Archive
Comparing developer/LLM coding performance
Lots of claims are being made about how LLMs will soon outperform developers on coding tasks. Given the lack of any effective measure of developer performance, these claims are meaningless. At some point, lower costs will entice management to accept good enough LLM performance as a replacement for human developers, i.e., LLM don’t need to be technically better than developers.
The outperform claims are, currently, marketing puff, and I was not expecting anybody to make a serious attempt to compare developer/LLM performance. However, concerns about AI exceeding human capacity to control it (and maybe wiping out humans) has resulted in some well funded AI safety research groups. There is at least one group actively recruiting developers to “… establish human performance baselines on tasks related to software engineering, machine learning, and cybersecurity …”.
The most talked about AI threat scenarios all seem to start with recursive self-improvement, i.e., LLMs training themselves, exponentially improving with each iteration (the implied exponential always seems to be continuously up, rather than getting exponentially closer to a maximum).
Can current LLMs improve themselves faster than a developer can?
Implementing a new LLM is beyond the ability of today’s LLM, but they can implement some of the components used to build an LLM. How does LLM performance compare against developers, on the implementation of these components?
The paper RE-Bench: Evaluating frontier AI R&D capabilities of language model agents against human experts from METR (Model Evaluation & Threat Research) comes with code and “… anonymized human expert data coming soon.” for seven tasks. The baseline was derived from the performance of 61 human experts.
I’m always pleased to see researchers doing experiments with developers. I wish there were more groups doing this kind of thing.
However, I think that these researchers have made the common mistake of using very complicated subject tasks in their experiment. Most software development tasks are mundane, with the occasional complicated task (which can often be solved by using an appropriate package/library). The tasks may be representative of the harder tasks that need to be done, but they are not representative of the complete LLM implementation scenario.
A consequence of using complicated tasks is that most subjects only had enough time to complete one task (they were given 8 hours). With so few tasks (seven) the confidence intervals are going to be very wide on any general statement about human/LLM performance. With around ten subjects per task, the individual task confidence intervals are also going to be wide.
Task 7 made me laugh: “… that generates solutions to CodeContests problems in Rust, …”
Why Rust? Did they happen to have access to lots of Rust experts, or does the research group contain enthusiastic fans of Rust? I suspect the latter. There is a certain kind of highly intelligent developer who strongly believes that writing programs in a particular language imbues the code with magical properties (their rationale won’t be worded that way). For the last few years, Rust has been one of these pixie dust languages. Many decades ago, C had this charisma.
Perhaps each generation of ever more ‘intelligent’ LLMs will choose to design a new language to use to implement their ‘successor’.
There are a myriad of tasks related to software engineering. Solving GitHub issues is a thankless task, and having LLMs reliably close open issues would be of enormous benefit. A study published two months ago obtained a 1.96% solution rate (no explicit testing of developers).
Changing development culture and practices: LLM edition
The popular perception of creating software systems is that it mainly involves writing code. In the 1950s, management treated writing code as a clerical task that just mapped the detailed requirements specified by someone with knowledge of the problem to something a computer could execute. Job titles reflected this division of labour, e.g., coder/programmer, systems analyst (the Wikipedia entry lists implementation as part of the job, this eventually became true in theory and for many was probably true in practice since the early days).
Using Large Language Models to write code based on the requirements contained in a prompt appears to take software development back to the process mandated by the managers of early software projects.
A major economic incentive for the creation of software systems is enabling more efficient work processes, with the collateral damage of decimated employment in some work functions. This happened to clerical workers and non-software engineering workers. Now it’s happening to software developers.
Hardware designers did not cease to exist once Computer-aided design became available. Technical drawing skills (larger schools once had a room full of drawing boards for teaching young teenagers) has ceased to be a job requirement (image from Wikipedia).

Software developer will remain as a job category, perhaps with reduced numbers or with reduced average pay. But the use of LLMs will change the culture and practices of software development.
