not contain more than one condition $BODY - pattern-not: | if $COND2 and $COND3: $BODY severity: INFO - id: if.subexpr-2 languages: [python] options: commutative_boolop: true # Reduce combinatorial explosion of rules message: if-cond2 pattern-either: - patterns: - pattern: | if $COND1 or $COND2: # if statement containing two conditions $BODY - pattern-not: | if $COND3 or $COND4 or $COND5: # must not contain more than two conditions $BODY - pattern-not: | if $COND3 or $COND4 and $COND5: $BODY - patterns: - pattern: | if $COND1 and $COND2: $BODY - pattern-not: | if $COND3 and $COND4 and $COND5: $BODY - pattern-not: | if $COND3 and $COND4 or $COND5: $BODY severity: INFO |
The rules would be simpler if it were possible for a pattern to not be applied to code that earlier matched another pattern (in my example, one containing more clauses). This functionality is supported by Coccinelle, and I’m sure it will eventually appear in semgrep.
This tool has lots of rough edges, and is still rapidly evolving, I’m using version 0.82, released four days ago. What’s exciting is the support for multiple languages (ten are listed, with experimental support for twelve more, and three in beta). Roughly what happens is that source code is mapped to an abstract syntax tree that is common to all supported languages, which is then pattern matched. Supporting a new language involves writing code to perform the mapping to this common AST.
It’s not too difficult to map different languages to a common AST that contains just tokens, e.g., identifiers and their spelling, literals and their value, and keywords. Many languages use the same operator precedence and associativity as C, plus their own extras, and they tend to share the same kinds of statements; however, declarations can be very diverse, which makes life difficult for supporting a generic AST.
An awful lot of useful things can be done with a tool that is aware of expression/statement syntax and matches at the token level. More refined semantic information (e.g., a variable’s type) can be added in later versions. The extent to which an investment is made to support the various subtleties of a particular language will depend on its economic importance to those involved in supporting semgrep (Return to Corp is a VC backed company).
Outside of a few languages that have established tools doing deep semantic analysis (i.e., C and C++), semgrep has the potential to become the go-to static analysis tool for source code. It will benefit from the network effects of contributions from lots of people each working in one or more languages, taking their semgrep skills and rules from one project to another (with source code language ceasing to be a major issue). Developers using niche languages with poor or no static analysis tool support will add semgrep support for their language because it will be the lowest cost path to accessing an industrial strength tool.
How are the VC backers going to make money from funding the semgrep team? The traditional financial exit for static analysis companies is selling to a much larger company. Why would a large company buy them, when they could just fork the code (other company sales have involved closed-source tools)? Perhaps those involved think they can make money by selling services (assuming semgrep becomes the go-to tool). I have a terrible track record for making business predictions, so I will stick to the technical stuff.
Update
Parts of the semgrep source have changed from an Open source license to a commercial one.
Opengrep is an Open source fork of semgrep.
Pricing by quantity of source code
Software tool vendors have traditionally licensed their software on a per-seat basis, e.g., the cost increases with the number of concurrent users. Per-seat licensing works well when there is substantial user interaction, because the usage time is long enough for concurrent usage to build up. When a tool can be run non-interactively in the cloud, its use is effectively instantaneous. For instance, a tool that checks source code for suspicious constructs. Charging by lines of code processed is a pricing model used by some tool vendors.
Charging by lines of code processed creates an incentive to reduce the number of lines. This incentive was once very common, when screens supporting 24 lines of 80 characters were considered a luxury, or the BASIC interpreter limited programs to 1023 lines, or a hobby computer used a TV for its screen (a ‘tiny’ CRT screen, not a big flat one).
It’s easy enough to splice adjacent lines together, and halve the cost. Well, ease of splicing depends on programming language; various edge cases have to be handled (somebody is bound to write a tool that does a good job).
How does the tool vendor respond to a (potential) halving of their revenue?
Blindly splicing pairs of lines creates some easily detectable patterns in the generated source. In fact, some of these patterns are likely to be flagged as suspicious, e.g., if (x) a=1;b=2; (did the developer forget to bracket the two statements with { }).
