Archive
Best tool for measuring lots of source code
Human written source code contains various common usage patterns. This blog has analysed a variety of these patterns, and in a few cases built models of processes that replicate these patterns. The data for this analysis has primarily comes from programs written in C and Java, because these are the languages that researchers most often study (tool availability and herd mentality).
Do these common usage patterns occur in other languages, or at least other C/Java like languages? I think so, and have set out to collect the necessary data. Obtaining this data requires large quantities of code written in many languages, and the ability to analyse code written in these languages.
GitHub contains huge quantities of code. There are two freely available source code analysis tools supporting many languages: Opengrep (the Open source version of semgrep) and CodeQL.
CodeQL’s method of operation had previously put me off trying it. The method is a two stage process: First a database of information is created by extracting information during a project’s build process (e.g., running existing makefiles and host compilers), followed by querying this database using a declarative language (think minimalist SQL with lots of built-in functions). This approach has the huge advantage of not having to worry about handling compiler dialects/options, however, I’m an ingrained user of tools that process individual files.
From the research perspective, CodeQL has a major feature that is not available with other tools. GitHub, who now owns CodeQL, host thousands of project databases and GitHub Actions allows third-parties to scan up to 1,000 databases of the most popular projects. Access to existing CodeQL databases removes the need to download repo/build project/store database locally.
CodeQL, like other static analysis tools, was designed to find issues/problems in code, and so might not support the kind of functionality I needed to extract source code measurements. The best way to find out if the data of interest could be extracted is to try and do it.
In the best developer tradition, I downloaded a prebuilt release (available for Linux, Windows and Mac; called CodeQL Bundles), skimmed the documentation, ran a simple QL script and spent an hour or two trying to figure out why I was getting Java runtime errors, e.g., “no String-argument constructor/factory method to deserialize from String value“.
Progress would have been faster if I had used Visual Studio Code, available free from the owners of GitHub, rather than the command line. The documentation is not command line oriented. Visual Studio handles details like creating a qlpack.yml file (whose necessary existence I eventually found out about). Also, the harmless looking metadata appearing in comments is necessary and had better match the output parameters of the query. How hard is it to warn that a file could not be found, or that metadata is missing?
The code databases are queried using the declarative language QL, which is a kind of minimal SQL (with the select appearing last, rather than first). The import statement specifies the language, or rather the name of a library module.
The imported library contains classes for each language construct (e.g., BlockStmt, Function, ArrayExpr, etc). In the query below, the line “from LocalScopeVariable lv” extracts all local scope variables, which can subsequently be referred to via the name lv. The where line lists conditions that must be met (in this example, not be a parameter and not be accessed; testing for unused variables). The select line invokes methods that return various kinds of information about the class, e.g., the name of the variable, and location within the source.
/** * @id compound-stmt * @kind problem * @problem.severity warning */ import cpp from LocalScopeVariable lv where not lv instanceof Parameter and not exists(lv.getAnAccess()) select "", ""+lv.getName()+ ","+lv.getLocation().getStartLine()+ ","+lv.getLocation().getEndLine()+ ","+lv.getEnclosingFunction()+","+bs.getFile() |
The output generated is driven by the select, whose number/kind of arguments must match that specified by the metadata.
Developers can write and call functions, such as this one:
predicate header_suffix(string fstr) { fstr = "h" or fstr = "H" or fstr = "hpp" } |
The QL language is a declarative logical query language with roots in Datalog (subset of Prolog). The claim that it is an object-oriented language is technically correct, in that it groups functions into things called classes and supports various constructs usually found in object-oriented languages. The language has the feel of an academic project that happened to be used in a tool that was in the right place at the right time. Using host compilers to enable the tool to support many languages must have been very attractive to GitHub.