The shift from using assembly language to high level languages suggests a few ideas about the kinds of changes. Using assembly language requires being reasonably familiar with the cpu architecture, e.g., register names/widths/instruction-restrictions and instruction timings. General developer chat about cpu architectures was still a thing in the 1980s, less so in the 1990s, and very rarely today (people do blog about it). Several decades from now, what will no longer be a general topic of developer conversation? Data types, perhaps; like registers, bit pattern representation is a low level detail. Since most developers don’t know much about the languages they use, it may be difficult to measure the impact of LLM usage on language knowledge.
High-level languages increase developer productivity by reducing the number of details that need to be thought about, at the cost of less efficient code. But for many applications, machine time is cheaper than human time.
LLMs increase developer productivity by reducing the need to lookup details (e.g., spelling of method names and their parameters). As confidence grows in the accuracy of LLM suggested code, developers will start accepting, whatever. What counts is whether the code works, not whether the average developer would have written something faster/smaller/idiomatic.
The early languages have a straightforward mapping from statements/declarations to machine code. Over time, languages were created that allowed developers to think less and less about implementation details, at the cost of supporting constructs that could introduce lots of hidden overhead. I expect that customer demand will incentivize LLM functionality that reduces what developers need to think about.
A real danger of LLM usage is that it will, eventually, result in programs a lot more bloated than humans have managed to achieve. There are physical constraints restricting what hardware designers can do, and these constraints show up in patterns of behavior, e.g., Rent’s rule relating the number of external connections in a logic block to the number of logic gates in the block. There are common usage patterns in existing code, but no theory suggesting they are desirable, or not, in any sense. I await having enough LLM generated production code to make statistically significant measurements.
I suspect that these days most developers are writing glue code, or short programs, and in the near term I expect that most LLM code will fill this need. Unfortunately, there is very little research/measurement on glue code/short program, so there are no known developer usage patterns to compare LLMs against.
LLMs and doing software engineering research
This week I attended the 65th COW workshop, the theme was Automated Program Repair and Genetic Improvement.
I first learned about using genetic programming to automatically fix reported faults at the 1st COW workshop in 2009. Claire Le Goues, a PhD student at that workshop, now a professor, returned to talk about the latest program repair work of her research group.
COW speakers are usually very upbeat, but uncertainty about the future was the general feeling I got from speakers at this workshop. The cause of this uncertainty was the topic of some talks and conversations: LLMs. Adding an LLM into the program repair process can produce a dramatic performance improvement.
Isn’t a dramatic performance improvement and a new technique great news for everyone? The performance improvement increases the likelihood of industrial adoption, and a new technique creates many opportunities for new research.
Despite claiming otherwise, most academics have zero interest in industrial adoption of their work, and some actively disdain practical uses of their work.
Major new techniques are great for PhD students; they provide an opportunity to kick-start a career by being in at the start of a new research area.
A major new technique can obsolete an established researcher’s expensively acquired area of expertise (expensive in personal time and effort). The expertise that enables a researcher to make state-of-the-art contributions to an active research area is a valuable asset; it can be used to attract funding, students and peer esteem. When a new technique dramatically improves the state-of-the-art, there is a sharp drop in the value of what is now yesterday’s know-how.
A major new technique removes some existing barriers to entering a field, and creates its own new ones. The result is that new people start working in a field, and some existing experts stop working in it.
At the workshop, I saw this process starting in automated program repair, and I imagine it’s also starting in many other research fields. It will probably take 3–5 years for the dust to start to settle; existing funded projects have to complete, and academia does not move that quickly.
A recent review of the use of LLMs in software engineering research found 229 papers; the table below shows the number of papers per year:
Papers Year
7 2020
11 2021
51 2022
160 2023 to end July |
Assuming, say, 10K software engineering papers per year, then LLM related papers should be around 3% this year, likely in double figures next year, and possibly over 50% the year after.
