Archive
Taking a new GLR parser generator for a spin
It’s been 10 years since I last wrote about parsing tools, and the C parser, pycparser, I took for a test drive is still actively maintained. This week I read a post on Gecko, a new parser generator. Its author, Vladimir Makarov, implemented his first parser generator in 1985.
Gecko generates GLR parsers (Generalized Left-to-Right). In 2009, I predicted that GLR parsing was the future. It might still be the future, but since I made that prediction handwritten parsers, using some form of recursive descent, are what the major compilers (e.g., gcc and llvm) have been updated to use. Bison, the almost invisible market leader for parser generation, has supported GLR parsers for almost 20 years. The other ‘generalized’ technique, Earley parsing, produces parsers that are much slower and are memory hogs.
GLR parsers support Type-1 languages in the Chomsky hierarchy. The LR parsers supported by yacc compatible tools (e.g., the Bison default mode), and LL by ANTLR, can handle Type-2 languages, and regular expressions are Type-3 languages.
Programming language grammars are often context-sensitive (ambiguous is the common developer terminology), i.e., there is more than one way of parsing a sequence of input tokens. The classic example is the C statement: T *p;, which could be a declaration of p, or a redundant multiplication. This ambiguity can be resolved by maintaining a list of identifiers currently defined as typedefs, and have the lexer/parser lookup the status of identifiers in the contexts where a typedef could occur. This is not a big deal for compilers, which have to build a symbol table anyway. However, it’s very inconvenient when only syntax analysis is needed, i.e., no semantic analysis of the source.
An alternative approach is to parse all possibilities, and hope that eventually only one parse is syntactically possible. The following example could work, because there is a subsequent use of T in a non-typedef context (I’m not aware of any tools that do this):
T *p; // Is this a declaration of p as a pointer to T? T++; // No! It's a multiplication of T by p |
Another approach is to choose the most likely parse. Redundant multiplications are rare, and a declaration is the most likely usage. The token sequence f(x); is most likely to be a function call with one argument, rather than redundant parenthesis around a declaration of x to have type f.
Taking Gecko for a test drive requires a lexer and a grammar. Fortunately, one of the Gecko test cases includes a C lexer/grammar, and I adapted this to try out some C syntax test cases (code). My comparison point for these tests my memory of testing out Bison with GLR enabled.
Developers make coding mistakes, and I made mistakes when adapting the existing Gecko C grammar. Perhaps because I’m new to it, but Gecko’s minimalist error reporting was not helpful. Lots of debug information is available, but this is oriented towards somebody developing the innards of a parser generator. Hopefully, now Gecko is up and working, the focus will shift to improving developer diagnostics.
When Bison fails to merge multiple parses into a single parse, it failed. Gecko appears not to fail (it’s difficult to tell), it returns a parse tree.
Coding mistakes are sometime syntax errors, and without some form of error recovery, syntax errors often cascade to produce lots of spurious errors. Recovering from syntax errors is hard, but skipping to the next semicolon works remarkably well as a catch-all.
In Bison, syntax error recovery has to be hand-coded into the grammar and parser. Gecko supports an automatic syntax error recovery process. Based on a small sample, this automatic process failed to handle the common syntax errors (e.g., missing identifier or missing operator in an expression) I tried it on (code). It did handle the example in the documentation. Perhaps this is a work in progress.
The Gecko source built and passed all of its own tests. My tests are intended to check for handling of ambiguous constructs and error handling. As such, they are not pass/fail.
The main functional difference between Gecko and Bison is that Gecko is compiled into the program and can then be used to read and process a grammar at program runtime. Bison processes the grammar to produce tables that are included as part of the build process of a program.
This difference enables Gecko to handle grammars that are created or updated at application runtime. This approach also simplifies the process of handling multiple grammars.
While on the subject of parser generators, I have been following the progress of Marpa, but not tried it yet. The author has some interesting things to say about parsing.
Automatically generating railroad diagrams from yacc files
Reading and understanding a language’s syntax written in the BNF-like notation used by yacc/bison takes some practice. Railroad diagrams are a much more user friendly notation, but require a lot of manual tweaking before they look as good as the following example from the json.org website:
I’m currently working on a language whose syntax is evolving and I want to create a visual representation of it that can be read by non-yacc experts; spending a day of so manually creating a decent looking railroad diagram is not an efficient use of time. What automatic visualization tools are out there that I can use?
