Archive
Hardware/Software cost ratio folklore
What percentage of data processing budgets is spent on software, compared to hardware?
The information in the plot below quickly became, and remains, the accepted wisdom, after it was published in May 1973 (page 49).
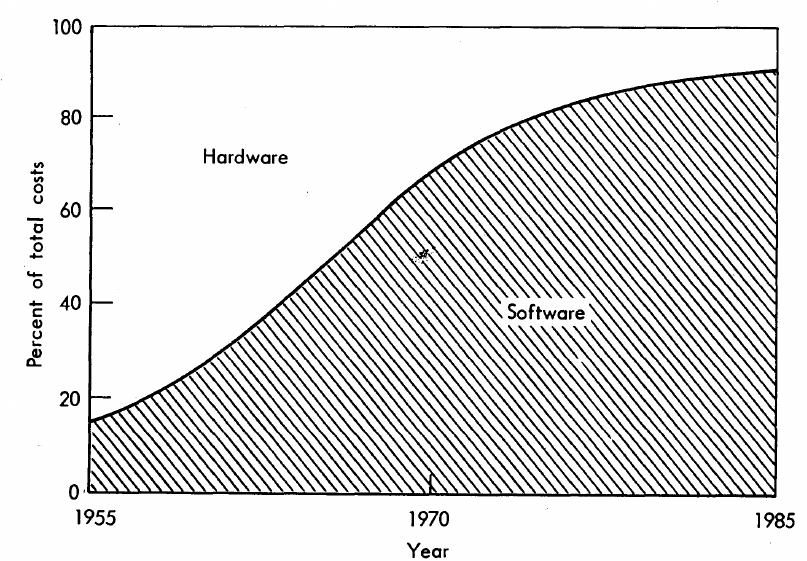
Is this another tale from software folklore? What does the evidence have to say?
What data did Barry Boehm use as the basis for this 1973 article?
Volume IV of the report Information processing/data automation implications of Air-Force command and control requirements in the 1980s (CCIP-85)(U), Technology trends: Software, contains this exact same plot, and Boehm is a co-author of volume XI of this CCIP-85 report (May 1972).
Neither the article or report explicitly calls out specific instances of hardware/software costs. However, Boehm’s RAND report Software and Its Impact A Quantitative Assessment (Dec 1972) gives three examples: the US Air Force estimated they will spend three times as much on software compared to hardware (in early 1970s), a military C&C system ($50-100 million hardware, $722 million software), and recent NASA expenditure ($100 million hardware, $200 million software; page 41).
The 10% hardware/90% software division by 1985 is a prediction made by Boehm (probably with others involved in the CCIP-85 work).
What is the source for the 1955 percentage breakdown? The 1968 article Software for Terminal-oriented systems (page 30) by Werner L. Frank may provide the answer (it also makes a prediction about future hardware/software cost ratios). The plot below shows both the Frank and Boehm data based on values extracted using WebPlotDigitizer (code+data):
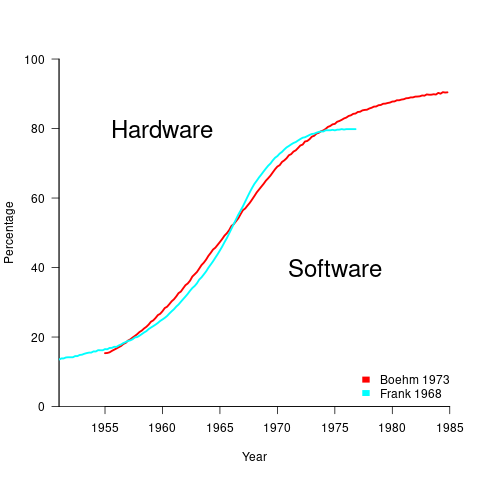
What about the shape of Boehm’s curve? A logistic equation is a possible choice, given just the start/end points, and fitting a regression model finds that  is an almost perfect fit (code+data).
is an almost perfect fit (code+data).
How well does the 1972 prediction agree with 1985 reality?
At the start of the 1980s, two people wrote articles addressing this question: The myth of the hardware/software cost ratio by Harvey Cragon in 1982, and The history of Myth No.1 (page 252) by Werner L. Frank in 1983.
