Archive
Street cred has no place in guidelines for nuclear power stations
The UK Government recently gave the go ahead to build a new nuclear power station in the UK. On Friday I spotted the document COMPUTER BASED SAFETY SYSTEMS published by the UK’s Office for Nuclear Regulation.
This document does a good job of enumerating all of the important software engineering issues in short, numbered, sentences, until sentence 54 of Appendix 1; “A1.54 The coding standards should prohibit the following practices:-“. Why-o-why did the committee of authors choose to stray from the approach of providing a high level overview of all the major issues? I suspect they wanted to prove their street cred as real software developers. As usually happens in such cases the end result looks foolish and dated (1970-80s in this case).
The nuclear industry takes it procedures a lot more seriously than most other industries, which means some poor group of developers are going to have to convince a regulator with minimal programming language knowledge that they are following this rather nebulous list of prohibitions.
What does the following mean? “5 Multiple use of variables – variables should not be used for more than one function;”. It could be read to mean no use of global variables, but is probably intended to cover something like the role of variables idea.
How is ‘complicated’ calculated in the following? “9 Complicated calculation of indexes;”
Here is my favorite: “15 Direct memory manipulation commands – for example, PEEK and POKE in BASIC;”. More than one committee member obviously had a BBC Micro or Sinclair Spectrum as a teenager.
What should A1.54 say? Something like: “A coding guideline document listing the known problematic areas of the language(s) used along with details of how to handle each area will be written. All staff will be given training on the use of these guidelines.”
The regulator needs to let the staff hired following A1.4 do their job: “A1.4 Only reputable companies should be used in all stages of the lifecycle of computer based protection systems. Each should have a demonstrably good track record in the appropriate field. Such companies should only use staff with the appropriate qualifications and training for the activities in which they are engaged. Evidence that this is the case should be provided.”
After A1.54 has been considerably simplified, A1.55 needs to be deleted: “A1.55 The coding standards should encourage the following:-“. Either require it or not. I suspect the author of “6 Explicit initialising of all variables;” had one of a small number of languages in mind, those that support implicit initialization with a defined value: many don’t, illustrating how language specific coding guidelines need to be.
Following the links in the above document led to: Verification and Validation of Software Related to Nuclear Power Plant Instrumentation and Control which contained some numbers about Sizewell B I had not seen before in public documents: “The total size of the source code for the reactor protection functions, excluding comments, support software for the autotesters and communications to other systems, is around 100 000 unique lines. A typical processor contains between 10 000 and 40 000 lines of source code, of which about half are typically from common functions, and the remainder form application code. In addition to the executable code, the PPS incorporates around 100 000 lines of configuration and calibration data per guardline associated with the reactor protection functions.”
Agreement between code readability ratings given by students
I have previously written about how we know nothing about code readability and questioned how the information content of expressions might be calculated. Buse and Weimer ran a very interesting experiment that asked subjects to rate short code snippets for readability (somebody please rerun this experiment using professional software developers).
I’m interested in measuring how well different students subjects agree with each other (I have briefly written about this before).
Short answer: Very little agreement between individual pairs, good agreement between rankings aggregated by year.
The longer answer is below as another draft section from my book Empirical software engineering with R book. As always comments welcome. R code and data here.
Readability
Source code is often said to have an attribute known as
A study by Buse and Weimer <book Buse_08> asked Computer Science students to rate short snippets of Java source code on a scale of 1 to 5. Buse and Weimer then searched for correlations between these ratings and various source code attributes they obtained by measuring the snippets.
Humans hold diverse opinions, have fragmented knowledge and beliefs about many topics and vary in their cognitive abilities. Any study involving human evaluation that uses an open ended problem on which subjects have had little experience is likely to see a wide range of responses.
Readability is a very nebulous term and students are unlikely to have had much experience working with source code. A wide range of responses is to be expected and the analysis performed here aims to check the degree of readability rating agreement between the subjects.
Data
The data made available by Buse and Weimer are the ratings, on a scale of 1 to 5, given by 121 students to 100 snippets of source code. The student subjects were drawn from those taking first, second and third/fourth year Computer Science degree courses and postgraduates at the researchers’ University (17, 65, 31 and 8 subjects respectively).
The postgraduate data was not used in this analysis because of the small number of subjects.
The source of the code snippets is also available but not used in this analysis.
Is the data believable?
The subjects were not given any instructions on how to rate the code snippets for readability. Also we don’t know what outcome they were trying to achieve when rating, e.g., where they rating on the basis of how readable they personally found the snippets to be, or rating on the basis of the answer they would expect to give if they were being tested in an exam.
The subjects were students who are learning about software development and many of them are unlikely to have had any significant development experience outside of the teaching environment. Experience shows that students vary significantly in their ability to read and write source code and a non-trivial percentage do not go on to become software developers.
Because the subjects are at an early stage of learning about code it is to be expected that their opinions about readability will change while they are rating the 100 snippets. The study did not include multiple copies of some snippets, this would have enabled the consistency of individual subject responses to be estimated.
The results of many studies <book Annett_02> has shown that most subject ratings are based on an ordinal scale (i.e., there is no fixed relationship between the difference between a rating of 2 and 3 and a rating of 3 and 4), that some subjects are be overly generous or miserly in their rating and that without strict rating guidelines different subjects apply different criteria when making their judgements (which can result a subject providing a list of ratings that is inconsistent with every other subject).
