Archive
An attempt to shroud text from LLMs
Describe the items discussed in the following sentences: “phashyon es cycklyq. chuyldren donth wanth tew weywr chloths vat there pairent weywr. pwroggwrammyng languij phashyon hash phricksionz vat inycially inqloob impleementaision suppoort, lybrareyz (whych sloa doun adopsion, ant wunsh establysht jobz ol avaylable too suppourt ecksysting kowd (slowyng doun va demighz ov a langguij).”
I was at the {Tech: Europe} hackathon yesterday, and my ‘inspired’ idea was to transform sentences such that while people could (eventually) still understand them, LLMs would fail miserably.
My team-mates from the last hackathon applied too late to be accepted, pitching the idea to people without a team failed to convince anyone to join me, and the idea pitches I heard did not convince me to join someone else.
Many years ago, I implemented a sounds like tool, which generates character sequences that an English reader would recognise (perhaps slowly) as sounding like the input word (also used in a previous hack). Surely, replacing every word in a sentence with a randomly chosen sounds-like character sequence would seriously confuse LLMs (wrapper code around sounds like tool).
My ‘inspired’ idea failed hard with: Grok, ChatGPT, Deepseek (no sharable link), and Perplexity.
Grok’s response yesterday (this recent response does not begin by giving the corrected sentence):
The sentences provided contain numerous typographical errors, making them challenging to interpret. However, by correcting the likely typos, the intended meaning can be inferred as follows: Corrected Sentences: "Fashion is cyclical. Children don’t want to wear clothes that their parents wore. Programming language fashion has frictions that initially include implementation support, libraries (which slow down adoption), and once established, jobs are available to support existing code (slowing down the demise of a language)." |
Time to do some pivoting, with options including:
- Update source-like tool. LLMs operate on tokens, which are short common character sequences, which may or may not be complete words. The sounds-like tool could be enhanced to be token aware, and attempt to change all tokens within a word. While the tokenization sequence list varies between LLMs, I assume that most, say, 10,000 common character sequences are always treated as tokens. The list of GPT2 tokens is available.
- Narrow the use case. Anybody monitoring text messages will want to keep costs down by using as small a model as possible, and will likely want to keep the text in-house. Check the ability of small models to handle sounds-like sentences.
- Add non-sounds-like changes. For instance, adding underscores, changing some letters to upper case, and changing ‘l’ to the number ‘1’.
With only a few hours available (this was essentially an afternoon hack), I opted to investigate the performance of small models.
Below is the edited output (‘…’ indicates further text was generated) of models containing 14.8, 8.29, 4.02, 2.03 billion parameters. These Open weights models ran under LM Studio on my local machine (which does not have a GPU, so the response is sluuuugish).
I was surprised at how well the models performed, particularly the 4.02B parameter reasoning model. The responses did not start to go wrong until the model size was reduced to 2 billion parameters. We will have to wait and see if tiny models continue to improve, such that a model containing under a billion parameters can reliably interpret sounds-like sentences.
I’m still clinging to the possibility that sentences can be modified such that humans can understand them, but LLMs cannot (AGI, which LLMs are not close to achieving, will by definition have human level ability).
deepseek-r1-distil-qwen-14b has 14.8B parameters and is currently a leading model at this size. Its response was:
The sentences discuss several items:
Fashion Cycles: The first sentence appears to suggest that fashion (phashyon)
is cyclic (cycklyq), meaning it follows repeating trends or cycles.
Children's Preferences for Clothing: The second sentence discusses children
not wanting to wear the same clothes as their parents, implying a
generational difference in fashion preferences.
Programming Language Trends and Challenges:
o The third sentence talks about programming languages (pwroggwrammyng languij)
having fads or trends (phashyon hash phricksionz), which are initially
implemented but can slow down adoption due to libraries taking time to develop.
o It also mentions that these fads may eventually lead to the decline of
existing codebases (ecksysting kowd) because they become outdated or unsupported.
Overall, the sentences touch on fashion trends, generational differences in
clothing preferences, and challenges related to programming language adoption
and maintenance.
2.68 tok/sec • 826 tokens • 29.94s to first token |
Perhaps vision models will not be as proficient with this kind of text. Qwen2.5-VL-7B-Instruct is an 8.29B parameter vision model.
