Archive
70% of new software engineering papers on arXiv are LLM related
Subjectively, it feels like LLMs dominate the software engineering research agenda. Are most researchers essentially studying “Using LLMs to do …”? What does the data on papers published since 2022, when LLMs publicly appeared, have to say?
There is usually a year or two delay between doing the research work and the paper describing the work appearing in a peer reviewed conference/journal. Sometimes the researcher loses interest and no paper appears.
Preprint servers offer a fast track to publication. A researcher uploads a paper, and it appears the next day, with a peer reviewed version appearing sometime later (or not at all). Preprint publication data provides the closest approximation to real-time tracking of research topics. arXiv is the major open-access archive for research papers in computing, physics, mathematics and various engineering fields. The software engineering subcategory is cs.SE; every weekday I read the abstracts of the papers that have been uploaded, looking for a ‘gold dust’ paper.
The python package arxivscraper uses the arXiv api to retrieve metadata associated with papers published on the site. A surprisingly short program extracted the 15,899 papers published in the cs.SE subcategory since 1st January 2022.
A paper’s titles had to capture people’s attention using a handful of words. Putting the name of a new tool/concept in the title is likely to attract attention. The three words in the phrase Large Language Model consume a lot of title space, but during startup the abbreviated form (i.e., LLM) may not be generally recognised. The plot below shows the percentage of papers published each month whose title (case-insensitive) is matched either the regular expression “llm” or “large language model” (code and data):

Peak Large Language Model appears to be at the end of 2024. As time goes by new phrases/abbreviations stop being new and attention is grabbed by other phrases. Did peak LLM in titles occur at the end of 2025?
A paper’s abstract summarises its contents and has space for a lot more words. The plot below shows the percentage of papers published each month whose abstract (case-insensitive) is matched by either the regular expression “llm” or “large language model” (code and data):
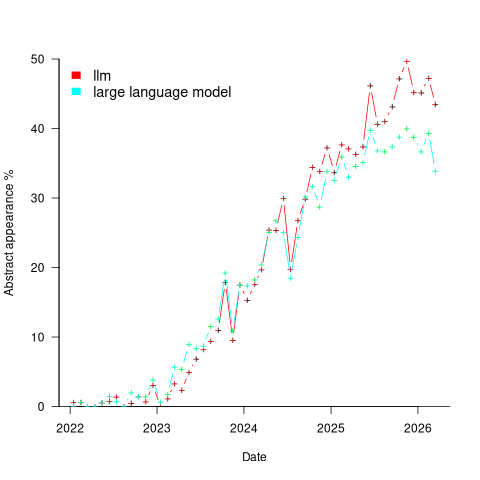
Peak, or plateauing, Large Language Model appears to be towards the end of 2025. Is the end of 2025 a peak of LLM in abstracts, or is it a plateauing with the decline yet to start? We should know by the end of this year.
Other phrases associated with LLMs are AI, artificial intelligence and agents. The plot below shows the percentage of papers published each month whose title (case-insensitive) is matched by each of the regular expressions “llm|large language model“, or “ ai[ ,.)]|artificial intellig“, or “agent” (code and data):
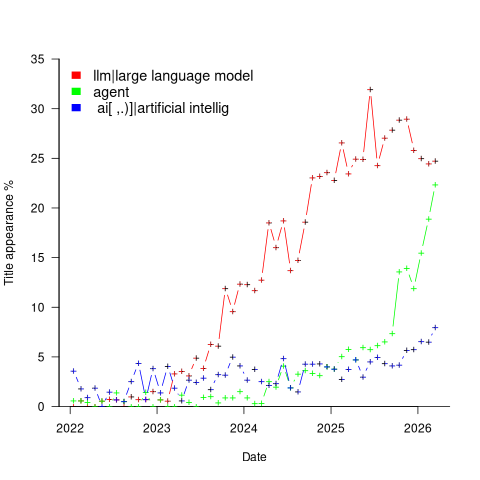
Counting the papers containing one or more of these LLM-related phrases gives an estimate of the number of software engineering papers studying this topic. The plot below shows the percentage of papers published each month whose title or abstract (case-insensitive) is matched by one or more of the regular expressions “llm|large language model“, or “ ai[ ,.)]|artificial intellig“, or “agent” (code and data):
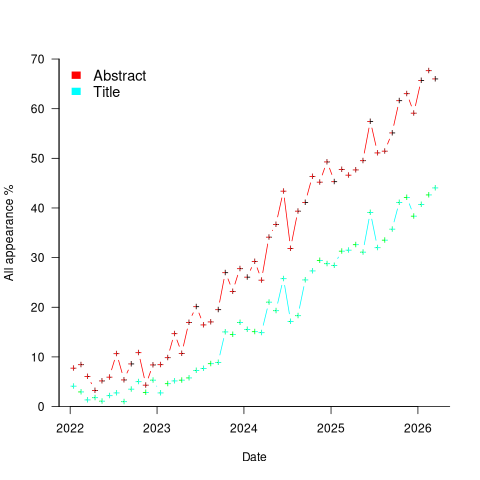
If the rate of growth is unchanged, around 18-month from now 100% of papers published in arXiv’s cs.SE subcategory will be LLM-related.
