Archive
First use of: software, software engineering and source code
While reading some software related books/reports/articles written during the 1950s, I suddenly realized that the word ‘software’ was not being used. This set me off looking for the earliest use of various computer terms.
My search process consisted of using pfgrep on my collection of pdfs of documents from the 1950s and 60s, and looking in the index of the few old computer books I still have.
Software: The Oxford English Dictionary (OED) cites an article by John Tukey published in the American Mathematical Monthly during 1958 as the first published use of software: “The ‘software’ comprising … interpretive routines, compilers, and other aspects of automotive programming are at least as important to the modern electronic calculator as its ‘hardware’.”
I have a copy of the second edition of “An Introduction to Automatic Computers” by Ned Chapin, published in 1963, which does a great job of defining the various kinds of software. Earlier editions were published in 1955 and 1957. Did these earlier edition also contain various definitions of software? I cannot find any reasonably prices copies on the second-hand book market. Do any readers have a copy?
Update: I now have a copy of the 1957 edition of Chapin’s book. It discusses programming, but there is no mention of software.
Software engineering: The OED cites a 1966 “letter to the ACM membership” by Anthony A. Oettinger, then ACM President: “We must recognize ourselves … as members of an engineering profession, be it hardware engineering or software engineering.”
The June 1965 issue of COMPUTERS and AUTOMATION, in its Roster of organizations in the computer field, has the list of services offered by Abacus Information Management Co.: “systems software engineering”, and by Halbrecht Associates, Inc.: “software engineering”. This pushes the first use of software engineering back by a year.
Source code: The OED cites a 1965 issue of Communications ACM: “The PUFFT source language listing provides a cross-reference between the source code and the object code.”
The December 1959 Proceedings of the EASTERN JOINT COMPUTER CONFERENCE contains the article: “SIMCOM – The Simulator Compiler” by Thomas G. Sanborn. On page 140 we have: “The compiler uses this convention to aid in distinguishing between SIMCOM statements and SCAT instructions which may be included in the source code.”
Update: The October 1956 issue of Computers and Automation contains an extensive glossary. It does not have any entries for software or source code.
Running pdfgrep over the archive of documents on bitsavers would probably throw up all manners of early users of software related terms.
The paper: What’s in a name? Origins, transpositions and transformations of the triptych Algorithm -Code -Program is a detailed survey of the use of three software terms.
A 1931 article using the term Super Computing machine to refer to a Punched card machine that could do arithmetic on numeric values contained on the card.
Distribution of uptimes for high-performance computing systems
Computers break down every now and again and this is a serious problem when an application needs runs on thousands of individual computers (nodes) plugged together; lots more hardware creates lots more opportunity for a failure that renders any subsequent calculations by working nodes possible wrong. The solution is checkpointing; saving the state of each node every now and again, and rolling back to that point when a failure occurs. Picking the optimal interval between checkpoints requires knowledge the distribution of node uptimes, what is it?
Short answer: Node uptimes have a negative binomial distribution, or at least five systems at the Los Alamos National Laboratory do.
The longer answer is below as another draft section from my book Empirical software engineering with R. As always comments and pointers to more data welcome. R code and data here.
Distribution of uptimes for high-performance computing systems
Today’s high-performance computing systems are created by connecting together lots of cpus. There is a hierarchy to the connection in that many cpus may populate a single board, several boards may be fitted into a rack unit, several rack units into a cabinet, lots of cabinets lined up in a row within a room and more than one room in a facility. A common operating unit is the node, effectively a computer on which an operating system is running (the actual hardware involved may be a single or multi processor cpu). A high-performance system is built from thousands of nodes and an application program may run on compute nodes from more than one facility.
With so many components, failures occur on a regular basis and long running applications need to recover from such failures if they are to stand a reasonable chance of ever completing.
Applications running on the systems installed at the Los Alamos National Laboratory create checkpoints at regular intervals, writing data needed to do a full restore to storage. When a failure occurs an application is restarted from its most recent checkpoint, one node failure causes all nodes to be rolled back to their most recent checkpoint (all nodes create their checkpoints at the same time).
A tradeoff has to be made between frequently creating checkpoints, which takes resources away from completing execution of the application but reduces the amount of lost calculation, and infrequent checkpoints, which diverts less resources but incurs greater losses when a fault occurs. Calculating the optimum checkpoint interval requires knowing the distribution of node uptimes and the following analysis attempts to find this distribution.