Coding in a declarative logic language requires a major mindset change. There are no loops, if statements or assignments. The query is one, potentially very long and complicated, predicate. A mindset change is necessary, but not sufficient, some fluency with the library of functions available is also needed. For instance, the isSideEffectFree predicate is true/false, but does not return a value (so there is nothing to print). I wanted to output 0/1, depending on whether a function was side effect free or not. When asked, all the LLMs questioned insisted that QL supported if-statements and assignment, just like other languages. After lots of dead-ends, an LLM claimed that “CodeQL automatically treats boolean expressions in count as 1/0″, and a test run showed this to be the case:
count(int dummy | dummy = 1 and func.isSideEffectFree() | dummy) |
The QL scripts needed to extract all the data of immediate interest to me were easily implemented. Looking at existing scripts has given me some ideas for more patterns I might measure. CodeQL currently supports 10 languages, and their classes appear to be slightly different (my initial focus is C, C++, Java and Python).
Visual Studio Code is required to run multi-repository variant analysis, i.e., scan up to 1,000 project databases on GitHub. It was after installing the CodeQL extension that I discovered how much smoother the process is within this IDE, compared to the command line (and off course the output is slightly different). There may be alternatives to Visual Studio, but I’m sticking with what the official documentation says.
Stepping back, is CodeQL a useful tool?
For me it is currently very useful, because of the large number of project databases. Some practice is needed to achieve some fluency in the use of a declarative logic language, not a major hurdle.
The need to run queries against a project database may be a major inconvenience for some developers, depending on working practices. Those practicing continuous integration should be ok.
Pricing by quantity of source code
Software tool vendors have traditionally licensed their software on a per-seat basis, e.g., the cost increases with the number of concurrent users. Per-seat licensing works well when there is substantial user interaction, because the usage time is long enough for concurrent usage to build up. When a tool can be run non-interactively in the cloud, its use is effectively instantaneous. For instance, a tool that checks source code for suspicious constructs. Charging by lines of code processed is a pricing model used by some tool vendors.
Charging by lines of code processed creates an incentive to reduce the number of lines. This incentive was once very common, when screens supporting 24 lines of 80 characters were considered a luxury, or the BASIC interpreter limited programs to 1023 lines, or a hobby computer used a TV for its screen (a ‘tiny’ CRT screen, not a big flat one).
It’s easy enough to splice adjacent lines together, and halve the cost. Well, ease of splicing depends on programming language; various edge cases have to be handled (somebody is bound to write a tool that does a good job).
How does the tool vendor respond to a (potential) halving of their revenue?
Blindly splicing pairs of lines creates some easily detectable patterns in the generated source. In fact, some of these patterns are likely to be flagged as suspicious, e.g., if (x) a=1;b=2; (did the developer forget to bracket the two statements with { }).
The plot below shows the number of lines in gcc 2.95 containing a given number of characters (left, including indentation), and the same count after even-numbered lines (with leading whitespace removed) have been appended to odd-numbered lines (code+data, this version of gcc was using in my C book):
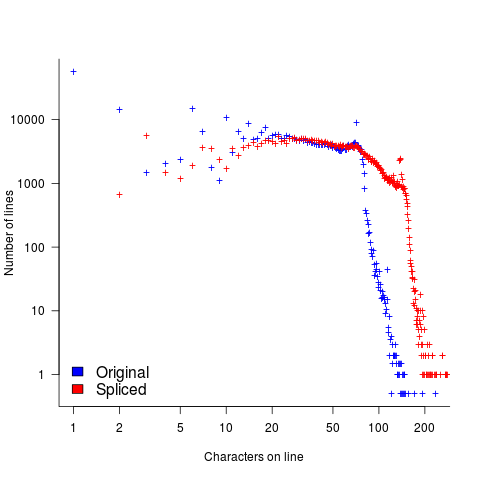
The obvious change is the introduction of a third straight’ish line segment (the increase in the offset of the sharp decline might be explained away as a consequence of developers using wider windows). By only slicing the ‘right’ pairs of lines together, the obvious patterns won’t be present.
Using lines of codes for pricing has the advantage of being easy to explain to management, the people who sign off the expense, who might not know much about source code. There are other metrics that are much harder for developers to game. Counting tokens is the obvious one, but has developer perception issues: Brackets, both round and curly. In the grand scheme of things, the use/non-use of brackets where they are optional has a minor impact on the token count, but brackets have an oversized presence in developer’s psyche.
