Archive
Student projects for 2024/2025
It will soon be that time of year when university students are looking for an interesting idea for a project. On an irregular basis, I post some ideas for thesis projects (here and here); primarily for students studying computing. In a change of direction, this post suggests software related ideas for business student projects.
Two idea areas require data analysis skills, one requires people skills, and one an interest in theory.
More suggestions welcome in the comments.
Career paths in software
Organizations employ people to work on software systems. What is the career path of people who work on software systems? Question include: how long people stay in a particular job or company, and salary changes over time (the only data I know of investigates the career paths of 500 people working in IT).
Governments are interested in employment, and they collect and publish data at various levels of granularity. The US Bureau of Labor Statistics contains a vast amount of information, but finding the bits of interest can require a lot of work.
In the US, government employee salary is public information, and various sites make this available, e.g., OpePayrolls and Transparent California. There is a Japanese Open Salaries, and various commercial companies operate an open salary policy (Buffer is perhaps the most famous).
This project requires students with some data analysis skills.
There is some data on job postings,
Computer company lifecycle
Companies are born, do business and eventually die (unless bought/merged). How do the lifecycle characteristics of computer companies differ from companies doing business in other domains? Lifecycle characteristics of interest might include profiles of age, number of employees, and profitability. What are the consequences, if any, of these differences?
Details of all UK registered companies are freely available from Companies House.
Open Corporates provides company information from across the world, but it is not free in bulk.
Some analysis of the geographical clustering of software companies in the UK.
This project requires students with some data analysis skills.
AI startup ecosystem
AI has exploded on the tech scene, and lots of people are creating startups to build services/products around LLMs. Teams are very fluid, with people moving around a lot looking for a viable service/product. Sometimes these teams form companies, and these might eventually leave stealth mode and become visible. What are the characteristics of the AI startup ecosystem within a city; questions include: how many people are working within it, their backgrounds, and the business areas are they focusing on?
This project requires students with people skills and a willingness to get out and about. Much of the current AI ecosystem is only visible to those within it. Evening meetups and workshops offer a way into this personal network. This research involves bootstrapping the data gathering by spending evenings schmoozing with founders and their new hires, and is probably only practical in major cities with a very active tech meeting scene.
An analysis of a Dutch software business network.
Theoretical analysis
Those with an interest in theory might like to analyse cost-benefit decision-making within software development. Examples of simple analysis+supporting data include:
Analysis of when refactoring becomes cost-effective, and Cost-effectiveness decision for fixing a known coding mistake, and Break even ratios for development investment decisions
A paper to forget about
Papers describing vacuous research results get published all the time. Sometimes they get accepted at premier conferences, such as ICSE, and sometimes they even win a distinguished paper award, such as this one appearing at ICSE 2024.
If the paper Breaking the Flow: A Study of Interruptions During Software Engineering Activities had been produced by a final year PhD student, my criticism of them would be scathing. However, it was written by an undergraduate student, Yimeng Ma, who has just started work on a Masters. This is an impressive piece of work from an undergraduate.
The main reasons I am impressed by this paper as the work of an undergraduate, but would be very derisive of it as a work of a final year PhD student are:
- effort: it takes a surprisingly large amount of time to organise and run an experiment. Undergraduates typically have a few months for their thesis project, while PhD students have a few years,
- figuring stuff out: designing an experiment to test a hypothesis using a relatively short amount of subject time, recruiting enough subjects, the mechanics of running an experiment, gathering the data and then analysing it. An effective experimental design looks very simply, but often takes a lot of trial and error to create; it’s a very specific skill set that takes time to acquire. Professors often use students who attend one of their classes, but undergraduates have no such luxury, they need to be resourceful and determined,
- data analysis: the data analysis uses the appropriate modern technique for analyzing this kind of experimental data, i.e., a random effects model. Nearly all academic researchers in software engineering fail to use this technique; most continue to follow the herd and use simplistic techniques. I imagine that Yimeng Ma simply looked up the appropriate technique on a statistics website and went with it, rather than experiencing social pressure to do what everybody else does,
- writing a paper: the paper is well written and the style looks correct (I’m not an expert on ICSE paper style). Every field converges on a common style for writing papers, and there are substyles for major conferences. Getting the style correct is an important component of getting a paper accepted at a particular conference. I suspect that the paper’s other two authors played a major role in getting the style correct; or, perhaps there is now a language model tuned to writing papers for the major software conferences.