Data
The data comes from 23 different systems installed at the Los Alamos National Laboratory (LANL) between 1996 and 2005. The total failure count for most of the systems is of the order of a few hundred; there are five systems (systems 2, 16, 18, 19 and 20) that each have several thousand failures and these are the ones analysed here.
The data consists of failure records for every node in a system. A failure record includes information such as system id, node number, failure time, restored to service time, various hardware characteristics and possible root causes for the failure. Schroeder and Gibson <book Schroeder_06> performed the first analysis of the dataset and provide more background details.
Is the data believable?
Failure records are created by operations staff when they are notified by the automated monitoring system that a failure has been detected. Given that several people are involved in the process <book LANL_data_06> it seems unlikely that failures will go unreported.
Some of the failure reports have start times before the given node was returned into service from the previous failure; across the five systems this varied between 0.4% and 2.5%. It is possible that these overlapping failures are caused by an incorrectly attempt to fix the first failure, or perhaps they are data entry errors. This error rate is comparable with human error rates for low stress/non-critical work
The failure reports do not include any information about the application software running on the node when it failed; the majority of the programs executed are large-scale scientific simulations, such as simulations of nuclear stockpile stability. Thus it is not possible to accurately calculate the node MTBF for an executing application. LANL say <book LANL_data_06> that the applications “… perform long periods (often months) of CPU computation, interrupted every few hours by a few minutes of I/O for check-pointing.”
Predictions made in advance
The purpose of this analysis is to find the distribution that best fits the node uptime data, i.e., the time interval between failures of the same node.
Your author is not aware of any empirically based theory that predicts the uptime of high performance computing systems. The Poisson and exponential distributions are both frequently encountered in the analysis of hardware failures and it is always comforting to fit in with existing expectations.
Applicable techniques
A [Cullen and Frey test] matches a dataset’s skew and kurtosis against known distributions (in the case of the descdist function in the fitdistrplus package this is a handful of commonly encountered distributions); the fitdist function in the same package can be used to fit the data to a specified distribution.
Results
The table below lists some basic properties of each of the systems analysed. The large difference in mean/median uptimes between some systems is caused by very fat tails in the uptime distribution of some systems, see [LANL-node-uptime-binned].
| System | Nodes | Failures | Mean | Median |
|---|---|---|---|---|
|
2
|
49
|
6997
|
133
|
377
|
|
16
|
16
|
2595
|
89
|
229
|
|
18
|
823
|
3014
|
2336
|
4147
|
|
19
|
738
|
2344
|
2376
|
4069
|
|
20
|
323
|
2063
|
653
|
2544
|
If there are any significant changes in failure rate over time or across different nodes in a given system it could have a significant impact on the distribution of uptime intervals. So we first check to large differences in failure rates.
Do systems experience any significant changes in failure rate over time?
The plot below shows the total number of failures, binned using 30-day periods, for the five systems. Two patterns that stand out are system 20 which experienced many failures during the first few months and then settled down, and system 2’s sudden spike in failures around month 23 before settling down again. This analysis is intended to be broad brush and does not get involved with details of specific systems, but these changes in failure frequency suggest that the exact form of any fitted distribution may change over time in turn potentially leading to a change of checkpoint interval.
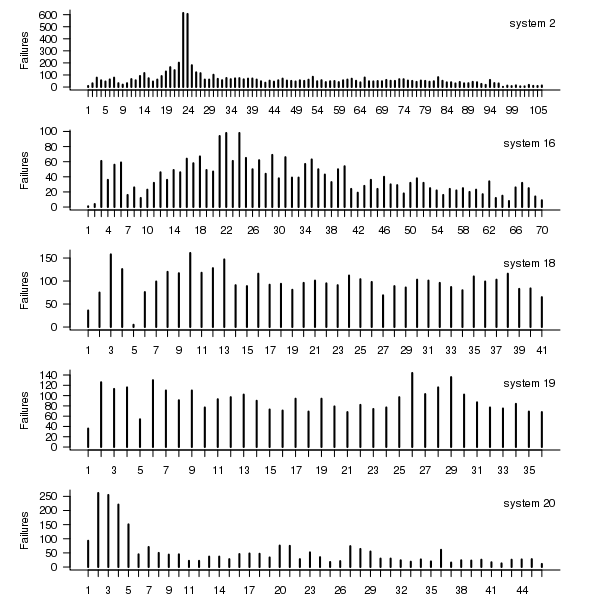
Figure 1. Total number of failures per 30-day interval for each LANL system.
