Archive
Likelihood of encountering a given sequence of statements
How many lines of code have to be read to be likely to encounter every meaningful sequence of  statements (a non-meaningful sequence would be the three statements
statements (a non-meaningful sequence would be the three statements break;break;break;)?
First, it is necessary to work out the likelihood of encountering a given sequence of statements within  lines of code.
lines of code.
If we just consider statements, then the following shows the percentage occurrence of the four kinds of C language statements (detailed usage information):
Statement % occurrence expression-stmt 60.3 selection-stmt 21.3 jump-stmt 15.0 iteration-stmt 3.4 |
The following analysis assumes that one statement occupies one line (I cannot locate data on percentage of statements spread over multiple lines).
An upper estimate can be obtained by treating this as an instance of the Coupon collector’s problem (which assumes that all items are equally likely), i.e., treating each sequence of statements as a coupon.
The average number of items that need to be processed before encountering all  distinct items is:
distinct items is: =n*H_n") , where
, where  is the n-th harmonic number. When we are interested in at least one instance of every kind of C statement (i.e., the four listed above), we have:
is the n-th harmonic number. When we are interested in at least one instance of every kind of C statement (i.e., the four listed above), we have: =8.33 right 9") .
.
There are  distinct sequences of three statements, but only
distinct sequences of three statements, but only  meaningful sequences (when statements are not labelled, a
meaningful sequences (when statements are not labelled, a jump-stmt can only appear at the end of a sequence). If we treat each of these 36 sequences as distinct, then =150.3 right 151") , 3-line sequences, or 453 LOC.
, 3-line sequences, or 453 LOC.
This approach both under- and over-estimates.
One or more statements may be part of different distinct sequences (causing the coupon approach to overestimate LOC). For instance, the following sequence of four statements:
expression-stmt selection-stmt expression-stmt expression-stmt |
contains two distinct sequences of three statements, i.e., the following two sequences:
expression-stmt selection-stmt selection-stmt expression-stmt expression-stmt expression-stmt |
There is a factor of 20-to-1 in percentage occurrence between the most/least common kind of statement. Does subdividing each kind of statement reduce this difference?
If expression-stmt, selection-stmt, and iteration-stmt are subdivided into their commonly occurring forms, we get the following percentages (where -other is the subdivision holding all cases whose occurrence is less than 1%, and the text to the right of sls- indicates the condition in an if-statement; data):
Statement % occurrence exs-func-call 22.3 exs-object=object 9.6 exs-object=func-call 6.0 exs-object=constant 4.2 exs-object_v++ 2.4 exs-other 15.7 sls-object 3.3 sls-object==object 1.9 sls-!object 1.6 sls-func-call 1.6 sls-expression 1.2 sls-other 11.7 jump-stmt 15.0 its-for 2.1 its-while 1.1 |
Function calls could be further broken down by number of arguments, but this would not have much impact because zero and one arguments are very common.
A more accurate model of the problem is needed.
A Markov chain approach handles both overlapping sequences, and statements having difference occurrence probabilities. For a sequence of length , the calculation involves an ") by matrix. For a sequence of three of the same kind of statement (chosen because ‘same kind’ of sequences are least likely to match, for a given length), the transition matrix is:
by matrix. For a sequence of three of the same kind of statement (chosen because ‘same kind’ of sequences are least likely to match, for a given length), the transition matrix is:
")
where  is the probability that statement
is the probability that statement  will occur. The last row is the absorbing state. For the general case, see: Pattern Markov chains: Optimal Markov chain embedding through deterministic finite automata.
will occur. The last row is the absorbing state. For the general case, see: Pattern Markov chains: Optimal Markov chain embedding through deterministic finite automata.
To calculate the probability that a sequence of the same kind of statement, of length , occurs within a sequence of statements, this transition matrix is multiplied  times (i.e., raised to the power ). The following code is an implementation in R (python script handling the general case):
times (i.e., raised to the power ). The following code is an implementation in R (python script handling the general case):
seq_prob = function(N, s_len, Sk)
{
Sp=rep(Sk, s_len)
P=matrix(0, nrow = s_len+1, ncol = s_len+1) # Transition matrix
P[ , 1]=1-c(Sp, 1) # Probability of not occurring: first column
op=cbind(1:s_len, (1:s_len)+1) # diagonal for occurrence probabilities
P[op]=Sp # assign occurrence probabilities
P[s_len+1, s_len+1]=1 # absorbing state
R=P # result value
for (n in 2:N)
R=R %*% P # matrix multiply
return(R)
}
# Calculate probability for N equiprobable occurrences
# Result in last column of first row
N = 100
seq_len=3
sk=0.01
likelihood=seq_prob(N, seq_len, sk)[1, seq_len+1] |
If the occurrence likelihood of  (i.e., 1%), then the likelihood of encountering a sequence of three such statements in a sequence of 3 lines is
(i.e., 1%), then the likelihood of encountering a sequence of three such statements in a sequence of 3 lines is  (i.e., 0.0001%), while for a sequence of 100 lines it is
(i.e., 0.0001%), while for a sequence of 100 lines it is  .