I expect the rate of growth to slow, and think it will stop before reaching 100% (I was expecting it to be higher than 70% in February). How much higher will it get? No idea, but herd mentality is a powerful force. Perhaps OpenAI going bankrupt will bring researchers to their senses.
Update
Martin Monperrus did an agentic replication of the analysis discussed in this post!
My 2025 in software engineering
Unrelenting talk of LLMs now infests all the software ecosystems I frequent.
- Almost all the papers published (week) daily on the Software Engineering arXiv have an LLM themed title. Way back when I read these LLM papers, they seemed to be more concerned with doing interesting things with LLMs than doing software engineering research.
- Predictions of the arrival of AGI are shifting further into the future. Which is not difficult given that a few years ago, people were predicting it would arrive within 6-months. Small percentage improvements in benchmark scores are trumpeted by all and sundry.
- Towards the end of the year, articles explaining AI’s bubble economics, OpenAI’s high rate of loosing money, and the convoluted accounting used to fund some data centers, started appearing.
Coding assistants might be great for developer productivity, but for Cursor/Claude/etc to be profitable, a significant cost increase is needed.
Will coding assistant companies run out of money to lose before their customers become so dependent on them, that they have no choice but to pay much higher prices?
With predictions of AGI receding into the future, a new grandiose idea is needed to fill the void. Near the end of the year, we got to hear people who must know it’s nonsense claiming that data centers in space would be happening real soon now.
I attend one or two, occasionally three, evening meetups per week in London. Women used to be uncommon at technical meetups. This year, groups of 2–4 women have become common in meetings of 20+ people (perhaps 30% of attendees); men usually arrive individually. Almost all women I talked to were (ex) students looking for a job; this was also true of the younger (early 20s) men I spoke to. I don’t know if attending meetups been added to the list of things to do to try and find a job.
Tom Plum passed away at the start of the year. Tom was a softly spoken gentleman whose company, PlumHall, sold a C, and then C++, compiler validation suite. Tom lived on Hawaii, and the C/C++ Standard committees were always happy to accept his invitation to host an ISO meeting. The assets of PlumHall have been acquired by Solid Sands.
Perennial was the other major provider of C/C++ validation suites. It’s owner, Barry Headquist, is now enjoying his retirement in Florida.
The evidence-based software engineering Discord channel continues to tick over (invitation), with sporadic interesting exchanges.
What did I learn/discover about software engineering this year?
Software reliability research is a bigger mess than I had previously thought.
I now regularly use LLMs to find mathematical solutions to my experimental models of software engineering processes. Most go nowhere, but a few look like they have potential (here and here and here).