The plot below shows the number of lines in gcc 2.95 containing a given number of characters (left, including indentation), and the same count after even-numbered lines (with leading whitespace removed) have been appended to odd-numbered lines (code+data, this version of gcc was using in my C book):
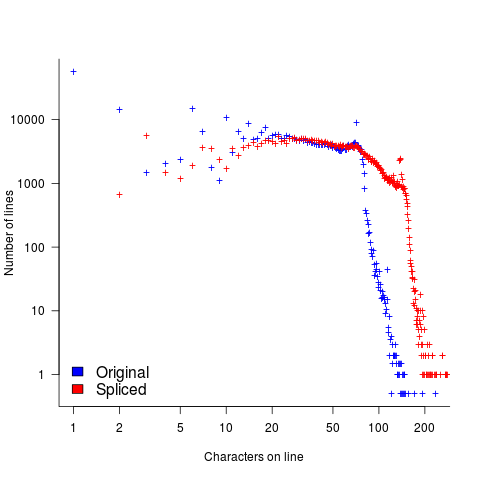
The obvious change is the introduction of a third straight’ish line segment (the increase in the offset of the sharp decline might be explained away as a consequence of developers using wider windows). By only slicing the ‘right’ pairs of lines together, the obvious patterns won’t be present.
Using lines of codes for pricing has the advantage of being easy to explain to management, the people who sign off the expense, who might not know much about source code. There are other metrics that are much harder for developers to game. Counting tokens is the obvious one, but has developer perception issues: Brackets, both round and curly. In the grand scheme of things, the use/non-use of brackets where they are optional has a minor impact on the token count, but brackets have an oversized presence in developer’s psyche.
Counting identifiers avoids the brackets issue, along with other developer perceptions associated with punctuation tokens, e.g., a null statement in an else arm.
If the amount charged is low enough, social pressure comes into play. Would you want to work for a company that penny pinches to save such a small amount of money?
As a former tool vendor, I’m strongly in favour of tool vendors making a healthy profit.
Creating an effective static analysis requires paying lots of attention to lots of details, which is very time-consuming. There are lots of not particularly good Open source tools out there; the implementers did all the interesting stuff, and then moved on. I know of several groups who got together to build tools for Java when it started to take-off in the mid-90s. When they went to market, they quickly found out that Java developers expected their tools to be free, and would not pay for claimed better versions. By making good enough Java tools freely available, Sun killed the commercial market for sales of Java tools (some companies used their own tools as a unique component of their consulting or service offerings).
Could vendors charge by the number of problems found in the code? This would create an incentive for them to report trivial issues, or be overly pessimistic about flagging issues that could occur (rather than will occur).
Why try selling a tool, why not offer a service selling issues found in code?
Back in the day a living could be made by offering a go-faster service, i.e., turn up at a company and reduce the usage cost of a company’s applications, or reducing the turn-around time (e.g., getting the daily management numbers to appear in less than 24-hours). This was back when mainframes ruled the computing world, and usage costs could be eye-watering.
Some companies offer bug-bounties to the first person reporting a serious vulnerability. These public offers are only viable when the source is publicly available.
There are companies who offer a code review service. Having people review code is very expensive; tools are good at finding certain kinds of problem, and investing in tools makes sense for companies looking to reduce review turn-around time, along with checking for more issues.
Array bound checking in C: the early products
Tools to support array bound checking in C have been around for almost as long as the language itself.
I recently came across product disks for C-terp; at 360k per 5 1/4 inch floppy, that is a C compiler, library and interpreter shipped on 720k of storage (the 3.5 inch floppies with 720k and then 1.44M came along later; Microsoft 4/5 is the version of MS-DOS supported). This was Gimpel Software’s first product in 1984.

The Model Implementation C checker work was done in the late 1980s and validated in 1991.
Purify from Pure Software was a well-known (at the time) checking tool in the Unix world, first available in 1991. There were a few other vendors producing tools on the back of Purify’s success.
Richard Jones (no relation) added bounds checking to gcc for his PhD. This work was done in 1995.
As a fan of bounds checking (finding bugs early saves lots of time) I was always on the lookout for C checking tools. I would be interested to hear about any bounds checking tools that predated Gimpel’s C-terp; as far as I know it was the first such commercially available tool.
The dance of the dead cat
The flagging of unspecified behavior in C source by static analysis tools (i.e., where the standard specifies two or more possible behaviors for translators to choose from when generating code) is starting to rather get sophisticated, some tools are working out and reporting how many different program outputs are possible given the unspecified behavior in the source (traditionally tools simply point at code containing an instance of unspecified behavior).