Counting identifiers avoids the brackets issue, along with other developer perceptions associated with punctuation tokens, e.g., a null statement in an else arm.
If the amount charged is low enough, social pressure comes into play. Would you want to work for a company that penny pinches to save such a small amount of money?
As a former tool vendor, I’m strongly in favour of tool vendors making a healthy profit.
Creating an effective static analysis requires paying lots of attention to lots of details, which is very time-consuming. There are lots of not particularly good Open source tools out there; the implementers did all the interesting stuff, and then moved on. I know of several groups who got together to build tools for Java when it started to take-off in the mid-90s. When they went to market, they quickly found out that Java developers expected their tools to be free, and would not pay for claimed better versions. By making good enough Java tools freely available, Sun killed the commercial market for sales of Java tools (some companies used their own tools as a unique component of their consulting or service offerings).
Could vendors charge by the number of problems found in the code? This would create an incentive for them to report trivial issues, or be overly pessimistic about flagging issues that could occur (rather than will occur).
Why try selling a tool, why not offer a service selling issues found in code?
Back in the day a living could be made by offering a go-faster service, i.e., turn up at a company and reduce the usage cost of a company’s applications, or reducing the turn-around time (e.g., getting the daily management numbers to appear in less than 24-hours). This was back when mainframes ruled the computing world, and usage costs could be eye-watering.
Some companies offer bug-bounties to the first person reporting a serious vulnerability. These public offers are only viable when the source is publicly available.
There are companies who offer a code review service. Having people review code is very expensive; tools are good at finding certain kinds of problem, and investing in tools makes sense for companies looking to reduce review turn-around time, along with checking for more issues.
The dance of the dead cat
The flagging of unspecified behavior in C source by static analysis tools (i.e., where the standard specifies two or more possible behaviors for translators to choose from when generating code) is starting to rather get sophisticated, some tools are working out and reporting how many different program outputs are possible given the unspecified behavior in the source (traditionally tools simply point at code containing an instance of unspecified behavior).
A while ago I created a function where the number of possible different values returned, driven by one unspecified behavior in the code, was a Fibonacci number (the value of the function parameter selected the n’th Fibonacci number).
Weird ways of generating Fibonacci numbers are great for entertaining fellow developers, but developers are unlikely to be amused by a tool that flags their code as generating Fibonacci possible values (rather than the one they are expecting).
The possibility of Fibonacci different values relies on the generated code cycling through all possible behaviors, allowed by the standard, at runtime. This can only happen if program execution uses a Just-in-Time compiler; the compile once before execution implementations used by most developers get to generate far fewer possible permitted values (i.e, two for this particular example). Who would be crazy enough to write a JIT compiler for C you ask? Those crazy people who translate C to JavaScript for one.
To be useful for developers who are not using a JIT compiler to execute their C code, static analysis tools that work out the number of possible values that could be produced are going to have to support a code-compiled-before-execution option. Tools that don’t support this option will have what they report dismissed as weird possibilities that cannot happen in the developer’s world.
In the code below, does setting the code-compiled-before-execution option guarantee that the function Schrödinger always returns 1?
int x; int set_x(void) { x=1; return 1; } int two_values(void) { x=0; return x + set_x(); // different evaluation order -> different value } bool Schrödinger(void) { return two_values() == two_values(); } |
A compiler is free to generate code that returns a value that depends on whether two_values appears as the left or right operand of a binary operator. Not the kind of behavior an implementor would choose on purpose, but inlining both calls could result in different evaluation orders for the two instances of the code contained in what was the function body.
Our developer friendly sophisticated static analysis tool vendor is going to have to support a different_calls_to_same_function_have_same_behavior option.
How can a developer find out whether the compiler they were using always generated code having the same external behavior for different instances of calls, in the source, to the same function? Possibilities include reading the compiler source and asking the compiler vendor (perhaps future releases of gcc and llvm will support a different_calls_to_same_function_have_same_behavior option).