Analysis/data in the following blog posts, from the last 12-months, belongs in my book Evidence-Based Software Engineering, in some form or other (2025 was a bumper year):
Naming convergence in a network of pairwise interactions
Lifetime of coding mistakes in the Linux kernel
Decline in downloads of once popular packages
Distribution of method chains in Java and Python
Modeling the distribution of method sizes
Distribution of integer literals in text/speech and source code
Percentage of methods containing no reported faults
Half-life of Open source research software projects
Positive and negative descriptions of numeric data
Impact of developer uncertainty on estimating probabilities
After 55.5 years the Fortran Specialist Group has a new home
When task time measurements are not reported by developers
Evolution has selected humans to prefer adding new features
One code path dominates method execution
Software_Engineering_Practices = Morals+Theology
Long term growth of programming language use
Deciding whether a conclusion is possible or necessary
CPU power consumption and bit-similarity of input
Procedure nesting a once common idiom
Functions reduce the need to remember lots of variables
Remotivating data analysed for another purpose
Half-life of Microsoft products is 7 years
How has the price of a computer changed over time?
Deep dive looking for good enough reliability models
Apollo guidance computer software development process
Example of an initial analysis of some new NASA data
Extracting information from duplicate fault reports
I visited Foyles bookshop on Charing cross road during the week (if you’re ever in London, browsing books in Foyles is a great way to spend an afternoon).
Computer books once occupied almost half a floor, but is now down to five book cases (opposite is statistics occupying one book case, and the rest of mathematics in another bookcase):

Around the corner, Gender Studies and LGBTQ+ occupies seven bookcases (the same as last year, as I recall):

Software_Engineering_Practices = Morals+Theology
Including the word science in the term used to describe a research field creates an aura of scientific enterprise. Universities name departments “Computer Science” and creationist have adopted the term “Creation Science”. The word engineering is used when an aura with a practical hue is desired, e.g., “Software Engineering” and “Consciousness Engineering”.
Science and engineering theories/models are founded on the principle of reproducibility. A theory/model achieves its power by making predictions that are close enough to reality.
Computing/software is an amalgam of many fields, some of which do tick the boxes associated with science and/or engineering practices, e.g., the study of algorithms or designing hardware. Activities whose output is primarily derived from human activity (e.g., writing software) are bedevilled by the large performance variability of people. Software engineering is unlikely to ever become a real engineering discipline.
If the activity known as software engineering is not engineering, then what is it?
To me, software engineering appears to be a form of moral theology. My use of this term is derived from the 1988 paper Social Science as Moral Theology by Neil Postman.
Summarising the term moral theology via its two components, i.e., morality+theology, we have:
Morality is a system of rules that enable people to live and work together for mutual benefit. Social groups operate better when its members cooperate with each other based on established moral rules. A group operating with endemic within group lying and cheating is unlikely to survive for very long. People cannot always act selfishly, some level of altruism towards group members is needed to enable a group to flourish.
Development teams will perform better when its members cooperate with each other, as opposed to ignoring or mistreating each other. Failure to successfully work together increases the likelihood that the project the team are working on will failure; however, it is not life or death for those involved.
The requirements of group living, which are similar everywhere, produced similar moral systems around the world.
The requirements of team software development are similar everywhere, and there does appear to be a lot of similarity across recommended practices for team interaction (although I have not studied this is detail and don’t have much data).
Theology is the study of religious beliefs and practices, some of which do not include a god, e.g., Nontheism, Humanism, and Religious Naturalism.
Religious beliefs provide a means for people to make sense of their world, to infer reasons and intentions behind physical events. For instance, why it rains or doesn’t rain, or why there was plenty of animal prey during last week’s hunt but none today. These beliefs also fulfil various psychological and emotional wants or needs. The questions may have been similar in different places, but the answers were essentially invented, and so different societies have ended up with different gods and theologies.
Different religions do have some features in common, such as:
- Creation myths. In software companies, employees tell stories about the beliefs that caused the founders to create the company, and users of a programming language tell stories about the beliefs and aims of the language designer and the early travails of the language implementation.
- Imagined futures, e.g., we all go to heaven/hell: An imagined future of software developers is that source code is likely to be read by other developers, and code lives a long time. In reality, most source code has a brief and lonely existence.
A moral rule sometimes migrates to become a religious rule, which can slow the evolution of the rule when circumstances change. For instance, dietary restrictions (e.g., must not eat pork) are an adaptation to living in some environments.
In software development, the morals of an Agile methodology perfectly fitted the needs of the early Internet, where existing ways of doing things did not exist and nobody knew what customers really wanted. The signatories of the Agile manifesto now have their opinions treated like those of a prophet (these 17 prophets are now preaching various creeds).