Why was this paper accepted at ICSE?
The paper is well written, covers a subject of general interest, involves an experiment, and discusses the results numerically (and very positively, which every other paper does, irrespective of their values).
The paper leaves out many of the details needed to understand what is going on. Those who volunteer their time to review papers submitted to a conference are flooded with a lot of work that has to be completed relatively quickly, i.e., before the published paper acceptance date. Anybody who has not run experiments (probably a large percentage of reviewers), and doesn’t know how to analyse data using non-simplistic techniques (probably most reviewers) are not going to be able to get a handle on the (unsurprising) results in this paper.
The authors got lucky by not being assigned reviewers who noticed that it’s to be expected that more time will be needed for a 3-minute task when the subject experiences an on-screen interruption, and even more time when for an in-person interruption, or that the p-values in the last column of Table 3 (0.0053, 0.3522, 0.6747) highlight the meaningless of the ‘interesting’ numbers listed
In a year or two, Yimeng Ma will be embarrassed by the mistakes in this paper. Everybody makes mistakes when they are starting out, but few get to make them in a paper that wins an award at a major conference. Let’s forget this paper.
Those interested in task interruption might like to read (unfortunately, only a tiny fraction of the data is publicly available): Task Interruption in Software Development Projects: What Makes some Interruptions More Disruptive than Others?
Research ideas for 2023/2024
Students sometimes ask me for suggestions of interesting research problems in software engineering. A summary of my two recurring suggestions, for this year, appears below; 2016/2017 and 2019/2020 versions.
How many active users does a program or application have?
The greater the number of users, the greater the number of reported faults. Estimates of program reliability have to include volume of usage as an integral part of the calculation.
Non-trivial amounts of public data on program usage is non-existent (in a few commercial environments, users are charged for using software on a per-usage basis, but this data is confidential). Usage has to be estimated by indirect means.
A popular indirect technique for estimating the popularity of Github repos is to count the number of stars it has; however, stars have a variety of interpretations. The extent to which Github stars tracks usage of the repo’s software is not known.
Other indirect techniques include: web server logs, installs of the application, or the operating system.
One technique that has not yet been researched is to make use of the identity of those reporting faults. A parallel can be drawn with the fish population in lakes, which is not directly visible. Ecologists have developed techniques for indirectly estimating the population size of distinct creatures using information about a subset of the population, and some of the population models developed for ecology can be adapted to estimating program user populations.
Estimates of population size can be obtained by plugging information on the number of different people reporting faults, and the number of reports from the same person into these models. This approach is not as easy as it sounds because sometimes the same person has multiple identities, reported faults also need to be deduplicated and cleaned (30-40% of reports have been found to be requests for enhancements).
Nested if-statement execution
As if-statement nesting depth increases, the number of conditions controlling the execution of the enclosed code increases.
Being able to estimate the likelihood of executing the code controlled by an if-statement is of interest to: compilers wanting to target optimizations along the most frequently executed paths, special handling for error paths, testing along the least/most likely paths (e.g., fuzzers wanting to know the conditions needed to reach a given block), those wanting to organize code for ease of understanding, by reducing cognitive effort to understand.
Possible techniques for analysing the likelihood of executing code controlled by one or more nested if-statements include:
- Compiler writers have discovered various heuristics for predicting the likely outcome of a branch, and there are probably more to be discovered. Statement coverage counts provides a ground truth against which to compare ideas,
- analysis of the conditional expression,
- mathematical analysis of the distribution of values of variables in conditional expressions.