Readability is one of those terms that developers use without having much idea what they and others are really referring to. The data from this study can at most be regarded as treating readability to be whatever each subject judges it to be.
Predictions made in advance
Is the readability rating given to code snippets consistent between different students on a computer science course?
The hypothesis is that the between student consistency of the readability rating given to code snippets improves as students progress through the years of attending computer science courses.
Applicable techniques
There are a variety of techniques for estimating rater agreement. <Krippendorff’s alpha> can be applied to ordinal ratings given by two or more raters and is used here.
Subjects do not have to give the same rating to share some degree of consistent response. Two subjects may share a similar pattern of increasing/decreasing/stay the same ratings across snippets. The <Spearman rank correlation> coefficient can be used to measure the correlation between the rank (i.e., relative value within sequence) of two sequences.
Results
When creating the snippets the researchers had no method of estimating what rating subjects would give to them and so there is no reason to expect a uniform distribution of rating values or any other kind of distribution of rating values.
The figure below is a boxplot of the rating of the first 50 code snippets rated by second year students and suggests that many subject ratings are within ±1 of each other.
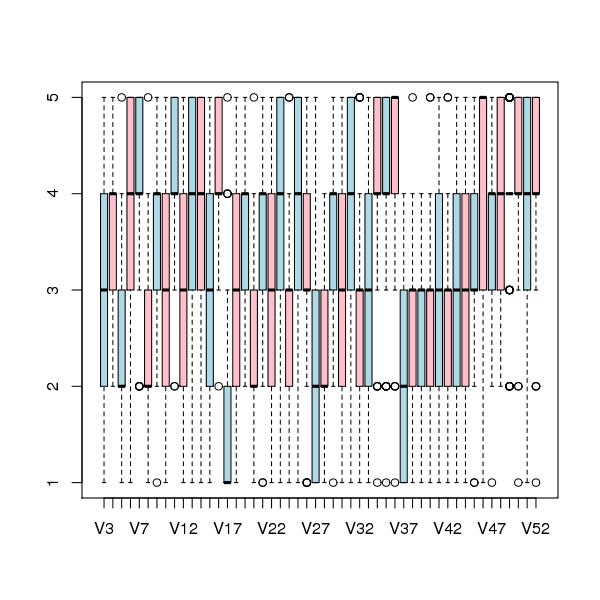
Figure 1. Boxplot of ratings given to snippets 1 to 50 by second year students (colors used to help distinguish boxplots for each snippet).
Between subject rating agreement
The Krippendorff alpha and mean Spearman rank correlation coefficient (the coefficient is calculated for every pair of subjects and the mean value taken) was obtained using the kripp.alpha and meanrho functions from the irr package (a <Jackknife> was used to obtain the following 95% confidence bounds):
Krippendorff's alpha cs1: 0.1225897 0.1483692 cs2: 0.2768906 0.2865904 cs4: 0.3245399 0.3405599 mean Spearman's rho cs1: 0.1844359 0.2167592 cs2: 0.3305273 0.3406769 cs4: 0.3651752 0.3813630 |
Taken as a whole there is a little of agreement. Perhaps there is greater consensus on the readability rating for a subset of the snippets. Recalculating using only using those snippets whose rated readability across all subjects, by year, has a standard deviation less than 1 (around 22, 51 and 62% of snippets respectively) shows some improvement in agreement:
Krippendorff's alpha cs1: 0.2139179 0.2493418 cs2: 0.3706919 0.3826060 cs4: 0.4386240 0.4542783 mean Spearman's rho cs1: 0.3033275 0.3485862 cs2: 0.4312944 0.4443740 cs4: 0.4868830 0.5034737 |
Between years comparison of ratings
The ratings from individual subjects is only available for one of their years at University. Aggregating the answers from all subjects in each year is one method of obtaining readability information that can be used to compare the opinions of students in different years.
How can subject ratings be aggregated to rank the 100 code snippets in order of what a combined group consider to be readability? The relatively large variation in mean value of the snippet ratings across subjects would result in wide confidence bounds for an aggregate based on ratings. Mapping each subject’s rating to a ranking removes the uncertainty caused by differences in mean subject ratings.
With 100 snippets assigned a rating between 1 and 5 by each subject there are going to be a lot of tied rankings. If, say, a subject gave 10 snippets a rating of 5 the procedure used is to assign them all the rank that is the mean of the ranks the 10 of them would have occupied if their ratings had been very slightly different, i.e., (1+2+3+4+5+6+7+8+9+10)/10 = 5.5. This process maps each students readability ratings to readability rankings, the next step is to aggregate these individual rankings.
The R_package[RankAggreg] package contains a variety of functions for aggregating a collection rankings to obtain a group ranking. However, these functions use the relative order of items in a vector to denote rank, and this form of data representations prevents them supporting ranked lists containing items having the same rank.
For this analysis a simple aggregate ranking algorithm using Borda’s method <book lin_10> was implemented. Borda’s method for creating an aggregate ranking operates on one item at a time, combining all of the subject ranks for that item into a single rank. Methods for combining ranks include taking their mean, their geometric mean and the square-root of the sum of their squares; the mean value was used for this analysis.