Agile is not always the best methodology to use, with a Waterfall methodology being a better match for some environments.
Now that the Agile methodology has migrated to become a ‘religious’ dogma, the reaction to suggestions that an alternative methodology be used are often what one would expect to questioning a religious belief.
For me this is an evolving idea.
My 2023 in software engineering
In a 2009 post, I predicted that Chinese and Indian developers would become a major influence in the next decade. This year, it was very noticeable that many of the authors of papers at major conferences had Asian names. I would say that, on average, papers with Asian author names were better than papers by authors with non-Asian names.
While LLMs dominated the software news this year, the lead time for research projects and conference submission deadlines meant that few of the papers accepted at this year’s top ranked conferences were LLM based, e.g., around 5% at ICSE. I expect there will be a much higher percentage of LLM based papers in 2024, which I think will be a disaster for software engineering research, at least in the short term. From what I have seen and read, much of LLM based software engineering is driven by fashion and/or a desire to gain experience that leads to a job in AI. Discovering something useful about software development takes a back seat (the current fashionable topic, butterfly collecting, at least produces potentially useful datasets). I think that LLMs are going to be very useful for analyzing text data, e.g., named entity recognition.
London based, software related meetups have come back to life. I go to around 1-2 a week, and the regular good ones include: Internet of Things, Extreme Tuesday Club, London Prompt Engineers, and London R. On the academic front, I have started attending the software reliability seminars at Imperial, and funding means that the excellent Crest Open Workshops are down to two a year. There were a handful of hackathons this year, and I got to go to one of them, a LLM hackathon.
Not usually software specific: Newspeak House hosts a variety of events that are often attended by many developers and those associated with the rationalist community. I attend maybe 2–3 events a month.
What did I learn/discover about software engineering this year?
- A small team estimation dataset showed the same kinds of patterns seen in larger teams,
- more cost/benefit analysis of software engineering activities here and here,
- data on Cobol source is very rare, and I found some,
- programs often continue to work very well in the presence of serious coding mistakes; I discovered some conditions where this occurs (to be continued next year),
- yet more debunking of software folklore: Optimal function length, and Hardware/Software cost ratio,
- I fell down the rabbit hole of early computer performance and their benchmarks.
The evidence-based software engineering Discord channel ticks over (invitation), with sporadic interesting exchanges.
Who are the famous academics in software engineering?
Who are today’s ‘famous’ academics in software engineering?
Famous as in, you can mention their name when chatting with general software developers, and expect those present to have heard of them, or you have heard their names dropped into a conversation, say, at least 3+ times this year (I’m excluding academics who are famous within one specific niche of software engineering). Academic, as in, works in an institution of secondary or tertiary higher learning.
When I started out in industry, the works of Knuth and Dijkstra were cited (not always accurately), people would talk about Ted Codd’s latest position on how best to structure a database. Tony Hoare later became known through his books, and Leslie Lamport for distributed systems and perhaps LaTeX. In very large niches, William Kahan for numerical analysis, and Barbara Liskov for the Liskov substitution principle.
Anyone suggesting Kernighan and Ritchie, of C and Unix fame, is overlooking the fact they worked in an industrial research lab.
A book series continues to maintain Knuth’s fame, while Dijkstra kept himself in the news by being a source of controversial quotes for industry journalists, and for kicking off the Go-To statement considered harmful debate (the latter is likely the reason that anybody has heard of him today). Has Kahan escaped his niche, even though use of floating-point arithmetic is now perhaps even more niche than it used to be?
How might academics become famous?
Widely used algorithms/metrics/techniques named after a person generates a kind of anonymous name recognition. For instance, Halstead complexity metric and McCabe’s cyclomatic complexity metric, and from the 1990s Shor’s algorithm.
Some people achieve fame through their association with a language. Academic name/language pairs include: McCarthy/Lisp, Wirth/Pascal, Stroustrup/C++ (worked in industry, university, industry, university), Peyton Jones/Haskell (university, industrial research, industry), Leroy/OCaml, Meyer/Eiffel.
An influential book, or widely read blog can generate a kind of fame.
