Archive
Why did organizations fund the creation of the first computers?
What were the events that drove organizations to fund the creation of the first computers?
I suspect that many readers do not appreciate how long scientific/engineering calculations took before electronic computers became available, or the huge number of clerical staff employed to process the paperwork associated with running any sizeable business.
If somebody wanted to know the logarithm of some value, or the sine/cosine of an angle, they looked up the answer in a table. Individuals owned small booklets of tables supplying some level of granularity and number of significant digits. My school boy booklet contains 60-pages of tables, all to five digits of output accuracy, with logarithm supporting four-digit input values and the sine/cosine/tangent tables having an input granularity of hundredth of a degree.
The values in these tables were calculated by human computers; with the following being among the most well known (for more details, see Calculation and Tabulation in the Nineteenth Century: Airy versus Babbage by Doron Swade, and The History of Mathematical Tables: from Sumer to Spreadsheets edited by Campbell-Kelly, Croarken, Flood, and Robson):
- In 1624 Henry Briggs published logarithms for the integer ranges 1-20,000 and 90,001-100,000 (to 14 decimal places), followed some years later by tables of sine and logarithm of sine; in 1628 Adriaan Vlacq publishing tables that filled in the missing values (to 10 decimal places). In 1783 Jurij Vega published a bug-fixed and extended version of Vlacq’s tables.
In 1827 Charles Babbage (that Babbage) published Table of Logarithms of the Natural Numbers from 1 to 10800. These tables were based on corrected versions of these tables, a rigorous nine-stage proofreading process was followed to prevent new mistakes creeping in.
Today, one person can publish A reconstruction of the tables of Briggs’ Arithmetica logarithmica (1624), with an appendix containing 300 pages of calculated values,
- between 1794 and 1799, Gaspard de Prony employed sixty to eighty computers to calculate the logarithms of the integers from 1 to 200,000 to fifteen significant digits (rounding issues sometimes required calculating 25 decimal digits; published in eighteen volumes). Around 400 man-years.
Logarithms and trigonometric functions are very widely used, creating incentives for investing in calculating and publishing tables. While it may be financially worthwhile investing in producing tables for some niche markets (e.g. Life tables for insurance companies), there is an unmet demand that will only be filled by a dramatic drop in the cost of computing simple expressions.
Babbage’s Difference engine was designed to evaluate polynomial expressions and print the results; perfect for publishing tables. While Babbage did not build a Difference engine, starting in 1837, engines based on Babbage’s design were built and sold commercially by the Swede Per Georg Scheutz.
Mechanical calculators improve accuracy and speed the process up. Vacuum tubes are invented in 1904 and become widely used to process analogue signals. World War II created an urgent demand for the results of a variety of time-consuming calculations, e.g., accurate ballistic tables, and valve computers were built. The plot below shows the cost per million operations for manual, mechanical and valve computers (code+data):
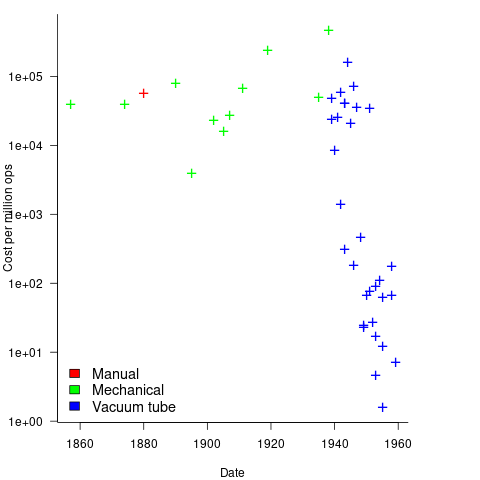
To many observers at the start of the 1950s, the market for electronic computers appeared to be organizations who needed to perform large amounts of scientific/engineering calculation.
Most businesses perform simple calculations on many unrelated values, e.g., banks have to credit/debit the appropriate account when money is deposited/withdrawn. There is no benefit in having a machine that can perform hundreds of calculations per second unless it can be fed data fast enough to keep it busy.
It so happened that, at the start of the 1950s, the US banking system was facing a crisis, the growth in the number of cheques being written meant that it would soon take longer than one day to process all the cheques that arrived in one day. In 1950 Bank of America managed 4.6 million checking accounts, and were opening 23,000 new account per month. Bank of America was then the largest bank in the world, and had a keen interest in continued growth. They funded the development of a bespoke computer system for processing cheques, the ERMA Banking system, which went live in 1959. The plot below shows the number of cheques processed per year by US banks (code+data):
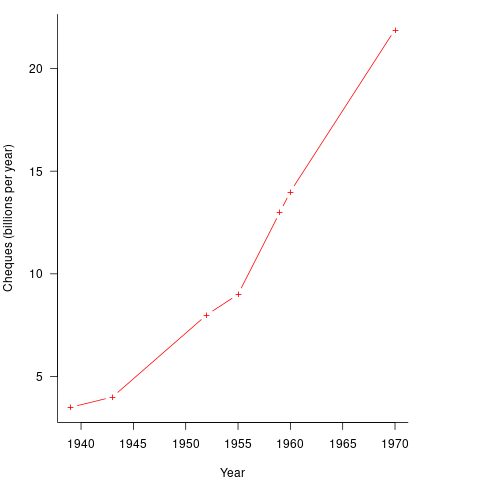
The ERMA system included electronic storage for holding account details, and data entry was speeded up by encoding account details on a magnetic strip included within every cheque.