An aggregate ranking was created for subjects in years one, two and four and the plot below compares the ranking between 1st/2nd year students (left) and 2nd/4th year students (right). The order of the second year student snippet rankings have been sorted and the other year rankings for the snippets mapped to the corresponding position.
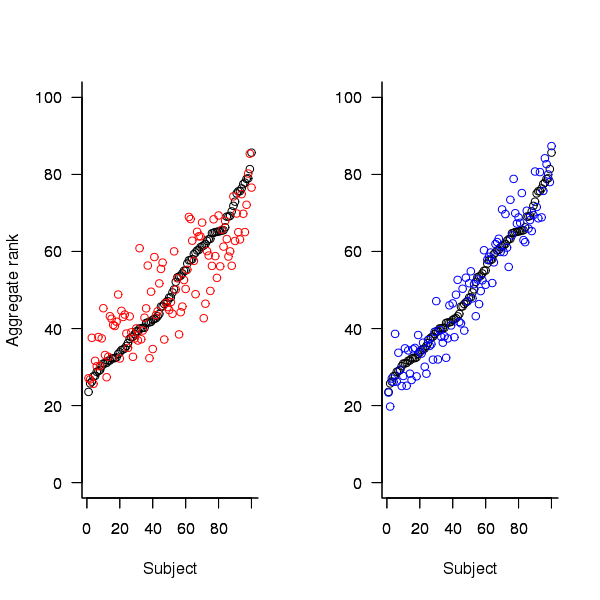
Figure 2. Aggregated ranking of snippets by subjects in years 1 and 2 (red and black) and years 2 and 4 (black and blue). Snippets have been sorted by year 2 ranking.
The above plot seems to show that at the aggregated year level there is much greater agreement between the 2nd/4th years than any other year pairing and measuring the correlation between each of the years using <Kendall’s tau>:
cs1.tau cs2.tau cs3.tau 0.6627602 0.6337914 0.8199636 |
confirms the greater agreement between this aggregate year pair.
Individual subject correlation to year aggregate ranking
To what extend to subject ratings correlate with their corresponding year aggregate? The following plot gives the correlation, using Kendall’s tau, between each subject and their corresponding year aggregate ranking.
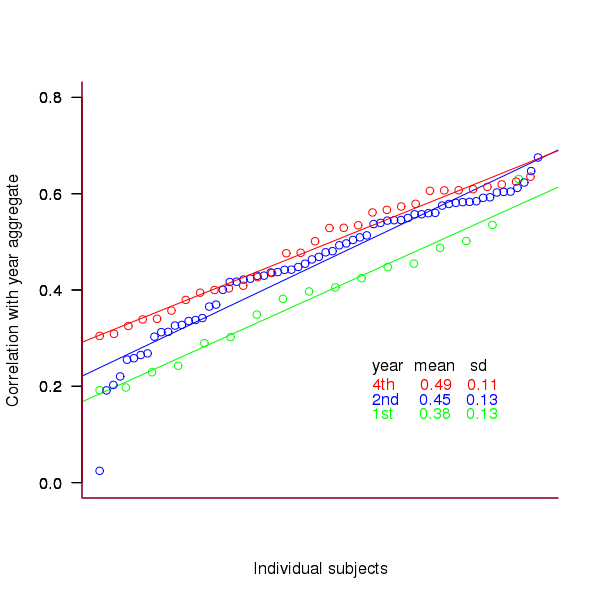
Figure 3. Correlation, using Kendall’s tau, between each subject and their corresponding year aggregate ranking.
The least squares fit shows that the variation in correlation across subjects in any year is very similar (removal of outliers in year 2 would make the lines almost parallel); the mean again shows a correlation that increases with year.
Discussion
The extent to which this study’s calculated values of rater agreement and correlation are considered worthy of further attention depends on the use to which the results will be put.
- From the perspective of trained raters the subject agreement in this study is very low and the rating have no further use.
- From the research perspective the results show that the concept of readability in the computer science student population has some non-zero substance to it that might be worth further study.
- From an overall perspective this study provides empirical evidence for a general lack of consensus on what constitutes readability.
It is not surprising that there is little agreement between student subjects on their readability rating, they are unlikely to have had much experience reading code and have not had any training in rating code for readability.
Professional developers will have spent years working with code and this experience is likely to have resulted in the creation of stable opinions on code readability. While developers usually work with code that is much longer than the few lines contained in the snippets used by Buse and Weimer, this experiment format is easy to administer and supports a fine level of control, i.e., allows a small set of source attributes of interest to be presented while excluding those not of interest. Repeating this study using such people as subjects would show whether this experience results in convergence to general agreement on the readability rating of code.
Summary of findings
The agreement between students readability ratings, for short snippets of code, improves as the students progress through course years 1 to 4 of a computer science degree.
While there is very good aggregated group agreement on the relative ranking of the readability of code snippets there is very little agreement between pairs of individuals.
- Two students chosen at random from within a year will have a low Spearman rank correlation coefficient for their rating of code snippet readability.
- Taken as a yearly aggregate there is a high degree of agreement between years two and four and less, but still good agreement between year 1 and other years.
- There is a broad range of correlations, from poor to good, between year aggregates and student subjects in the corresponding year.
Developers do not remember what code they have written
The size distribution of software components used in building many programs appears to follow a power law. Some researchers have and continue to do little more than fit a straight line to their measurements, while those that have proposed a process driving the behavior (e.g., information content) continue to rely on plenty of arm waving.