A while ago I created a function where the number of possible different values returned, driven by one unspecified behavior in the code, was a Fibonacci number (the value of the function parameter selected the n’th Fibonacci number).
Weird ways of generating Fibonacci numbers are great for entertaining fellow developers, but developers are unlikely to be amused by a tool that flags their code as generating Fibonacci possible values (rather than the one they are expecting).
The possibility of Fibonacci different values relies on the generated code cycling through all possible behaviors, allowed by the standard, at runtime. This can only happen if program execution uses a Just-in-Time compiler; the compile once before execution implementations used by most developers get to generate far fewer possible permitted values (i.e, two for this particular example). Who would be crazy enough to write a JIT compiler for C you ask? Those crazy people who translate C to JavaScript for one.
To be useful for developers who are not using a JIT compiler to execute their C code, static analysis tools that work out the number of possible values that could be produced are going to have to support a code-compiled-before-execution option. Tools that don’t support this option will have what they report dismissed as weird possibilities that cannot happen in the developer’s world.
In the code below, does setting the code-compiled-before-execution option guarantee that the function Schrödinger always returns 1?
int x; int set_x(void) { x=1; return 1; } int two_values(void) { x=0; return x + set_x(); // different evaluation order -> different value } bool Schrödinger(void) { return two_values() == two_values(); } |
A compiler is free to generate code that returns a value that depends on whether two_values appears as the left or right operand of a binary operator. Not the kind of behavior an implementor would choose on purpose, but inlining both calls could result in different evaluation orders for the two instances of the code contained in what was the function body.
Our developer friendly sophisticated static analysis tool vendor is going to have to support a different_calls_to_same_function_have_same_behavior option.
How can a developer find out whether the compiler they were using always generated code having the same external behavior for different instances of calls, in the source, to the same function? Possibilities include reading the compiler source and asking the compiler vendor (perhaps future releases of gcc and llvm will support a different_calls_to_same_function_have_same_behavior option).
As far as I know (not having spent a lot of time looking) none of the tools doing the sophisticated unspecified behavior stuff support either of the developer friendly options I am suggesting need to be supported. Tools I know about include: c-semantics (including its go faster commercial incarnation) and ch2o (which the authors tell me executes the Fibonacci code a lot faster than c-semantics; last time I looked ch2o needed more installation time for the support tools it uses than I was willing to spend, so I have not tried it); the Cerberus project has not released the source of their system yet (I’m assuming they will).
Tools that help handle floating-point dragons
There be dragons is a common refrain in any discussion involving code containing floating-point. The dragons are not likely to disappear anytime soon, but there has been a lot of progress since my 2011 post and practical tools for handling them are starting to become available to developers who are not numerical analysts.
All the techniques contain an element of brute force, very many possibilities are examined (cloud computing is starting to have a big impact on how problems are attacked). All the cloud computing on the planet would not make a noticeable dent in any problem unless some clever stuff was done to drastically prune the search space.
My current favorite tool is Herbie, if only because of the blog posts describing some of the techniques used (it’s currently limited to code without loops; if you need loop support check out Rosa).
It’s all very well having the performance of your floating-point code optimized, but who is to say nasty problems are not lurking in unexplored ranges of the underlying formula. Without an Oracle capable of generating the correct answer (whatever that might be; Precimonious has to be provided with training inputs), the analysis can only flag what is considered to be suspicious behavior. Craft attempts to detect cancellation errors, S3FP searches for input values that produce results containing large relative error and Rangelab simply provides bounds on the output values calculated from whatever input it is fed.
Being interested in getting very accurate results is a niche market. Surprisingly inaccurate results are good enough for many people and perhaps we should be using a language designed for this market.
Perhaps the problem of efficiently and accurately printing floating-point numbers might finally have just been solved.
The POPL 2015 papers involving C
SIGPLAN (the ACM Special Interest Group on Programming LANguages) has just made available many of the papers that have been accepted for their 2015 POPL conference (Principles of Programming Languages). Good for them. I wish more conferences would do this.