The sentences you've provided appear to be a mix of misspelled and jumbled words, making it challenging to understand the intended meaning. However, I'll attempt to interpret them based on common themes in technology and programming. 1. "phashyon es cycklyq." - This seems to be an incomplete or corrupted phrase that might refer to something related to fashion being cyclical. 2. "chuyldren donth wanth tew weywr chloths vat there pairent weywr." - This appears to be a misspelled and jumbled sentence, possibly referring to children not wanting to wear clothes their parents wore when they were young. 3. "pwroggwrammyng languij phashyon hash phricksionz vat inycially inqloob impleementaision suppoort." - This phrase seems to be discussing programming languages and the friction or challenges associated with implementing initial support for new features or functionalities within these languages. 4. "lybrareyz (whych sloa doun adopsion, ant wunsh establysht jobz ol avaylable too suppourt ecksysting kowd (slowyng doun va demighz ov a langguij)" - This part appears to be discussing libraries that slow down adoption and the desire for established jobs or roles available to support existing code, which in turn slows down development of languages. In summary: ... 4.06 tok/sec • 392 tokens • 13.46s to first token |
Qwen3-4b is a 4.02B parameter model with reasoning abilities:
Thought for 2 minutes 47 seconds The sentences discuss two main topics: 1. A Metaphorical Observation: "Children don’t want to wear clothes their parents wear." This is a metaphorical statement suggesting that individuals (e.g., developers) may resist adopting technologies or practices that are inherited from older generations (e.g., legacy code, outdated programming languages). It highlights a generational or cultural resistance to following established norms. 2. Technical Discussion on Programming Languages and Libraries: "Programming languages have features initially included in implementation support, libraries that slow down adoption and establish jobs for existing code, slowing the decline of a language." This refers to: o Programming Language Features: Some programming languages include built-in support for specific functionalities (e.g., syntax, tools) that are essential for development. o Libraries and Ecosystems: Libraries or frameworks in a programming language can influence adoption by providing tools that simplify tasks. However, if these libraries become outdated or complex, they may slow down the adoption of newer versions of the language. o Maintenance and Decline: The text suggests that maintaining compatibility with existing code (e.g., legacy systems) can help sustain a programming language, even as newer technologies emerge. This creates a tension between innovation and backward compatibility. Key Concepts: o Metaphor vs. Technicality: The first part uses a metaphor to illustrate resistance to inherited practices, while the second part delves into technical aspects of software development. o Language Evolution: The discussion highlights how programming languages balance innovation (new features) with preservation (supporting existing code), which can affect their longevity and adoption. This interplay between metaphor and technical detail underscores themes of generational change, technological inertia, and the challenges of maintaining compatibility in software ecosystems. 5.59 tok/sec • 1290 tokens • 7.67s to first token |
Qwen3-1.7B is a 2.03B parameter model, i.e., a smaller version of Qwen3-4b used above.
Thought for 1 minutes 8 seconds The sentences discuss several interconnected themes, blending technical and metaphorical elements: 1. Phishing (Cyclic Behavior): The first sentence references "phashyon" (likely a misspelling of "phishing") as cyclic or recurring, suggesting phishing attacks that repeat or evolve over time. 2. Children's Clothing and Parental Influence: A metaphorical statement about children not wanting to wear clothes their parents wear, implying a generational or cultural disconnect in preferences or values. 3. Programming Languages and Technical Concepts: The text introduces complex technical terms: o Phishing Zones (possibly a misinterpretation of "phishing zones" as areas where phishing attacks occur). o Implementation Support and Libraries (e.g., libraries that slow down adoption or require stable ecosystems). o Ecosystems (referring to software or technical environments) and Job Creation in these systems. 4. Adoption and Slowdown: Libraries are described as "slowing down adoption" and "slowly reducing values over a language," suggesting challenges in integrating new technologies or standards. 5. Confusion and Mixed Language Elements: The text contains mixed syntax (e.g., "pwroggwrammyng" → "programming"), mistranslations, and unclear phrasing, likely due to linguistic errors or intentional ambiguity. Key Items Discussed:... 10.32 tok/sec • 1081 tokens • 2.93s to first token |
Thanks to our {Tech: Europe} hosts who kept us fed and watered.
Semantic vs phonetic similarity for word pairs: a weekend investigation
The Computational Semantics hackathon was one of the events I attended last weekend. Most if the suggested problems either looked like they could not reasonably be done in a weekend (it ran 10:00-17:00 on both days, I know academics hacks) or were uninspiring coding problems. Chatting to some of the academics present threw up an interesting idea that involved comparing word pair semantic and phonetic similarity (I have written about my interest in sounds-like and source code identifiers).
Team Semantic-sounds consisted of Pavel and yours truly (code and data).
