Archive
Finding links between gcc source code and the C Standard
How close is the agreement between the behavior of a compiler and its corresponding language specification?
In the previous century, some Standards’ bodies offered a compiler validation service. However, even when the number of commercial compilers numbered in the hundreds, this service was not commercially viable. These days there are only a handful of industrial strength compilers.
The availability of huge quantities of Open source, for some languages, has created a new language specification. Being able to turn much of this source into executable programs has become an effective measure of compiler correctness.
Those working on C/C++ compilers (Open source or otherwise), often claim that they implement the requirements contained in the corresponding ISO Standard. Some are active in the ISO Standards’ process, and I believe that they do strive to implement the requirements contained in the language standard.
How confident can we be that all the requirements contained in a language standard are correctly implemented by a compiler?
There is a cottage industry of testing compiler runtime behavior, often using fuzzers, and sometimes a compiler is one of the programs chosen to test new fuzzing techniques. This research checks optimization and code generation.
This runtime testing is all well and good, but a large percentage of the text in a language specification contains requirements on the syntax and semantics. The quality of syntax/semantic testing depends on how well the people writing the tests understand the language semantics. It takes a year or two of detailed study to achieve an effective compiler-level of understanding of these ‘front-end’ requirements.
The approach taken by the Model Implementation C Checker to show syntax/semantic correctness was to cross-referenced every if-statement in the front-end to one or more lines in the C90 Standard (the 1990 edition of the ISO C Standard), or an internal house-keeping reference (the source contained 3K references to 1.3K requirements in the C Standard). This compiler/checker was formally validated by BSI. As far as I know, this is the only compiler source cross-referenced at the level of individual lines/if-statements; there are compilers whose source contains cross-references to the sections of a language specification.
The main benefit of this cross-referencing process is insuring that every requirement in the C Standard is addressed by the compiler (correctly or otherwise). Other benefits include providing packets of wording for targeted tests and the ability to generate a runtime trace of all language features involved in compiling a given translation unit.
Replicating this cross-referencing for the gcc or llvm C compiler front-ends would be a huge amount of work for somebody who already has a detailed knowledge of the C Standard, along with some knowledge of compilers. The number of pages in the Standard relating to the C language has grown from 101 pages in C90 to 190 pages in C23. At an average of 14 cross-referenceable lines per page, the expected number of cross-references is now likely to be around 2,700.
LLMs are great at extracting information from text, can generate impressive quality C conformance tests, and are much, much cheaper than C language experts. How good are LLMs at working out which section(s)/paragraph(s) in the C Standard are implemented by the source code of a function contained in, say, gcc?
The LLM prompt I used to test out the idea was:
List the section and paragraph number of the latest ISO C standard containing the requirements implemented in the following source code from a C compiler |
Links to all responses from: ChatGPT5 Thinking, Grok3 Fast and Gok3 Expert.
It is very likely that text from the various versions of the C Standard were in the training data of the larger LLMs, so I did not include this material in the prompt. ChatGPT5 Thinking listed the 2024 draft N3220 as its source document.
The source code was copied from the C front-end code of gcc (i.e., the directory: gcc-15.1.0/gcc/c), which contains 67KLOC, with 6.8K if-statements.
Starting small, the following code looked like an easy test (I removed the comment containing text from the C Standard and obscured the big clue in the original function name: null_pointer_constant_p):
bool check_is_n_ptr (const_tree expr) { /* This should really operate on c_expr structures, but they aren't yet available everywhere required. */ tree type = TREE_TYPE (expr); if (expr == nullptr_node) return true; return (TREE_CODE (expr) == INTEGER_CST && !TREE_OVERFLOW (expr) && integer_zerop (expr) && (INTEGRAL_TYPE_P (type) || (TREE_CODE (type) == POINTER_TYPE && VOID_TYPE_P (TREE_TYPE (type)) && TYPE_QUALS (TREE_TYPE (type)) == TYPE_UNQUALIFIED))); } |
Wow, ChatGPT5 Thinking’s response even included a note on why the code checks for an unqualified type:
Here are the exact C23 (ISO/IEC 9899:2024) clauses that your function is implementing:
6.3.2.3 Pointers, ¶3 — Definition of a null pointer constant: “An integer constant expression
with the value 0, such an expression cast to type void *, or the predefined constant nullptr
is called a null pointer constant.”
6.6 Constant expressions, ¶8 — What qualifies as an integer constant expression
(your INTEGER_CST / INTEGRAL_TYPE_P checks).
6.6 Constant expressions, ¶4 — Range requirement for constant expressions
(motivates the !TREE_OVERFLOW (expr) check).
6.4.4.6 Predefined constants, ¶¶1–3 — nullptr is a predefined constant (token classification;
ties to your expr == nullptr_node fast-path).
6.3.2.4 nullptr_t, ¶¶1–2 — Conversions of nullptr_t (confirms nullptr converts to any pointer
type yielding the null pointer value).
Notes
• The “cast to type void *” wording in 6.3.2.3 means unqualified void *,
which is why your code insists the pointed-to void is unqualified.