Cragon’s article cites several major ecosystems where recent hardware/software percentage ratios are comparable to Boehm’s ratios from the early 1970s, i.e., no change. Cragon suggests that Boehm’s data applies to a particular kind of project, where a non-recurring cost was invested to develop a new software system either for a single deployment or with more hardware to be purchased at a later date.
When the cost of software is spread over multiple installations, the percentage cost of software can dramatically shrink. It’s the one-of-a-kind developments where software can consume most of the budget.
Boehm’s published a response to Cragon’s article, which answered some misinterpretations of the points raised by Cragdon, and finished by claiming that the two of them agreed on the major points.
The development of software systems was still very new in the 1960s, and ambitious projects were started without knowing much about the realities of software development. It’s no surprise that software costs were so great a percentage of the total budget. Most of Boehm’s articles/reports are taken up with proposed cost reduction ideas, with the hardware/software ratio used to illustrate how ‘unbalanced’ the costs have become, an example of the still widely held belief that hardware costs should consume most of a budget.
Frank’s article references Cragon’s article, and then goes on to spend most of its words citing other articles that are quoting Boehm’s prediction as if it were reality; the second page is devoted 15 plots taken from these articles. Frank feels that he and Boehm share the responsibility for creating what he calls “Myth No. 1” (in a 1978 article, he lists The Ten Great Software Myths).
What happened at the start of 1980, when it was obvious that the software/hardware ratio predicted was not going to happen by 1985? Yes, obviously, move the date of the apocalypse forward; in this case to 1990.
Cragon’s article plots software/hardware budget data from an uncited Air Force report from 1980(?). I managed to find a 1984 report listing more data. Fitting a regression model finds that both hardware and software growth is deemed to be quadratic, with software predicted to consume 84% of DoD budget by 1990 (code+data).
Did software consume 84% of the DoD computer/hardware budget in 1990? Pointers to any subsequent predictions welcome.
Studying the lifetime of Open source
A software system can be said to be dead when the information needed to run it ceases to be available.
Provided the necessary information is available, plus time/money, no software ever has to remain dead, hardware emulators can be created, support libraries can be created, and other necessary files cobbled together.
In the case of software as a service, the vendor may simply stop supplying the service; after which, in my experience, critical components of the internal service ecosystem soon disperse and are forgotten about.
Users like the software they use to be actively maintained (i.e., there are one or more developers currently working on the code). This preference is culturally driven, in that we are living through a period in which most in-use software systems are actively maintained.
Active maintenance is perceived as a signal that the software has some amount of popularity (i.e., used by other people), and is up-to-date (whatever that means, but might include supporting the latest features, or problem reports are being processed; neither of which need be true). Commercial users like actively maintained software because it enables the option of paying for any modifications they need to be made.
Software can be a zombie, i.e., neither dead or alive. Zombie software will continue to work for as long as the behavior of its external dependencies (e.g., libraries) remains sufficiently the same.
Active maintenance requires time/money. If active maintenance is required, then invest the time/money.
Open source software has become widely used. Is Open source software frequently maintained, or do projects inhabit some form of zombie state?
Researchers have investigated various aspects of the life cycle of open source projects, including: maintenance activity, pull acceptance/merging or abandoned, and turnover of core developers; also, projects in niche ecosystems have been investigated.
The commits/pull requests/issues, of circa 1K project repos with lots of stars, is data that can be automatically extracted and analysed in bulk. What is missing from the analysis is the context around the creation, development and apparent abandonment of these projects.
Application areas and development tools (e.g., editor, database, gui framework, communications, scientific, engineering) tend to have a few widely used programs, which continue to be actively worked on. Some people enjoy creating programs/apps, and will start development in an area where there are existing widely used programs, purely for the enjoyment or to scratch an itch; rarely with the intent of long term maintenance, even when their project attracts many other developers.
I suspect that much of the existing research is simply measuring the background fizz of look-alike programs coming and going.