I have a very simple, and surprising, explanation for component size distribution following power law-like behavior; when writing new code developers ignore the surrounding context. To be a little more mathematical, I believe code written by developers has the following two statistical properties:
- nesting invariance. That is, the statistical characteristics of code sequences does not depend on how deeply nested the sequence is within
if/for/while/switchstatements, - independent of what went immediately before. That is the choice of what statement a developer writes next does not depend on the statements that precede it (alternatively there is no short range correlation).
Measurements of C source show that these two properties hold for some constructs in some circumstances (the measurements were originally made to serve a different purpose) and I have yet to see instances that significantly deviate from these properties.
How does writing code following these two properties generate a power law? The answer comes from the paper Power Laws for Monkeys Typing Randomly: The Case of Unequal Probabilities which proves that Zipf’s law like behavior (e.g., the frequency of any word used by some author is inversely proportional to its rank) would occur if the author were a monkey randomly typing on a keyboard.
To a good approximation every non-comment/blank line in a function body contains a single statement and statements do not often span multiple lines. We can view a function definition as being a sequence of statement kinds (e.g., each kind could be if/for/while/switch/assignment statement or an end-of-function terminator). The number of lines of code in a function is closely approximated by the length of this sequence.
The two statistical properties listed above allow us to treat the selection of which statement kind to write next in a function as mathematically equivalent to a monkey randomly typing on a keyboard. I am not suggesting that developers actually select statements at random, rather that the set of higher level requirements being turned into code are sufficiently different from each other that developers can and do write code having the properties listed.
Switching our unit of measurement from lines of code to number of tokens does not change much. Every statement has a few common forms that occur most of the time (e.g., most function calls contain no parameters and most assignment statements assign a scalar variable to another scalar variable) and there is a strong correlation between lines of code and token count.
What about object-oriented code, do developers follow the same pattern of behavior when creating classes? I am not aware of any set of measurements that might help answer this question, but there have been some measurements of Java that have power law-like behavior for some OO features.
Fingerprinting the author of the ZeuS Botnet
The source code of the ZeuS Botnet is now available for download. I imagine there are a few organizations who would like to talk to the author(s) of this code.
All developers have coding habits, that is they usually have a particular way of writing each coding construct. Different developers have different sets of habits and sometimes individual developers have a way of writing some language construct that is rarely used by other developers. Are developer habits sufficiently unique that they can be used to identify individuals from their code? I don’t have enough data to answer that question. Reading through the C++ source of ZeuS I spotted a few unusual usage patterns (I don’t know enough about common usage patterns in PHP to say much about this source) which readers might like to look for in code they encounter, perhaps putting name to the author of this code.
The source is written in C++ (32.5 KLOC of client source) and PHP (7.5KLOC of server source) and is of high quality (the C++ code could do with more comments, say to the level given in the PHP code), many companies could increase the quality of their code by following the coding standard that this author seems to be following. The source is well laid out and there are plenty of meaningful variable names.
So what can we tell about the person(s) who wrote this code?
- There is one author; this is based on consistent usage patterns and nothing jumping out at me as being sufficiently different that it could be written by somebody else,
- The author is fluent in English; based on the fact that I did not spot any identifiers spelled using unusual word combinations that often occur when a developer has a poor grasp of English. Update 16-May: skier.su spotted four instances of the debug message “Request sended.” which suggests the author is not as fluent as I first thought.
- The usage that jumped out at me the most is:
for(;; p++)if(*p == '\\' || *p == '/' || *p == 0) { ...
This is taking to an extreme the idea that if a ‘control header’ has a single statement associated with it, then they both appear on the same line; this usage commonly occurs with if-statements and this for/while-statement usage is very rare (this usage also occurs in the PHP code),
- The usage of
true/falsein conditionals is similar to that of newbie developers, for instance writing:return CWA(kernel32, RemoveDirectoryW)(path) == FALSE ? false : true; // and return CWA(shlwapi, PathCombineW)(dest, dir, p) == NULL ? false : true; // also return CWA(kernel32, DeleteFileW)(file) ? true : false;
in a function returning
boolinstead of:return CWA(kernel32, RemoveDirectoryW)(path); //and return CWA(shlwapi, PathCombineW)(dest, dir, p) != NULL // and return CWA(kernel32, DeleteFileW)(file);
The author is not a newbie developer, perhaps sometime in the past they were badly bitten by a Microsoft C++ compiler bug, found that this usage worked around the problem and have used it ever since,
- The author vertically aligns the assignment operator in statement sequences but not in a sequence of definitions containing an initializer:
// = not vertically aligned here DWORD itemMask = curItem->flags & ITEMF_IS_MASK; ITEM *cloneOfItem = curItem; // but is vertically aligned here: desiredAccess |= GENERIC_WRITE; creationDisposition = OPEN_ALWAYS;
Vertical alignment is not common and I would have said that alignment was more often seen in definitions than statements, the reverse of what is seen in this code,
- Non-terminating loops are created using
for(;;)rather than the more commonly seenwhile(TRUE), - The author is happy to use
gototo jump to the end of a function, not a rare habit but lots of developers have been taught that such usage is bad practice (I would say it depends, but that discussion belongs in another post), - Unnecessary casts often appear on negative constants (unnecessary in the sense that the compiler is required to implicitly do the conversion). This could be another instance of a previous Microsoft compiler bug causing a developer to adopt a coding habit to work around the problem.