Grok3 Fast’s response was even more expansive (and almost instantaneous), listing examples of section/paragraphs containing uses of null pointers, and pointing out that the wording was unchanged until C23 (when the nullptr keyword was introduced, along with its type nullptr_t). It also pointed out gcc specific features of the implementation (the prompt did not identify the compiler).
That’s enough of the easy questions. The following code (comments removed, function name unchanged) is essentially asking a question: What is the promoted type of the argument?
tree c_type_promotes_to (tree type) { tree ret = NULL_TREE; if (TYPE_MAIN_VARIANT (type) == float_type_node) ret = double_type_node; else if (c_promoting_integer_type_p (type)) { if (TYPE_UNSIGNED (type) && (TYPE_PRECISION (type) == TYPE_PRECISION (integer_type_node))) ret = unsigned_type_node; else ret = integer_type_node; } if (ret != NULL_TREE) return (TYPE_ATOMIC (type) ? c_build_qualified_type (ret, TYPE_QUAL_ATOMIC) : ret); return type; } |
ChatGPT5 listed six references. Three were good, and the other three were closely related, but I would not have cited them. The seven Grok3 references came from several documents using slightly different section numbers. Updating the prompt to explicitly name N3220 as the document to use did not change Grok3’s cited references (for this question).
All the code in the previous questions was there because of text in the C Standard. How do ChatGPT5/Grok3 handle the presence of code that does not have standard associated text?
The following function contains code to handle named address spaces (defined in a 2005 Technical Report: TR 18037 Extensions to support embedded processors).
static tree qualify_type (tree type, tree like) { addr_space_t as_type = TYPE_ADDR_SPACE (type); addr_space_t as_like = TYPE_ADDR_SPACE (like); addr_space_t as_common; /* If the two named address spaces are different, determine the common superset address space. If there isn't one, raise an error. */ if (!addr_space_superset (as_type, as_like, &as_common)) { as_common = as_type; error ("%qT and %qT are in disjoint named address spaces", type, like); } return c_build_qualified_type (type, TYPE_QUALS_NO_ADDR_SPACE (type) | TYPE_QUALS_NO_ADDR_SPACE_NO_ATOMIC (like) | ENCODE_QUAL_ADDR_SPACE (as_common)); } |
ChatGPT5 listed six good references and pointed out the association between the named address space code and TR 18037. Grok3 Fast hallucinated extensive quoted text/references from TR 18037 related to named address spaces. Grok3 Expert pointed out that the Standard does not contain any requirements related to named address spaces and listed two reasonable references.
Finding appropriate cross-references is the time-consuming first step. Next, I want the LLM to add them as comments next to the corresponding code.
I picked a 312 line function, and updated the prompt to add comments to the attached file:
Find the section and paragraph numbers in the ISO C standard, specified in document N3220, containing the requirements implemented in the source code contained in the attached file, and add these section and paragraph numbers at the corresponding places in the code as comment |
ChatGPT5 Thinking thought for 5 min 46 secs (output), and Grok3 Expert thought for 3 mins 4 secs (output).
Both ChatGPT5 and Grok3 modified the existing code, either by joining adjacent lines, changing variable names, or deleting lines. ChatGPT made far fewer changes, while the Grok3 output was 65 lines shorter than the original (including the added comments).
Both LLMs added comments to blocks of if-statements (my fault for not explicitly specifying that every if should be cross-referenced), with ChatGPT5 adding the most cross-references.
One way to stop the LLMs making unasked for changes to the source is to have them focus on the added comments, i.e., ask for a diff that can be fed into patch. The updated prompt is:
Find the section and paragraph numbers in the ISO C standard, specified in document N3220, containing the requirements implemented by each if statement in the source code contained in the attached file. Create a diff file that patch can use to add these section and paragraph numbers as comments at the corresponding lines in the original code |
ChatGPT5 Thinking thought for around 4 min (it reported inconsistent values (output), and Grok3 Expert thought for 5 min 1 sec (output).
The ChatGPT5 patch contained many more cross-references than its earlier output, with comments on more if-statements. The Grok3 patch was a third the size of the ChatGPT5 patch.
How well did the LLMs perform?
ChatGPT5 did very well, and its patch output would be a good starting point for a detailed human expert edit. Perhaps an improved prompt, or some form of fine-tuning would useful improve performance.
Grok3 Fast does not appear to be usable, but Grok3 Expert could be used as an independent check against ChatGPT5 output.
Working at the section/paragraph level it is not always possible to give the necessary detailed cross-reference because some paragraphs contain multiple requirements. It might be easier to split the C Standard text into smaller chunks, rather than trying to get LLMs to give line offsets within a paragraph.
Functions reduce the need to remember lots of variables
What, if any, are the benefits of adding bureaucracy to a program by organizing a file’s source code into multiple function/method definitions (rather than a single function)?
Having a single copy of a sequence of statements that need to be executed at multiple points in a program reduces implementation effort, and any updates only need to be made once (reducing coding mistakes by removing the need to correctly make duplicate changes). A function/method is the container for this sequence of statements.
Why break code up into separate functions when each is only called once and only likely to ever be called once?