The linguists I chatted to seemed to think that there would be a lot of word pairs that sounded alike and were semantically similar; I did not succeed it getting any of them to put a percentage to “a lot”. From the human communication point of view, words that both sound alike and have a similar meaning are likely to be confused with each other; should such pairs come into existence they are likely to quickly disappear, at least if the words are in common usage. Sound symbolism related issues got mentioned several times, but we did not have any data to check out the academic enthusiasm.
One of the datasets supplied by the organizers was word semantic similarity data extracted from the Google news corpus. The similarity measure is based on similarity of occurrence, e.g., the two sentences “I like licking ice-cream” and “I like eating ice-cream” suggest a degree of semantic similarity between the words licking and eating; given enough sentences containing licking and eating there are clever ways of calculating a value that can be viewed as a measure of word similarity.
The data contained 72,000+ words, giving a possible half a billion pairs (most having zero similarity). To prune this down a bit we took, for each word, the 150 other words that were most similar to it, giving around 10 million word pairs. Each word was converted to a phoneme sequence and a similarity distance calculated for each pair of phoneme sequences (which we called phonetic distance and claimed it was a measure of how similar the words sounded to each other).
The list of word pairs with high semantic/phonetic similarity was very noisy, with lots of pairs containing the same base word in plural, past tense or some other form, e.g., billion and billions. A Porter stemmer was used to remove all pairs where the words shared the same stem, reducing the list to 2.5 million pairs. Most of the noise now came from differences in British/American spelling. We removed all word pairs that contained a word that was not in the list of words that occurred in the common subset of the British and American dictionaries used by aspell; this reduced the list to half a million pairs.
The output contained some interesting pairs, including: faultless/flawless, astonishingly/astoundingly, abysmal/dismal and elusive/illusive. These look like rarely used words to me (not enough time to add in word frequency counts).
Some pairs had surprisingly low similarity, e.g., artifact/artefact (the British/American spelling equality idea has a far from perfect implementation). Is this lower than expected semantic similarity because there is a noticeable British/American usage difference? An idea for a future hack.
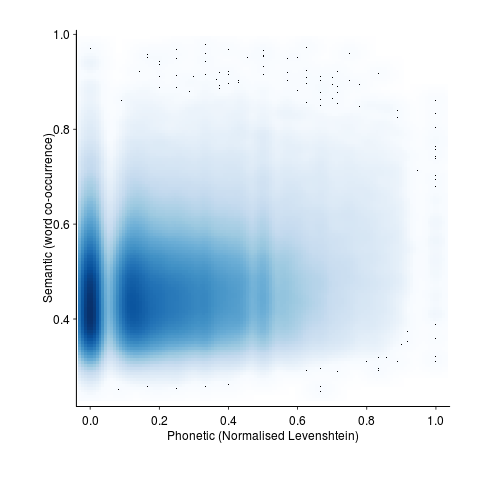
A smoothed scatter plot of semantic vs phonetic similarity (for the most filtered pair list) shows lots of semantically similar pairs that don’t sound alike, but a few that do (I suspect that most of these are noise that better stemming and spell checking will filter out). The following uses Levenshtein distance for phoneme similarity, normalised by the maximum distance for a given phoneme sequence with all phoneme differences having equal weight:
and using Jaro-Winkler distance (an alternative distance metric that is faster to calculate):
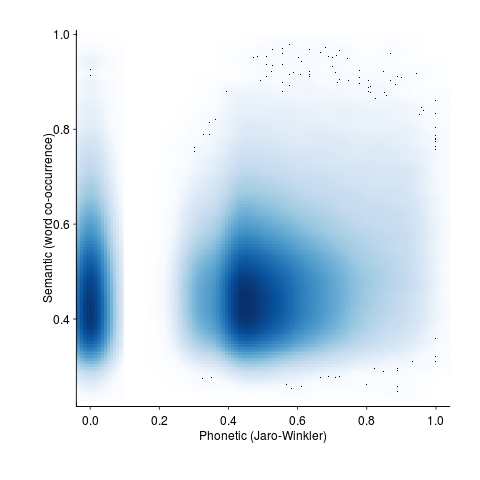
The empty band at low phonetic similarity is an artifact of the data being quantized (i.e., words contain a small number of components).