Businesses are very interested in an integrated combination of input devices plus electronic storage plus compute. There are more commerce oriented businesses than scientific/engineering businesses, and commercial businesses usually have a lot more money to spend, i.e., the real money to be made by selling computers was the business data processing market.
The plot below shows the decreasing cost of hard disc storage (blue, right axis), along with the decreasing computing cost of valve based computers (red, left axis; code+data):
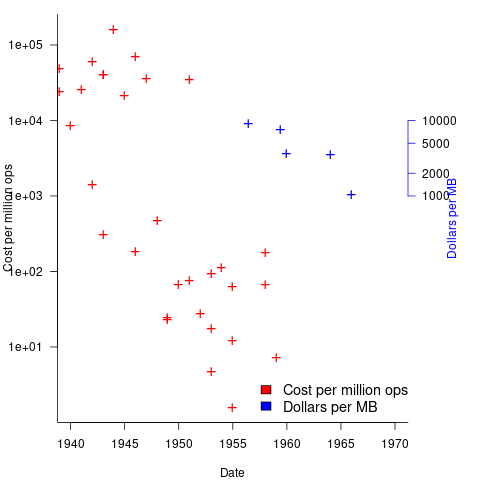
There was a larger business demand to be able to store information electronically, and the hard disc was invented by IBM, roughly 15 years after the first electronic computers.
The very different application demands of data processing and scientific/engineering are reflected in the features supported by the two languages designed in the 1950s, and widely used for the rest of the century: Cobol and Fortran.
Data processing involves simple operations on large quantities of data stored in a potentially huge number of different combinations (the myriad of mechanical point-of-sale terminals stored data in a myriad of different formats, which evolved over time, and the demand for backward compatibility created spaghetti data well before spaghetti code existed). Cobol has extensive functionality supporting the layout and format of input and output data, and simplistic coding constructs.
Scientific/engineering code involves complex calculations on some amount of input. Fortran has extensive functionality supporting program control flow, and relatively basic support for data input/output.
A third major application domain is real-time processing, such as SAGE. However, data on this domain is very hard to find, so it is not discussed.
Software memory management
I recently wrote about how computer memory capacity limits were a serious constraint for compiler writers. One technique used to increase the amount of memory available to a compiler (back in the days when pointers usually contained 16-bits) is software based paged memory management. Yes, compiler writers were generally willing to take the runtime performance hit to increase effectively accessible memory by around a factor of 10-25 (e.g., a 2 byte number used as an index into an array of 20 to 50 byte records).
The code to iterate over a data structure stored under the control of a software memory manager looks like the following (taken from a C to Pascal translator):
Var Flds : Sw_Ptr; (* in practice an integer *) T_Node : Sw_Node; (* in practice a pointer to a record *) Begin While Flds <> Sw_Nil Do (* Sw_Nil is the memory managers Nil value *) Begin Sw_Node_Ref(Cpswfile, Flds, T_Node, Mm_Readonly); If T_Node.Pn^.Node_Is<>N_Is_Field Then Verify_Error(Ve_Cputils, Ve_Scan_Fld); Scan(T_Node.Pn^.Field_Node.Ftype); Flds := T_Node.Pn^.Field_Node.Next; End; End; |
Where Sw_Node_Ref is a procedure in the memory management package that ensures the record denoted by Flds (whose value was obtained by a previous called to Sw_New_Node) is available in memory and returned in T_Node. Had Mm_ReadWrite rather than Mm_Readonly been specified the memory manager would assume that the record had been modified and when the page containing the record was swapped out of main memory it would write the contents of the page containing it to the swapfile (specified by the first argument, Cpswfile).
A call to Sw_Node_Ref only guarantees that the record is at the returned location until the next memory management procedure is called. This takes advantage of common usage which is: read a record, do something with its contents and then move on to the next one. The procedure Sw_Node_Ptr is available for when a record needs to be held in main memory across multiple Sw_ calls; this procedure locks a record in the limited capacity memory pool until explicitly freed (a Pascal style Mark/Release system was also available).
Multiple records were overlayed on a page (invariably 512 bytes) of storage. Some implementations used a fancy tool to create the overlay while others did it manually. The size of the pool in main memory used to hold swapped-in pages was specified when the memory manager was initialized; the maximum number of records that could be created by a call to Sw_New_Node was only limited by the maximum value of an integer and available disk space.