Estimation experiments: specification wording is mostly irrelevant
Existing software effort estimation datasets provide information about estimates made within particular development environments and with particular aims. Experiments provide a mechanism for obtaining information about estimates made under conditions of the experimenters choice, at least in theory.
Writing the code is sometimes the least time-consuming part of implementing a requirement. At hackathons, my default estimate for almost any non-trivial requirement is a couple of hours, because my implementation strategy is to find the relevant library or package and write some glue code around it. In a heavily bureaucratic organization, the coding time might be a rounding error in the time taken up by meeting, documentation and testing; so a couple of months would be considered normal.
If we concentrate on the time taken to implement the requirements in code, then estimation time and implementation time will depend on prior experience. I know that I can implement a lexer for a programming language in half-a-day, because I have done it so many times before; other people take a lot longer because they have not had the amount of practice I have had on this one task. I’m sure there are lots of tasks that would take me many days, but there is somebody who can implement them in half-a-day (because they have had lots of practice).
Given the possibility of a large variation in actual implementation times, large variations in estimates should not be surprising. Does the possibility of large variability in subject responses mean that estimation experiments have little value?
I think that estimation experiments can provide interesting information, as long as we drop the pretence that the answers given by subjects have any causal connection to the wording that appears in the task specifications they are asked to estimate.
If we assume that none of the subjects is sufficiently expert in any of the experimental tasks specified to realistically give a plausible answer, then answers must be driven by non-specification issues, e.g., the answer the client wants to hear, a value that is defensible, a round number.
A study by Lucas Gren and Richard Berntsson Svensson asked subjects to estimate the total implementation time of a list of tasks. I usually ignore software engineering experiments that use student subjects (this study eventually included professional developers), but treating the experiment as one involving social processes, rather than technical software know-how, makes subject software experience a lot less relevant.
Assume, dear reader, that you took part in this experiment, saw a list of requirements that sounded plausible, and were then asked to estimate implementation time in weeks. What estimate would you give? I would have thrown my hands up in frustration and might have answered 0.1 weeks (i.e., a few hours). I expected the most common answer to be 4 weeks (the number of weeks in a month), but it turned out to be 5 (a very ‘attractive’ round number), for student subjects (code+data).
The professional subjects appeared to be from large organizations, who I assume are used to implementations including plenty of bureaucratic stuff, as well as coding. The task specification did not include enough detailed information to create an accurate estimate, so subjects either assumed their own work environment or played along with the fresh-faced, keen experimenter (sorry Lucas). The professionals showed greater agreement in that the range of value given was not as wide as students, but it had a more uniform distribution (with maximums, rather than peaks, at 4 and 7); see below. I suspect that answers at the high end were from managers and designers with minimal coding experience.
What did the experimenters choose weeks as the unit of estimation? Perhaps they thought this expressed a reasonable implementation time (it probably is if it’s not possible to use somebody else’s library/package). I think that they could have chosen day units and gotten essentially the same results (at least for student subjects). If they had chosen hours as the estimation unit, the spread of answers would have been wider, and I’m not sure whether to bet on 7 (hours in a working day) or 10 being the most common choice.
Fitting a regression model to the student data shows estimates increasing by 0.4 weeks per year of degree progression. I was initially baffled by this, and then I realized that more experienced students expect to be given tougher problems to solve, i.e., this increase is based on self-image (code+data).
The stated hypothesis investigated by the study involved none of the above. Rather, the intent was to measure the impact of obsolete requirements on estimates. Subjects were randomly divided into three groups, with each seeing and estimating one specification. One specification contained four tasks (A), one contained five tasks (B), and one contained the same tasks as (A) plus an additional task followed by the sentence: “Please note that R5 should NOT be implemented” (C).
A regression model shows that for students and professions the estimate for (A) is about 1-2 weeks lower than (B), while (A) estimates are 3-5 weeks lower than (C) estimated.