.
The number of statements contained in a function varies. To calculate the likelihood of encountering a particular sequence of three statements in a program, or collection of programs, we need to find the likelihood over all function lengths, adjusting for the probability of encountering functions containing a given number of statements.
The plot below shows the cumulative percentage of code as function LOC increases (data from Landman, Serebrenik, Bouwers and Vinju; plot code):
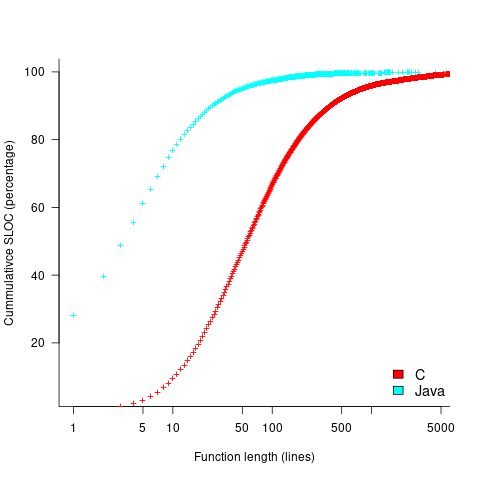
Calculating the likelihood of encountering a given sequence length in a function containing a given number of LOC (ignoring local definitions and blank lines), and then adjusting for the probability of a function containing a given number of LOC, the likelihood of encountering a sequence containing 3-to-10 of the same kind of statement (whose likelihood of occurrence is 1%) is given by the following table (calculation code):
of
seq length Occurrence likelihood
3 2.3e-05
4 2.2e-07
5 2.1e-09
6 2.0e-11
7 2.0e-13
8 1.9e-15
9 1.8e-17
10 1.8e-19 |
These values can be used to calculate the likelihood of encountering this ‘1%’ statement sequence in a repo containing C functions. For instance, in 1 million functions the likelihood of one instance of a three ‘1%’ same-kind statement sequence is: ^{10^6} approx 1") . For a repo containing one billion functions of C, there is an 88% chance of encountering a sequence of five such statements.
. For a repo containing one billion functions of C, there is an 88% chance of encountering a sequence of five such statements.
The sequence occurrence likelihood for Java will be smaller because Java functions contain fewer LOC.
At the subdivision level of kind-of-statement that has been found to occur in 1% of all statements, sequences up to five long are likely to be encountered at least once in a billion functions, with sequences containing more common statements occurring at a greater rate.
Sequences of kind-of-statements whose occurrence rate is well below 1% are unlikely to be encountered.
This analysis has assumed that the likelihood of occurrence of each statement in a sequence is independent of the other statements in the sequence. For some kind-of-statement this is probably not true, but no data is available.
The pervasive use of common statement sequences enables LLMs to do a good job of predicting what comes next.
Developers do not remember what code they have written
The size distribution of software components used in building many programs appears to follow a power law. Some researchers have and continue to do little more than fit a straight line to their measurements, while those that have proposed a process driving the behavior (e.g., information content) continue to rely on plenty of arm waving.
I have a very simple, and surprising, explanation for component size distribution following power law-like behavior; when writing new code developers ignore the surrounding context. To be a little more mathematical, I believe code written by developers has the following two statistical properties:
- nesting invariance. That is, the statistical characteristics of code sequences does not depend on how deeply nested the sequence is within
if/for/while/switchstatements, - independent of what went immediately before. That is the choice of what statement a developer writes next does not depend on the statements that precede it (alternatively there is no short range correlation).
Measurements of C source show that these two properties hold for some constructs in some circumstances (the measurements were originally made to serve a different purpose) and I have yet to see instances that significantly deviate from these properties.
How does writing code following these two properties generate a power law? The answer comes from the paper Power Laws for Monkeys Typing Randomly: The Case of Unequal Probabilities which proves that Zipf’s law like behavior (e.g., the frequency of any word used by some author is inversely proportional to its rank) would occur if the author were a monkey randomly typing on a keyboard.
To a good approximation every non-comment/blank line in a function body contains a single statement and statements do not often span multiple lines. We can view a function definition as being a sequence of statement kinds (e.g., each kind could be if/for/while/switch/assignment statement or an end-of-function terminator). The number of lines of code in a function is closely approximated by the length of this sequence.
The two statistical properties listed above allow us to treat the selection of which statement kind to write next in a function as mathematically equivalent to a monkey randomly typing on a keyboard. I am not suggesting that developers actually select statements at random, rather that the set of higher level requirements being turned into code are sufficiently different from each other that developers can and do write code having the properties listed.
Switching our unit of measurement from lines of code to number of tokens does not change much. Every statement has a few common forms that occur most of the time (e.g., most function calls contain no parameters and most assignment statements assign a scalar variable to another scalar variable) and there is a strong correlation between lines of code and token count.
What about object-oriented code, do developers follow the same pattern of behavior when creating classes? I am not aware of any set of measurements that might help answer this question, but there have been some measurements of Java that have power law-like behavior for some OO features.
Recent Comments