A more realistic model of the lifecycle of Open source projects requires human information; the intent of the core developers, e.g., whether the project is intended to be long-term, primarily supported by commercial interests, abandoned for a successor project, or whether events got in the way of the great things planned.
A new career in software development: advice for non-youngsters
Lately I have been encountering non-young people looking to switch careers, into software development. My suggestions have centered around the ageism culture and how they can take advantage of fashions in software ecosystems to improve their job prospects.
I start by telling them the good news: the demand for software developers outstrips supply, followed by the bad news that software development culture is ageist.
One consequence of the preponderance of the young is that people are heavily influenced by fads and fashions, which come and go over less than a decade.
The perception of technology progresses through the stages of fashionable, established and legacy (management-speak for unfashionable).
Non-youngsters can leverage the influence of fashion’s impact on job applicants by focusing on what is unfashionable, the more unfashionable the less likely that youngsters will apply, e.g., maintaining Cobol and Fortran code (both seriously unfashionable).
The benefits of applying to work with unfashionable technology include more than a smaller job applicant pool:
- new technology (fashion is about the new) often experiences a period of rapid change, and keeping up with change requires time and effort. Does somebody with a family, or outside interests, really want to spend time keeping up with constant change at work? I suspect not,
- systems depending on unfashionable technology have been around long enough to prove their worth, the sunk cost has been paid, and they will continue to be used until something a lot more cost-effective turns up, i.e., there is more job security compared to systems based on fashionable technology that has yet to prove their worth.
There is lots of unfashionable software technology out there. Software can be considered unfashionable simply because of the language in which it is written; some of the more well known of such languages include: Fortran, Cobol, Pascal, and Basic (in a multitude of forms), with less well known languages including, MUMPS, and almost any mainframe related language.
Unless you want to be competing for a job with hordes of keen/cheaper youngsters, don’t touch Rust, Go, or anything being touted as the latest language.
Databases also have a fashion status. The unfashionable include: dBase, Clarion, and a whole host of 4GL systems.
Be careful with any database that is NoSQL related, it may be fashionable or an established product being marketed using the latest buzzwords.
Testing and QA have always been very unsexy areas to work in. These areas provide the opportunity for the mature applicants to shine by highlighting their stability and reliability; what company would want to entrust some young kid with deciding whether the software is ready to be released to paying customers?
More suggestions for non-young people looking to get into software development welcome.
Two failed software development projects in the High Court
When submitting a bid, to be awarded the contract to develop a software system, companies have to provide information on costs and delivery dates. If the costs are significantly underestimated, and/or the delivery dates woefully optimistic, one or more of the companies involved may resort to legal action.
Searching the British and Irish Legal Information Institute‘s Technology and Construction Court Decisions throws up two interesting cases (when searching on “source code”; I have not been able to figure out the patterns in the results that were not returned by their search engine {when I expected some cases to be returned}).
The estimation and implementation activities described in the judgements for these two cases could apply to many software projects, both successful and unsuccessful. Claiming that the system will be ready by the go-live date specified by the customer is an essential component of winning a bid, the huge uncertainties in the likely effort required comes as standard in the software industry environment, and discovering lots of unforeseen work after signing the contract (because the minimum was spent on the bid estimate) is not software specific.
The first case is huge (BSkyB/Sky won the case and EDS had to pay £200+ million): (1) BSkyB Limited (2) Sky Subscribers Services Limited: Claimants – and (1) HP Enterprise Services UK Limited (formerly Electronic Data Systems Limited) (2) Electronic Data systems LLC (Formerly Electronic Data Systems Corporation: Defendants. The amount bid was a lot less than £200 million (paragraph 729 “The total EDS “Sell Price” was £54,195,013 which represented an overall margin of 27% over the EDS Price of £39.4 million.” see paragraph 90 for a breakdown).
What can be learned from the judgement for this case (the letter of Intent was subsequently signed on 9 August 2000, and the High Court decision was handed down on 26 January 2010)?