Could the source have been processed by an code formatter to remove fingerprint information? I think not. There are small inconsistencies in layout here and there that suggest human error, also automatic layout tends to have a ‘template’ look to it that this code does not have.
Update 16 May: One source file stands out as being the only one that does not make extensive use of camelCase and a quick search finds that it is derived from the ucl compression library.
Unused function parameters
I have started redoing the source code measurements that appear in my C book, this time using a lot more source, upgraded versions of existing tools, plus some new tools such as Coccinelle and R. The intent is to make the code and data available in a form that is easy for others to use (I am hoping that one or more people will measure the same constructs in other languages) and to make some attempt at teasing out relationships in the data (previously the data was simply plotted with little or no explanation).
While it might be possible to write a paper on every language construct measured I don’t have the time to do the work. Instead I will use this blog to make a note of the interesting things that crop up during the analysis of each construct I measure.
First up are unused function parameters (code and data), which at around 11% of all parameters are slightly more common than unused local variables (Figure 190.1). In the following plot black circles are the total number of functions having a given number of parameters, red circles a given number of unused parameters, blue line a linear regression fit of the red circles, and the green line is derived from black circle values using a formula I concocted to fit the data and have no theoretical justification for it.
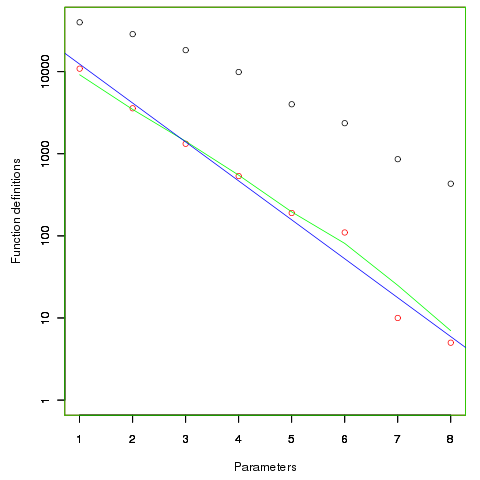
The number of functions containing a given number of unused parameters drops by around a factor of three for each additional unused parameter. Why is this? The formula I came up with for estimating the number of functions containing  unused parameters is:
unused parameters is:  , where
, where  is the total number of function definitions containing
is the total number of function definitions containing  parameters.
parameters.
Which parameter, for those functions defined with more than one, is most likely to be unused? My thinking was that the first parameter might either hold the most basic information (and so rarely be unused) or hold information likely to be superseded when new parameters are added (and so commonly be unused), either way I considered later parameters as often being put there for later use (and therefore more likely to be unused). The following plot is for eight programs plus the sum of them all; for all functions defined with between one and eight parameters the percentage of times the  ‘th parameter is unused is given. The source measured contained 104,493 function definitions containing more than one parameter with 16,643 of these functions having one or more unused parameter, there were a total of 235,512 parameters with 25,886 parameters being unused.
‘th parameter is unused is given. The source measured contained 104,493 function definitions containing more than one parameter with 16,643 of these functions having one or more unused parameter, there were a total of 235,512 parameters with 25,886 parameters being unused.
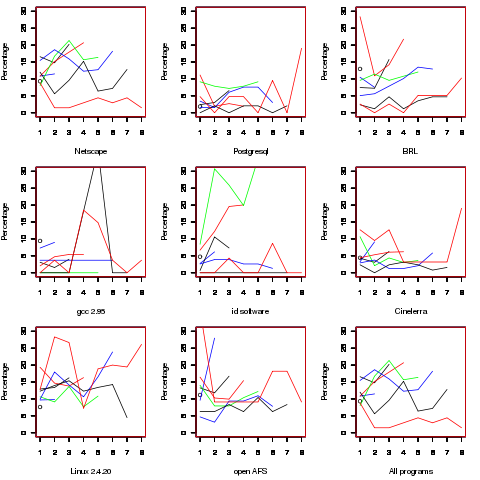
There is no obvious pattern to which parameters are likely to be unused, although a lot of the time the last parameter is more likely to be unused than the penultimate one.
Looking through the raw data I noticed that there seemed to be some clustering of names of unused parameters, in particular if the ‘th parameter was unused in two adjacent ‘unused parameter’ functions they often had the same name. The following plot is for all measured source and gives the percentage of same name occurrences; the matching process analyses function definitions in the order they occur within a source file and having found one unused parameter its name is compared against the corresponding parameter in the next function definition with the same number of parameters and having an unused parameter at the same position.
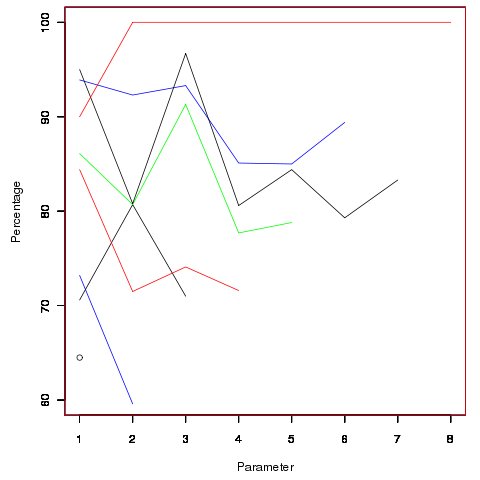
Before getting too excited about this pattern we should ask if something similar exists for the used parameters. When I get around to redoing the general parameter measurements I will look into this question. The numbers of occurrences for functions containing eight parameters is close to minimal.
