Archive
4,000 vs 400 vs 40 hours of software development practice
What is the skill difference between professional developers and newly minted computer science graduates?
Practice, e.g., 4,000 vs. 400 hours
People get better with practice, and after two years (around 4,000 hours) a professional developer will have had at least an order of magnitude more practice than most students; not just more practice, but advice and feedback from experienced developers. Most of these 4,000 hours are probably not the deliberate practice of 10,000 hours fame.
It’s understandable that graduates with a computing degree consider themselves to be proficient software developers; this opinion is based on personal experience (i.e., working with other students like themselves), and not having spent time working with professional developers. It’s not a joke that a surprising number of academics don’t appreciate the student/professional difference, the problem is that some academics only ever get to see a limit range of software development expertise (it’s a question of incentives).
Surveys of student study time have found that for Computer science, around 50% of students spend 11 hours or more, per week, in taught study and another 11 hours or more doing independent learning; let’s take 11 hours per week as the mean, and 30 academic weeks in a year. How much of the 330 hours per year of independent learning time is spent creating software (that’s 1,000 hours over a three-year degree, assuming that any programming is required)? I have no idea, and picked 40% because it matched up with 4,000.
Based on my experience with recent graduates, 400 hours sounds high (I have no idea whether an average student spends 4-hours per week doing programming assignments). While a rare few are excellent, most are hopeless. Perhaps the few hours per week nature of their coding means that they are constantly relearning, or perhaps they are just cutting and pasting code from the Internet.
Most graduates start their careers working in industry (around 50% of comp sci/maths graduates work in an ICT profession; UK higher-education data), which means that those working in industry are ideally placed to compare the skills of recent graduates and professional developers. Professional developers have first-hand experience of their novice-level ability. This is not a criticism of computing degrees; there are only so many hours in a day and lots of non-programming material to teach.
Many software developers working in industry don’t have a computing related degree (I don’t). Lots of non-computing STEM degrees give students the option of learning to program (I had to learn FORTRAN, no option). I don’t have any data on the percentage of software developers with a computing related degree, and neither do I have any data on the average number of hours non-computing STEM students spend on programming; I’ve cosen 40 hours to flow with the sequence of 4’s (some non-computing STEM students spend a lot more than 400 hours programming; I certainly did). The fact that industry hires a non-trivial number of non-computing STEM graduates as software developers suggests that, for practical purposes, there is not a lot of difference between 400 and 40 hours of practice; some companies will take somebody who shows potential, but no existing coding knowledge, and teach them to program.
Many of those who apply for a job that involves software development never get past the initial screening; something like 80% of people applying for a job that specifies the ability to code, cannot code. This figure is based on various conversations I have had with people about their company’s developer recruitment experiences; it is not backed up with recorded data.
Some of the factors leading to this surprisingly high value include: people attracted by the salary deciding to apply regardless, graduates with a computing degree that did not require any programming (there is customer demand for computing degrees, and many people find programming is just too hard for them to handle, so universities offer computing degrees where programming is optional), concentration of the pool of applicants, because those that can code exit the applicant pool, leaving behind those that cannot program (who keep on applying).
Apologies to regular readers for yet another post on professional developers vs. students, but I keep getting asked about this issue.
Undergraduates and learning to program
I last looked at the research on teaching programming around 10 years ago and I have been catching up with what has been going on; in brief: same old, same old. One of the best papers on the subject is still: Language-independent conceptual “Bugs”
The research activity is still focused on making the tools and language ‘better’. There is a defining silence on the possibility that those doing the teaching could not teach their way out of a paper bag. Nobody is brave enough to suggest that teacher training might be a worthwhile investment, or that lectures oriented to what is useful (rather than what the lecturer finds interesting) would be appreciated by students.
I have always thought that researching the teaching of programming had no practical purpose, other than possibly helping universities increase the number of students graduating with computing degrees (some universities are solving the problem students have with programming by offering degrees that don’t involve being able to program). I still think that teaching programming to school children is at best a waste of time.