As far as I know (not having spent a lot of time looking) none of the tools doing the sophisticated unspecified behavior stuff support either of the developer friendly options I am suggesting need to be supported. Tools I know about include: c-semantics (including its go faster commercial incarnation) and ch2o (which the authors tell me executes the Fibonacci code a lot faster than c-semantics; last time I looked ch2o needed more installation time for the support tools it uses than I was willing to spend, so I have not tried it); the Cerberus project has not released the source of their system yet (I’m assuming they will).
The Ockham Sound Analysis Criteria
Yesterday a headline on a tool vendor blog caught my eye “… meets NIST high assurance standards”. What is this high assurance standard that I had not heard about before?
It turns out to be the Ockham Sound Analysis Criteria (which is not a standard, but is sort of connected to assurance at some level). I have been following the NIST group (now known as SAMATE) behind this work since their first meeting (the only one I have attended); their Static Analysis Tool Exposition (SATE) work is a great idea, but I imagine it has been an uphill battle convincing tool vendors to publicly expose the strength and weaknesses of their tools.
Passing the Ockham Sound Analysis Criteria requires that a static analysis tool detect “…a minimum of 60% of buggy sites OR of non-buggy sites.”, with no false-positives (which I take to mean that no incorrect warnings generated, i.e., the tool cannot incorrectly say “there is a fault here” or “there are no faults here”).
The obvious low cost tool implementation is to pattern detect the known problems in the known test suite (called the Juliet test suite) and output warnings about them. The only way for SAMATE to stop companies doing this (or at least tuning their tools to pass the suite) is to regularly change the test cases used.
I think I understand the rationale being the no false-positive requirement (SAMATE are using the marketing term “sound”). NIST want static analysis tools to be usable by people who don’t know anything about software; a strange idea I know, but the Nuclear Regulatory Commission have wanted to do this in the past.
Not being willing to accept false-positives kills innovation. New analysis techniques invariably start out being unreliable and improve over time.
I suspect that few vendors will have any interest in claiming to meet the Ockham Sound Analysis Criteria (apart from the ones that pattern match on the tests to satisfy some contract requirement). There is too much downside (new tests could put a vendor in the position of having to make a big investment just to continue to meet the criteria) for almost no upside (does anybody make purchase decisions based on this criteria?)
I think that the tool vendor (TrustinSoft) found they could make the claim and being relatively new in the tools market thought it might mean something to customers (I doubt it will, as their sales people are probably finding out). Of course what customers really want tool vendors to tell them is that their code does not contain any problems.
Hiring experts is cheaper in the long run
The SAMATE (Software Assurance Metrics And Tool Evaluation) group at the US National Institute of Standards and Technology recently started hosting a new version of test suites for checking how good a job C/C++/Java static analysis tools do at detecting vulnerabilities in source code. The suites were contributed by the NSA‘s Center for Assured Software.
Other test suites hosted by SAMATE contain a handful of tests and have obviously been hand written, one for each kind of vulnerability. These kind of tests are useful for finding out whether a tool detects a given problem or not. In practice problems occur within a source code context (e.g., control flow path) and a tool’s ability to detect problems in a wide range of contexts is a crucial quality factor. The NSA’s report on the methodology used looked good and with the C/C++ suite containing 61,387 tests it was obviously worth investigating.
Summary: Not a developer friendly test suite that some tools will probably fail to process because it exceeds one of their internal limits. Contains lots of minor language infringements that could generate many unintended (and correct) warnings.
Recommendation: There are people in the US who know how to write C/C++ test suites, go hire some of them (since this is US government money there are probably rules that say it has to go to US companies).
I’m guessing that this test suite was written by people with a high security clearance and a better than average knowledge of C/C++. For this kind of work details matter and people with detailed knowledge are required.
Another recommendation: Pay compiler vendors to add checks to their compilers. The GCC people get virtually no funding to do front end work (nearly all funding comes from vendors wanting backend support). How much easier it would be for developers to check their code if they just had to toggle a compiler flag; installing another tool introduces huge compatibility and work flow issues.
I had this conversation with a guy from GCHQ last week (the UK equivalent of the NSA) who are in the process of spending £5 million over the next 3 years on funding research projects. I suspect a lot of this is because they want to attract bright young things to work for them (student sponsorship appears to be connected with the need to pass a vetting process), plus universities are always pointing out how more research can help (they are hardly likely to point out that research on many of the techniques used in practice was done donkey’s years ago).