Is research in software engineering en route to becoming another subfield of prompt engineering research?
Delphi and group estimation
A software estimate is a prediction about the future. Software developers were not the first people to formalize processes for making predictions about the future. Starting in the last 1940s, the RAND Corporation’s Delphi project created what became known as the Delphi method, e.g., An Experiment in Estimation, and Construction of Group Preference Relations by Iteration.
In its original form experts were anonymous; there was a “… deliberate attempt to avoid the disadvantages associated with more conventional uses of experts, such as round-table discussions or other milder forms of confrontation with opposing views.”, and no rules were given for the number of iterations. The questions involved issues whose answers involved long term planning, e.g., how many nuclear weapons did the Soviet Union possess (this study asked five questions, which required five estimates). Experts could provide multiple answers, and had to give a probability for each being true.
One of those involved in the Delphi project (Helmer-Hirschberg) co-founded the Institute for the Future, which published reports about the future based on answers obtained using the Delphi method, e.g., a 1970 prediction of the state-of-the-art of computer development by the year 2000 (Dalkey, a productive member of the project, stayed at RAND).
The first application of Delphi to software estimation was by Farquhar in 1970 (no pdf available), and Boehm is said to have modified the Delphi process to have the ‘experts’ meet together, rather than be anonymous, (I don’t have a copy of Farquhar, and my copy of Boehm’s book is in a box I cannot easily get to); this meeting together form of Delphi is known as Wideband Delphi.
Planning poker is a variant of Wideband Delphi.
An assessment of Delphi by Sackman (of Grant-Sackman fame) found that: “Much of the popularity and acceptance of Delphi rests on the claim of the superiority of group over individual opinions, and the preferability of private opinion over face-to-face confrontation.” The Oracle at Delphi was one person, have we learned something new since that time?
Group dynamics is covered in section 3.4 of my Evidence-based software engineering book; resource estimation is covered in section 5.3.
The likelihood that a group will outperform an individual has been found to depend on the kind of problem. Is software estimation the kind of problem where a group is likely to outperform an individual? Obviously it will depend on the expertise of those in the group, relative to what is being estimated.
What does the evidence have to say about the accuracy of the Delphi method and its spinoffs?
When asked to come up with a list of issues associated with solving a problem, groups generate longer lists of issues than individuals. The average number of issues per person is smaller, but efficient use of people is not the topic here. Having a more complete list of issues ought to be good for accurate estimating (the validity of the issues is dependent on the expertise of those involved).
There are patterns of consistent variability in the estimates made by individuals; some people tend to consistently over-estimate, while others consistently under-estimate. A group will probably contain a mixture of people who tend to over/under estimate, and an iterative estimation process that leads to convergence is likely to produce a middling result.
By how much do some people under/over estimate?
The multiplicative factor values (y-axis) appearing in the plot below are from a regression model fitted to estimate/actual implementation time for a project involving 13,669 tasks and 47 developers (data from a study Nichols, McHale, Sweeney, Snavely and Volkmann). Each vertical line, or single red plus, is one person (at least four estimates needed to be made for a red plus to occur); the red pluses are the regression model’s multiplicative factor for that person’s estimates of a particular kind of creation task, e.g., design, coding, or testing. Points below the grey line are overestimation, and above the grey line the underestimation (code+data):
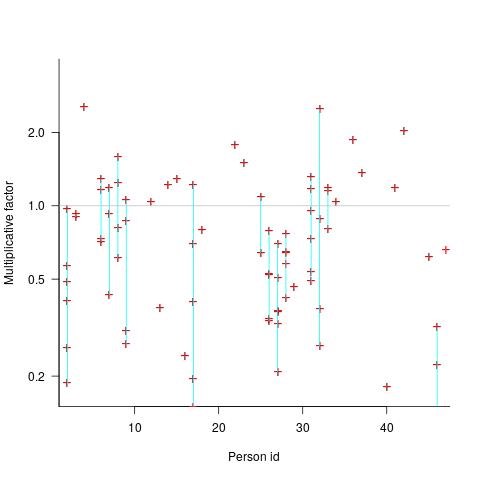
What is the probability of a Delphi estimate being more accurate than an individual’s estimate?