My experience with students learning to program is from a very long time ago. The process involved listening to confusing and disjoint lectures, reading books and figuring out what worked by trial and error. Students were not taught to program, they got thrown in at the deep and were expected to survive. Anybody who could handle this stood some chance of being able to handle developing software in the ‘real world’; universities were (accidentally) graduating people with the skills industry needed. However, these days universities are supposed to be customer focused, what industry needs is irrelevant (my experience of sitting on departmental industry panels is that the head of department tells us what they are thinking of doing {i.e., new courses for which there will be lots of paying students} and we try to talk him/her out of the sillier ideas); too many fee paying students find programming too hard, let’s offer computing degrees that don’t require any programming has been the only workable solution to-date.
Would you hire a recent graduate, for a development role, who had trouble figuring out how to fix syntax errors in their code? Surely, the minimum requirement is somebody who gets some pleasure from coding, even if they don’t want to spend lots of time doing it.
There is a shortage of software developers and flying turkeys are still with us.
Evidence for the benefits of strong typing, where is it?
It is often claimed that writing software using a strongly typed programming language bestows worthwhile benefits. Those making the claims can sometimes be rather vague about exactly what the benefits are, while at other times appear willing to claim almost any benefit. What does the empirical evidence have to say (let’s ignore the what languages are strongly typed elephant in the room)?
Until recently there had been two empirical studies (plus a couple of language comparison experiments; one of the better ones involves the researcher timing himself implementing various algorithms in various languages; Zislis “An Experiment in Algorithm Implementation”), while in the last few years a group has been experimenting away in Germany (three’ish published data sets).
Measuring changes in developer performance caused by the use of different programming languages is very hard, some of the problems include:
- every person is different: a way needs to be found to take account of differences in subject ability/knowledge/characteristics,
- every problem is different: it may be easier to write a program to solve a problem using language X than using language Y,
- it is difficult to obtain experimental subjects.
The experimental procedure adopted by all the experiments discussed here is to:
- select two different languages or the same language modified to not support some type constructs,
- get students (mostly upper-undergraduates+graduates) to volunteer as experimental subjects,
- have each subject use one language to solve a problem and then use the other language to solve the same problem. Each subject is randomly assigned to a group using a given language order (the experiments start out with an equal number of subjects in each group, but not all subjects complete every problem),
- in some cases the previous step is repeated for new problems.
Having subjects solve the same problem twice creates the opportunity for learning to occur during the implementation of the first program and for this learning to improve performance during the second implementation. The experimental procedures employed generate information that can be used during the analysis of the data (in my case using a mixed-model in R; download code and all data) to factor this ordering effect into the created model.
So what are the results? In chronological order we have (if you know of anymore published work please tell me):
- Gannon “An Experimental Evaluation of Data Type Conversions”: Implemented compilers for two simple languages (think BCPL and BCPL+a string type and simple structures; by today’s standards one language is not quiet as weakly typed as the other). One problem had to be solved and this was designed to require the use of features available in both languages, e.g., a string oriented problem (final programs were between 50-300 lines). The result data included number of errors during development and number of runs needed to create a working program (this all happened in 1977, well before the era of personal computers, when batch processing was king).
There was a small language difference in number of errors/batch submissions; the difference was about half the size of that due to the order in which languages were used by subjects, both of which were small in comparison to the variation due to subject performance differences. While the language effect was small, it exists. To what extent Can the difference be said to be due to stronger typing rather than only one language having built in support for a string type? Who knows, no more experiments like this were performed for 20 years
- Prechelt & Tichy A Controlled Experiment to Assess the Benefits of Procedure Argument Type Checking: Used two C compilers, one K&R C (i.e., no argument checking of function calls) and the other ANSI C, with subjects solving one problem using both compilers; available output data was time taken by subjects to solve the problem.
Using the no argument checking compiler slowed implementation time by around 10%, about five times smaller than the variation in subject performance (there was an ordering effect of around 30%).