Some details
Having over 379,000 lines in the main function is not a good idea. The functions used to test each vulnerability should be grouped into a hierarchy; main calling functions that implement say the top 20 categories of vulnerability, each of these functions containing calls to the next level down and so on. This approach makes it easy for the developer to switch in/out subsets of the tests and also makes it more likely that the tool will not hit some internal limit on function size.
The following log string is good in theory but has a couple of practical problems:
printLine("Calling CWE114_Process_Control__w32_char_connect_socket_03_good();"); CWE114_Process_Control__w32_char_connect_socket_03_good(); |
C89 (the stated version of the C Standard being targeted) only requires identifiers to be significant to 32 characters, so differences in the 63rd character might be a problem. From the readability point of view it is a pain to have to check for values embedded that far into a string.
Again the overheads associated with storing so many strings of that length might cause problems for some tools, even good ones that might be doing string content scanning and checking.
The following is a recurring pattern of usage and has undefined behavior that is independent of the vulnerability being checked for. The lifetime of the variable shortBuffer terminates at the curly brace, }, and who knows what might happen if its address is accessed thereafter.
data = NULL; { /* FLAW: Point data to a short */ short shortBuffer = 8; data = &shortBuffer; } CWE843_Type_Confusion__short_68_badData = data; |
A high quality tool would report the above problem, which occurs in several tests classified as GOOD, and so appear to be failing (i.e., generating a warning when none should be generated).
The tests contain a wide variety of minor nits like this that the higher quality tools are likely to flag.
Why does Coverity restrict who can see its tool output?
Coverity generate a lot of publicity from their contract (started under a contract with the US Department of Homeland Security, don’t know if things have changed) to scan large quantities of open source software with their static analysis tools and a while back I decided to have a look at the warning messages they produce. I was surprised to find that access to the output required singing a non-disclosure agreement, this has subsequently been changed to agreeing to a click-through license for the basic features and signing a NDA for access to advanced features. Were Coverity limiting access because they did not want competitors learning about new suspicious constructs to flag, or because they did not want potential customers seeing what a poor job their tool did?
The claim that access “… for most projects is permitted only to members of the scanned project, partially in order to ensure that potential security issues may be resolved before the public sees them.” does not really hold much water. Anybody interested in finding security problems in code could probably find hacked versions of various commercial static analysis tools to download. The SAMATE – Software Assurance Metrics And Tool Evaluation project runs yearly evaluations of static analysis tools and makes the results publicly available.
A recent blog post by Andy Chou, Coverity’s CTO, added weight to the argument that their Scan tool is rather run-of-the-mill. The post discussed a new check that had recently been added flagging occurrences of memcmp, and related standard library functions, that were being tested for equality (or inequality) with specific integer constants (these functions are defined to return a negative or positive value or 0, and while many implementations always return the negative value -1 and the positive value 1 a developer should always test for the property of being negative/positive and not specific values that have that property). Standards define library functions to have a wide variety of different properties, and tools that check for correct application of these properties have been available for over 15 years.
My experience of developer response, when told that some library function is required to return a negative value and some implementation might not return -1, is that they regard any implementation not returning -1 as being ‘faulty’ since all implementations in their experience return -1. I imagine that library implementors are aware of this expectation and try to meet it. However, optimizing compilers often try to automatically inline calls to memcpy and related copy/compare functions and will want to take advantage of the freedom to return any negative/positive value if it means not having to perform a branch test (a big performance killer on most modern processors).
Trying to sell analysis tools to the Nuclear Regulatory Commission
Over the last few days there has been an interesting, and in places somewhat worrying, discussion going on in the Safety Critical mailing list about the US Nuclear Regulatory Commission. I thought I would tell my somewhat worrying story about dealing with the NRC.
In 1996 the NRC posted a request for information for a tool that I thought my company stood a reasonable chance of being able to meet (“NRC examines source code in nuclear power plant safety systems during the licensing process. NRC is interested in finding commercially available tools that can locate and provide information about the following programming practices…”). I responded, answered the questions on the form I received and was short listed to make a presentation to the NRC.