If we assume that a middling answer is more likely to be correct, then we need to calculate the probability that the mix of people in a Delphi group produces a middling estimate while the individual produces a more extreme estimate.
I don’t have any Wideband Delphi estimation data (or rather, I only have tiny amounts); pointers to such data are most welcome.
Changes in the shape of code during the twenties?
At the end of 2009 I made two predictions for the next decade; Chinese and Indian developers having a major impact on the shape of code (ok, still waiting for this to happen), and scripting languages playing a significant role (got that one right, but then they were already playing a large role).
Since this blog has just entered its second decade, I will bring the next decade’s predictions forward a year.
I don’t see any new major customer ecosystems appearing. Ecosystems are the drivers of software development, and no new ecosystems has several consequences, including:
- No major new languages: Creating a language is a vanity endeavour. Vanity project can take off if they are in the right place at the right time. New ecosystems provide opportunities for new languages to become widely used by being in at the start and growing with the ecosystem. There is another opportunity locus; it is fashionable for companies that see themselves as thought-leaders to have their own language, e.g., Google, Apple, and Mozilla. Invent your language at the right time, while working for a thought-leader company and your language could become well-known enough to take-off.
I don’t see any major new ecosystems appearing, and all the likely companies already have their own language.
Any new language also faces the problem of not having a large collection packages.
- Software will be more thoroughly tested: When an ecosystem is new, the incentives drive early and frequent releases (to build a customer base); software just has to be good enough. Once a product is established, companies can invest in addressing issues that customers find annoying, like faulty behavior; the incentive change results in more testing.
There are other forces at work around testing. Companies are experiencing some very expensive faults (testing may be expensive, but not testing may be more expensive) and automatic test generation is becoming commercially usable (i.e., the cost of some kinds of testing is decreasing).
The evolution of widely used languages.
- I think Fortran and C will have new features added, with relatively little fuss, and will quietly continue to be widely used (to the dismay of the fashionista).
-
There is a strong expectation that C++ and Java should continue to evolve:
- I expect the ISO C++ work to implode, because there are too many people pulling in too many directions. It makes sense for the gcc and llvm teams to cooperate in taking C++ in a direction that satisfies developers’ needs, rather than the needs of bored consultants. What are Microsoft’s views? They only have their own compiler for strategic reasons (they make little if any profit selling compilers, compilers are an unnecessary drain on management time; who cares what happens to the language).
- It is going to be interesting watching the impact of Oracle’s move to charging for runtimes. I have no idea what might happen to Java.
In terms of code volume, the future surely has to be scripting languages, and in particular Python, Javascript and PHP. Ten years from now, will there be a widely used, single language? People have been predicting, for many years, that web languages will take over the world; perhaps there will be a sudden switch and I will see that the choice is obvious.
Moore’s law is now dead, which means researchers are going to have to look for completely new techniques for building logic gates. If photonic computers happen, then ternary notation may reappear again (it was used in at least one early Russian computer); I’m not holding my breath for this to occur.
Automatically improving code
Compared to 20 or 30 years ago we know a lot more about the properties of algorithms and better ways of doing things often exist (e.g., more accurate, faster, more reliable, etc). The problem with this knowledge is that it takes the form of lots and lots of small specific details, not the kind of thing that developers are likely to be interested in, or good at, remembering. Rather than involve developers in the decision-making process, perhaps the compiler could figure out when to substitute something better for what had actually been written.