The benefits claimed from splitting code into functions include: making it easier to understand, test, debug, maintain, reuse, and scale development (i.e., multiple developers working on the same program). Our LLM overlords also make these claims, and hallucinate references to published evidence (after three iterations of pointing out the hallucinated references, I gave up asking for evidence; my experience with asking people is that they usually remember once reading something but cannot remember the source).
Regular readers will not be surprised to learn that there is little or no evidence for any of the claimed benefits. I’m not saying that the benefits don’t exist (I think there are some), simply that there have not been any reliable studies attempting to measure the benefits (pointers to such studies welcome).
Having decided to cluster source code into functions, for whatever reason, are there any organizational rules of thumb worth following?
Rules of thumb commonly involve function length (it’s easy to measure) and desirable semantic characteristics of distinct functions (it’s very hard to measure semantic characteristics).
Claims for there being an optimal function length (i.e., lines of code that minimises coding mistakes) turned out to be driven by a mathematical artifact of the axis used when plotting (miniscule) datasets.
Semantic rules of thumb such as: group by purpose, do one thing, and Single-responsibility principle are open to multiple interpretations that often boil down to personal preferences and experience.
One benefit of using functions that is rarely studied is the restricted visibility of local variables defined within them, i.e., only visible within the function body.
When trying to figure out what code does, readers have to keep track of the information contained in all the variables accessed. Having to track more variables not only increases demands on reader memory, it also increases the opportunities for making mistakes.
A study of C source found that within a function, the number of local variables is proportional to the square root of the number of statements (code+data). Assuming the proportionality constant is one, a function containing 100 statements might be expected to define 10 local variables. Splitting this function up into, say, four functions containing 25 statements, each is expected to define 5 local variables. The number of local variables that need to be remembered at the same time, when reading a function definition, has halved, although the total number of local variables that need to be remembered when processing those 100 statements has doubled. Some number of global variables and function parameters need to be added to create an overall total for the number of variables.
The plot below shows the number of locals defined in 36,617 C functions containing a given number of statements, the red line is a fitted regression model having the form:  (code+data):
(code+data):
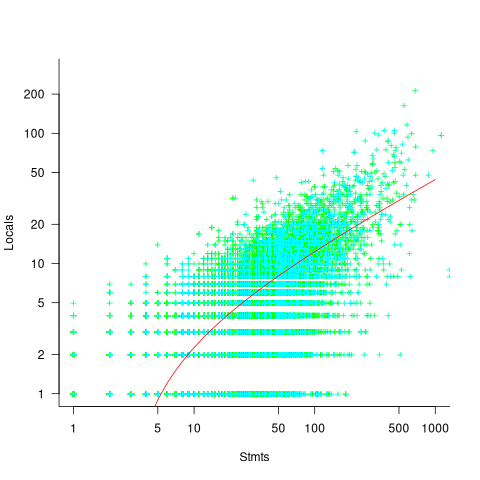
My experience with working with recently self-taught developers, especially very intelligent ones, is that they tend to write monolithic programs, i.e., everything in one function in one file. This minimal bureaucracy approach minimises the friction of a stream of thought development process for adding new code, and changing existing code as the program evolves. Most of these programs are small (i.e., at most a few hundred lines). Assuming that these people continue to code, one of two events teaches them the benefits of function bureaucracy:
- changes to older programs becomes error-prone. This happens because the developer has forgotten details they once knew, e.g., they forget which variables are in use at particular points in the code,
- the size of a program eventually exceeds their ability to remember all of it (very intelligent people can usually remember much larger programs than the rest of us). Coding mistakes occur because they forget which variables are in use at particular points in the code.
Compiler validation used to be a big thing
Compiler validation used to be a big thing; a NIST quarterly validated products list could run to nearly 150 pages, and approaching 1,000 products (not all were compilers).
Why did compiler validation stop being a thing?
Running a compiler validation service (NIST was also involved with POSIX, graphics, and computer security protocols validation) costs money. If there are enough people willing to pay (NIST charged for the validation service), the service pays for itself.
The 1990s was a period of consolidation, lots of computer manufacturers went out of business and Micro Focus grew to dominate the Cobol compiler business. The number of companies willing to pay for validation fell below the number needed to maintain the service; the service was terminated in 1998.
The source code of the Cobol, Fortran and SQL + others tests that vendors had to pass (to appear for 12 months in the validated products list) is still available; the C validation suite costs money. But passing these tests, then paying NIST’s fee for somebody to turn up and watch the compiler pass the tests, no longer gets your product’s name in lights (or on the validated products list).
At the time, those involved lamented the demise of compiler validation. However, compiler validation was only needed because many vendors failed to implement parts of the language standard, or implemented them differently. In many ways, reducing the number of vendors is a more effective means of ensuring consistent compiler behavior. Compiler monoculture may spell doom for those in the compiler business (and language standards), but is desirable from the developers’ perspective.
How do we know whether today’s compilers implement the requirements contained in the corresponding ISO language standard? You could argue that this is a pointless question, i.e., gcc and llvm are the language standard; but let’s pretend this is not the case.