Many academics have written an ‘algorithms’ book, and readers may have fond memories of the particular book they used as an undergraduate. Barry Boehm wrote “Software Engineering Economics”, but is more likely to be known for the model he spent his life promoting, i.e., the COCOMO model.
Fred Brooks, author of one of the most famous books in software engineering The Mythical Man Month, was not an academic worked in industry and then academia.
I have always been surprised by how many Turing award winners I have never heard of, or while recognizing a name am completely unfamiliar with their work. I am less surprised by my failure to recognise around half the names in the Wikipedia category software engineering researchers.
A few people are known because of the widespread use of their software (Linus Torvalds has never been an academic). Richard Stallman, employed as an academic, originally became famous as the author of the GNU version of emacs and gcc; the fame from the Free Software Foundation came after copyleft took off.
Are there academics who have become ‘famous’ in software engineering this century? I’m not in a position to answer this because I don’t read introductory software books, and generally avoid bike-shed discussions.
Does the resurgence of interest in AI mean that Judea Pearl’s fame is no longer niche?
I do read recent academic papers, and the only person on the list of most frequently cited authors in my evidence-based software engineering book with any claim to fame, researches cognitive neuroscience, i.e., Stanislas Dehaene.
Is software engineering a field where it is possible for a person, academic or otherwise, to become famous?
If there are fame worthy discoveries waiting to be made, or fame worthy software engineering book waiting to be written, how likely is it that the people responsible will be academics? A lot of the advances in software engineering have been made and continue to be made by those working in industry.
Suggestions relating to (in)famous academics welcome.
Anthropological studies of software engineering
Anthropology is the study of humans, and as such it is the top level research domain for many of the human activities involved in software engineering. What has been discovered by the handful of anthropologists who have spent time researching the tiny percentage of humans involved in writing software?
A common ‘discovery’ is that developers don’t appear to be doing what academics in computing departments claim they do; hardly news to those working in industry.
The main subfields relevant to software are probably: cultural anthropology and social anthropology (in the US these are combined under the name sociocultural anthropology), plus linguistic anthropology (how language influences social life and shapes communication). There is also historical anthropology, which is technically what historians of computing do.
For convenience, I’m labelling anybody working in an area covered by anthropology as an anthropologist.
I don’t recommend reading any anthropology papers unless you plan to invest a lot of time in some subfield. While I have read lots of software engineering papers, anthropologist’s papers on this topic are often incomprehensible to me. These papers might best be described as anthropology speak interspersed with software related terms.
Anthropologists write books, and some of them are very readable to a more general audience.
The Art of Being Human: A Textbook for Cultural Anthropology by Wesch is a beginner’s introduction to its subject.
Ethnography, which explores cultural phenomena from the point of view of the subject of the study, is probably the most approachable anthropological research. Ethnographers spend many months living with a remote tribe, community, or nowadays a software development company, and then write-up their findings in a thesis/report/book. Examples of approachable books include: “Engineering Culture: Control and Commitment in a High-Tech Corporation” by Kunda, who studied a large high-tech company in the mid-1980s; “No-Collar: The Humane Workplace and its Hidden Costs” by Ross, who studied an internet startup that had just IPO’ed, and “Coding Freedom: The Ethics and Aesthetics of Hacking” by Coleman, who studied hacker culture.
Linguistic anthropology is the field whose researchers are mostly likely to match developers’ preconceived ideas about what humanities academics talk about. If I had been educated in an environment where Greek and nineteenth century philosophers were the reference points for any discussion, then I too would use this existing skill set in my discussions of source code (philosophers of source code did not appear until the twentieth century). Who wouldn’t want to apply hermeneutics to the interpretation of source code (the field is known as Critical code studies)?
It does not help that the software knowledge of many of the academics appears to have been acquired by reading computer books from the 1940s and 1950s.
The most approachable linguistic anthropology book I have found, for developers, is: The Philosophy of Software Code and Mediation in the Digital Age by Berry (not that I have skimmed many).
Software engineering research is a field of dots
Software engineering research is a field of dots; people are fully focused on publishing papers about their chosen tiny little subject.
Where are the books joining the dots into even a vague outline?