Do some nodes failure more often than others?
The plot below shows the total number of failures for each node in the given system. Node 0 has many more failures than the other nodes (for node 0 of system 2 most of the failure data appears to be missing, so node 1 has the most failures). The distribution suggested by the analysis below is not changed if Node 0 is removed from the dataset.
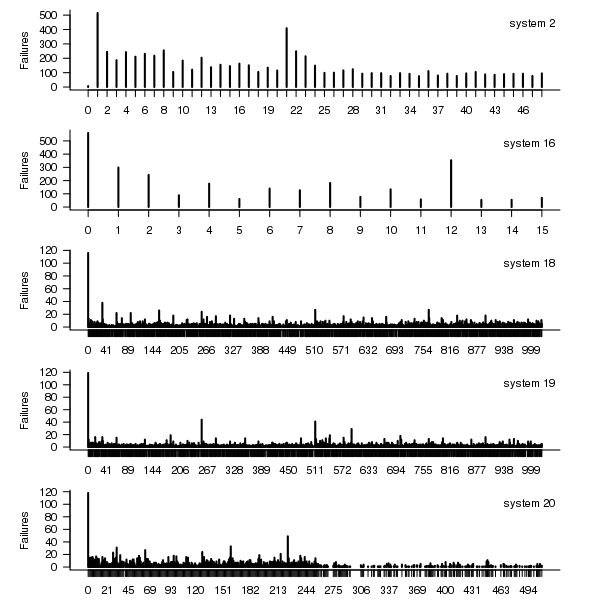
Figure 2. Total number of failures for each node in the given LANL system.
Fitting node uptimes
When plotted in units of 1 hour there is a lot of variability and so uptimes are binned into 10 hour units to help smooth the data. The number of uptimes in each 10-hour bin forms a discrete distribution and a [Cullen and Frey test] suggests that the negative binomial distribution might provide the best fit to the data; the Scroeder and Gibson analysis did not try the negative binomial distribution and of those they tried found the Weilbull distribution gave the best fit; the R functions were not able to fit this distribution to the data.
The plot below shows the 10-hour binned data fitted to a negative binomial distribution for systems 2 and 18. Visually the negative binomial distribution provides the better fit and the Akaiki Information Criterion values confirm this (see code for details and for the results on the other systems, which follow one of the two patterns seen in this plot).
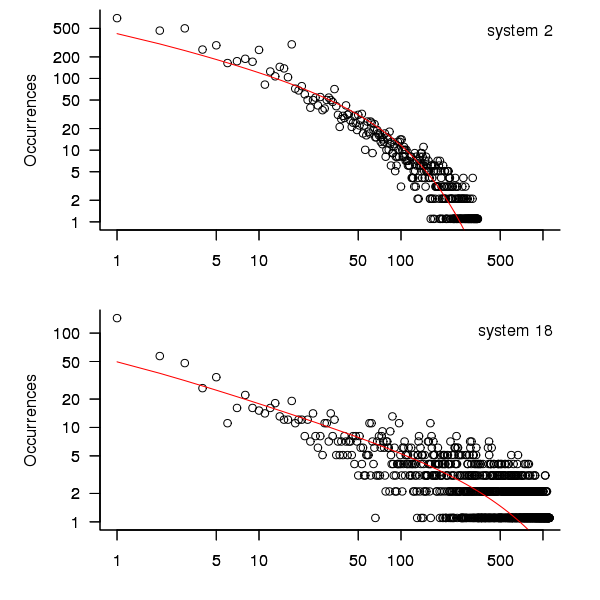
Figure 3. For systems 2 and 18, number of uptime intervals, binned into 10 hour interval, red line is fitted negative binomial distribution.
The negative binomial distribution is also the best fit for the uptime of the systems 16, 19 and 20.
The Poisson distribution often crops up in failure analysis. The quality of fit of a Poisson distribution to this dataset was an order of worse for all systems (as measured by AIC) than the negative binomial distribution.