- Mayer, Kleinschmager & Hanenberg: Two experiments used different languages (Java and Groovy) and multiple problems; result data was time for subjects to complete the task (Do Static Type Systems Improve the Maintainability of Software Systems? An Empirical Study and An Empirical Study of the Influence of Static Type Systems on the Usability of Undocumented Software). No significant difference due to just language (surprisingly) but differences due to language order, but big differences due to language/problem interaction with some problems solved more quickly in Java and other more quickly in Groovy. Again large variation due to subject performance.
Another experiment used a single language (Java) and multiple problems involving making use of either Java’s generic types or non-generic types (“Do Developers Benefit from Generic Types?”). Again the only significant language difference effects occurred through interaction with other variables in the experiment (e.g., the problem or the language ordering) and again there were large variations in subject performance.
In summary, when a language typing/feature effect has been found its contribution to overall developer performance has been small.
I think some reasons that the effects of typing have been so small, or non-existent, include (I should declare my belief that strong typing is useful):
- the use of students as subjects. Most students have very little programming experience relative to professional developers (i.e., under 100 hours vs. thousands of hours). I can easily imagine many student subjects often finding the warnings produced by the type system more confusing than helpful. More experienced developers are in a position to make full use of what a type system offers, and researchers should try to use professional developers as subjects (it is not that hard to obtain such volunteers)
- the small size of the problems. Typing comes into its own when used to organize and control large amounts of code. I understand the constraints of running an experiment limit the amount of code involved.
Proposal for a change of approach to programming language teaching
In a previous post I explained why I think developers don’t really know any computer language, and in this post I want to outline how I think we should adapt to this reality and radically change the approach taken to teaching students about using a computer language. First, a couple of points:
- The programming community needs to change its attitude towards language knowledge from being an end in itself to being something that is ok to acquire on an as needed basis. Developers don’t need to know much about the programming language they use in order to get their job done, get over it. Spending time learning the ins and outs of a language’s semantics rarely provides a worthwhile return on investment compared to time spent learning something else, such as the application domain or customer requirements,
- designing a new, ‘simpler’ programming language is not a solution; the existing languages in common use are not going away anytime soon and creating a new general purpose language is only going to overload developers with more stuff to learn and yet another runtime system to interface to,
- we need to concentrate on suggestions about what students and developers should be doing and not what they should not be doing. This is not only a good teaching principle it avoids the problem of having to come up with a good list of things not to do (coding standard recommendations are very rarely based on any evidence apart from the proposers own point of view and even the ones that make it through peer review are little more than group think or a waste of time).
The response to the existing state of affairs should be to approach the teaching of programming languages as an exercise in teaching students only what they need to know to do useful work, rather than acting on the belief that students should strive to be experts in the language they use and burdening them with lots of pointless language details. The exact minimum-set of knowledge could vary across different industries and application domains, so the set might need to be a bit larger than the minimum to be on the safe side.
Invariably some developers will need to know more than the minimum-set, so we also need to figure out what ‘template’ knowledge (or whatever term is used, an alternative is behavior patterns or patterns of behavior) should be included in the next level of language knowledge, this can be documented and made available to anybody who wants to read it; there may or may not be more levels before a developer is told to go and read a reference book or the language reference manual to figure out what they need to know.
This is minimum-set approach, with the opportunity to progress to successively more detailed levels, is often used for learning human languages, computer languages are not any different.
I would expect there to be some variation in the minimum-set between different languages, and would resist the temptation to try and create a ‘common minimum’ until some experience had been gained in teaching single languages.
How would the minimum-set of language knowledge be chosen? Simple. Students need to learn those construct they are likely to use most of the time, and that question can be answered by measuring a large amount of existing source code. Results from measurements that have been made typically show a small number of constructs are used a large percentage of the time. For instance, measurements of C source find that the 33.2% of for-loops have the form: for (assignment ; identifier < identifier ; identifier++), where identifier might be two or more different identifiers; allowing the central test to have the form identifier < expression takes the percentage to over 50%. I would expect the same pattern of usage to occur in source written in other languages but don't have any number to back up that assertion.
Perhaps the most important pattern of (developer) behavior is what its discoverer, Jorma Sajaniemi, calls the roles of variables (each variable is used to hold a particular kind of information, e.g., most wanted holder, stepper, container, etc).