The functions containing these same-name unused parameters appear to also have related function names. Is this a case of related function being grouped together, often sharing parameter names and when one of them has an unused parameter the corresponding parameter in the others is also unused?
Is there a correlation between number of parameters and number of statements, are functions containing lots of statements less likely to have unused parameters? What effect does software evolution have (most of this kind of research measures executable code not variable definitions)?
Simple generator for compiler stress testing source
Since writing my C book I have been interested in the problem of generating source that has the syntactic and semantic statistical characteristics of human written code.
Generating code that obeys a language’s syntax is straight forward. Take a specification of the syntax (say is some yacc-like form) and ‘generate’ each of the terminals/nonterminals on the right-hand-side of the start symbol. Nonterminals will lead to rules having right-hand-sides that in turn need to be ‘generated’, a random selection being made when a nonterminal has more than one possible rhs rule. Output occurs when a terminal is ‘generated’.
For the code to mimic human written code it is necessary to bias the random selection process; a numeric value at the start of each rhs rule can be used to specify the percentage probability of that rule being chosen for the corresponding nonterminal.
The following example generates a subset of C expressions; nonterminals in lowercase, terminals in uppercase and implemented as a call to a function having that name:
%grammar first_rule : def_ident " = " expr " ;\n" END_EXPR_STMT ; def_ident : MK_IDENT ; constant : MK_CONSTANT ; identifier : KNOWN_IDENT ; primary_expr : 30 constant | 60 identifier | 10 " (" expr ") " ; multiplicative_expr : 50 primary_expr | 40 multiplicative_expr " * " primary_expr | 10 multiplicative_expr " / " primary_expr ; additive_expr : 50 multiplicative_expr | 25 additive_expr " + " multiplicative_expr | 25 additive_expr " - " multiplicative_expr ; expr : START_EXPR additive_expr FINISH_EXPR ; |
A 250 line awk program (awk only because I use it often enough for simply text processing that it is second nature) translates this into two Python lists:
productions = [ [0], [ 1, 1, 1, # first_rule 0, 5, [2, 1001, 3, 1002, 1003, ], ], [ 2, 1, 1, # def_ident 0, 1, [1004, ], ], [ 4, 1, 1, # constant 0, 1, [1005, ], ], [ 5, 1, 1, # identifier 0, 1, [1006, ], ], [ 6, 3, 0, # primary_expr 30, 1, [4, ], 60, 1, [5, ], 10, 3, [1007, 3, 1008, ], ], [ 7, 3, 0, # multiplicative_expr 50, 1, [6, ], 40, 3, [7, 1009, 6, ], 10, 3, [7, 1010, 6, ], ], [ 8, 3, 0, # additive_expr 50, 1, [7, ], 25, 3, [8, 1011, 7, ], 25, 3, [8, 1012, 7, ], ], [ 3, 1, 1, # expr 0, 3, [1013, 8, 1014, ], ], ] terminal = [ [0], [ STR_TERM, " = "], [ STR_TERM, " ;\n"], [ FUNC_TERM, END_EXPR_STMT], [ FUNC_TERM, MK_IDENT], [ FUNC_TERM, MK_CONSTANT], [ FUNC_TERM, KNOWN_IDENT], [ STR_TERM, " ("], [ STR_TERM, ") "], [ STR_TERM, " * "], [ STR_TERM, " / "], [ STR_TERM, " + "], [ STR_TERM, " - "], [ FUNC_TERM, START_EXPR], [ FUNC_TERM, FINISH_EXPR], ] |
which can be executed by a simply interpreter:
def exec_rule(some_rule) : rule_len=len(some_rule) cur_action=0 while (cur_action < rule_len) : if (some_rule[cur_action] > term_start_base) : gen_terminal(some_rule[cur_action]-term_start_base) else : exec_rule(select_rule(productions[some_rule[cur_action]])) cur_action+=1 productions.sort() start_code() ns=0 while (ns < 2000) : # Loop generating lots of test cases exec_rule(select_rule(productions[1])) ns+=1 end_code() |
Naive syntax-directed generation results in a lot of code that violates one or more fundamental semantic constraints. For instance the assignment (1+1)=3 is syntactically valid in many languages, which invariably specify a semantic constraint on the lhs of an assignment operator being some kind of modifiable storage location. The simplest solution to this problem is to change the syntax to limit the kinds of constructs that can be generated on the lhs of an assignment.
The hardest semantic association to get right is the connection between variable declarations and references to those variables in expressions. One solution is to mimic how I think many developers write code, that is to generate the statements first and then generate the required definitions for the appropriate variables.
A whole host of minor semantic issues require the syntax generated code to be tweaked, e.g., division by zero occurs more often in untweaked generated code than human code. There are also statistical patterns within the semantics of human written code, e.g., frequency of use of local variables, that need to be addressed.