- If you have not been involved in putting together a bid for a large project, paragraphs 58-92 provides a good description of the kinds of activities involved. Paragraphs 697-755 discuss costing details, and paragraphs 773-804 manpower and timing details,
- if you have never seen a software development contract, paragraphs 93-105 illustrate some of the ways in which delivery/payments milestones are broken down and connected. Paragraph 803 will sound familiar to developers who have worked on large projects: “… I conclude that much of Joe Galloway’s evidence in relation to planning at the bid stage was false and was created to cover up the inadequacies of this aspect of the bidding process in which he took the central role.” The difference here is that the money involved was large enough to make it worthwhile investing in a court case, and Sky obviously believed that they could only be blamed for minor implementation problems,
- don’t have the manager in charge of the project give perjured evidence (paragraph 195 “… Joe Galloway’s credibility was completely destroyed by his perjured evidence over a prolonged period.”). Bringing the law of deceit and negligent misrepresentation into a case can substantially increase/decrease the size of the final bill,
- successfully completing an implementation plan requires people with the necessary skills to do the work, and good people are a scarce resource. Projects fail if they cannot attract and keep the right people; see paragraphs 1262-1267.
A consequence of the judge’s finding of misrepresentation by EDS is a requirement to consider the financial consequences. One item of particular interest is the need to calculate the likely effort and time needed by alternative suppliers to implement the CRM System.
The only way to estimate, with any degree of confidence, the likely cost of implementing the required CRM system is to use a conventional estimation process, i.e., a group of people with the relevant domain knowledge work together for some months to figure out an implementation plan, and then cost it. This approach costs a lot of money, and ties up scarce expertise for long periods of time; is there a cheaper method?
Management at the claimant/defence companies will have appreciated that the original cost estimate is likely to be as good as any, apart from being tainted by the perjury of the lead manager. So they all signed up to using Tasseography, e.g., they get their respective experts to estimate the amount of code that needs to be produce to implement the system, calculate how long it would take to write this code and multiply by the hourly rate for a developer. I would loved to have been a fly on the wall when the respective IT experts, all experienced in provided expert testimony, were briefed. Surely the experts all knew that the ballpark figure was that of the original EDS estimate, and that their job was to come up with a lower/high figure?
What other interpretation could there be for such a bone headed approach to cost estimation?
The EDS expert based his calculation on the debunked COCOMO model (ok, my debunking occurred over six years later, but others have done it much earlier).
The Sky expert based his calculation on the use of function points, i.e., estimation function points rather than lines of code, and then multiply by average cost per function point.
The legal teams point out the flaws in the opposing team’s approach, and the judge does a good job of understanding the issues and reaching a compromise.
There may be interesting points tucked away in the many paragraphs covering various legal issues. I barely skimmed these.
The second case is not as large (the judgement contains a third the number of paragraphs, and the judgement handed down on 19 February 2021 required IBM to pay £13+ million): SCIS GENERAL INSURANCE LIMITED: Claimant – and – IBM UNITED KINGDOM LIMITED: Defendant.
Again there is lots to learn about how projects are planned, estimated and payments/deliveries structured. There are staffing issues; paragraph 104 highlights how the client’s subject matter experts are stuck in their ways, e.g., configuring the new system for how things used to work and not attending workshops to learn about the new way of doing things.
Every IT case needs claimant/defendant experts and their collection of magic spells. The IBM expert calculated that the software contained technical debt to the tune of 4,000 man hours of work (paragraph 154).
If you find any other legal software development cases with the text of the judgement publicly available, please let me know (two other interesting cases with decisions on the British and Irish Legal Information Institute).
What can be learned from studying long gone development practices?
Current ideas about the best way of building a software system are heavily influenced by the ideas that captured the attention of previous generations of developers. Can anything of practical use be learned from studying long gone techniques for building software systems?
During the writing of my software engineering book, I was spending a lot of time researching the development techniques used during the twentieth century, and one day I suddenly realised that this was a waste of time. While early software developers tend to be eulogized today, the reality is that they were mostly people who had little idea what they were doing, who through personal competence of being in the right place at the right time managed to produce something good enough. On the whole, twentieth century software development techniques are only of historical interest. Yes, some timeless development principles were discovered, and these can be integrated into today’s techniques (which may also turn out to be of their-time).
My experience of software development in the late 1970s and 1980s is that there was rarely any connection between what management told the world about the development process, and how those reporting to the manager actually did the development.