Fuzzing is good for testing code generation. Checking language semantics still requires expert human effort, and lots of it. People have to extract the requirements contained in the language specification, and write code that checks whether the required behavior is implemented. As far as I know, there are only commercial groups doing this, i.e., nothing in the open source world; pointers welcome.
2015: A new C semantics research group
A very new PhD student research group working on C semantics has just appeared on the horizon. You can tell they are very new to C semantics by the sloppy wording in their survey of C users (what is a ‘normal’ compiler and how does it differ from the ‘current mainstream’ compiler referred to in some questions? I’m surprised the outcome appeared clear to the authors, given the jumble of multiple choice options given to respondents).
Over the years a number of these groups have appeared, existed until their members received a PhD and then disappeared. In some cases one of the group members does something that shows a lot of potential (e.g., the C-semantics work), but the nature of academic research means that either the freshly minted PhD moves to industry or else moves on to another research area. Unfortunately most groups are overwhelmed by the task and pivot into meaningless subsets of concentrating on mathematical organisms. Very, very occasionally interesting work gets supported once the PhD is out of the way, Coccinelle being the stand-out example for C.
It takes implementing a full compiler (as part of a PhD or otherwise) to learn C semantics well enough to do meaningful research on it. The world seems to be stuck in a loop of using research to educate know-nothings until they know-something and then sending them off on another track. This is why C language researchers keep repeating themselves every 10 years or so.
Will anybody in this new group do any interesting work? Alan Mycroft set the bar very high for Cambridge by submitting a 100 page comment document on the draft C89 standard that listed almost as much ambiguous wording as everybody else put together found (but he was implementing a compiler in his spare time and not doing it for a PhD, so perhaps he does not count).
One suggestion I would make to this new group is that if they really are interested in actual usage they should measure actual usage, developer beliefs about compiler behavior is rarely very accurate and always heavily tainted by experiences from when they first started out.
Semantic vs phonetic similarity for word pairs: a weekend investigation
The Computational Semantics hackathon was one of the events I attended last weekend. Most if the suggested problems either looked like they could not reasonably be done in a weekend (it ran 10:00-17:00 on both days, I know academics hacks) or were uninspiring coding problems. Chatting to some of the academics present threw up an interesting idea that involved comparing word pair semantic and phonetic similarity (I have written about my interest in sounds-like and source code identifiers).
Team Semantic-sounds consisted of Pavel and yours truly (code and data).
The linguists I chatted to seemed to think that there would be a lot of word pairs that sounded alike and were semantically similar; I did not succeed it getting any of them to put a percentage to “a lot”. From the human communication point of view, words that both sound alike and have a similar meaning are likely to be confused with each other; should such pairs come into existence they are likely to quickly disappear, at least if the words are in common usage. Sound symbolism related issues got mentioned several times, but we did not have any data to check out the academic enthusiasm.
One of the datasets supplied by the organizers was word semantic similarity data extracted from the Google news corpus. The similarity measure is based on similarity of occurrence, e.g., the two sentences “I like licking ice-cream” and “I like eating ice-cream” suggest a degree of semantic similarity between the words licking and eating; given enough sentences containing licking and eating there are clever ways of calculating a value that can be viewed as a measure of word similarity.
The data contained 72,000+ words, giving a possible half a billion pairs (most having zero similarity). To prune this down a bit we took, for each word, the 150 other words that were most similar to it, giving around 10 million word pairs. Each word was converted to a phoneme sequence and a similarity distance calculated for each pair of phoneme sequences (which we called phonetic distance and claimed it was a measure of how similar the words sounded to each other).
The list of word pairs with high semantic/phonetic similarity was very noisy, with lots of pairs containing the same base word in plural, past tense or some other form, e.g., billion and billions. A Porter stemmer was used to remove all pairs where the words shared the same stem, reducing the list to 2.5 million pairs. Most of the noise now came from differences in British/American spelling. We removed all word pairs that contained a word that was not in the list of words that occurred in the common subset of the British and American dictionaries used by aspell; this reduced the list to half a million pairs.
The output contained some interesting pairs, including: faultless/flawless, astonishingly/astoundingly, abysmal/dismal and elusive/illusive. These look like rarely used words to me (not enough time to add in word frequency counts).
Some pairs had surprisingly low similarity, e.g., artifact/artefact (the British/American spelling equality idea has a far from perfect implementation). Is this lower than expected semantic similarity because there is a noticeable British/American usage difference? An idea for a future hack.