A few weeks ago the source of Csmith, a C source generator designed to stress the code generation phase of a compiler, was released. Over the years various people have written C compiler stress testers, most recently NPL implemented one in Java, but this is the first time that the source has been released. Imagine my disappointment on discovering that Csmith contained around 40 KLOC of code, only a bit smaller than a C compiler I had once help write. I decided to see if my ‘human characteristics’ generator could be used to create a compiler code generator stress tester.
The idea behind compiler code generator stress testing is to generate a program containing some complicated sequence of code, compile and run it, comparing the value produced against the value that is supposed to be produced.
I modified the human characteristics generator to produce pairs of statements like the following:
i = i_3 * i_6 & i_2 << i_7 ; chk_result(i, 3 * 6 & 2 << 7, __LINE__); |
the second argument to chk_result is the value that i should contain (while generating the expression to assign to i the corresponding constant expression with the variables replaced by their known values is also created).
Having the compiler evaluate the constant expression simplifies the stress tester and provides another check that the compiler gets things right (or gets two different things wrong in the same way, in which case we probably don’t get to see any failure message). The first gcc bug I found concerned this constant expression (in fact this same compiler bug crops up with alarming regularity in the generated code).
As previously mentioned connecting variables in expressions to a corresponding definition is a lot of work. I simplified this problem by assuming that an integer variable i would be predefined in the surrounding support code and that this would be the only variable ever assigned to in the generated code.
There is some simple house-keeping that wraps everything within a program and provides the appropriate variable definitions.
The grammar used to generate full C expressions is 228 lines, the awk translator 252 lines and the Python interpreter 55 lines; just over 1% of Csmith in LOC and it is very easy to configure. However, an awful lot functionality needs to be added before it starts to rival Csmith, not least of which is support for assignment to more than one integer variable!
Hexadecimal usage in Google’s scanned books
After investigating programming language name usage in Google’s ngram viewer I decided to try something more specific. Hexadecimal literals are an interesting subproblem in optical character recognition; a little uncertainty in an image can result in a character sequence being equally viable as a word or a hexadecimal literal.
I downloaded all of the Google books 1-grams and started to experiment. I eventually considered any character sequence matching the pattern ^[0oO][xX][0-9a-fA-FoOl] for further analysis; that is ohh, Ohh and ell were treated as the corresponding digits.
This prefix matching reduced 473 million possibilities down to 89 thousand.
Next any character sequence containing a non-hex character (again ohh, Ohh and ell were treated as special cases) was removed, bringing the possibilities down to 20 thousand.
When did the first hexadecimal literal appear in print? I settled on a generous view of history, 1945; also the sequence oxo seemed surprisingly common and looking at a few of the contexts in which it occurred I decided that most of the usage related to chemical formula and removed all matches. The post-1945 and oxo checks removed a third of remaining character sequences.
It seems to me that if any hexadecimal literal appears in a book at least one more is likely to occur. Google does not provide a breakdown of each character sequence by book; for a given character sequence the total count for each year is given, along with the number of pages it occurred on in that year and the number of different books it appeared within in the year. If the number of occurrences of a character sequence in a given year equaled the number of different books I excluded the usage count; this reduced the number of matches from 13,729 to 7,292; with 319 unique character sequences.
Are the remaining of character sequences a reasonably accurate list of hexadecimal literals appearing in the books that Google has scanned? Is 0.15 hexadecimal literals per million words a reasonable value?
A while back I did some analysis of C source usage that included checking whether integer literals followed Benford’s law. Extracting the first non-zero digit from the character sequences extracted from Google books and comparing them with the C source hexadecimal data we get:
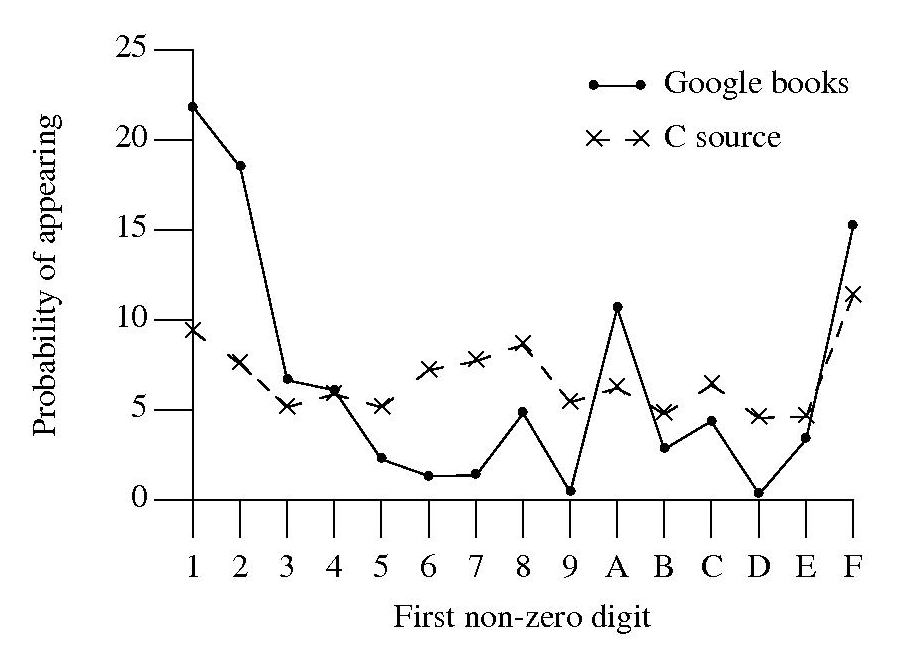
Both plots share ‘spikes’ at five values but the pattern of relative sizes is different. Perhaps the pattern of hexadecimal literal usage in C source is slightly different from what occurs in other languages, or perhaps the relatively large percentage of 1 occurs because ell is accepted.