There are three papers involving C, so obviously I have read those first. Two papers are heavy on the mathematics and one not quite so heavy:
- Sound Modular Verification of C Code Executing in an Unverified Context: Describes a tool that takes C source annotated with separation logic and translates it to C source containing runtime checks; it is intended that these runtime checks verify the conditions expressed in the separation logic. Why does the developer add the interface checks in separation logic and then translate, rather than adding them in C in the first place? This was question was not addressed
- Common compiler optimizations are invalid in the C11 memory model and what we can do about it: This sounds like bad news, but the introduction mentions specialist optimizations that are common in that specialist area. There follows 11 pages of mathematics + another five pages in an appendix. Page 12 tells us what it is all about. Some requirements in C11 would be muck up the nice mathematics should CompCert, which currently supports C90, be upgraded to C11. In other words, a compiler implementor is complaining that wording in the standard is making their life difficult (hey, join the queue) and has published a paper about it.
- Formal verification of a C static analyzer: An interesting piece of work spoiled by claims that a soap powder manufacturer would not be able to get away with. Verasco, the static analysis tool described, does its checking on an intermediate language that is two-steps removed from the original C source. Using the authors’ logic, I could bolt on one of the existing Fortran-to-C translators and claim to have a formally-verified Fortran static analyzer, with C being just an intermediate language in the chain. The problem with analyzing an intermediate language is that the transformations that have occurred along the way have changed the semantics of the original code, so the results of any analysis could be different than if applied to the original source. An example from the paper, the code:
z = f(x) + 2 * g(y)
is transformed to:
t1 = f(x); t2 = g(y); z = t1 + 2 * t2;
The implementation thus selects one of the two possible evaluation orders for the functions
fandg. It is possible that callingfbeforegwill result in behavior that is different from callinggbeforef(no undefined behavior occurs because there is a sequence point before a function returns, using pre-C11 terminology).So Verasco is only checking one of the two possible execution paths in this code. Not a particularly sound proof.
C-semantics is the C formal methods tool that stands head and shoulders above anything else that currently exists (a fun Fibonacci example). It is actually based on the C source and does significantly more checking than verasco, but is not mentioned in the “Related work” section of the paper.
Some of the other POPL papers look a lot more interesting and potentially useful.
Tool for tuning the use of floating-point types
A common problem when writing code that performs floating-point arithmetic is figuring out which of the available three (usually) possible floating-point types to use (e.g., float, double or long double). Some language ‘solve’ this problem by only having one possibility (e.g., R) and some implementations of languages that offer three types use the same representation for all of them (e.g., 32 bits).
The type float often represents the least precision/range of values but occupies the smallest amount of storage and operations on it have traditionally been the fastest, type long double often represents the greatest precision/range of values but occupies the most storage and operations on it are generally the slowest. Applying the Goldilocks principle the type double is very often selected.
Anyone who has worked with floating-point values will be familiar with some of the ways they can bite very hard. Once a function that uses floating-point types is written the general advice is to leave it alone.
Precimonious is an interesting new tool that searches for possible performance/accuracy trade-offs; it randomly selects a floating-point declaration, changes the type used, executes the resulting program and compares the output against that produced by the original program. Users of the tool specify the maximum error (difference in output values) they are willing to accept and Precimonious searches for a combination of changes to the floating-point types contained within a program that result in a faster program that does not exceed this maximum error.
The performance improvements cited in the paper (which includes the doyen of floating-point in its long list of authors) cluster around zero and worthwhile double figure percentage (max 41.7%); sometimes no improvements were found until the maximum error was reduced from  to
to  .
.
Perhaps a combination of Precimonious and a tool that attempts to improve accuracy is the next step 🙂
There is resistance to using search based methods to fix faults. Perhaps tools like Precimonious will help developers get used to the idea of search assisted software development.
I wonder how long it will be before we see commentary in bug reports such as the following:
- that combination of values was not in the Precimonious test set,
- Precimonious cannot find a sufficiently optimized program within the desired error tolerance for that rarely seen combination of values. Won’t fix.
Hiring experts is cheaper in the long run
The SAMATE (Software Assurance Metrics And Tool Evaluation) group at the US National Institute of Standards and Technology recently started hosting a new version of test suites for checking how good a job C/C++/Java static analysis tools do at detecting vulnerabilities in source code. The suites were contributed by the NSA‘s Center for Assured Software.
