Archive
Compiler validation is now part of history
Compiler validation makes sense in a world where there are many different hardware platforms, each with their own independent compilers (third parties often implemented compilers for popular platforms, competing against the hardware vendor). A large organization that spends hundreds of millions on a multitude of computer systems (e.g., the U.S. government) wants to keep prices down, which means the cost of porting its software to different platforms needs to be kept down (or at least suppliers need to think it will not cost too much to switch hardware).
A crucial requirement for source code portability is that different compilers be able to compile the same source, generating code that produces the same behavior. The same behavior requirement is an issue when the underlying word-size varies or has different alignment requirements (lots of code relies on data structures following particular patterns of behavior), but management on all sides always seems to think that being able to compile the source is enough. Compilers vendors often supported extensions to the language standard, and developers got to learn they were extensions when porting to a different compiler.
The U.S. government funded a conformance testing service, and paid for compiler validation suites to be written (source code for what were once the Cobol 85, Fortran 78 and SQL validation suites). While it was in business, this conformance testing service was involved C compiler validation, but it did not have to fund any development because commercial test suites were available.
The 1990s was the mass-extinction decade for companies selling non-Intel hardware. The widespread use of Open source compilers, coupled with the disappearance of lots of different cpus (porting compilers to new vendor cpus was always a good money spinner, for the compiler writing cottage industry), meant that many compilers disappeared from the market.
These days, language portability issues have been essentially solved by a near monoculture of compilers and cpus. It’s the libraries that are the primary cause of application portability problems. There is a test suite for POSIX and Linux has its own tests.
There are companies selling compiler C/C++ test suites (e.g., Perennial and PlumHall); when maintaining a compiler, it’s cost-effective to have a set of third-party tests designed to exercise all the language.
The OpenGroup offer to test your C compiler and issue a brand certificate if it passes the tests.
Source code portability requires compilers to have the same behavior and traditionally the generally accepted behavior has been defined by an ISO Standard or how one particular implementation behaved. In an Open source world, behavior is defined by what needs to be done to run the majority of existing code. Does it matter if Open source compilers evolve in a direction that is different from the behavior specified in an ISO Standard? I think not, it makes no difference to the majority of developers; but be careful, saying this can quickly generate a major storm in a tiny teacup.
Learning R as a language
Books written to teach a general purpose programming language are usually organized according to the features of the language and examples often show how a particular language feature is interpreted by a compiler. Books about domain specific languages are usually organized in a way that makes sense in the corresponding application domain and examples usually illustrate how a particular domain problem can be solved using the language.
I have spent a lot of time using R over the last year and by dint of reading lots of R code and various introductions to the language I have managed to piece together a model of the language. I rarely have any trouble learning a general purpose language from its reference manual, but users of domain specific languages are rarely interested in language details and so these reference manuals are usually only intended to be read by people who know the language well (another learning problem is that domain specific languages often contain quirky features rarely seen in other languages; in the case of R I was not lucky enough to know enough other languages to cover all its quirky features).
I managed to one introduction to R written from the perspective of the programming language (and not the application domain): the original The Art of R Programming by Norman Matloff has been expanded and is now available as a book.
Summary. If you know another language and want to quickly learn about the languages features of R I recommend this book. I have not taught raw beginners for over 30 years and have no idea if this book would be of any use to them.
This book does not attempt to teach you to think ‘R’, it is not about the art of R programming. The value of this book is as a single source for a broad coverage of lots of language features explained using lots of examples. Yes, more time could have been spent on the organization and fixing inconsistencies in the layout; these are not show stoppers.
Some people might tell you to buy “Software for Data Analysis” by John Chambers. Don’t; if you are a fan of Finnegans Wake and are nostalgic for the mainframe world of the 1970s you might like to give it a go. (I think Bertrand Meyer’s “Object-oriented Software Construction” is still the best book about the design of a language).
Meanderings. What books are good examples of “The Art of …” writing for domain specific languages? Two that spring to mind are: “Algorithms in Snobol 4” by James Gimpel (still spotted from time to time on second hand book sites) and more recently “SQL For Smarties: Advanced SQL Programming” by Joe Celko.