A couple of tools that look like they might produce useful results are web based (e.g., bottlecaps.de; working on an internal project for a company means I cannot take this approach). Some tools take EBNF as input (e.g., my28msec.com which is also online based); the Extensions in EBNF obviate the need for many of the low level organizational details that appear in grammars written with BNF, making grammars written using EBNF easier to layout and look good; great if I was working with EBNF. The yacc file input tools I tried (yaccviso, Vyacc) were a bit too fragile and the output was not that good.
Bison has an option to generate a output that can be processed into graphical form (using graphviz as the layout engine). Unfortunately the graphs produced are as visually tangled as the input grammar and if anything harder to follow.
It is possible to produce great looking visual diagrams using a simple tool if you are willing to spend lots of fiddling with the input grammar to control the output. I wanted to take the grammar as written (i.e., a yacc input file) and am willing to accept less than perfect output.
Most of the syntax rules in a yacc grammar are straight forward sequences of tokens that have an obvious one-to-one mapping and there are a few commonly seen idioms. I decided to write a tool that concentrated on untangling the idioms and let the simple stuff look after itself. One idiom that has a visual representation very different from its yacc form is the two productions used to specify an arbitrary long list, e.g., a semicolon separated list of ys is often written as (ok, there might perhaps be times when right recursion is appropriate):
x : y | x ";" y ; |
and I wanted something that looked like (from the sql-lite web site, which goes one better and allows support for the list to be optional:
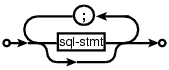
Graph layout is a complicated business and like everybody else I decided to use graphviz to do the heavy lifting (specifically I would generate the layout directives used by dot). All I had to do was write a yacc grammar to dot translator (and not spend lots of time doing it).
The dot language provides a directives that specify the visual properties of nodes and the connections between them. For instance:
n_0[shape=point] n_1[label="sql-stmt"] n_2[label=";"] n_3[shape=point] n_0 -> n_3 n_0 -> n_1 n_1 -> n_3 n_1 -> n_2 n_2 -> n_1 |
is the dot specification of the optional semicolon separated list of sql-stmts displayed above.
Dot takes a list of directives describing the nodes and edges of a graph and makes its own decisions about how to layout the output. It is possible to specify in excruciating detail exactly how to do the layout, but I wanted everything to be automated.