What are subjects to make of an experimental situation where the specification includes a task that they are explicitly told to ignore?
How would you react? My first thought was that the ignore R5 sentence was itself ignored, either accidentally or on purpose. But my main thought is that Relevance theory is a complicated subject, and we are a very long way away from applying it to estimation experiments containing supposedly redundant information.
The plot below shows the number of subjects making a given estimate, in days; exp0to2 were student subjects (dashed line joins estimate that include a half-hour value, solid line whole hour), exp3 MSc students, and exp4 professional developers (code+data):
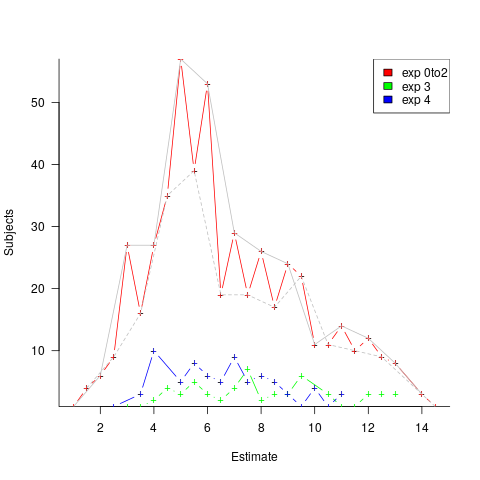
I hope that the authors of this study run more experiments, ideally working on the assumption that there is no connection between specification and estimate (apart from trivial examples).
Student projects for 2019/2020
It’s that time of year when students are looking for an interesting idea for a project (it might be a bit late for this year’s students, but I have been mulling over these ideas for a while, and might forget them by next year). A few years ago I listed some suggestions for student projects, as far as I know none got used, so let’s try again…
Checking the correctness of the Python compilers/interpreters. Lots of work has been done checking C compilers (e.g., Csmith), but I cannot find any serious work that has done the same for Python. There are multiple Python implementations, so it would be possible to do differential testing, another possibility is to fuzz test one or more compiler/interpreter and see how many crashes occur (the likely number of remaining fault producing crashes can be estimated from this data).
Talking to the Python people at the Open Source hackathon yesterday, testing of the compiler/interpreter was something they did not spend much time thinking about (yes, they run regression tests, but that seemed to be it).
Finding faults in published papers. There are tools that scan source code for use of suspect constructs, and there are various ways in which the contents of a published paper could be checked.
Possible checks include (apart from grammar checking):
- incorrect or inaccurate numeric literals.
Checking whether the suspect formula is used is another possibility, provided the formula involved contains known constants.
- inconsistent statistics reported (e.g., “8 subjects aged between 18-25, average age 21.3″ may be correct because 21.3*8 == 170.4, ages must add to a whole number and the values 169, 170 and 171 would not produce this average), and various tools are available (e.g., GRIMMER).
Citation errors are relatively common, but hard to check automatically without a good database (I have found that a failure of a Google search to return any results is a very good indicator that the reference does not exist).
There are lots of tools available for taking pdf files apart; I use pdfgrep a lot
Number extraction. Numbers are some of the most easily checked quantities, and anybody interested in fact checking needs a quick way of extracting numeric values from a document. Sometimes numeric values appear as numeric words, and dates can appear as a mixture of words and numbers. Extracting numeric values, and their possible types (e.g., date, time, miles, kilograms, lines of code). Something way more sophisticated than pattern matching on sequences of digit characters is needed.
spaCy is my tool of choice for this sort of text processing task.
Students vs. professionals in software engineering experiments
Experiments are an essential component of any engineering discipline. When the experiments involve people, as subjects in the experiment, it is crucial that the subjects are representative of the population of interest.
Academic researchers have easy access to students, but find it difficult to recruit professional developers, as subjects.
If the intent is to generalize the results of an experiment to the population of students, then using student as subjects sounds reasonable.