The presentation took place at the offices of National Institute of Standards and Technology, the government agency helping out with the software expertise.
From our brief email exchanges I had guessed that nobody at the NRC/NIST end knew much about C or static analysis. A typical potential customer occurrence that I was familiar with handling.
Turned up, four or so people from NRC+one(?) from NIST, gave a brief overview and showed how the tool detected the constructs they were interested in, based on test cases I had written after reading their requirements (they had not written any but did give me some code that they happened to have, that was, well, code they happened to have; a typical potential customer occurrence that I was familiar with handling).
Why did the tool produce all those messages? Well, those are the constructs you want flagged. A typical potential customer occurrence that I was familiar with handling.
Does any information have to be given to the tool, such as where to find header files (I knew that they had already seen a presentation from another tool vendor, these managers who appeared to know nothing about software development had obviously picked up this question from that presentation)? Yes, but it is very easy to configure this information… A typical potential customer occurrence that I was familiar with handling.
I asked how they planned to use the tool and what I had to do to show them that this tool met their requirements.
We want one of our inspectors to be able turn up at a reactor site and check their source code. The inspector should not need to know anything about software development and so the tool must be able to run automatically without any options being given and the output must be understandable to the inspector. Not a typical potential customer occurrence and I had no idea about how to handle it (I did notice that my mouth was open and had to make a conscious effort to keep it closed).
No, I would not get to see their final report and in fact I never heard from them again (did they find any tool vendor who did not stare at them in disbelief?)
The trip was not a complete waste of time, a few months earlier I had been at a Java study group meeting (an ISO project that ultimately failed to convince Sun to standarize Java through the ISO process) with some NIST folk who worked in the same building and I got to chat with them again.
A few hours later I realised that perhaps the question I should have asked was “What kind of software are people writing at nuclear facilities that needs an inspector to turn up and check?”
sparse can now generate executables
How can you be confident that a source code analysis tool is correct when its analysis of a file does not result in any warning being generated? The best way I know of addressing this issue is for the analysis tool to be capable of generating an executable from the source. Executing a moderately large program requires that the translator get all sorts of complicated analysis correct and provides a huge boost to confidence of correctness compared to an analysis tool that does not have this ability.
Congratulations to the maintainers of sparse (a Linux kernel specific analysis tool started by Linus Torvalds in 2003) for becoming one of the very small number of source code analysis tools capable of generating executable programs.
The Model C Implementation is another tool capable of generating executables. I would love to be able to say that the reason for this was dedication to perfection by the project team, however, the truth is that it started life as a compiler and became an analyzer later.
Clang, the C front end+analyzer to llvm is often referred to as a static analyzer. While it does perform some static checking (like gcc does when the -Wall option is specified) a lot more checks needs to be supported before it can be considered on a par with modern static analysis tools.
GCC’s Treehydra project works via a plug-in to the compiler. This project has yet to live up to its potential, so we can delay discussion of whether it should be classified as a standalone system or an executable generator.
I cannot think of any other ‘full language’ static analysis tools capable of generating executable programs (the C-semantics tool restricts its checks to those required by the C Standard, and I think tools need to do a lot more than this to be considered static analysis tools). Corrections to my lack of knowledge welcome.
I was a little concerned that there were plans afoot to migrate sparse to becoming the build compiler for the Linux kernel. Linus answered my query by saying that this was never a goal.
Searching for inaccurate literals in R
In creating the numbers tool I wanted to be able to do two things, 1) obtain information about what source did by matching the numeric literals it contained against a database of ‘interesting’ values (now with over 14,000 entries) and 2) flag possible incorrect numeric literals (e.g., 3.1459265 when 3.14159265 had been intended in core/Helix.cpp of the MIFit source {now fixed}).
I have recently been enhancing ‘incorrect numeric literal’ support and using the latest release of R as a test bed (whose floating-point literals are almost identical to the last release I looked at, R-2.11.1, log file here).