The context in which a character sequenced occurred would probably be a very good indicator of whether it was a hexadecimal literal or not. Google only provide a subset of their 2-grams and any analysis of these will have to wait for another time; however I did quickly check to see whether the OCR process had resulted in a single literal being split into two separate sequences, a manual check of the 95 possible sequences I found showed that most were not good candidates for a split literal.
The final list of ‘hexadecimal literal’s and their occurrence counts is available for download.
SQL usage: schema evolution
My first serious involvement with SQL, about 15 years ago, was writing a parser for the grammar specified in the ISO SQL-92 Standard. One of the things that surprised me about SQL was how little source code was generally available (for testing) and the almost complete lack of any published papers on SQL usage (its always better to find out about where the pot-holes are from other peoples’ experience).
The source code availability surprie is largely answered by the very close coupling between source and data that occurs with SQL; most SQL source is closely tied to a database schema and unless you have a need to process exactly the same kind of data you are unlikely to have any interest having access to the corresponding SQL source. The growth in usage of MySQL means that these days it is much easier to get hold of large amounts of SQL (large is a relative term here, I suspect that there are probably many orders of magnitude fewer lines of SQL in existence than there is of other popular languages).
In my case I was fortunate in that NIST released their SQL validation suite for beta testing just as I started to test my parser (it had taken me a month to get the grammar into a manageable shape).
Published research on SQL usage continues to be thin on the ground and I was pleased to recently discover a paper combining empirical work on SQL usage with another rarely researched topic, declaration usage e.g., variables and types or in this case schema evolution (for instance, changes in the table columns over time).
The researchers only analyzed one database, the 171 releases of the schema used by Wikipedia between April 2003 and November 2007, but they also made their scripts available for download and hopefully the results of applying them to lots of other databases will be published.
Not being an experienced database person I don’t know how representative the Wikipedia figures are; the number of tables increased from 17 to 34 (100% increase) and the number of columns from 100 to 242 (142%). A factor of two increase sounds like a lot but I suspect that all but one these columns occupy a tiny fraction of the 14GB that is the current English Wikipedia.
Christmas book for 2010
I’m rather late with my list of Christmas books for 2010. While I do have a huge stack of books waiting to be read I don’t seem to have read many books this year (I have been reading lots of rather technical blogs this year, i.e., time/thought consuming ones) and there is only one book I would strongly recommend.
Anybody with even the slightest of interest in code readability needs to read
Reading in the Brain by Stanislaw Dehaene (the guy who wrote The Number Sense, another highly recommended book). The style of the book is half way between being populist and being an undergraduate text.
Most of the discussion centers around the hardware/software processing that takes place in what Dehaene refers to as the letterbox area of the brain (in the left occipito-temporal cortex). The hardware being neurons in the human brain and software being the connections between them (part genetically hardwired and part selectively learned as the brain’s owner goes through childhood; Dehaene is not a software developer and does not use this hardware/software metaphor).
{kind=link}
As any engineer knows, knowledge of the functional characteristics of a system are essential when designing other systems to work with it. Reading this book will help people separate out the plausible from the functionally implausible in discussions about code readability.
Time and again the reading process has co-opted brain functionality that appears to have been designed to perform other activities. During the evolution of writing there also seems to have been some adaptation to existing processes in the brain; a lesson here for people designing code visualizations tools.
{kind=link}
{kind=link}
In my C book I tried to provide an overview of the reading process but skipped discussing what went on in the brain, partly through ignorance on my part and also a belief that we were a long way from having an accurate model. Dehaene’s book clearly shows that a good model of what goes on in the brain during reading is now available.
SEC wants prospectus source code to be published
The US Securities and Exchange Commission are proposing new rules involving the prospectuses for public offerings of asset-backed securities including publishing the source code used to calculate the contractual cash flow provisions.
Requiring that the source code used to perform the financial modeling for a prospectus be made available is an excellent idea. A prospectus document contains a huge number of technical details and more importantly for anybody trying to understand the thinking behind it, a lots of assumption. Writing a program requires that all necessary details be enumerated and appropriately connected together and more importantly creating code that can be meaningfully executed usually means making explicit any assumptions that were previously implicit.
There are parallels here with having access to the source code and data used to make climate predictions.
The authors of the proposals are naive to think that simply requiring source to be written in a language for which there is an open source implementation (i.e., Python) is all they need to specify for others to duplicate the program output generated by the proposer (I have submitted some suggestions to the SEC about the issues that need to be addressed). The suggestions that a formally defined language be used is equally naive.
The availability of this source code opens up some interesting commercial prospects. No, not selling analysis tools to financial institutions but selling them program fault information, e.g., under circumstance X the program incorrectly predicts A will happen when in fact B will actually happen. Of course companies know this will happen and will put a lot more effort into ensuring that their models/code is correct.
Will these disclosure rules change the characteristics of financial software? One characteristic that I’m sure will change is the percentage of swear words in the comments and identifiers.
Recent Comments