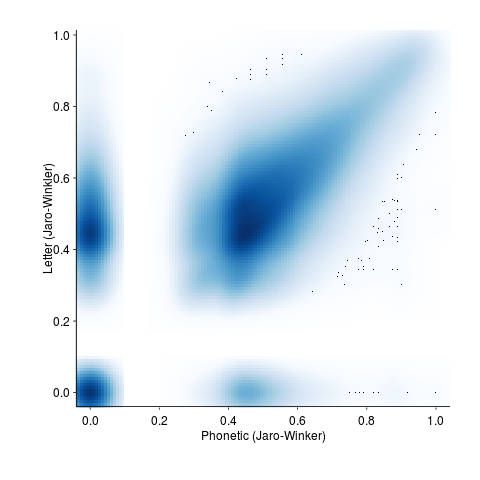
Is it worth going to the trouble of comparing phoneme sequences? Would comparing letter sequences be just as good? The following plot shows word pair letter distance vs phonetic similarity distance (there is a noticeable amount of off-diagonal data, i.e., for some pairs letter/phoneme differences are large):
Its always good to have some numbers to go with graphical data. The following is the number of pairs having a given phonetic similarity (remember the starting point was the top 150 most semantically similar pairs). The spikes are cause by the discrete nature of word components.
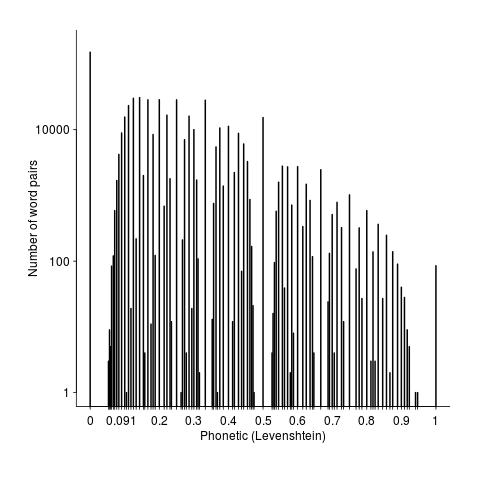
Squinting at the above it is possible to see an exponential decline as phonetic word similarity increases. It would be interesting to have enough data to display a meaningful 3D plot, perhaps a plane can be fitted (with a log scale on the z-axis).
Rather than using the Google news corpus data as the basis of word pair semantic similarity we could have used the synonym sets from Wordnet. This rather obvious idea did not occur to me until later Saturday and there was no time to investigate. How did the small number of people who created the Wordnet data come up with lists of synonyms? If they simply thought very hard they might have been subject to the availability bias, preferentially producing lists of synonyms that contained many words that sounded alike because those that did not sound alike were less likely to be recalled. Another interesting idea to check out at another hack.
It was an interesting hack and as often happens more new questions were raised than were answered.
Generating sounds-like and accented words
I have always been surprised by the approaches other people have taken to generating words that sound like a particular word or judging whether two words sound alike. The aspell program letter sequence is in its dictionary; the Soundex algorithm is often used to compare whether two words sound alike and has the advantage of being very simple and delivers results that many people seem willing to accept. Over 25 years ago I wrote some software that used a phoneme based approach and while sorting through a pile of papers recently I came across an old report used as the basis for that software. I decided to implement a word sounds-like tool to show people how I think sounds-like should be done. To reduce the work involved this initial tool is based on what I already know, which in some cases is very out of date.
Phonemes are the basic units of sound and any sounds-like software needs to operate on a word’s phoneme sequence, not its letter sequence. The way to proceed is to convert a word’s letter sequence to its phoneme sequence, manipulate the phoneme sequence to create other sequences that have a spoken form similar to the original word and then convert these new sequences back to letter sequences.
A 1976 report by Elovitz, Johnson, McHugh and Shore contains a list of 329 rules for converting a word’s letter sequence into a phoneme sequence. It seemed to me that this same set of rules could be driven in reverse to map a phoneme sequence back to a letter sequence (the complications involved in making this simple idea work will be discussed in another article).
Once we have a phoneme sequence how might it be modified to create similar sounding words?
The distinctive feature theory assigns ten or so features to every phoneme, these denote details such as such things as manner and place of articulation. I decided to use these features as the basis of a distance metric between two phonemes (e.g., the more features two phonemes had in common the more similar they sounded). The book “Phonology theory and analysis” by Larry M. Hyman contains the required table of phoneme/distinctive features. Yes, I am using a theory from the 1950s and a book from the 1970s, but to start with I want to recreate what I know can be done before moving on to use more modern theories/data.
In practice this approach generates too many letter sequences that just don’t look like English words. The underlying problem is that the letter/phoneme rules were not designed to be run in reverse. Rather than tune the existing rules to do a better job when run in reverse I used the simpler method of filtering using letter bigrams to remove non-English letter sequences (e.g., ‘ck’ is not acceptable at the start of a word letter sequence). In preInternet times word bigram information was obtained from specialist cryptographic publishers, but these days psychologists researching human reading are a very good source of reliable information (or at least one I am familiar with).