One pattern of behavior that I am more or less completely in the dark about is class/package usage. There is the famous book on design patterns which the authors did a good job of promoting, but I have yet to see any empirical evidence showing the claimed benefits. The analysis of class/package behavioral usage is non-trivial, but it can be done.
Would I insist that developers only use constructs list in the suggested minimum-set (plus possible extras)? No. The purpose of this proposal is to help students and developers learn what they need to know to get a job done. Figuring out what language constructs, if any, should be avoided at all costs is a very tough problem which at the end of the day might not be worth solving.
A minimum-set knowledge of the language being used does not imply poor quality code. Most code is simple anyway, the complicated stuff invariably revolves around the algorithms that need to be used, and a skillful developer is one who uses straightforward language constructs to create easy to maintain code, not one who writes code that relies on detailed knowledge of some language feature.
I expect this proposal to adopt a minimum-set approach to language teaching will draw an angry reaction from the cottage industry that makes its living from writing and giving seminars on the latest trends in language-X. Don't panic guys, managers are well aware that this kind of knowledge rarely has any impact of developer performance and the actual motivation for sending employees on such seminars is to keep them happy (it can be a much more effective way of keeping staff than simply giving them a pay rise).
Agreement between code readability ratings given by students
I have previously written about how we know nothing about code readability and questioned how the information content of expressions might be calculated. Buse and Weimer ran a very interesting experiment that asked subjects to rate short code snippets for readability (somebody please rerun this experiment using professional software developers).
I’m interested in measuring how well different students subjects agree with each other (I have briefly written about this before).
Short answer: Very little agreement between individual pairs, good agreement between rankings aggregated by year.
The longer answer is below as another draft section from my book Empirical software engineering with R book. As always comments welcome. R code and data here.
Readability
Source code is often said to have an attribute known as
A study by Buse and Weimer <book Buse_08> asked Computer Science students to rate short snippets of Java source code on a scale of 1 to 5. Buse and Weimer then searched for correlations between these ratings and various source code attributes they obtained by measuring the snippets.
Humans hold diverse opinions, have fragmented knowledge and beliefs about many topics and vary in their cognitive abilities. Any study involving human evaluation that uses an open ended problem on which subjects have had little experience is likely to see a wide range of responses.
Readability is a very nebulous term and students are unlikely to have had much experience working with source code. A wide range of responses is to be expected and the analysis performed here aims to check the degree of readability rating agreement between the subjects.
Data
The data made available by Buse and Weimer are the ratings, on a scale of 1 to 5, given by 121 students to 100 snippets of source code. The student subjects were drawn from those taking first, second and third/fourth year Computer Science degree courses and postgraduates at the researchers’ University (17, 65, 31 and 8 subjects respectively).
The postgraduate data was not used in this analysis because of the small number of subjects.
The source of the code snippets is also available but not used in this analysis.
Is the data believable?
The subjects were not given any instructions on how to rate the code snippets for readability. Also we don’t know what outcome they were trying to achieve when rating, e.g., where they rating on the basis of how readable they personally found the snippets to be, or rating on the basis of the answer they would expect to give if they were being tested in an exam.
The subjects were students who are learning about software development and many of them are unlikely to have had any significant development experience outside of the teaching environment. Experience shows that students vary significantly in their ability to read and write source code and a non-trivial percentage do not go on to become software developers.
Because the subjects are at an early stage of learning about code it is to be expected that their opinions about readability will change while they are rating the 100 snippets. The study did not include multiple copies of some snippets, this would have enabled the consistency of individual subject responses to be estimated.
The results of many studies <book Annett_02> has shown that most subject ratings are based on an ordinal scale (i.e., there is no fixed relationship between the difference between a rating of 2 and 3 and a rating of 3 and 4), that some subjects are be overly generous or miserly in their rating and that without strict rating guidelines different subjects apply different criteria when making their judgements (which can result a subject providing a list of ratings that is inconsistent with every other subject).
Readability is one of those terms that developers use without having much idea what they and others are really referring to. The data from this study can at most be regarded as treating readability to be whatever each subject judges it to be.