Several software researchers have told me that writing books is not a worthwhile investment of their time, i.e., the number of citations they are likely to attract makes writing papers the only cost-effective medium (books containing an edited collection of papers continue to be published).
Butterfly collecting has become the method of study for many researchers. The butterflies in question often being Github repos that are collected together, based on some ‘interestingness’ metric, and then compared and contrasted in a conference paper.
The dots being collected are influenced by the problems that granting agencies consider to be important topics to fund (picking a research problem that will attract funding is a major consideration for any researcher). Fake research is one consequence of incentivizing people to use particular techniques in their research.
Whatever you think the aims of research in software engineering might be, funding the random collecting of dots does not seem like an effective strategy.
Perhaps it is just a matter of waiting for the field to grow up. Evidence-based software engineering research is still a teenager, and the novelty of butterfly collecting has yet to wear off.
My study of particular kinds of dots did not reveal many higher level patterns, although a number of folk theories were shown to be unfounded.
Payback time-frame for research in software engineering
What are the major questions in software engineering that researchers should be trying to answer?
A high level question whose answer is likely to involve life, the universe, and everything is: What is the most cost-effective way to build software systems?
Viewing software engineering research as an attempt to find the answer to a big question mirrors physicists quest for a Grand Unified Theory of how the Universe works.
Physicists have the luxury of studying the Universe at their own convenience, the Universe does not need their input to do a better job.
Software engineering is not like physics. Once a software system has been built, the resources have been invested, and there is no reason to recreate it using a more cost-effective approach (the zero cost of software duplication means that manufacturing cost is the cost of the first version).
Designing and researching new ways of building software systems may be great fun, but the time and money needed to run the realistic experiments needed to evaluate their effectiveness is such that they are unlikely to be run. Searching for more cost-effective software development techniques by paying to run the realistic experiments needed to evaluate them, and waiting for the results to become available, is going to be expensive and time-consuming. A theory is proposed, experiments are run, results are analysed; rinse and repeat until a good-enough cost-effective technique is found. One iteration will take many years, and this iterative process is likely to take many decades.
Very many software systems are being built and maintained, and each of these is an experiment. Data from these ‘experiments’ provides a cost-effective approach to improving existing software engineering practices by studying the existing practices to figure out how they work (or don’t work).
Given the volume of ongoing software development, most of the payback from any research investment is likely to occur in the near future, not decades from now; the evidence shows that source code has a short and lonely existence. Investing for a payback that might occur 30-years from now makes no sense; researchers I talk to often use this time-frame when I ask them about the benefits of their research, i.e., just before they are about to retire. Investing in software engineering research only makes economic sense when it is focused on questions that are expected to start providing payback in, say, 3-5 years.
Who is going to base their research on existing industry practices?
Researching existing practices often involves dealing with people issues, and many researchers in computing departments are not that interested in the people side of software engineering, or rather they are more interested in the computer side.
Algorithm oriented is how I would describe researchers who claim to be studying software engineering. I am frequently told about the potential for huge benefits from the discovery of more efficient algorithms. For many applications, algorithms are now commodities, i.e., they are good enough. Those with a career commitment to studying algorithms have a blinkered view of the likely benefits of their work (most of those I have seen are doing studying incremental improvements, and are very unlikely to make a major break through).
The number of researchers studying what professional developers do, with an aim to improving it, is very small (I am excluding the growing number of fake researchers doing surveys). While I hope there will be a significant growth in numbers, I’m not holding my breadth (at least in the short term; as for the long term, Planck’s experience with quantum mechanics was: “Science advances one funeral at a time”).
Evidence-based software engineering: book released
My book, Evidence-based software engineering, is now available; the pdf can be downloaded here, here and here, plus all the code+data. Report any issues here. I’m investigating the possibility of a printed version. Mobile friendly pdf (layout shaky in places).
The original goals of the book, from 10-years ago, have been met, i.e., discuss what is currently known about software engineering based on an analysis of all the publicly available software engineering data, and having the pdf+data+code freely available for download. The definition of “all the public data” started out as being “all”, but as larger and higher quality data was discovered the corresponding were ignored.
The intended audience has always been software developers and their managers. Some experience of building software systems is assumed.
