Archive
Converting lines in an svg image to csv
During a search for data on programming language usage I discovered Stack Overflow Trends, showing an interesting plot of language tags appearing on Stack Overflow questions (see below). Where was the csv file for these numbers? Somebody had asked this question last year, but there were no answers.

The graphic is in svg format; has anybody written an svg to csv conversion tool? I could only find conversion tools for specialist uses, e.g., geographical data processing. The svg file format is all xml, and using a text editor I could see the numbers I was after. How hard could it be (it had to be easier than a png heatmap)?
Extracting the x/y coordinates of the line segments for each language turned out to be straight forward (after some trial and error). The svg generation process made matching language to line trivial; the language name was included as an xml attribute.
Programmatically extracting the x/y axis information exhausted my patience, and I hard coded the numbers (code+data). The process involves walking an xml structure and R’s list processing, two pet hates of mine (the data is for a book that uses R, so I try to do everything data related in R).
I used R’s xml2 package to read the svg files. Perhaps if my mind had a better fit to xml and R lists, I would have been able to do everything using just the functions in this package. My aim was always to get far enough down to convert the subtree to a data frame.
Extracting data from graphs represented in svg files is so easy (says he). Where is the wonderful conversion tool that my search failed to locate? Pointers welcome.
Extracting the original data from a heatmap image
The paper Analysis of the Linux Kernel Evolution Using Code Clone Coverage analysed 136 versions of Linux (from 1.0 to 2.6.18.3) and calculated the amount of source code that was shared, going forward, between each pair of these versions. When I saw the heatmap at the end of the paper (see below) I knew it had to appear in my book. The paper was published in 2007 and I knew from experience that the probability of seven year old data still being available was small, but looked so interesting I had to try. I emailed the authors (Simone Livieri, Yoshiki Higo, Makoto Matsushita and Katsuro Inoue) and received a reply from Makoto Matsushita saying that he had searched for the data and had been able to find the original images created for the paper, which he kindly sent me.
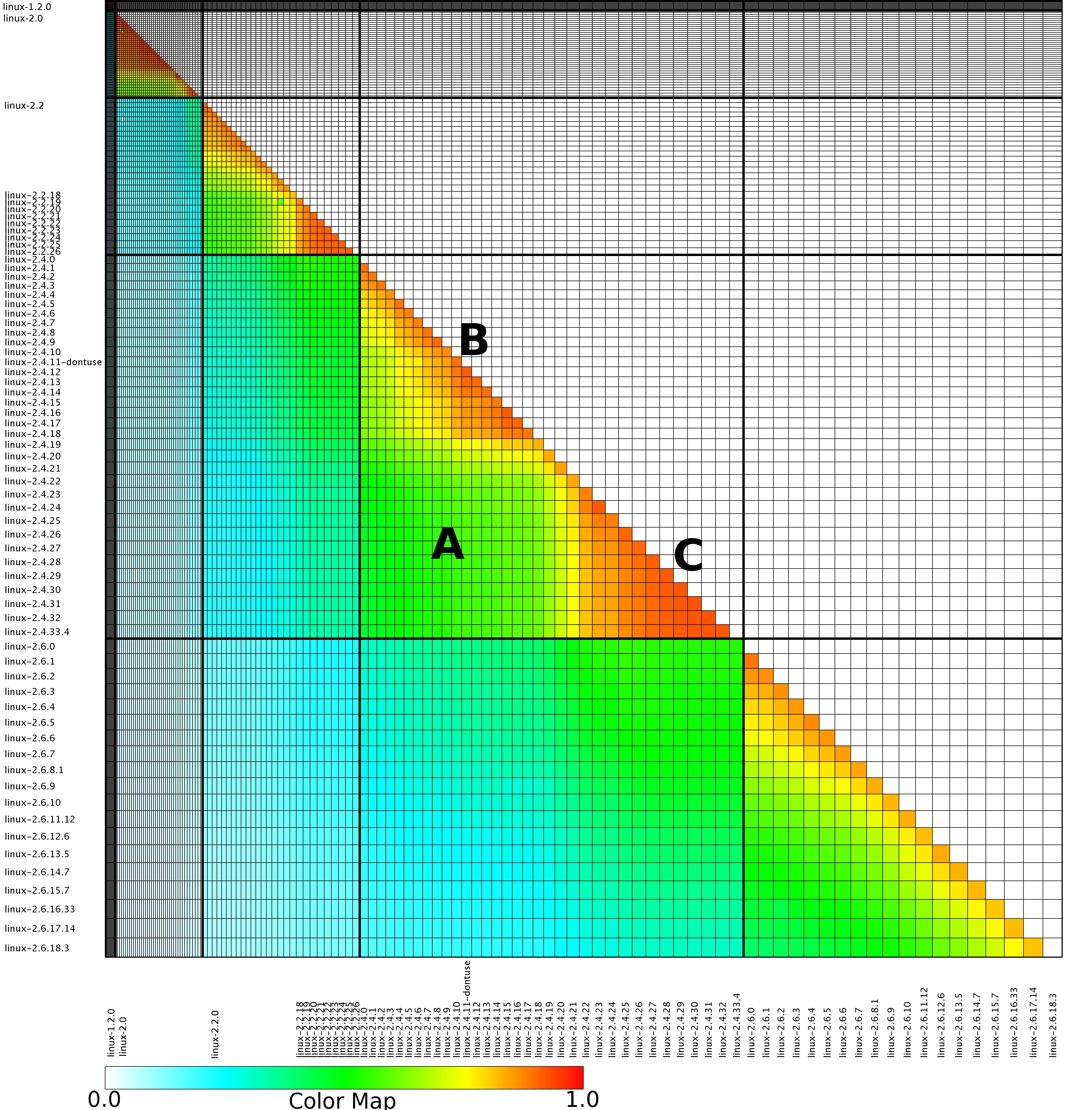
I was confident that I could reverse engineer the original values from the png image and that is what I have just done (I have previously reverse engineered the points in a pdf plot by interpreting the pdf commands to figure out relative page locations).
The idea I had was to find the x/y coordinates of the edge of the staircase running from top left to bottom right. Those black lines appear to complicate things, but the RGB representation of black follows the same pattern as white, i.e., all three components are equal (0 for black and 1 for white). All I had to do was locate the first pixel containing an RGB value whose three components had at least one different value, which proved to be remarkably easy to do using R’s vector operations.