If you are a manager in a world where software development is still very new, and you are given the job of managing the development of a software system, how do you go about it? A common approach is to apply the techniques that are already being used to run the manager’s organization. On a regular basis, managers came up with the idea of applying techniques from the science of industrial production (which is still happening today).
In the 1970s and 1980s there were usually very visible job hierarchies, and sharply defined roles. Organizations tended to use their existing job hierarchies and roles to create the structure for their software development employees. For years after I started work as a graduate, managers and secretaries were surprised to see me typing; secretaries typed, men did not type, and women developers fumed when they were treated like secretaries (because they had been seen typing).
The manual workers performed data entry, operated the computer (e.g., mounted tapes, and looked after the printer). The junior staff often started with the job title programmer, or perhaps junior programmer and there might be senior programmers; on paper these people wrote the code to implement the functionality specified by a systems analyst (or just analyst, or business analyst, perhaps with added junior or senior). Analysts did not to write code and programmers only coded what the specification they were given, at least according to management.
Pay level was set by the position in the job hierarchy, with those higher up earning more than those below them, and job titles/roles were also mapped to positions in the hierarchy. This created, in theory, a direct correspondence between pay and job title/role. In practice, organizations wanted to keep their productive employees, and so were flexible about the correspondence between pay and title, e.g., during their annual review some people were more interested in the status provided by a job title, while others wanted more money and did not care about job titles. Add into this mix the fact that pay/title levels rarely matched up between organizations, it soon became obvious to all that software job titles were a charade.
How should the people at the sharp end go about building a software system?
Structured programming was the widely cited technique in the 1970s. Consultants promoted their own variants, with Jackson structured programming being widely known in the UK, with regular courses and consultants offering to train staff. Today, structured programming appears remarkably simplistic, great for writing tiny programs (it has an academic pedigree), but not for anything larger than a thousand lines. Part of its appeal may have been this simplicity, many programs were small (because computer memory was measured in kilobytes) and management often thought that problems were simple (a recurring problem). There were a few adaptations that tried to address larger scale issues, e.g., Warnier/Orr structured programming.
The military were major employers of software developers in the 1960s and 1970s. In the US Work Breakdown Structure was mandated by the DOD for project development (for all projects, not just software), and in the UK we had MASCOT. These mandated development methodologies were created by committees, and have not been experimentally tested to be better/worse than any other approach.
I think the best management technique for successfully developing a software system in the 1970s and 1980s (and perhaps in the following decades), is based on being lucky enough to have a few very capable people, and then providing them with what is needed to get the job done while maintaining the fiction to upper management that the agreed bureaucratic plan is being followed.
There is one technique for producing a software system that rarely gets mentioned: keep paying for development until something good enough is delivered. Given the life-or-death need an organization might have for some software systems, paying what it takes may well have been a prevalent methodology during the early days of major software development.
To answer the question posed at the start of this post. What might be learned from a study of early software development techniques is the need for management to have lots of luck and to be flexible; funding is easier to obtain when managing a life-or-death project.
Research software code is likely to remain a tangled mess
Research software (i.e., software written to support research in engineering or the sciences) is usually a tangled mess of spaghetti code that only the author knows how to use. Very occasionally I encounter well organized research software that can be used without having an email conversation with the author (who has invariably spent years iterating through many versions).
Spaghetti code is not unique to academia, there is plenty to be found in industry.
Structural differences between academia and industry make it likely that research software will always be a tangled mess, only usable by the person who wrote it. These structural differences include:
- writing software is a low status academic activity; it is a low status activity in some companies, but those involved don’t commonly have other higher status tasks available to work on. Why would a researcher want to invest in becoming proficient in a low status activity? Why would the principal investigator spend lots of their grant money hiring a proficient developer to work on a low status activity?
I think the lack of status is rooted in researchers’ lack of appreciation of the effort and skill needed to become a proficient developer of software. Software differs from that other essential tool, mathematics, in that most researchers have spent many years studying mathematics and understand that effort/skill is needed to be able to use it.