Predictions made in advance
Is the readability rating given to code snippets consistent between different students on a computer science course?
The hypothesis is that the between student consistency of the readability rating given to code snippets improves as students progress through the years of attending computer science courses.
Applicable techniques
There are a variety of techniques for estimating rater agreement. <Krippendorff’s alpha> can be applied to ordinal ratings given by two or more raters and is used here.
Subjects do not have to give the same rating to share some degree of consistent response. Two subjects may share a similar pattern of increasing/decreasing/stay the same ratings across snippets. The <Spearman rank correlation> coefficient can be used to measure the correlation between the rank (i.e., relative value within sequence) of two sequences.
Results
When creating the snippets the researchers had no method of estimating what rating subjects would give to them and so there is no reason to expect a uniform distribution of rating values or any other kind of distribution of rating values.
The figure below is a boxplot of the rating of the first 50 code snippets rated by second year students and suggests that many subject ratings are within ±1 of each other.
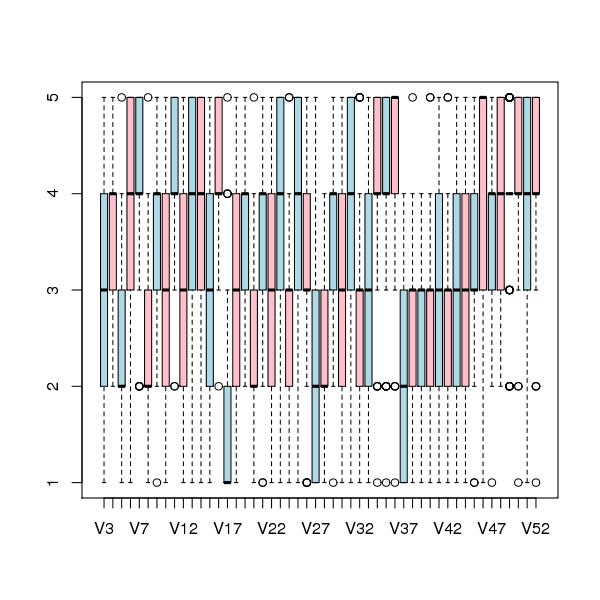
Figure 1. Boxplot of ratings given to snippets 1 to 50 by second year students (colors used to help distinguish boxplots for each snippet).
Between subject rating agreement
The Krippendorff alpha and mean Spearman rank correlation coefficient (the coefficient is calculated for every pair of subjects and the mean value taken) was obtained using the kripp.alpha and meanrho functions from the irr package (a <Jackknife> was used to obtain the following 95% confidence bounds):
Krippendorff's alpha cs1: 0.1225897 0.1483692 cs2: 0.2768906 0.2865904 cs4: 0.3245399 0.3405599 mean Spearman's rho cs1: 0.1844359 0.2167592 cs2: 0.3305273 0.3406769 cs4: 0.3651752 0.3813630 |
Taken as a whole there is a little of agreement. Perhaps there is greater consensus on the readability rating for a subset of the snippets. Recalculating using only using those snippets whose rated readability across all subjects, by year, has a standard deviation less than 1 (around 22, 51 and 62% of snippets respectively) shows some improvement in agreement:
Krippendorff's alpha cs1: 0.2139179 0.2493418 cs2: 0.3706919 0.3826060 cs4: 0.4386240 0.4542783 mean Spearman's rho cs1: 0.3033275 0.3485862 cs2: 0.4312944 0.4443740 cs4: 0.4868830 0.5034737 |
Between years comparison of ratings
The ratings from individual subjects is only available for one of their years at University. Aggregating the answers from all subjects in each year is one method of obtaining readability information that can be used to compare the opinions of students in different years.
How can subject ratings be aggregated to rank the 100 code snippets in order of what a combined group consider to be readability? The relatively large variation in mean value of the snippet ratings across subjects would result in wide confidence bounds for an aggregate based on ratings. Mapping each subject’s rating to a ranking removes the uncertainty caused by differences in mean subject ratings.