While developers are likely to be very happy to see what they have written behaving as accurately and reliably as they had expected (ignorance is bliss), there is always the possibility that the ‘less better’ behavior of what they had actually written had really been intended. The following examples illustrate two relatively low level ‘improvement’ transformations:
- this case is probably a long-standing fault in many binary search and merge sort functions; the relevant block of developer written code goes something like the following:
while (low <= high) { int mid = (low + high) / 2; int midVal = data[mid]; if (midVal < key) low = mid + 1 else if (midVal > key) high = mid - 1; else return mid; }
The fault is in the expression
(low + high) / 2which overflows to a negative value, and returns a negative value, if the number of items being sorted is large enough. Alternatives that don’t overflow, and that a compiler might transform the code to, include:low + ((high - low) / 2)and(low + high) >>> 1. - the second involves summing a sequence of floating-point numbers. The typical implementation is a simple loop such as the following:
sum=0.0; for i=1 to array_len sum += array_of_double[i];
which for large arrays can result in
sumlosing a great deal of accuracy. The Kahan summation algorithm tries to take account of accuracy lost in one iteration of the loop by compensating on the next iteration. If floating-point numbers were represented to infinite precision the following loop could be simplified to the one above:sum=0.0; c=0.0; for i = 1 to array_len { y = array_of_double[i] - c; // try to adjust for previous lost accuracy t = sum + y; c = (t - sum) - y; // try and gets some information on lost accuracy sum = t; }
In this case the additional accuracy is bought at the price of a decrease in performance.
Compiler maintainers are just like other workers in that they want to carry on working at what they are doing. This means they need to keep finding ways of improving their product, or at least improving it from the point of view of those willing to pay for their services.
Many low level transformations such as the above two examples would be not be that hard to implement, and some developers would regard them as useful. In some cases the behavior of the code as written would be required, and its transformed behavior would be surprising to the author, while in other cases the transformed behavior is what the developer would prefer if they were aware of it. Doesn’t it make sense to perform the transformations in those cases where the as-written behavior is least likely to be wanted?
Compilers already do things that are surprising to developers (often because the developer does not fully understand the language, many of which continue to grow in complexity). Creating the potential for more surprises is not that big a deal in the overall scheme of things.
Has the seed that gets software development out of the stone-age been sown?
A big puzzle for archaeologists is why Stone Age culture lasted as long as it did (from approximately 2.5 millions years ago until the start of the copper age around 6.3 thousand years ago). Given the range of innovation rates seen in various cultures through-out human history, a much shorter Stone Age is to be expected. A recent paper proposes that low population density is what maintained the Stone Age status quo; there was not enough contact between different hunter gather groups for widespread take up of innovations. Life was tough, and the viable lifetime of individual groups of people may not have been long enough for them to be likely to pass on innovations (either their own ones encountered through contact with other groups).
Software development is often done by small groups that don’t communicate with other groups and regularly die out (well there is a high turn-over, with many of the more experienced people moving on to non-software roles). There are sufficient parallels between hunter gathers and software developers to suggest both were/are kept in a Stone Age for the same reason, lack of a method that enables people to obtain information about innovations and how worthwhile these might be within a given environment.
A huge barrier to the development of better software development practices is the almost complete lack of significant quantities of reliable empirical data that can be used to judge whether a claimed innovation is really worthwhile. Companies rarely make their detailed fault databases and product development history public; who wants to risk negative publicity and lawsuits just so academics have some data to work with.
At the start of this decade, public source code repositories like SourceForge and public software fault repositories like Bugzilla started to spring up. These repositories contain a huge amount of information about the characteristics of the software development process. Questions that can be asked of this data include: what are common patterns of development and which ones result in fewer faults, how does software evolve and how well do the techniques used to manage it work.
Empirical software engineering researchers are now setting up repositories, like Promise, containing the raw data from their analysis of Open Source (and some closed source) projects. By making this raw data available, they are reducing the effort needed by other researchers to investigate their own alternative ideas (I have just started a book on empirical software engineering using the R statistical language that uses examples based on this raw data).
One of the side effects of Open Source development could be the creation of software development practices that have been shown to be better (including showing that some existing practices make things worse). The source of these practices not being what the software developers themselves do or how they do it, but the footsteps they have left behind in the sand.