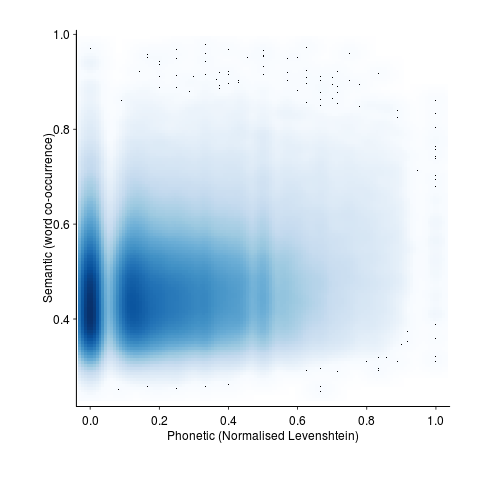
A smoothed scatter plot of semantic vs phonetic similarity (for the most filtered pair list) shows lots of semantically similar pairs that don’t sound alike, but a few that do (I suspect that most of these are noise that better stemming and spell checking will filter out). The following uses Levenshtein distance for phoneme similarity, normalised by the maximum distance for a given phoneme sequence with all phoneme differences having equal weight:
and using Jaro-Winkler distance (an alternative distance metric that is faster to calculate):
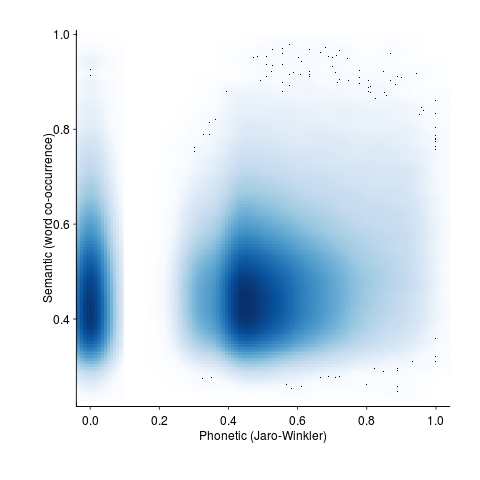
The empty band at low phonetic similarity is an artifact of the data being quantized (i.e., words contain a small number of components).
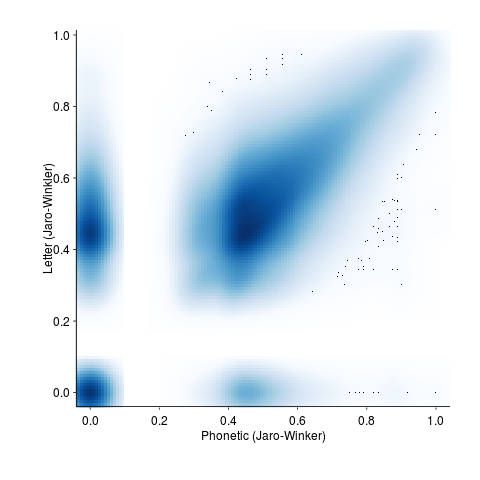
Is it worth going to the trouble of comparing phoneme sequences? Would comparing letter sequences be just as good? The following plot shows word pair letter distance vs phonetic similarity distance (there is a noticeable amount of off-diagonal data, i.e., for some pairs letter/phoneme differences are large):
Its always good to have some numbers to go with graphical data. The following is the number of pairs having a given phonetic similarity (remember the starting point was the top 150 most semantically similar pairs). The spikes are cause by the discrete nature of word components.
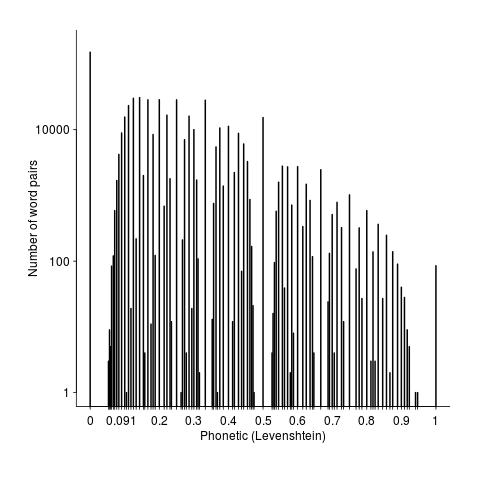
Squinting at the above it is possible to see an exponential decline as phonetic word similarity increases. It would be interesting to have enough data to display a meaningful 3D plot, perhaps a plane can be fitted (with a log scale on the z-axis).
Rather than using the Google news corpus data as the basis of word pair semantic similarity we could have used the synonym sets from Wordnet. This rather obvious idea did not occur to me until later Saturday and there was no time to investigate. How did the small number of people who created the Wordnet data come up with lists of synonyms? If they simply thought very hard they might have been subject to the availability bias, preferentially producing lists of synonyms that contained many words that sounded alike because those that did not sound alike were less likely to be recalled. Another interesting idea to check out at another hack.
It was an interesting hack and as often happens more new questions were raised than were answered.
Testing compiler semantics with minimal manual input
The 2011 revision of the C++ Standard added lots of new constructs to the language and in the past few months both the GCC and LLVM teams have been claiming that the next release of their C++ compilers will fully support the 2011 Standard. How true are these claims? One way of answering this question is to run both compilers over an extensive test suite. There are commercial C++ compiler test suites available, but I don’t have access to them and if I did the license agreement would probably not allow me to talk in detail about the results. Writing compiler tests cases requires a very detailed knowledge of the language; I have done it often enough in previous lives to know that more than a year or so of my time would be needed just to get my head around the semantics of the new C++ features, before I could produce anything half decent.