If the intent is to generalize the results of an experiment to the population of professional software developers, then using student as subjects is questionable.
What it is about students that makes them likely to be very poor subjects, to use in experiments designed to learn about the behavior and performance of professional software developers?
The difference between students and professionals is practice and experience. Professionals have spent many thousands of hours writing code, attending meetings discussing the development of software; they have many more experiences of the activities that occur during software development.
The hours of practice reading and writing code gives professional developers a fluency that enables them to concentrate on the problem being solved, not on technical coding details. Yes, there are students who have this level of fluency, but most have not spent the many hours of practice needed to achieve it.
Experience gives professional developers insight into what is unlikely to work and what may work. Without experience students have no way of evaluating the first idea that pops into their head, or a situation presented to them in an experiment.
People working in industry are well aware of the difference between students and professional developers. Every year a fresh batch of graduates start work in industry. The difference between a new graduate and one with a few years experience is apparent for all to see. And no, Masters and PhD students are often not much better and in some cases worse (their prolonged sojourn in academia means that have had more opportunity to pick up impractical habits).
It’s no wonder that people in industry laugh when they hear about the results from experiments based on student subjects.
Just because somebody has “software development” in their job title does not automatically make they an appropriate subject for an experiment targeting professional developers. There are plenty of managers with people skills and minimal technical skills (sub-student level in some cases)
In the software related experiments I have run, subjects were asked how many lines of code they had read/written. The low values started at 25,000 lines. The intent was for the results of the experiments to be generalized to the population of people who regularly wrote code.
Psychology journals are filled with experimental papers that used students as subjects. The intent is to generalize the results to the general population. It has been argued that students are not representative of the general population in that they have spent more time reading, writing and reasoning than most people. These subjects have been labeled as WEIRD.
I spend a lot of time reading software engineering papers. If a paper involves human subjects, the first thing I do is find out whether the subjects were students (usual) or professional developers (not common). Authors sometimes put effort into dressing up their student subjects as having professional experience (perhaps some of them have spent a year or two in industry, but talking to the authors often reveals that the professional experience was tutoring other students), others say almost nothing about the identity of the subjects. Papers describing experiments using professional developers, trumpet this fact in the abstract and throughout the paper.
I usually delete any paper using student subjects, some of the better ones are kept in a subdirectory called students.
Software engineering researchers are currently going through another bout of hand wringing over the use of student subjects. One paper makes the point that a student based experiment is a good way of validating an experiment that will later involve professional developers. This is a good point, but ignored the problem that researchers rarely move on to using professional subjects; many researchers only ever intend to run student-based experiments. Also, they publish the results from the student based experiment, which are at best misleading (but academics get credit for publishing papers, not for the content of the papers).
Researchers are complaining that reviews are rejecting their papers on student based experiments. I’m pleased to hear that reviewers are rejecting these papers.
Signaling cognitive firepower as a software developer
Female Peacock mate selection is driven by the number of ‘eyes’ in the tail of the available males; the more the better. Supporting a large fancy tail is biologically expensive for the male and so tail quality is a reliable signal of reproductive fitness.
A university degree used to be a reliable signal of the cognitive firepower of its owner, a quality of interest to employers looking to fill jobs that required such firepower.
Some time ago, the UK government expressed the desire for 50% of the population to attend university (when I went to university the figure was around 5%). These days, a university degree is a signal of being desperate for a job to start paying off a large debt and having an IQ in the top 50% of the population. Dumbing down is the elephant in the room.
The idea behind shifting the payment of tuition fees from the state to the student, was that as paying customers students would somehow actively ensure that universities taught stuff that was useful for getting a job. In my day, lecturers laughed when students asked them about the relevance of the material being taught to working in industry; those that persisted had their motives for attending university questioned. I’m not sure that the material taught these days is any more relevant to industry than it was in my day, but students don’t get laughed at (at least not to their face) and there is more engagement.