Yes, I know that R is not really a domain specific language but a language that is primarily used in one domain. Frink is an example of a language containing a major behavior feature that is specific to its intended application domain. I cannot think of any major language feature of R that is specific to statistics.
SQL usage: schema evolution
My first serious involvement with SQL, about 15 years ago, was writing a parser for the grammar specified in the ISO SQL-92 Standard. One of the things that surprised me about SQL was how little source code was generally available (for testing) and the almost complete lack of any published papers on SQL usage (its always better to find out about where the pot-holes are from other peoples’ experience).
The source code availability surprie is largely answered by the very close coupling between source and data that occurs with SQL; most SQL source is closely tied to a database schema and unless you have a need to process exactly the same kind of data you are unlikely to have any interest having access to the corresponding SQL source. The growth in usage of MySQL means that these days it is much easier to get hold of large amounts of SQL (large is a relative term here, I suspect that there are probably many orders of magnitude fewer lines of SQL in existence than there is of other popular languages).
In my case I was fortunate in that NIST released their SQL validation suite for beta testing just as I started to test my parser (it had taken me a month to get the grammar into a manageable shape).
Published research on SQL usage continues to be thin on the ground and I was pleased to recently discover a paper combining empirical work on SQL usage with another rarely researched topic, declaration usage e.g., variables and types or in this case schema evolution (for instance, changes in the table columns over time).
The researchers only analyzed one database, the 171 releases of the schema used by Wikipedia between April 2003 and November 2007, but they also made their scripts available for download and hopefully the results of applying them to lots of other databases will be published.
Not being an experienced database person I don’t know how representative the Wikipedia figures are; the number of tables increased from 17 to 34 (100% increase) and the number of columns from 100 to 242 (142%). A factor of two increase sounds like a lot but I suspect that all but one these columns occupy a tiny fraction of the 14GB that is the current English Wikipedia.
Language usage in Google’s ngram viewer
I thought I would join the fun that people are having with Google’s new ngram viewer. The raw data (only a subset for bigrams and longer ngrams) was also enticing, but at 35+ gigabytes for the compressed 1/2/3-grams of English-all I decided to forgo the longer n-grams.
We all know that in the dim and distant past most programmers wrote in machine code, but it was not until 1980 that “source code” appeared more frequently in books that “machine code”.
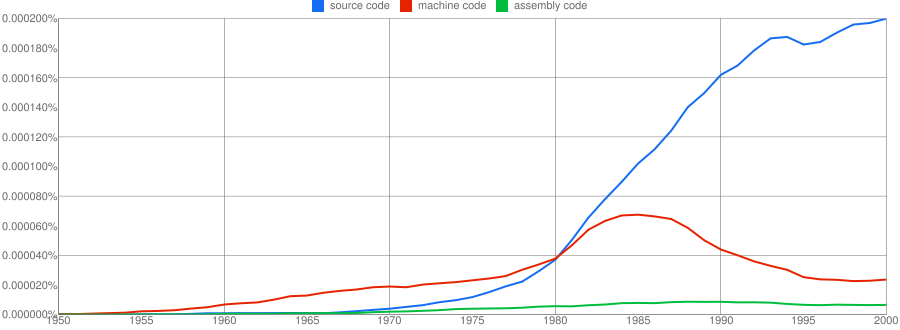
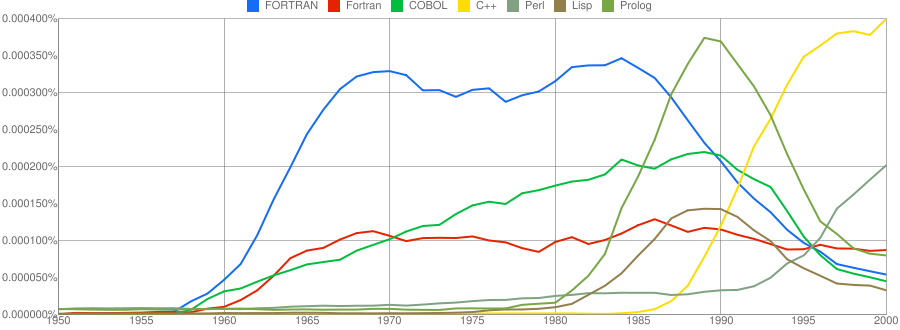
Computer language popularity is a perennial question. Fortran and Cobol address very different markets and I would have expected their usage to follow similar patterns, with “COBOL” having the obvious usage pattern for them both to follow. Instead, both “FORTRAN” and “Fortran” peaked within 10 years, with one staying there for another 20 years before declining and the other still going strong in 2000 (and still ahead of “PHP” and “Python” in 2000; neither shown to keep the clutter down). I am surprised to see “Prolog” usage being so much greater than “Lisp” and I would have expected “Lisp” to have a stronger presence in the 1970s.