Discussion
This analysis only compares how well commonly encountered distributions fit the data. The variability present in the datasets for all systems means that the quality of all fitted distributions will be poor and there is no theoretical justification for testing other, non-common, distributions. Given that the analysis is looking for the best fit from a chosen set of distributions no attempt was made to tune the fit (e.g., by forming a zero-truncated distribution).
Of the distributions fitted the negative binomial distribution has the lowest AIC and best fit visually.
As discussed in the section on [properties of distributions] the negative binomial distribution can be generated by a mixture of [Poisson distribution]s whose means have a [Gamma distribution]. Perhaps the many components in a node that can fail have a Poisson distribution and combined together the result is the negative binomial distribution seen in the uptime intervals.
The Weilbull distribution is often encountered with datasets involving some form of time between events but was not seen to be a good fit (for a continuous distribution) by a Cullen and Frey test and could not be fitted by the R functions used.
The characteristics of node uptime for two systems (i.e., 2 and 16) follows what might be thought of as a typical distribution of measurements, with some fattening in the tail, while two systems (i.e., 18 and 19) have very fat tails with indeed and system 20 sits between these two patterns. One system characteristic that matches this pattern is the number of nodes contained within it (with systems 2 and 16 having under 50, 18 and 19 having over 1,000 and 20 having around 500). The significantly difference in the size of the tails is reflected in the mean uptimes for the systems, given in the table above.
Summary of findings
The negative binomial distribution, of the commonly encountered distributions, gives the best fit to node uptime intervals for all systems.
There is over an order of magnitude variation in the mean uptime across some systems.
Why does Intel sell compilers?
Intel is a commercial company and the obvious answer to the question of why it sells compilers is: to make money. Does a company that makes billions of dollars in profits really have any interest in making a few million, I’m guessing, from selling compilers? Of course not, Intel’s interest in compilers is as a means of helping them sell more hardware.
How can a compiler be used to increase computer hardware sales? One possibility is improved performance and another is customer perception of improved performance. My company’s first product was a code optimizer and I was always surprised by the number of customers who bought the product without ever performing any before/after timing benchmarks; I learned that engineers are seduced by the image of performance and only a few are ever forced to get involved in measuring it (having been backed into a corner because what they currently have is not good enough).
Intel are not the only company selling x86 chips, AMD and VIA have their own Intel compatible x86 chips. Intel compatible? Doesn’t that mean that programs compiled using the Intel compiler will execute just as quickly on the equivalent chip sold by competitors? Technically the answer is no, but the performance differences are likely to be small in most cases. However, I’m sure there are many developers who have been seduced by Intel’s marketing machine into believing that they need to purchase x86 chips from Intel to make sure they receive this ‘worthwhile’ benefit.
Where do manufacturer performance differences, for the same sequence of instructions, come from? They are caused by the often substantial internal architectural difference between the processors sold by different manufacturers, also Intel and its competitors are continually introducing new processor architectures and processors from the same company will have differences performance characteristics. It is possible for an optimizer to make use of information on different processor characteristics to tune the machine code generated for a particular high-level language construct, with the developer selecting the desired optimization target processor via compiler switches.
Optimizing code for one particular processor architecture is a specialist market. But let’s not forget all those customers who will be seduced by the image of performance and ignore details such as their programs being executed on a wide variety of architectures.
The quality of a compiler’s runtime library can have a significant impact on a program’s performance. The x86 instruction set has grown over time and large performance gains can be had by a library function that adapts to the instructions available on the processor it is currently executing on. The CPUID instruction provides all of the necessary information.
As well as providing information on the kind of processor and its architectural features the CPUID instruction can return information about the claimed manufacturer of the chip (some manufacturers provide a mechanism that allows users to change the character sequence returned by this instruction).
The behavior of some of the functions in Intel’s runtime library depends on the
character sequence returned by the CPUID instruction, producing better performance for the sequence “GenuineIntel”. The US Federal Trade Commission have filed a complaint alleging that this is anti-competitive (more details) and requested that this manufacturer dependency be removed.
I think that removing this manufacturer dependency will have little impact on sales. Any Intel compiler user who is not targeting Intel chips and who is has a real interest in performance can patch the runtime library, the Supercomputer crowd will want to talk to the kind of sophisticated processor/compiler engineers that Intel makes available and for everybody else it is about the perception of performance. In fact Intel ought to agree to a ‘manufacturer free’ runtime library pronto before too many developers have their delusions shattered.
Recent Comments