Is there a way of automating the generation of test cases for language semantics? Automated statement/expression generation is very effective at finding problems with optimizers and code generators. Can this technique be applied to check the semantic requirements of a language?
Having concocted various elaborate schemes over the years I recently realised that life would be a lot simpler if I was willing to accept a very high percentage of erroneous test programs (the better manually written test suites usually contain around as many test cases that intended to fail to compile as tests that pass, i.e., intended to compile correctly; the not so good ones have few failing tests).
If two or more compilers are available the behavior of each of them on a given source file can be compared: differential testing. If both compile a file or fail to compile it, they may both be right or wrong; either way this shared behavior is not interesting, but is likely to be the common case. The interesting case is if one compiles a file and the other fails to compile it; this could be a fault in one of them, or one of those cases where the Standard permits compilers to do their own thing.
I hereby jump to the conclusion that behavior differences is a good proxy for compiler conformance to the language Standard (actually developers are often more interested in all compilers they are likely to use having the same external behavior than conforming to a Standard).
Lets implement this (source code here)!
First we need to generate lots of test cases. The process I used is based on program templates, such as the following (lines starting with ! are places where various constructs can be inserted):
int v; ! declare_id 2 int main(void) { ! declare_id 2 ! ref_id 2 } |
the identifier after the ! is the name of a file containing lines to be inserted at the given location (the number after the identifier is the maximum number of lines that can be inserted at that point; default 1 if no number given). The following is example file contents for the above template:
declare_id
int i; enum {i, j}; enum i {x, y}; struct i {int f;}; typedef int i; |
ref_id
enum i ev_i; struct i sv_i; typedef i tv_i; v=i; |
It is then simply a matter of permuting through all of the possible combinations of lines that can be inserted in the program template, creating a stand alone file for each possibility (18,000 of them in the above example); I used the Python Natural Language Toolkit to do the heavy lifting.
A shell script compiles each source file and compares the compiler exit codes. For the above example there were 16,366 failures, 1,634 passes and no differences (this example contains well established C constructs and any difference would have been surprising).
Next, a feature new in C++11, lambda functions!
Here is the template used:
! declare_xy 2 int main(void) { ! declare_xy 2 auto foo_bar = ! define_lambda ; return 0; } |
I cut and pasted some examples from the Standard to create the following optional lines:
define_lambda
[](float a, float b) { return a + b; } [=](float a, float b) { return a + b; } [=,x](float a, float b) { return a + b; } [y](float a, float b) { return a + b; } [=]()->int { return operator()(this->x + y); } [&, i]{ } [=] { decltype(x) y1; decltype((x)) y2 = y1; decltype(y) r1 = y1; decltype((y)) r2 = y2; } |
which generated 6,300 source files of which 5,865 failed, 396 passed and 39 were treated differently by the compilers (g++ version 4.7.2, clang version 3.3).
How should the percentages be calculated? If we take the human written numbers for well written test suites containing (roughly) equal numbers of pass/fail tests, then we have around 800 tests of which (say) 40 gave different behavior, giving us a 5% fault rate. Do we share that 5% equally between both compilers or assign 3% for both being wrong and 1% for each being uniquely wrong?
Submitting a bug report to both compiler teams pointing out that their behavior is different from the other’s is a sure fire way to make myself unpopular. Any suggestions for how to resolve this issue, that does not involve me having to study the tiresomely long and convoluted C++ Standard, welcome.
Verified compilers and soap powder advertising
There’s a new paper out claiming to be about a formally-verified C compiler, it even states a Theorem about its abilities! If this paper appeared as part of a Soap powder advert the Advertising Standards Authority would probably require clarification of the claims. What clarifications might appear in the small print tucked away at the bottom of the ad?
- C source code is not verified directly, it is first translated to the formal notations used by the verification system; the software that performs this translation is assumed to be correct.
- The CompCert system may successfully translate programs containing undefined behavior. Any proof statements made about such programs may not be valid.
- The support tools are assumed to be correct; primarily the Coq proof assistant, which is written in OCaml.
- The CompCert system makes decisions about implementation dependent behaviors and any proofs only apply in the context of these decisions.
- The CompCert system makes decisions about unspecified behaviors and any proofs only apply in the context of these decisions.
Some notes on the small print:
The C source translator used by CompCert rarely gets mentioned in any of the published papers; what was done to check its accuracy (I have previously discussed some options)? Presumably the developers who wrote it tried very hard to make sure they did a good job, just like the authors of f2c, a Fortran to C translator, did. Connecting f2c as a front-end of the CompCert system gives us a verified Fortran compiler! I think the f2c translator is much more likely to be correct than the CompCert C source translator, it has been used by a lot more people, processed a lot more source and maintained over a longer period.
When they encounter undefined behavior in source code production C compilers sometimes generate code that has very unexpected behavior. Using the CompCert system will not avoid unexpected behavior in these situations; CompCert simply washes its hands for this kind of code and says all bets are off.
Proving the support tools correct would simply move the assumption of correctness to a different set of tools. I am not aware of any major effort to test whether the Coq system behaves as intended, but have not read all the papers describing it (the list of reported faults is does not appear to be publicly available); bugs have been found in the OCaml implementation.