Academic performance is often measured using citations, and there is a growing move towards citing software,
- many of those writing software know very little about how to do it, and don’t have daily contact with people who do. Recent graduates are the pool from which many new researchers are drawn. People in industry are intimately familiar with the software development skills of recent graduates, i.e., the majority are essentially beginners; most developers in industry were once recent graduates, and the stream of new employees reminds them of the skill level of such people. Academics see a constant stream of people new to software development, this group forms the norm they have to work within, and many don’t appreciate the skill gulf that exists between a recent graduate and an experienced software developer,
- paid a lot less. The handful of very competent software developers I know working in engineering/scientific research are doing it for their love of the engineering/scientific field in which they are active. Take this love away, and they will find that not only does industry pay better, but it also provides lots of interesting projects for them to work on (academics often have the idea that all work in industry is dull).
I have met people who have taken jobs writing research software to learn about software development, to make themselves more employable outside academia.
Does it matter that the source code of research software is a tangled mess?
The author of a published paper is supposed to provide enough information to enable their work to be reproduced. It is very unlikely that I would be able to reproduce the results in a chemistry or genetics paper, because I don’t know enough about the subject, i.e., I am not skilled in the art. Given a tangled mess of source code, I think I could reproduce the results in the associated paper (assuming the author was shipping the code associated with the paper; I have encountered cases where this was not true). If the code failed to build correctly, I could figure out (eventually) what needed to be fixed. I think people have an unrealistic expectation that research code should just build out of the box. It takes a lot of work by a skilled person to create to build portable software that just builds.
Is it really cost-effective to insist on even a medium-degree of buildability for research software?
I suspect that the lifetime of source code used in research is just as short and lonely as it is in other domains. One study of 214 packages associated with papers published between 2001-2015 found that 73% had not been updated since publication.
I would argue that a more useful investment would be in testing that the software behaves as expected. Many researchers I have spoken to have not appreciated the importance of testing. A common misconception is that because the mathematics is correct, the software must be correct (completely ignoring the possibility of silly coding mistakes, which everybody makes). Commercial software has the benefit of user feedback, for detecting some incorrect failures. Research software may only ever have one user.
Research software engineer is the fancy title now being applied to people who write the software used in research. Originally this struck me as an example of what companies do when they cannot pay people more, they give them a fancy title. Recently the Society of Research Software Engineering was setup. This society could certainly help with training, but I don’t see it making much difference with regard status and salary.
Update
This post generated a lot of discussion on the research software mailing list, and Peter Schmidt invited me to do a podcast with him. Here it is.
Books similar to my empirical software engineering book
I am sometimes asked which other books are similar to the Empirical Software Engineering book I am working on.
In spirit, the most similar book is “Software Project Dynamics” by Abdel-Hamid and Madnick, based on Abdel-Hamid’s PhD thesis. The thesis/book sets out to create an integrated model of software development projects, using system dynamics (the model can be ‘run’ to produce outputs from inputs, assuming the necessary software is available).
Building a model of the software development process requires figuring out the behavior of all the important factors and Abdel-Hamid does a thorough job of enumerating the important factors and tracking down the available empirical work (in the 1980s). The system dynamics model, written in Dynamo appears in an appendix (I have not been able to locate any current implementation).
In the 1980s I would have agreed with Abdel-Hamid that it was possible to build a reasonably accurate model of software development projects. Thirty years later, I have tracked down a lot more empirical work and know a more about how software projects work. All this has taught me is that I don’t know enough to be able to build a model of software development projects; but I still think it is possible, one day.
There have been other attempts to build models of major aspects of software development projects (all using system dynamics), including Madachy’s PhD and later book “Software Process Dynamics”, and Buettner’s PhD (no book, yet???).
There are other books that include some combination of the words empirical, software and engineering in their title. On the whole these are collections of edited papers, whose chapters are written by researchers promoting their latest work; there is even one that aims to teach students how to do empirical work.
Dag Sjøberg has done some interesting empirical work and is currently working on an empirical book, this should be worth a look.
“R in Action” by Kabacoff is the closest to the statistical material, but at a more general level. “The R Book” by Crawley is the R book I would recommended, but it is not at all like the material I have written.
Recent Comments