The first fault I found (0.20403... instead of 0.020403...) looked very serious until I realised it was involved in calculating an initial value feed into an iterative algorithm (at worst causing an extra iteration or so). It looks like the developer overlooked the “e-1” that appears in the original (click on ‘Page 48’).
The second possible problem turned out to be an ambiguity in the file main/color.c which contains the comment “CIE-XYZ to sRGB” above three expressions that perform a conversion from CIE-XYZ to BT.709 RGB. Did the developer get the comment or the numeric literals wrong? People are known to confuse the two forms of RGB (for an explanation see Annex B) .
Apart from a few minor errors such as 0.950301 instead of 0.9503041 (in …/grDevices/R/postscript.R) nothing else of interest turned up so I shifted attention to the add-on packages available on the Comprehensive R Archive Network.
The 3,000+ packages occupy almost 2 Gig in compressed form (fortunately numbers can operate directly on compressed archives and the files did not need to be unpacked) and I decided to limit the analysis to just the R source files, which cut the number of floating-point literals down to around 2 million (after ignoring the contents of comments, 10M compressed log file here).
The various floating-point literals having a value close to 2.30258509299404568402 (the most common match; no idea why the value ln(10) or 1/log(e) should be so popular) highlight the various issues that crop up when using approximate matching to look for faults. The following are some of these matches (first number is total occurrences, second sequence is the literal appearing in the source with dot denoting the same digit as in the number matched against):
92 ........ 2.30258509299404568402 ln(10) or 1/log(e) 5 ...............5 2.30258509299404568402 ln(10) or 1/log(e) 1 .....80528052805 2.30258509299404568402 ln(10) or 1/log(e) 3 .....6 2.30258509299404568402 ln(10) or 1/log(e) 2 .....67 2.30258509299404568402 ln(10) or 1/log(e) 1 .....38 2.30258509299404568402 ln(10) or 1/log(e) 2 .....8 2.30258509299404568402 ln(10) or 1/log(e) 1 .....42 2.30258509299404568402 ln(10) or 1/log(e) 2 ......7 2.30258509299404568402 ln(10) or 1/log(e) 2 ......2 2.30258509299404568402 ln(10) or 1/log(e) 1 ....... 2.30258509299404568402 ln(10) or 1/log(e) 2 .....6553 2.30258509299404568402 ln(10) or 1/log(e) 1 .......4566 2.30258509299404568402 ln(10) or 1/log(e)
Most of those 92 seven digit matches occur in a subdirectory called data implying that they do not occur within code expressions, while .....80528052805 contains enough extra trailing non-matching digits to suggest a different value really was intended. Are there enough unmatched trailing digits in .....6553 to consider it a different value? More experience needs to be gained before attempting to make this call automatically.
At the moment a person has to look at the code containing these ‘close’ values to decide whether the author made a mistake or really did mean to use the value given (unfortunately numbers does not yet have a fancy gui to simplify this task). Sometimes the literals appear in data and other times in an expression that requires domain knowledge to figure out whether it is correct or not. My cursory sampling of the very large data set did not find any serious problems.
Some of the unmatched literals contain so few significant digits they would match many entries in a database of ‘interesting’ values. For instance the numbers database used to contain 745.0, the mean radius of the minor planet Sedna (according to the latest NASA data), but it was removed because of the large number of false positive matches it generated.
Many of the unmatched literals appear to do not appear to have any special interest outside of code that contains them, for instance 0.2.
I am hoping that readers of this blog will download numbers and run their code through it. They might find some faults in their code and add new values to their local ‘interesting’ numbers database to target their own application domain(not forgetting to email me a copy to include in the next release). Suggestions for improving the detection of inaccurate literals always welcome (check to the TODO file first).
An interesting observation from comparing the mathematical equations in the book Computation of Special Functions with the Fortran source provided by its authors is that when a ‘known’ constant (e.g., pi, pi/2) appears in isolation (e.g., as an argument or a value in an assignment) its literal representation often contains as many digits as supported in 64-bits, while when the same constant appears within an expression evaluating a polynomial it often contains the same number of digits as the other literals appearing in that expression (which is usually less than supported in 64-bits).
Recent Comments