Like all compilers that generate code, CompCert has to make implementation dependent decisions and select one of the possible unspecified behaviors. The C-Semantics tool generates all unspecified behaviors, rather than just one.
Most developers don’t really know any computer language
What does it mean to know a language? I can count to ten in half a dozen human languages, say please and thank you, tell people I’m English and a few other phrases that will probably help me get by; I don’t think anybody would claim that I knew any of these languages.
It is my experience that most developers’ knowledge of the programming languages they use is essentially template based; they know how to write a basic instances of the various language constructs such as loops, if-statements, assignments, etc and how to define identifiers to have a small handful of properties, and they know a bit about how to glue these together.
There are many developers who can skilfully weave together useful programs from the hodgepodge of coding knowledge they happen to know (proving that little programming knowledge is needed to write useful programs).
The purpose of this post is not to complain about developers’ lack of knowledge of the programming languages they use; I appreciate that time spent learning about the application domain often gives a better return on investment compared to learning more about a language. The purpose is to suggest that the programming language community (e.g., teachers and tool producers) acknowledge how languages are primarily used and go with the flow rather than maintaining the fiction that developers know anything much about the languages they use and that they should acquire this knowledge to expert level; students should be taught the commonly encountered templates, not the general language rules, developers should be encouraged to use just the common templates (this will also have the side effect of reducing the effort needed to follow other peoples code since the patterns of usage will be familiar to many).
I suspect that many readers will disagree with the statement in this post’s title, and I need to provide more evidence before proposing (in another post) how we might adapt to the reality to be found in development teams.
The only evidence I can offer is my own experience; not a very satisfactory situation; a possible measurement approach discussed below. So what is this experience based evidence (I only claim to ‘know’ the handful of language I have written compiler front ends for, with other languages my usage follows the template form just like everybody else)?
- discussions with developers: individuals and development groups invariably have their own terminology for programming language constructs (my use of terminology appearing in the language definition usually draws blank stares and I have to make a stab at guessing what the local terms mean and using them if I want to be listened to); asking about identifier scoping or type compatibility rules (assuming that either of the terms ‘scope’ or ‘type compatibility’ is understood) usually results in a vague description of specific instances (invariably the commonly encountered situations),
- books that claim to teach a language often provide superficial coverage of the language semantics and concentrate on usage examples (because that is what is useful to their readers). Those books claiming to give insight into the depths of a language often contains many mistakes; perhaps the most well known example is Herbert Schildt’s “The Annotated ANSI C Standard”, Clive Feather’s review of the 1995 edition and Peter Seebach’s review of later versions,
- the word ‘Advanced’ has to appear in programming courses for professional developers with 3–10 years of experience because potential customers think they have reached an advanced level. In practice, such courses teach the basics and get away with it because most of the attendees don’t know them. My own experiences of teaching such courses is that outside of the walking people through the slides, the real teaching is about trying to undo some of the bad habits and misconceptions individuals have picked up over the years.
Recent graduate think they are an expert in the language used on their course because they probably have not met anybody who knows a lot more; some professional developers think they are language experts because the have lots of years of experience, in practice they tend to have spent those years essentially using what they originally learned and are now very adept with that small subset.
How might we measure the program language knowledge of the general developer population?
Software development question/answer sites such as Stack Overflow contain a wealth of information. I think I could write a function that did a reasonably good job of deducing the programming language, if any, being used in the question. Given the language definition (in some cases this might not exist, e.g., Perl and PHP) and the answers to the question of how do I figure out the language expertise of the person who wrote the answer?
First, we need to filter out those questions that are application related, with code being incidental. Latent Semantic Indexing could be used to locate the strongest connections between parts of the language specification and the non-source code answer text. If strong connections are found, the question would be assumed to be programming language related.
Developers only need surface knowledge to sprinkle any answer with phrases related to the language referred to; more in depth analysis is needed.
One idea is to process any code in the question/answer with a compiler capable of generating references to those parts of the language definition used during its semantic processing (ideally ‘part’ would be the sentence level, but I would settle for paragraph level or perhaps couple of paragraph level). A non-trivial overlap between the ‘parts’ references returned by the two searches would be a good indicator of programming language question. The big problem with this idea is complete lack of compilers supporting this language reference functionality (somebody please prove me wrong).
I am currently stumped for a practical technique for a non-superficial way of measuring developer language expertise. The 2013 Mining Software Repositories challenge is based on a dump of the questions/answers from Stack Overflow, I’m looking forward to seeing what useful information researchers extract from it.
Would you buy second hand software from a formal methods researcher?
I have been reading a paper on formally proving software correct (Bridging the Gap: Automatic Verified Abstraction of C by Greenaway, Andronick and Klein) and as often the case with papers on this topic the authors have failed to reach the level of honest presentation required by manufacturers of soap power in their adverts.
The Greenaway et al paper describes a process that uses a series of translation steps to convert a C program into what is claimed to be a high level specification in Isabelle/HOL (a language+support tool for doing formal proofs).