With 100 snippets assigned a rating between 1 and 5 by each subject there are going to be a lot of tied rankings. If, say, a subject gave 10 snippets a rating of 5 the procedure used is to assign them all the rank that is the mean of the ranks the 10 of them would have occupied if their ratings had been very slightly different, i.e., (1+2+3+4+5+6+7+8+9+10)/10 = 5.5. This process maps each students readability ratings to readability rankings, the next step is to aggregate these individual rankings.
The R_package[RankAggreg] package contains a variety of functions for aggregating a collection rankings to obtain a group ranking. However, these functions use the relative order of items in a vector to denote rank, and this form of data representations prevents them supporting ranked lists containing items having the same rank.
For this analysis a simple aggregate ranking algorithm using Borda’s method <book lin_10> was implemented. Borda’s method for creating an aggregate ranking operates on one item at a time, combining all of the subject ranks for that item into a single rank. Methods for combining ranks include taking their mean, their geometric mean and the square-root of the sum of their squares; the mean value was used for this analysis.
An aggregate ranking was created for subjects in years one, two and four and the plot below compares the ranking between 1st/2nd year students (left) and 2nd/4th year students (right). The order of the second year student snippet rankings have been sorted and the other year rankings for the snippets mapped to the corresponding position.
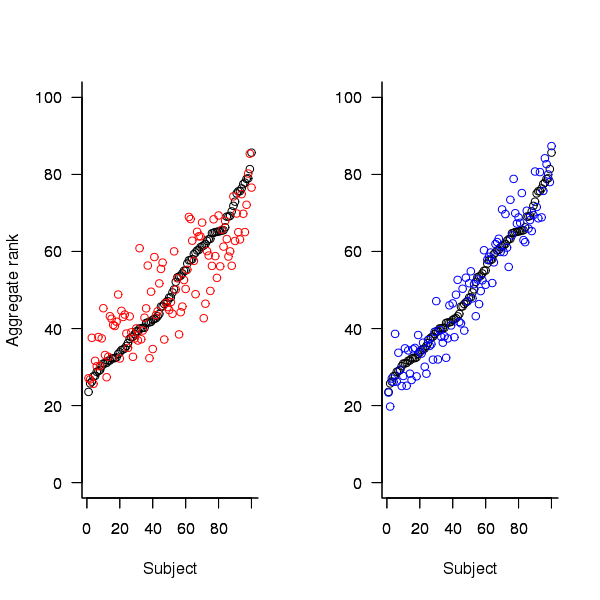
Figure 2. Aggregated ranking of snippets by subjects in years 1 and 2 (red and black) and years 2 and 4 (black and blue). Snippets have been sorted by year 2 ranking.
The above plot seems to show that at the aggregated year level there is much greater agreement between the 2nd/4th years than any other year pairing and measuring the correlation between each of the years using <Kendall’s tau>:
cs1.tau cs2.tau cs3.tau 0.6627602 0.6337914 0.8199636 |
confirms the greater agreement between this aggregate year pair.
Individual subject correlation to year aggregate ranking
To what extend to subject ratings correlate with their corresponding year aggregate? The following plot gives the correlation, using Kendall’s tau, between each subject and their corresponding year aggregate ranking.
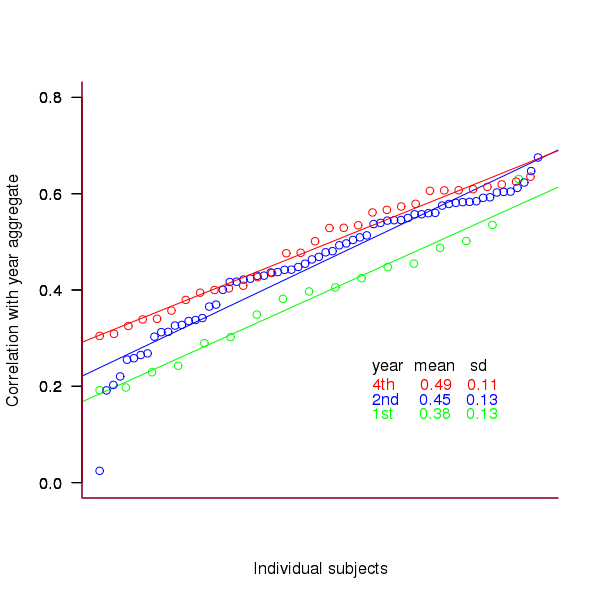
Figure 3. Correlation, using Kendall’s tau, between each subject and their corresponding year aggregate ranking.