What could universities teach that is useful in industry? For some subjects the possible subject matter can at least be delineated (e.g., becoming a doctor), while for others a good knowledge of what is currently known about how the universe works and a familiarity with some of the maths involved is the most that can sensibly be covered in three years (when the final job of the student is unknown).
Software development related jobs often prize knowledge of the application domain above knowledge that might be learned on a computing degree, e.g., accounting knowledge when developing software for accounting systems, chemistry knowledge when working on chemical engineering software, and so on. Employers don’t want to employ people who are going to spend all their time working on the kind of issues their computing lecturers have taught them to be concerned about.
Despite the hype, computing does not appear to be as popular as other STEM subjects. I don’t see this as a problem.
With universities falling over themselves to award computing degrees to anybody who can pay and is willing to sit around for three years, how can employers separate the wheat from the chaff?
Asking a potential employee to solve a simple coding problem is a remarkably effective filter. By simple, I mean something that can be coded in 10 lines or so (e.g., read in two numbers and print their sum). There is no need to require any knowledge of fancy algorithms, the wheat/chaff division is very sharp.
The secret is to ask them to solve the problem in their head and then speak the code (or, more often than not, say it as the solution is coded in their head, with the usual edits, etc).
Student projects for 2016/2017
This is the time of year when students have to come up with an idea for their degree project. I thought I would suggest a few interesting ideas related to software engineering.
- The rise and fall of software engineering myths. For many years a lot of people (incorrectly) believed that there existed a 25-to-1 performance gap between the best/worst software developers (its actually around 5 to 1). In 1999 Lutz Prechelt wrote a report explaining out how this myth came about (somebody misinterpreted values in two tables and this misinterpretation caught on to become the dominant meme).
Is the 25-to-1 myth still going strong or is it dying out? Can anything be done to replace it with something closer to reality?
One of the constants used in the COCOMO effort estimation model is badly wrong. Has anybody else noticed this?
- Software engineering papers often contain trivial mathematical mistakes; these can be caused by cut and paste errors or mistakenly using the values from one study in calculations for another study. Simply consistency checks can be used to catch a surprising number of mistakes, e.g., the quote “8 subjects aged between 18-25, average age 21.3” may be correct because 21.3*8 == 170.4, ages must add to a whole number and the values 169, 170 and 171 would not produce this average.
The Psychologies are already on the case of Content Mining Psychology Articles for Statistical Test Results and there is a tool, statcheck, for automating some of the checks.
What checks would be useful for software engineering papers? There are tools available for taking pdf files apart, e.g., qpdf, pdfgrep and extracting table contents.
- What bit manipulation algorithms does a program use? One way of finding out is to look at the hexadecimal literals in the source code. For instance, source containing
0x33333333,0x55555555,0x0F0F0F0Fand0x0000003Fin close proximity is likely to be counting the number of bits that are set, in a 32 bit value.Jörg Arndt has a great collection of bit twiddling algorithms from which hex values can be extracted. The numbers tool used a database of floating-point values to try and figure out what numeric algorithms source contains; I’m sure there are better algorithms for figuring this stuff out, given the available data.
Feel free to add suggestions in the comments.
Joke: Student subjects in software engineering experiments
Most academic experiments in software engineering use the students available to the researcher as subjects, often classifying first year as novices and final year or postgrads as experts. If professional developers (i.e., non-student) subjects are used the paper will trumpet this fact; talk of comparing novices and experts is the give-away for an all undergraduate subject line-up. Most computing academics don’t write much software, so they are blissfully ignorant that they and their students are novices compared to a professional developer with a couple of years experience.
Results from well designed and executed experiments can reasonably be extended to cover people who share the skills used by subjects in the experiment. Becoming an expert programmer takes several years of continuous (i.e., several hours a day) practice. Using real experts in a programming experiment means that no measurable change in programming skill will occur during the experiment, while novices are likely to noticeably learn during the experiment and thus introduce unwanted sources of variation into the results. Of course novices will also take longer and are likely to have patterns of behavior that are not yet been selectively tuned to something that works in practice.