After reducing duplicate sequences to a single item I now had the x/y coordinates of the colored rectangle for each version pair; extracting an RGB value for each pair of Linux releases was one R statement. Now I needed to map RGB values to the zero to one scale denoting the amount of shared Linux source. The color scale under the heatmap contains the information needed and with some trial and error I isolated a vector of RGB pixels from this scale. Passing the offset of each RGB value on this scale to mapvalues (in the plyr package) converted the extracted RGB values.
The extracted array has 130 rows/columns, which means information on 5 versions has been lost (no history is given for the last version). At the moment I am not too bothered, most of the data has been extracted.
Here is the result of calling the R function readPNG (from the png package) to read the original file, mapping the created array of RGB values to amount of Linux source in each version pair and calling the function image to display this array (I have gone for maximum color impact; the code has no for loops):
The original varied the width of the staircase, perhaps by some measure of the amount of source code. I have not done that.
Its suspicious that the letter A is not visible in some form. Its embedded in the original data and I would have expected a couple of hits on that black outline.
The above overview has not bored the reader with my stupidities that occurred along the way.
If you improve the code to handle other heatmap data extraction problems, please share the code.
Ways of obtaining empirical data in software engineering
For as long as I can remember I have been a collector of empirical data. Writing a book that involves analysis of empirical lots of data has added some focus to my previous scatter gun approach. I have been using three methods to obtain data relating to a recently read paper+one other approach:
- Download from researchers website,
- Emailing the author requesting a copy of the data,
- Reverse engineering numbers from the original paper (using tools like WebPlotDigitizer).
- Roll my sleeves up and do the experiment, write the extraction tool or convince a company to make its data available.
A sea change in attitudes to making data available seems to be underway. Until recently it was rare to find a researcher who provided a link for downloading data; in the last 12 months there has been a noticeable increase in the number of researchers making data, associated with a paper, available for download. I hope this increase continues and making data freely available becomes the accepted norm.
I regularly (once or twice a week) email the authors of a paper asking if I can have a copy of their data, typical responses include:
- Yes, here it is,
- Yes, but you cannot share it with anybody else (i.e., everybody has to get it from the original author). I have said “Thanks, but no thanks” in these cases since I make all the data I use freely available for download,
- I no longer have a copy of the data (changed jobs, lost in a computer crash, etc). In one case an established repository at a university lost funding and has gone dark.