The least squares fit shows that the variation in correlation across subjects in any year is very similar (removal of outliers in year 2 would make the lines almost parallel); the mean again shows a correlation that increases with year.
Discussion
The extent to which this study’s calculated values of rater agreement and correlation are considered worthy of further attention depends on the use to which the results will be put.
- From the perspective of trained raters the subject agreement in this study is very low and the rating have no further use.
- From the research perspective the results show that the concept of readability in the computer science student population has some non-zero substance to it that might be worth further study.
- From an overall perspective this study provides empirical evidence for a general lack of consensus on what constitutes readability.
It is not surprising that there is little agreement between student subjects on their readability rating, they are unlikely to have had much experience reading code and have not had any training in rating code for readability.
Professional developers will have spent years working with code and this experience is likely to have resulted in the creation of stable opinions on code readability. While developers usually work with code that is much longer than the few lines contained in the snippets used by Buse and Weimer, this experiment format is easy to administer and supports a fine level of control, i.e., allows a small set of source attributes of interest to be presented while excluding those not of interest. Repeating this study using such people as subjects would show whether this experience results in convergence to general agreement on the readability rating of code.
Summary of findings
The agreement between students readability ratings, for short snippets of code, improves as the students progress through course years 1 to 4 of a computer science degree.
While there is very good aggregated group agreement on the relative ranking of the readability of code snippets there is very little agreement between pairs of individuals.
- Two students chosen at random from within a year will have a low Spearman rank correlation coefficient for their rating of code snippet readability.
- Taken as a yearly aggregate there is a high degree of agreement between years two and four and less, but still good agreement between year 1 and other years.
- There is a broad range of correlations, from poor to good, between year aggregates and student subjects in the corresponding year.
Teach children planning and problem solving not programming
When I first heard that children in secondary education (11-16 year olds) here in the UK were to be taught programming I thought it was another example of a poorly thought through fad ruining our education system. Schools already have enough trouble finding goos maths and science teachers, and the average school leavers knowledge of these subjects is not that great, now resources and time are being diverted to a specialist subject for which it is hard to find good teachers. After talking to a teacher about his experience teaching Scratch to 11-13 year olds I realised he was not teaching programming but teaching how to think through problems, breaking them down into subcomponents and cover all possibilities; a very worthwhile subject to teach.
As I see it the ‘writing code’ subject needs to be positioned as the teaching of planning and problem solving skills (ppss, p2s2, a suitable acronym is needed) rather than programming. Based on a few short conversations with those involved in teaching, the following are a few points I would make:
- Stay with one language (Scratch looks excellent).
- The more practice students get with a language the more fluent they become, giving them more time to spend solving the problem rather than figuring out how to use the language.
- Switching to a more ‘serious’ language because it is similar to what professional programmers use is a failure to understand the purpose of what is being taught and a misunderstanding of why professionals still use ‘text’ based languages (because computer input has historically been via a keyboard and not a touch sensitive screen; I expect professional programmers will slowly migrate over to touch screen programming languages).
- Give students large problems to solve (large as in requiring lots of code). Small programs are easy to hold in your head, where the size of small depends on intellectual capacity; the small program level of coding is all about logic. Large programs cannot be held in the head and this level of coding is all about structure and narrative (there are people who can hold very large programs in their head and never learn the importance of breaking things down so others can understand them), logic does not really appear at this level. Large problems can be revisited six months later; there is no better way of teaching the importance of making things easy for others to understand than getting a student to modify one of their own programs a long time after they originally wrote it (I’m sure many will start out denying ever having written the horrible code handed back to them).