There is also an elephant in the room of student subjects in software engineering; some of the students are never going to get jobs in software engineering because they are completely useless at it. How does a student manage to get a degree in a software related subject and be unemployable as a software engineer? Money. Students are attracted by the money and lifestyle they hear a job in software engineering will offer and many Universities are happy to treat the computing department as a cash cow by offering courses that allow students to concentrate on “strategic” subjects and avoid having to get involved in nitty gritty details like programming. The University is probably defrauding some students by accepting them for a software related degree course.
My experience is that professional developers are happy to donate some time to taking part in a software engineering experiment. They just have to be asked, of course I do have the advantage of actually knowing some professional software developers.
Halstead’s metrics and flat-Earthers are still with us
I recently discovered a fascinating series of technical reports from the 1970s in the Purdue University e-Pubs archive that shine a surprising light on what are now known as the Halstead metrics.
The first surprises came from Halstead’s A Software Physics Analysis of Akiyama’s Debugging Data; surprising in the size of the data set used (nine measurements of four attributes), the amount of hand waving used to pluck numbers out of thin air, the substantial difference between the counting methods used then and now and the very high correlation found between various measured and calculated attributes.
I disagreed with the numbers Halstead plucked and wrote some R to check Halstead’s results and try out my own numbers. While my numbers significantly changed the effort estimation values, the high correlations between the number of faults and various source attributes remained high. Even changing from the Pearson correlation coefficient (calculating confidence bounds for this coefficient requires that the data be normally distributed, which it is not {program size is now thought to follow a power law/exponential like distribution}) to the Spearman rank correlation coefficient did not have much impact. Halstead seems to have struck luck with this data set.
What did Halstead’s colleagues at Purdue think of these metrics? The report Software Science Revisited: A Critical Analysis of the Theory and Its Empirical Support written four years after Halstead’s flurry of papers contains a lot of background material and points out the lack of any theoretical foundation for some of the equations, that the analysis of the data was weak and that a more thorough analysis suggests theory and data don’t agree. Damming stuff.
If it is known that Halstead’s metrics do not hold up why do writers of books (including Shen, Conte and Dunsmore, the authors of the above report) continue to discuss Halstead’s work? Are they treating this work like Astronomy authors treat Ptolemy’s theory (the Sun and planets revolved around the Earth), i.e., incorrect but part of history and worth a mention?
An observation in the Shen et al report, that Halstead originally proposed the metrics as a way of measuring the complexity of algorithms not programs, explains the background to the report Impurities Found in Algorithm Implementations. Halstead uses the term “impurities” and talks about the need for “purification” in his early work. In this report Halstead points out that the value of metrics for “algorithms written by students” are very different from those for the equivalent programs published in journals and goes on to list eight classes of impurity that need to be purified (i.e., removing or rewriting clumsy, inefficient or duplicate code) in order to obtain results that agree with the theory. Now we know what needs to be done to existing programs to get them to agree with the predictions made by the Halstead metrics!
Did Halstead strike lucky with the data used in his first published analysis of ‘industrial code’, obtaining a very high correlation that caused him to shift focus away from measuring algorithms to measuring programs? Unfortunately, he died soon after publishing the work for which he is now known, so he did not get to comment on how his ideas were used over the subsequent years.
Why are people still attracted to the Halstead metrics, given their poor theoretical foundations and a predictive power that is comparable with using lines of code? Is it because the idea of code volume and length are easy to understand and so are attractive (dimensionally, both of these metrics are the same, a fact that cannot hold for any self-consistent concept of volume and length)? Is it because we don’t have alternative metrics that outperform the poorly performing ones proposed by Halstead, after all Copernicus only won out because his theory gave answers that were more accurate than Ptolomy’s.
Perhaps like the flat Earthers proponents of the Halstead metrics will always be with us.
Recent Comments