The paper was published by an Australian research group; I could not find an Australian advertising standards code dealing with soap power but did find one covering food and beverages. Here is what the Australian Association of National Advertisers has to say in their Food & Beverages Advertising & Marketing Communications Code:
“2.1 Advertising or Marketing Communications for Food or Beverage Products shall be truthful and honest, shall not be or be designed to be misleading or deceptive or otherwise contravene Prevailing Community Standards, and shall be communicated in a manner appropriate to the level of understanding of the target audience of the Advertising or Marketing Communication with an accurate presentation of all information…”
So what claims and statements do Greenaway et al make?
2.1 “Before code can be reasoned about, it must first be translated into the theorem prover.” A succinct introduction to one of the two main tasks, the other being to prove the correctness of these translations.
“In this work, we consider programs in C99 translated into Isabelle/HOL using Norrish’s C parser … As the parser must be trusted, it attempts to be simple, giving the most literal translation of C wherever possible.”
“As the parser must be trusted”? Why must it be trusted? Oh, because there is no proof that it is correct, in fact there is not a lot of supporting evidence that the language handled by Norrish’s translator is an faithful subset of C (ok, for his PhD Norrish wrote a formal semantics of a subset of C; but this is really just a compiler written in mathematics and there are umpteen PhDs who have written compilers for a subset of C; doing it using a mathematical notation does not make it any more fault free).
The rest of the paper describes how the output of Norrish’s translator is generally massaged to make it easier for people to read (e.g., remove redundant statements and rename variables).
Then we get to the conclusion which starts by claiming: “We have presented a tool that automatically abstracts low-level C semantics into higher-level specifications with automatic proofs of correctness for each of the transformation steps.”
Oh no you didn’t. There is no proof for the main transformation step of C to Isabelle/HOL. The only proofs described in the paper are for the post processing fiddling about that was done after the only major transformation step.
And what exactly is this “high-level specification”? The output of the Norrish translator was postprocessed to remove the clutter that invariably gets generated in any high-level language to high-level language translator. Is the result of this postprocessing a specification? Surely it is just a less cluttered representation of the original C?
Actually this paper does contain a major advance in formally proving software correct, tucked away at the start it says “As the parser must be trusted…”. There it is in black and white, if you have some software that must be trusted don’t bother with formal proofs just simply follow the advice given here.
But wait a minute you say, I am ignoring the get out of jail wording “… shall be communicated in a manner appropriate to the level of understanding of the target audience …”. What is the appropriate level of understanding of the target audience, in fact who is the target audience? Is the target audience other formal methods researchers who are familiar with the level of intellectual honesty within their field and take claims made by professional colleagues with a pinch of salt? Are non-formal methods researchers not the target audience and so have no redress to being misled by the any claims made by papers in this field?
Estimating the quality of a compiler implemented in mathematics
How can you tell if a language implementation done using mathematical methods lives up to the claims being made about it, without doing lots of work? Answers to the following questions should give you a good idea of the quality of the implementation, from a language specification perspective, at least for C.
- How long did it take you to write it? I have yet to see any full implementation of a major language done in less than a man year; just understanding and handling the semantics, plus writing the test cases will take this long. I would expect an answer of at least several man years
- Which professional validation suites have you tested the implementation against? Many man years of work have gone into the Perennial and PlumHall C validation suites and correctly processing either of them is a non-trivial task. The gcc test suite is too light-weight to count. The C Model Implementation passed both
- How many faults have you found in the C Standard that have been accepted by WG14 (DRs for C90 and C99)? Everybody I know who has created a full implementation of a C front end based on the text of the C Standard has found faults in the existing wording. Creating a high quality formal definition requires great attention to detail and it is to be expected that some ambiguities/inconsistencies will be found in the Standard. C Model Implementation project discoveries include these and these.
- How many ‘rules’ does the implementation contain? For the C Model Implementation (originally written in Pascal and then translated to C) every if-statement it contained was cross referenced to either a requirement in the C90 standard or to an internal documentation reference; there were 1,327 references to the Environment and Language clauses (200 of which were in the preprocessor and 187 involved syntax). My C99 book lists 2,043 sentences in the equivalent clauses, consistent with a 70% increase in page count over C90. The page count for C1X is around 10% greater than C99. So for a formal definition of C99 or C1X we are looking for at around 2,000 language specific ‘rules’ plus others associated with internal housekeeping functions.
- What percentage of the implementation is executed by test cases? How do you know code/mathematics works if it has not been tested? The front end of the C Model Implementation contains 6,900 basic blocks of which 87 are not executed by any test case (98.7% coverage); most of the unexecuted basic blocks require unusual error conditions to occur, e.g., disc full, and we eventually gave up trying to figure out whether a small number of them were dead code or just needed the right form of input (these days genetic programming could be used to help out and also to improve the quality of coverage to something like say MC/DC, but developing on a PC with a 16M hard disc does limit what can be done {the later arrival of a Sun 4 with 32M of RAM was mind blowing}).
Other suggested questions or numbers applicable to other languages most welcome. Some forms of language definition do not include a written specification, which makes any measurement of implementation conformance problematic.
Recent Comments