I think the C++ crowd will be surprised to see that in 2000 usage was not much greater than what “FORTRAN” had enjoyed for 20 years.
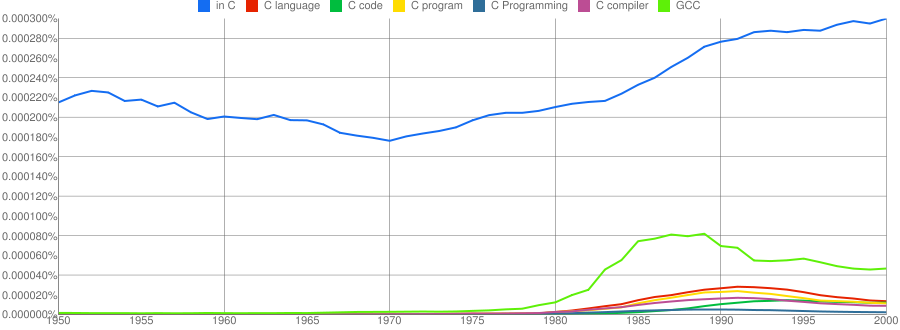
“C”, as in language, usage is obviously different to reliably measure. I have tried the obvious bigrams. Looking at some of the book matches for the phrase “in C” shows that the OCR process has sometimes inserted spaces that probably did not exist in the original, the effect being to split words and create incorrect bigrams. The phrase “in C” would also appear in books on music.
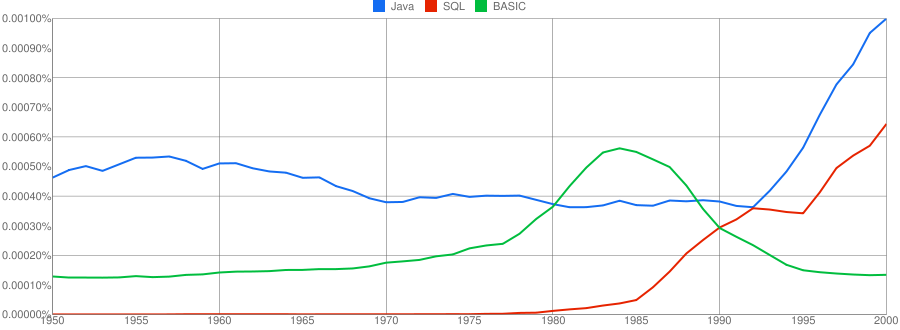
I have put the three words “Java”/”SQL”/”BASIC” in a separate plot because their usage swamps that of the other languages. Java obviously has multiple non-computer related uses and subtracting the estimated background usage suggests a language usage similar to that of “SQL”. There is too much noise for the usage of “Basic” to tell us much.