I have implemented this approach and the system currently supports the generation of:
- letter sequences that sound the same as the input word, e.g., cowd, coad, kowd, koad.
- letter sequences that sound similar to the input word, e.g., bite, dight, duyt, gight, guyt, might, muyt, pight, puyt, bit, byt, bait, bayt, beight, beet, beat, beit, beyt, boyt, boit, but, bied, bighd, buyd, bighp, buyp, bighng, buyng, bighth, buyth, bight, buyt
- letter sequences that sound like the input word said with a German accent, e.g., one, vun and woven, voughen, vuphen.
The output can be piped through a spell checker to remove nondictionary letter sequences.
How accurate are the various sequence translations? Based on a comparison against manual translation of several thousand words from the Brown corpus Elovitz et al claim around 90% of words in random text will be correctly translated to phonemes. I have not done any empirical analysis of the performance of the rules when used to convert phoneme sequences to letters; it will obviously be less than 90%.
The source code of the somewhat experimental tool is available for download. Please note that the code has only been built on Linux, is likely to be fragile in various places and needs a recent copy of the pcre library. Bug reports welcome.
Some of the uses for a word’s phoneme sequence include:
- matching names contained in information transcribed using different conventions or by different people (i.e., slight spelling differences).
- better word splitting at the end of line in LaTeX. Word splitting decisions are best made using sound units.
- better spell checking, particularly for non-native English speakers when coupled with a sound model of common mistakes made by speakers of other languages.
- aid to remembering partially forgotten words whose approximate sound can be remembered.
- inventing trendy spellings for words.
Where next?
Knowledge of the written and spoken word had moved forward in the last 25 years and various other techniques that might improve the performance of the tool are now available. My interest in the written, rather than the spoken, form of code means I have only followed written/sound conversion at a superficial level; reader suggestions on more modern theories, models and data sources that might be used to improve the tools performance are most welcome. A few of my own thoughts:
- As I understand it modern text to speech systems are driven by models derived through machine learning (i.e., some learning algorithm has processed lots of data). There might be existing models out there that can be used, otherwise the MRC Psycholinguistic Database is a good source for lots for word phoneme sequences and perhaps might be used to learn rules for both letter to phoneme and phoneme to letter conversion.
- Is Distinctive feature theory the best basis for a phoneme sounds-like metric? If not which theory should be used and where can the required detailed phoneme information be found? Hyman gives yes/no values for each feature while the first edition of Ladeforded’s “A Course in Phonetics” gives percentage contribution values for the distinctive features of some phonemes; subsequent editions don’t include this information. Is a complete table of percentage contribution of each feature to every phoneme available somewhere?
- A more sophisticated approach to sounds-like would take phoneme context into account. A slightly less crude approach would be to make use of phoneme bigram information extracted from the MRC database. What is really needed is a theory of sounds-like and some machine usable rules; this would hopefully support the adding and removal of phonemes and not just changing existing ones.
As part of my R education I plan to create an R sounds-like package.
In the next article I will talk about how I used and abused the PCRE (Perl Compatible Regular Expressions) library to recognize a context dependent set of rules and generate corresponding output.
Incorrect spelling
While even a mediocre identifier name can provide useful information to a reader of the source a poorly chosen name can create confusion and require extra effort to remember. An author’s good intent can be spoiled by spelling mistakes, which are likely to be common if the developer is not a native speaker of the English (or whatever natural language is applicable).
Identifiers have characteristics which make them difficult targets for traditional spell checking algorithms; they often contain specialized words, dictionary words may be abbreviated in some way (making phonetic techniques impossible) and there is unlikely to be any reliable surrounding context.
Identifiers share many of the characteristics of search engine queries, they contain a small number of words that don’t fit together into a syntactically correct sentence and any surrounding context (e.g., previous queries or other identifiers) cannot be trusted. However, search engines have their logs of millions of previous search queries to fall back on, enabling them to suggest (often remarkably accurate) alternatives to non-dictionary words, specialist domains and recently coined terms. Because developers don’t receive any feedback on their spelling mistakes revision control systems are unlikely to contain any relevant information that can be mined.
One solution is for source code editors to require authors to fully specify all of the words used in an identifier when it is declared; spell checking and suitable abbreviation rules being applied at this point. Subsequent uses of the identifier can be input using the abbreviated form. This approach could considerably improve consistency of identifier usage across a project’s source code (it could also flag attempts to use both orderings of a word pair, e.g., number count and count number). The word abbreviation mapping could be stored (perhaps in a comment at the end of the source) for use by other tools and personalized developer preferences stored in a local configuration file. It is time for source code editors to start taking a more active role in helping developers write readable code.
Recent Comments