I decided to write the tool in awk because it has great input token handling facilities and I use it often enough to be fluent.
Each grammar rule containing one or more productions is mapped to a single graph. When generating postscript dot puts each graph on a separate page, other output formats appear to loose all but one of the graphs. To make sure each rule fitted on a page I had the text point size depend on the number of productions in a rule, more productions smaller point size. The most common idioms are handled (i.e., list-of and optional construct) with hooks available to handle others. Productions within a rule will often have common token sequences but the current version only checks for matching token sequences at the start of a production and all productions in a rule have to start with the same sequence. Words written all in upper-case are assumed to be language tokens and are converted to lower case and bracketed with quotes. The 300+ lines of conversion tool’s awk source is available for download.
The follow examples are taken from an attempted yacc grammar of C++ done when people still thought such a thing could be created. While the output does have a certain railroad diagram feel to it, the terrain must be very hilly to generate those curvaceous lines.
and the run of the mill rules look good, a C++ primary-expression is:
and we can rely on C++ to push syntax rule complexity to the limit, a postfix-expression is:
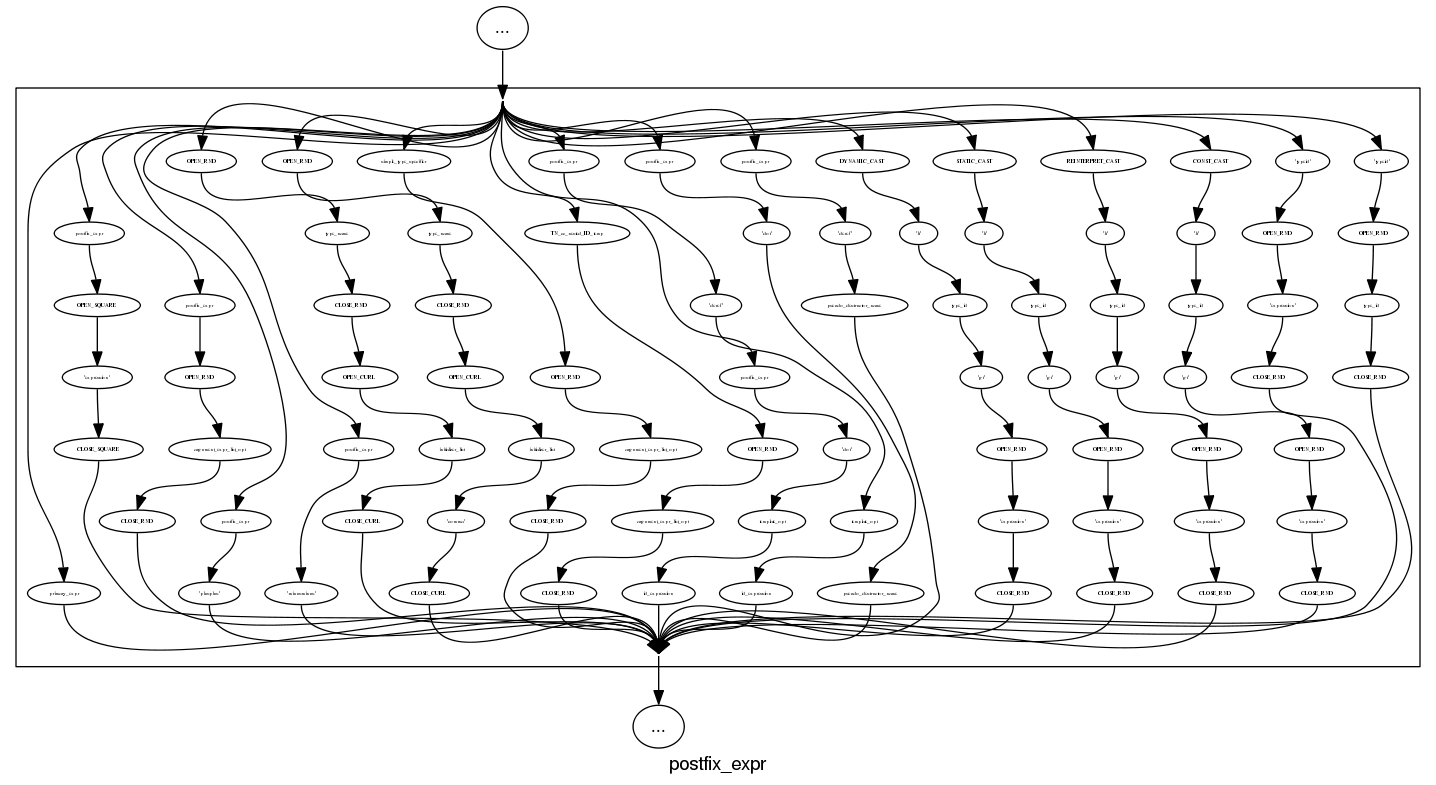
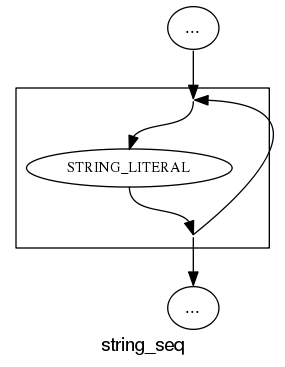
What about the idioms? A simple list of items looks good:
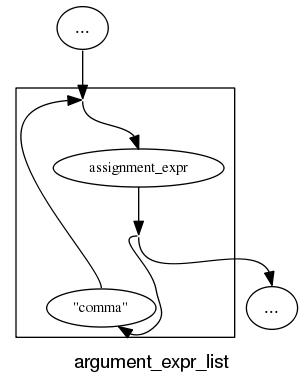
and slightly less good when separators are involved:
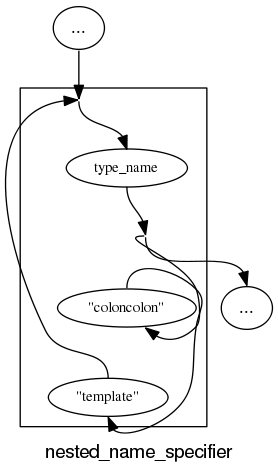
and if we push our luck things start to look tangled:
With a bit more work invested on merging token sequences common to two or more rules the following might look a lot less cluttered:
Apart from a few tangled cases the results are not bad for a tool that was a few hours work. I will wait a bit to see if the people I deal with find this visual form of use.
In the meantime I would be interested to hear about my readers experience with visualizing grammars, using dot to this kind of thing and any suggestions they have. As a long time user of dot I know that there are lots of ways of influencing the final layout (e.g., changing the ordering or edges and nodes in its input), I will have to be careful not to get pulled down this rabbit hole.
GLR parsing is the future
Traditionally parser generators have required that their input grammar be LALR(1) or some close variant (I would include LL(1) in this set). Back when 64k was an unimaginably large amount of memory being able to squeeze parser tables in a few kilobytes was very important; people received PhDs on parser table compression.