Other test suites hosted by SAMATE contain a handful of tests and have obviously been hand written, one for each kind of vulnerability. These kind of tests are useful for finding out whether a tool detects a given problem or not. In practice problems occur within a source code context (e.g., control flow path) and a tool’s ability to detect problems in a wide range of contexts is a crucial quality factor. The NSA’s report on the methodology used looked good and with the C/C++ suite containing 61,387 tests it was obviously worth investigating.
Summary: Not a developer friendly test suite that some tools will probably fail to process because it exceeds one of their internal limits. Contains lots of minor language infringements that could generate many unintended (and correct) warnings.
Recommendation: There are people in the US who know how to write C/C++ test suites, go hire some of them (since this is US government money there are probably rules that say it has to go to US companies).
I’m guessing that this test suite was written by people with a high security clearance and a better than average knowledge of C/C++. For this kind of work details matter and people with detailed knowledge are required.
Another recommendation: Pay compiler vendors to add checks to their compilers. The GCC people get virtually no funding to do front end work (nearly all funding comes from vendors wanting backend support). How much easier it would be for developers to check their code if they just had to toggle a compiler flag; installing another tool introduces huge compatibility and work flow issues.
I had this conversation with a guy from GCHQ last week (the UK equivalent of the NSA) who are in the process of spending £5 million over the next 3 years on funding research projects. I suspect a lot of this is because they want to attract bright young things to work for them (student sponsorship appears to be connected with the need to pass a vetting process), plus universities are always pointing out how more research can help (they are hardly likely to point out that research on many of the techniques used in practice was done donkey’s years ago).
Some details
Having over 379,000 lines in the main function is not a good idea. The functions used to test each vulnerability should be grouped into a hierarchy; main calling functions that implement say the top 20 categories of vulnerability, each of these functions containing calls to the next level down and so on. This approach makes it easy for the developer to switch in/out subsets of the tests and also makes it more likely that the tool will not hit some internal limit on function size.
The following log string is good in theory but has a couple of practical problems:
printLine("Calling CWE114_Process_Control__w32_char_connect_socket_03_good();"); CWE114_Process_Control__w32_char_connect_socket_03_good(); |
C89 (the stated version of the C Standard being targeted) only requires identifiers to be significant to 32 characters, so differences in the 63rd character might be a problem. From the readability point of view it is a pain to have to check for values embedded that far into a string.
Again the overheads associated with storing so many strings of that length might cause problems for some tools, even good ones that might be doing string content scanning and checking.
The following is a recurring pattern of usage and has undefined behavior that is independent of the vulnerability being checked for. The lifetime of the variable shortBuffer terminates at the curly brace, }, and who knows what might happen if its address is accessed thereafter.
data = NULL; { /* FLAW: Point data to a short */ short shortBuffer = 8; data = &shortBuffer; } CWE843_Type_Confusion__short_68_badData = data; |
A high quality tool would report the above problem, which occurs in several tests classified as GOOD, and so appear to be failing (i.e., generating a warning when none should be generated).
The tests contain a wide variety of minor nits like this that the higher quality tools are likely to flag.
Trying to sell analysis tools to the Nuclear Regulatory Commission
Over the last few days there has been an interesting, and in places somewhat worrying, discussion going on in the Safety Critical mailing list about the US Nuclear Regulatory Commission. I thought I would tell my somewhat worrying story about dealing with the NRC.
In 1996 the NRC posted a request for information for a tool that I thought my company stood a reasonable chance of being able to meet (“NRC examines source code in nuclear power plant safety systems during the licensing process. NRC is interested in finding commercially available tools that can locate and provide information about the following programming practices…”). I responded, answered the questions on the form I received and was short listed to make a presentation to the NRC.
The presentation took place at the offices of National Institute of Standards and Technology, the government agency helping out with the software expertise.
From our brief email exchanges I had guessed that nobody at the NRC/NIST end knew much about C or static analysis. A typical potential customer occurrence that I was familiar with handling.
Turned up, four or so people from NRC+one(?) from NIST, gave a brief overview and showed how the tool detected the constructs they were interested in, based on test cases I had written after reading their requirements (they had not written any but did give me some code that they happened to have, that was, well, code they happened to have; a typical potential customer occurrence that I was familiar with handling).
Why did the tool produce all those messages? Well, those are the constructs you want flagged. A typical potential customer occurrence that I was familiar with handling.