Program analysis via information leakage
The use of software in high value transactions has created an interesting new field of software research that investigates the leakage of information from programs. The kind of information leaked, so-called sideband information, can take various forms, including:
- The amount of time taken to perform some operation. Many developers instinctively do their best to ensure that code does not take any longer to execute than it has to. In the case of one commonly used authentication system, the time taken to fail to authenticate an encryption key provided useful information on how close one trial encryption-key was compared to another (the closer the trial key to the actual key, the longer the authentication took to fail). The obvious implementation technique to foil this kind of attack is to add random delays into the authentication process.
It has even proved possible to perform timing attacks against a remote machine over the Internet to remote
- Use of some part of the value of secure information, by a system library function, to create the value passed back to the caller, e.g.,
if (secret_value & 0xf000) // Tell the caller that the top 'secret' four bits are set return 1; else return 0;
Researchers have been able to analyse the information flow of input values through some very large C programs.
- Analyse of network traffic routing information to work out who is talking to who. Various kinds of anonymizers have been created in attempt to make various forms of Internet traffic untraceable.
Any Internet program is accessible to information flow analysis. Using these techniques to analyse the search algorithm used by Google might be overly ambitious. A Google algorithm that might be within reach of is the one used by Adwords; the behavior of this algorithm is of interest to a growing number of people.
Information leakage techniques are becoming more widely known and developers working on programs containing a security component now need to consider how they can prevent information being leaked to attackers who sample program behavior looking for exploitable weaknesses.
The changing shape of code in the next decade
I think there are two forces that will have a major impact on the shape of code in the next decade:
- Asian developers. China and India each have a population that is more than twice as large as Europe and the US combined, and software development has been kick-started in these countries by a significant amount of IT out sourcing. I have one comparative data point for software developers who might be of the hacker ilk. A discussion of my C book on a Chinese blog resulted in a download volume that was 50% of the size of the one that occurred when the book appeared as a news item on Slashdot.
- Scripting languages. Software is written to solve a problem, and there are only so many packaged applications (COTS or bespoke) that can profitably be supported. Scripting languages are generally designed to operate within one application domain, e.g., Bash, numerical analysis languages such as R and graphical plotting languages such as gnuplot.
While markup languages are very widely used they tend to be read and written by programs not people.
Having to read code containing non-alphabetic characters is always a shock the first time. Simply having to compare two sequences of symbols for equality is hard work. My first experience of having to do this in real time was checking train station names once I had travelled outside central Tokyo and the names were no longer also given in Romaji.
其中,ul分别是bootmap_size(bit map的size),start_pfn(开始的页框) max_low_pfn(被内核直接映射的最后一个页框的页框号) ; |
Developers based in China and India have many different cultural conventions compared to the West (and each other) and I suspect that these will affect the code they write (my favorite potential effect involves treating time vertically rather than horizontally). Many coding conventions used by a given programming language community exist because of the habits adopted by early users of that language, these being passed on to subsequent users. How many Chinese and Indian developers are being taught to use these conventions, are the influential teachers spreading different conventions? I don’t have a problem with different conventions being adopted, other than that having different communities using different conventions increases the cost for one community to adopt another community’s source.
Programs written in a scripting language tend to be much shorter (often being contained within a single file) and make use of much more application knowledge than programs written in general purpose languages. Their data flow tends to be relatively simple (e.g., some values are read/calculated and passed to a function that has some external effect), while the relative complexity of the control flow seems to depend on the language (I only have a few data points for both assertions).
Because of their specialized nature, most scripting languages will not have enough users to support any kind of third party support tool market, e.g., testing tools. Does this mean that programs written in a scripting language will contain proportionally more faults? Perhaps their small size means that only a small number of execution paths are possible, and these are quickly exercised by everyday usage (I don’t know of any research on this topic).
Recent Comments