There is still a market for compact, fast parsers. Formal language grammars abound in communication protocols and vendors of communications hardware are very interested in keeping down costs by using minimizing the storage needed by their devices.
The trouble with LALR(1) is that value 1. It means that the parser only looks ahead one token in the input stream. This often means that a grammar is flagged as being ambiguous (i.e., it contains shift/reduce or reduce/reduce conflicts) when it is actually just locally ambiguous, i.e., reading tokens further head on the input stream would provide sufficient context to unambiguously specify the appropriate grammar production.
Restructuring a grammar to make it LALR(1) requires a lot of thought and skill and inexperienced users often give up. I once spent a month trying to remove the conflicts in the SQL/2 grammar specified by the SQL ISO standard; I managed to get the number down from over 1,000 to a small number that I decided I could live with.
It has taken a long time for parser generators to break out of the 64k mentality, but over the last few years it has started to happen. There have been two main approaches: 1) LR(n) provides a mechanism to look further ahead than one token, ie,
I think that GLR parsing is the future for two reasons:
- It is supported by the most widely used parser generator, bison.
- It enables working parsers to be created with much less thought and effort than a LALR(1) parser. (I don’t know how it compares against LR(n)).
GLR parsers resolve any language ambiguities by effectively delaying decisions until runtime in the hope that reading enough tokens will resolve local ambiguities. If an ambiguity in the token stream cannot be resolved a runtime error occurs (this is the one big downside of a GLR parser, the parser generated by a LALR(1) parser generator may produce lots of build time warnings but never produces errors when the parser is executed).
One example of a truly ambiguous construct (discussed here a while ago) is:
x * y; |
which in C/C++ could be a declaration of y to be a pointer to x, or an expression that multiplies x and y.
Tools that can detect these global ambiguities in a grammar are starting to appear, e.g., DTWA is a bison extension.
I reviewed an early draft of the new O’Reilly book “flex & bison” and tried to get the author to be more upbeat on GLR support in bison; I think I got him to be a bit less cautious.
Parsing without a symbol table
When processing C/C++ source for the first time through a compiler or static analysis tool there are invariably errors caused by missing header files (often because the search path has not been set) or incorrectly defined, or not defined, macro names. One solution to this configuration problem is to be able to process source without handling preprocessing directives (e.g., skipping them, such as not reading the contents of header files or working out which arm of a conditional directive is applicable). Developers can do it, why not machines?
A few years ago GLR support was added to Bison, enabling it to process ambiguous grammars, and I decided to create a C parser that simply skipped all preprocessing directives. I knew that at least one reasonably common usage would generate a syntax error:
func_call(a, #if SOME_FLAG b_1); #else b_2); #endif |
c);
and wanted to minimize its consequences (i.e., cascading syntax errors to the end of the file). The solution chosen was to parse the source a single statement or declaration at a time, so any syntax error would be localized to a single statement or declaration.
Systems for parsing ambiguous grammars work on the basis that while the input may be locally ambiguous, once enough tokens have been seen the number of possible parses will be reduced to one. In C (and even more so in C++) there are some situations where it is impossible to resolve which of several possible parses apply without declaration information on one or more of the identifiers involved (a traditional parser would maintain a symbol table where this information could be obtained when needed). For instance, x * y; could be a declaration of the identifier y to have type x or an expression statement that multiplies x and y. My parser did not have a symbol table and even if it did the lack of header file processing meant that its contents would only contain a partial set of the declared identifiers. The ambiguity resolution strategy I adopted was to pick the most likely case, which in the example is the declaration parse.
Other constructs where the common case (chosen by me and I have yet to get around to actually verifying via measurement) was used to resolve an ambiguity deadlock included:
f(p); // Very common, // confidently picked function call as the common case (m)*p; // Not rare, // confidently picked multiplication as the common case (s) - t; // Quiet rare, // picked binary operator as the common case (r) + (s) - t; // Very rare, //an iteration on the case above |
At the moment I am using the parser to measure language usage, so less than 100% correctness can be tolerated. Some of the constructs that cause a syntax error to be generated every few hundred statement/declarations include:
offsetof(struct tag, field_name) // Declarators cannot be //function arguments int f(p, q) int p; // Tries to reduce this as a declaration without handling char q; // it as part of an old style function definition { MACRO(+); // Preprocessing expands to something meaningful |
Some of these can be handled by extensions to the grammar, while others could be handled by an error recovery mechanism that recognized likely macro usage and inserted something appropriate (e.g., a dummy expression in the MACRO(x) case).
Recent Comments