Does any information have to be given to the tool, such as where to find header files (I knew that they had already seen a presentation from another tool vendor, these managers who appeared to know nothing about software development had obviously picked up this question from that presentation)? Yes, but it is very easy to configure this information… A typical potential customer occurrence that I was familiar with handling.
I asked how they planned to use the tool and what I had to do to show them that this tool met their requirements.
We want one of our inspectors to be able turn up at a reactor site and check their source code. The inspector should not need to know anything about software development and so the tool must be able to run automatically without any options being given and the output must be understandable to the inspector. Not a typical potential customer occurrence and I had no idea about how to handle it (I did notice that my mouth was open and had to make a conscious effort to keep it closed).
No, I would not get to see their final report and in fact I never heard from them again (did they find any tool vendor who did not stare at them in disbelief?)
The trip was not a complete waste of time, a few months earlier I had been at a Java study group meeting (an ISO project that ultimately failed to convince Sun to standarize Java through the ISO process) with some NIST folk who worked in the same building and I got to chat with them again.
A few hours later I realised that perhaps the question I should have asked was “What kind of software are people writing at nuclear facilities that needs an inspector to turn up and check?”
Would you buy second hand software from a formal methods researcher?
I have been reading a paper on formally proving software correct (Bridging the Gap: Automatic Verified Abstraction of C by Greenaway, Andronick and Klein) and as often the case with papers on this topic the authors have failed to reach the level of honest presentation required by manufacturers of soap power in their adverts.
The Greenaway et al paper describes a process that uses a series of translation steps to convert a C program into what is claimed to be a high level specification in Isabelle/HOL (a language+support tool for doing formal proofs).
The paper was published by an Australian research group; I could not find an Australian advertising standards code dealing with soap power but did find one covering food and beverages. Here is what the Australian Association of National Advertisers has to say in their Food & Beverages Advertising & Marketing Communications Code:
“2.1 Advertising or Marketing Communications for Food or Beverage Products shall be truthful and honest, shall not be or be designed to be misleading or deceptive or otherwise contravene Prevailing Community Standards, and shall be communicated in a manner appropriate to the level of understanding of the target audience of the Advertising or Marketing Communication with an accurate presentation of all information…”
So what claims and statements do Greenaway et al make?
2.1 “Before code can be reasoned about, it must first be translated into the theorem prover.” A succinct introduction to one of the two main tasks, the other being to prove the correctness of these translations.
“In this work, we consider programs in C99 translated into Isabelle/HOL using Norrish’s C parser … As the parser must be trusted, it attempts to be simple, giving the most literal translation of C wherever possible.”
“As the parser must be trusted”? Why must it be trusted? Oh, because there is no proof that it is correct, in fact there is not a lot of supporting evidence that the language handled by Norrish’s translator is an faithful subset of C (ok, for his PhD Norrish wrote a formal semantics of a subset of C; but this is really just a compiler written in mathematics and there are umpteen PhDs who have written compilers for a subset of C; doing it using a mathematical notation does not make it any more fault free).
The rest of the paper describes how the output of Norrish’s translator is generally massaged to make it easier for people to read (e.g., remove redundant statements and rename variables).
Then we get to the conclusion which starts by claiming: “We have presented a tool that automatically abstracts low-level C semantics into higher-level specifications with automatic proofs of correctness for each of the transformation steps.”
Oh no you didn’t. There is no proof for the main transformation step of C to Isabelle/HOL. The only proofs described in the paper are for the post processing fiddling about that was done after the only major transformation step.
And what exactly is this “high-level specification”? The output of the Norrish translator was postprocessed to remove the clutter that invariably gets generated in any high-level language to high-level language translator. Is the result of this postprocessing a specification? Surely it is just a less cluttered representation of the original C?
Actually this paper does contain a major advance in formally proving software correct, tucked away at the start it says “As the parser must be trusted…”. There it is in black and white, if you have some software that must be trusted don’t bother with formal proofs just simply follow the advice given here.
But wait a minute you say, I am ignoring the get out of jail wording “… shall be communicated in a manner appropriate to the level of understanding of the target audience …”. What is the appropriate level of understanding of the target audience, in fact who is the target audience? Is the target audience other formal methods researchers who are familiar with the level of intellectual honesty within their field and take claims made by professional colleagues with a pinch of salt? Are non-formal methods researchers not the target audience and so have no redress to being misled by the any claims made by papers in this field?
Recent Comments