- Problems should not be algorithms. Yes, technically all programs are algorithms but most are not mathematical algorithms in the sense that, say, sorting and searching are, real life problems are messy things that involve lots of simple checks for various conditions and ad-hoc approaches to solving a problem. Teachers should resist mapping computing problems to the Scratch domain, e.g., tree walking algorithms mapped to walking the branches of a graphical tree or visiting all parts of a maze.
Readability, an experimental view
Readability is an attribute that source code is often claimed to have, but what is it? While people are happy to use the term they have great difficulty in defining exactly what it is (I will eventually get around discussing my own own views in post). Ray Buse took a very simply approach to answering this question, he asked lots of people (to be exact 120 students) to rate short snippets of code and analysed the results. Like all good researchers he made his data available to others. This posting discusses my thoughts on the expected results and some analysis of the results.
The subjects were first, second, third year undergraduates and postgraduates. I would not expect first year students to know anything and for their results to be essentially random. Over the years, as they gain more experience, I would expect individual views on what constitutes readability to stabilize. The input from friends, teachers, books and web pages might be expected to create some degree of agreement between different students’ view of what constitutes readability. I’m not saying that this common view is correct or bears any relationship to views held by other groups of people, only that there might be some degree of convergence within a group of people studying together.
Readability is not something that students can be expected to have explicitly studied (I’m assuming that it plays an insignificant part in any course marks), so their knowledge of it is implicit. Some students will enjoy writing code and spends lots of time doing it while (many) others will not.
Separating out the data by year the results for first year students look like a normal distribution with a slight bulge on one side (created using plot(density(1_to_5_rating_data)) in R).
year by year this bulge turns (second year):
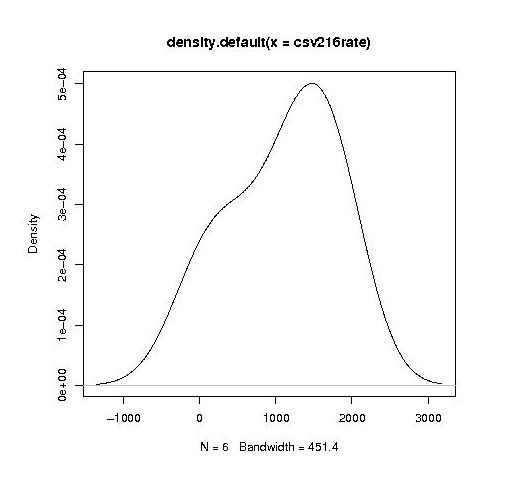
into a hillock (final year):
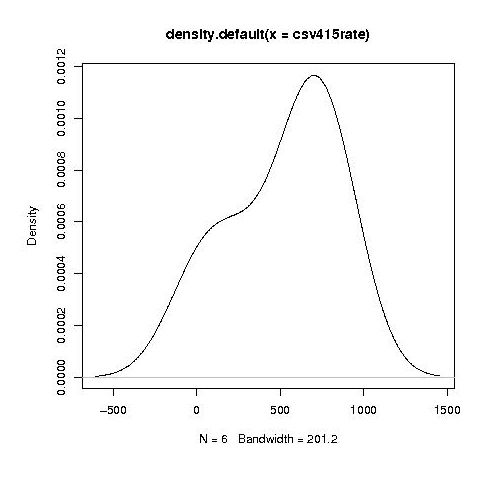
It is tempting to interpret these results as the majority of students assigning an essentially random rating, with a slight positive bias, for the readability of each snippet, with a growing number of more experienced students assigning less than average rating to some snippets.
Do the student’s view converge to a common opinion on readability? The answers appears to be No. An analysis of the final year data using Fleiss’s Kappa shows that there is virtually no agreement between students ratings. In fact every Interrater Reliability and Agreement function I tried said the same thing. Some cluster analysis might enable me to locate students holding similar views.
In an email exchange with Ray Buse I learned that the postgraduate students had a relatively wide range of computing expertise, so I did not analyse their results.
I wish I had thought of this approach to measuring readability. Its simplicity makes it amenable for use in a wide range of experimental situations. The one change I would make is that I would explicitly create the snippets to have certain properties, rather than randomly extracting them from existing source.
Recent Comments