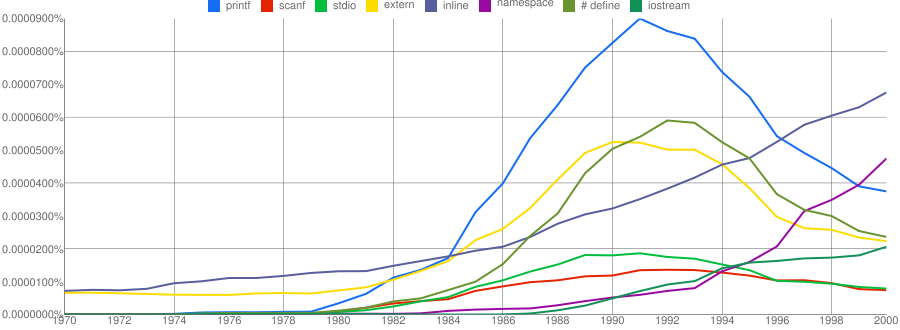
One way of comparing C/C++ language usage is to look source code usage where they are likely to differ. I/O, in the form of printf/scanf and stdio/iostream, is one obvious choice and while the expected C usage starts to declines in the 1990s the C++ usage just shows a stead growth (perhaps the <</>> usage, which does not appear in the Google viewer, has a dramatic growth during this time period).
Surprisingly #define also follows a similar pattern of decline. Even allowing for the rabid anti-macro rhetoric of the C++ in-crowd I would not have expected such a rapid decline. Perhaps this is some artifact of the book selection process used by Google; but then "namespace" shows a healthy growth around this time period.
The growth of "inline" over such a long period of time is a mystery. Perhaps some of this usage does not relate to a keyword appearing within source code examples but to text along the lines of "put this inline to make it faster".
What usage should we expect for the last decade? A greater usage of "PHP" and "Python" is an obvious call to make, along with the continuing growth of SQL, I think "UML" will also feature prominently. Will "C++" show a decline in favor or "Java" and what about "C#"? We will have to wait and see.
GLR parsing is the future
Traditionally parser generators have required that their input grammar be LALR(1) or some close variant (I would include LL(1) in this set). Back when 64k was an unimaginably large amount of memory being able to squeeze parser tables in a few kilobytes was very important; people received PhDs on parser table compression.
There is still a market for compact, fast parsers. Formal language grammars abound in communication protocols and vendors of communications hardware are very interested in keeping down costs by using minimizing the storage needed by their devices.
The trouble with LALR(1) is that value 1. It means that the parser only looks ahead one token in the input stream. This often means that a grammar is flagged as being ambiguous (i.e., it contains shift/reduce or reduce/reduce conflicts) when it is actually just locally ambiguous, i.e., reading tokens further head on the input stream would provide sufficient context to unambiguously specify the appropriate grammar production.
Restructuring a grammar to make it LALR(1) requires a lot of thought and skill and inexperienced users often give up. I once spent a month trying to remove the conflicts in the SQL/2 grammar specified by the SQL ISO standard; I managed to get the number down from over 1,000 to a small number that I decided I could live with.
It has taken a long time for parser generators to break out of the 64k mentality, but over the last few years it has started to happen. There have been two main approaches: 1) LR(n) provides a mechanism to look further ahead than one token, ie,
I think that GLR parsing is the future for two reasons:
- It is supported by the most widely used parser generator, bison.
- It enables working parsers to be created with much less thought and effort than a LALR(1) parser. (I don’t know how it compares against LR(n)).
GLR parsers resolve any language ambiguities by effectively delaying decisions until runtime in the hope that reading enough tokens will resolve local ambiguities. If an ambiguity in the token stream cannot be resolved a runtime error occurs (this is the one big downside of a GLR parser, the parser generated by a LALR(1) parser generator may produce lots of build time warnings but never produces errors when the parser is executed).
One example of a truly ambiguous construct (discussed here a while ago) is:
x * y; |
which in C/C++ could be a declaration of y to be a pointer to x, or an expression that multiplies x and y.
Tools that can detect these global ambiguities in a grammar are starting to appear, e.g., DTWA is a bison extension.
I reviewed an early draft of the new O’Reilly book “flex & bison” and tried to get the author to be more upbeat on GLR support in bison; I think I got him to be a bit less cautious.
Recent Comments