I learned about this implementation technique while on secondment at Intermetrics in the early 1980s, and they told me it came from the PQCC project of the mid 1970s. There is a paper in the Proceedings of the 1982 SIGPLAN symposium describing the system/library used by Intermetrics, which rambles on about nothing in particular and fails to say anything about software memory management (it is too useful an idea for a commercial company to tell anybody else); I don’t know of any other published description. Everybody I know who left Intermetrics to work on other compilers created their own implementation of a software memory management package.
Register vs. stack based VMs
Traditionally the virtual machine architecture of choice has been the stack machine; benefits include simplicity of VM implementation, ease of writing a compiler back-end (most VMs are originally designed to host a single language) and code density (i.e., executables for stack architectures are invariably smaller than executables for register architectures).
For a stack architecture to be an effective solution, two conditions need to be met:
- The generated code has to ensure that the top of stack is kept in sync with where the next instruction expects it to be. For instance, on its return a function cannot leave stuff lying around on the stack like it can leave values in registers (whose contents can simply be overwritten).
- Instruction execution needs to be generally free of state, so an add-two-integers instruction should not have to consult some state variable to find out the size of integers being added. When the value of such state variables have to be saved and restored around function calls, they effectively become VM registers.
Cobol is one language where it makes more sense to use a register based VM. I wrote one and designed two machine code generators for the MicroFocus Cobol VM and always find it difficult to explain to people what a very different kind of beast it is compared to the VMs usually encountered.
Parrot, the VM designed as the target for compiled PERL, is register based. A choice driven, I suspect, by the difficulty of ensuring a consistent top-of-stack and perhaps the dynamic typing of the language.
On register based cpus with 64k of storage, the code density benefits of a stack based VM are usually sufficient to cancel out the storage overhead of the VM interpreter and support a more feature rich application (provided speed of execution is not crucial).
If storage capacity is not a significant issue and a VM has to be used, what are the runtime performance differences between a register and stack based VM? Answering this question requires compiling and executing the same set of applications for the two kinds of VM. Something that until 2001 nobody had done, or at least not published the results.
A comparison of the Java (stack based) VM with a register VM (The Case for Virtual Register Machines) found that while the stack based code was more compact, fewer instructions needed to be executed on the register based VM.
Most VM instructions are very simple and take relatively little time to execute. When hosted on a pipelined processor the main execution time overhead of a VM is the instruction dispatch (Optimizing Indirect Branch Prediction Accuracy in Virtual Machine Interpreters) and reducing the number of VM instructions executed, even if they are larger and more complicated, can produce a worthwhile performance improvement.
Google has chosen a register based VM for its Android platform. While licensing issues may have been a consideration, there are a number of technical advantages to this decision:
- A register VM is likely to have an intrinsic performance advantage over a stack VM when hosted on a pipelined processor.
- Byte code verification is likely to be faster on a register VM (i.e., faster startup times) because stack height integrity checks will be greatly simplified.
- A register VM will be more forgiving of incorrect code (in the VM, generated by the compiler, code corrupted during program transmission or storage attacked by malware) than a stack VM.
Code generation via machine learning
Commercial compiler implementors have to produce compilers that are capable of being used on a typical developer computer. A whole bunch of optimization techniques were known for years but could not be used because few computers had the available memory capacity (in the days when 2M was a lot of memory your author once attended a talk that presented some impressive results and was frustrated to learn that the typical memory footprint was 160M, who would ever imagine developers having so much memory to work within?) These days the available of gigabytes of storage has means that likely computer storage capacity is rarely a reason not to use some optimization technique, although the whole program optimization people are still out in the cold.
What is new these days is the general availability of multiple processors. The obvious use of multiple processors is to have make distribute the compilation load. The more interesting use is having the compiler apply different sets of optimizations techniques on different processors, picking the one that produces the highest quality code.
Optimizing code generation algorithms don’t appear to leave anything to chance and individually they generally don’t. However, selecting an order in which to apply individual optimization algorithms is something of a black art. In some cases code transformations made by one algorithm can interfere with the performance of another algorithm. In some cases the possibility of the interference is known and applies in one direction, choosing the appropriate relative ordering of the two algorithms solves the problem. In other cases the way in which two algorithms interfere with each other depends on the code being translated, now the ordering of the two algorithms becomes problematic. The obvious solution is to try both orderings and pick the one that produces the best result.
Several research groups have investigated the use of machine learning in compiler optimization. cTuning.org is a new project that aims to bring together groups interested in self-tuning adaptive computing systems based on statistical and machine learning techniques.
Commercial pressure is always forcing compiler implementors to produce faster code and use of machine learning techniques can produce some impressive results. Now that multi-processor systems are common it will not be long before compilers writers start to make use of the extra resources now available to them.
The safety critical people have problems trying to show the correctness of compiler output that has been generated by ‘fixed’ algorithms. It is not hard to envisage that in 10 years time all large production quality compilers will be using machine learning.
Recent Comments