How much data is there? The data directory contains 1,142 csv files and 985 R files, the book cites 895 papers that have data available of which 556 are cited in figure captions; there are 628 figures. I am currently quoting the figure of 600+ for the ‘amount of data’.

Things that might be learned from the analysis has been discussed in previous posts on the chapters: Human cognition, Cognitive capitalism, Ecosystems, Projects and Reliability.
The analysis of the available data is like a join-the-dots puzzle, except that the 600+ dots are not numbered, some of them are actually specs of dust, and many dots are likely to be missing. The future of software engineering research is joining the dots to build an understanding of the processes involved in building and maintaining software systems; work is also needed to replicate some of the dots to confirm that they are not specs of dust, and to discover missing dots.
Some missing dots are very important. For instance, there is almost no data on software use, but there can be lots of data on fault experiences. Without software usage data it is not possible to estimate whether the software is very reliable (i.e., few faults experienced per amount of use), or very unreliable (i.e., many faults experienced per amount of use).
The book treats the creation of software systems as an economically motivated cognitive activity occurring within one or more ecosystems. Algorithms are now commodities and are not discussed. The labour of the cognitariate is the means of production of software systems, and this is the focus of the discussion.
Existing books treat the creation of software as a craft activity, with developers applying the skills and know-how acquired through personal practical experience. The craft approach has survived because building software systems has been a sellers market, customers have paid what it takes because the potential benefits have been so much greater than the costs.
Is software development shifting from being a sellers market to a buyers market? In a competitive market for development work and staff, paying people to learn from mistakes that have already been made by many others is an unaffordable luxury; an engineering approach, derived from evidence, is a lot more cost-effective than craft development.
As always, if you know of any interesting software engineering data, please let me know.
First use of: software, software engineering and source code
While reading some software related books/reports/articles written during the 1950s, I suddenly realized that the word ‘software’ was not being used. This set me off looking for the earliest use of various computer terms.
My search process consisted of using pfgrep on my collection of pdfs of documents from the 1950s and 60s, and looking in the index of the few old computer books I still have.
Software: The Oxford English Dictionary (OED) cites an article by John Tukey published in the American Mathematical Monthly during 1958 as the first published use of software: “The ‘software’ comprising … interpretive routines, compilers, and other aspects of automotive programming are at least as important to the modern electronic calculator as its ‘hardware’.”
I have a copy of the second edition of “An Introduction to Automatic Computers” by Ned Chapin, published in 1963, which does a great job of defining the various kinds of software. Earlier editions were published in 1955 and 1957. Did these earlier edition also contain various definitions of software? I cannot find any reasonably prices copies on the second-hand book market. Do any readers have a copy?
Update: I now have a copy of the 1957 edition of Chapin’s book. It discusses programming, but there is no mention of software.
Software engineering: The OED cites a 1966 “letter to the ACM membership” by Anthony A. Oettinger, then ACM President: “We must recognize ourselves … as members of an engineering profession, be it hardware engineering or software engineering.”
The June 1965 issue of COMPUTERS and AUTOMATION, in its Roster of organizations in the computer field, has the list of services offered by Abacus Information Management Co.: “systems software engineering”, and by Halbrecht Associates, Inc.: “software engineering”. This pushes the first use of software engineering back by a year.
Source code: The OED cites a 1965 issue of Communications ACM: “The PUFFT source language listing provides a cross-reference between the source code and the object code.”
The December 1959 Proceedings of the EASTERN JOINT COMPUTER CONFERENCE contains the article: “SIMCOM – The Simulator Compiler” by Thomas G. Sanborn. On page 140 we have: “The compiler uses this convention to aid in distinguishing between SIMCOM statements and SCAT instructions which may be included in the source code.”
Update: The October 1956 issue of Computers and Automation contains an extensive glossary. It does not have any entries for software or source code.
Running pdfgrep over the archive of documents on bitsavers would probably throw up all manners of early users of software related terms.
The paper: What’s in a name? Origins, transpositions and transformations of the triptych Algorithm -Code -Program is a detailed survey of the use of three software terms.
A 1931 article using the term Super Computing machine to refer to a Punched card machine that could do arithmetic on numeric values contained on the card.
Recent Comments