- Data is confidential,
- Plan to write more papers based on the data, will release it when done (obtaining good data can be very time consuming and I can appreciate researchers wanting to maximize their return on investment),
- No response.
I have run a few experiments and have been luck enough to obtain data from one company.
When analysing data the most common ‘mistake’ I encounter is researchers failing to get the most out of the data they have. An example of this is two researchers who made some structural changes to the way a Java library worked and then ran a thorough before/after benchmark to investigate the impact; their statistical analysis consisted of reducing the extensive data down to mean+variance and comparing these across before/after (I built a regression model that makes a much stronger case for their claims).
Of course the usual incorrect use of statistical techniques does occur, but I have not spotted anything major. However, one study found: Willingness to Share Research Data Is Related to the Strength of the Evidence and the Quality of Reporting of Statistical Results, based on 49 papers published in two major psychology journals. Since I am concentrating on papers where the data is available I am probably painting an overly rosy picture of not getting things wrong.
As always, if anybody knows of ways of obtaining data that I have not mentioned (e.g., a twitter account to follow) do please let me know.
Using evolution to reduce competition
The Microsoft purchase of Skype got me thinking back to my time as an advisor to the Monitoring Trustee appointed by the European Commission in the EU/Microsoft competition court case. The Commission wanted to introduce competition into the Windows Work Group server market and it hoped that by requiring Microsoft to license all of the necessary communication protocols companies would produce products that were plug-compatible with Microsoft products. The major flaw in this plan turned out to be economics, we estimated it would cost around £100 million to implement the protocols and making a worthwhile profit on this investment looked decidedly problematic.
Microsoft’s approach to publishing protocol specifications went through three stages: 1) doing everything they could not to do it, 2) following the judgment handed down by the court, 3) actively documenting additional protocols and making all the documents publicly available. Yes, as the documentation process progressed Microsoft started to see the benefits of having English prose documentation (previously the documentation was the source code) but I suspect the switch from (2) to (3) was made possible by the economic analysis that implied there would not be any competition in the server market.
Skype have not made their client/server protocols public, will Microsoft do so? I suspect not because there is no benefit for them to do so. Also I’m sure that Microsoft will want to steer clear of antitrust authorities and will not be making Skype an integral part of Windows’ internal functionality.
What progress has been made in reverse engineering the Skype protocols? There is a community of people trying to figure them out but they have not made the progress that enabled Andrew Tridgell to quickly get something useful up and running that could then evolve into a full blown implementation of a Microsoft protocol.
What lesson can Skype product managers learn from the Microsoft experience of having to make their proprietary protocols available to third parties? I don’t think Microsoft intentionally did any the following:
- Don’t write any English prose documentation; ensure that the source code is the only specification of the protocols. This will make it easier for point 3) to occur,
- proprietary protocols are your friend, even designing ‘better’ alternatives to non-proprietary protocols,
- don’t put too much of a brake on evolution, i.e., allow developers to do what they always want to do which is to make quick fixes to the code and tweak it here and there resulting in a tangle that cannot be simplified. This will significantly drive up third-party costs as they will not be able to create a product handling a useful subset (i.e., they will have to implement everything) and the tangle make sit harder form them to sure that what they have done is correct.
What might be the short term costs of following this strategy? Very good developers are used to learning by reading code (lack of documentation is a fact of life for may of them). Experience has shown that allowing developers to make quick fixes and tweak code often results in difficult to maintain code (ok, so a small group of developers have to be paid above the market rate to ensure access to their code memory). If developers really do dig themselves into a very large hole it is always possible to completely redesign the protocols and provide a very major upgrade (Skype can always reinvent its own protocols, an option not available to third parties which have to follow slavishly behind; this option has always been open to Microsoft with its protocols, i.e., the courts did not place any restrictions on protocol changes).
Where did the £100 million figure come from? The problem of estimating development cost was approached from various angles. The one I used was to estimate the number of requirements at 50,000 (there are 38,158 MUSTs in the first public release of the documents) of which 1,651 occur in the SMB specification for which there is a 450KLOC implementation (i.e., samba source in 2006), giving an estimate of (50000/1651)*450K -> 13.6 MLOC in the final implementation. At £10 per line we get a bit more than £100 million.
Minimum information needed for writing a code generator
If a compiler writer is faced with writing a back-end for an undocumented processor, what is the minimum amount of information that needs to be reverse engineered?
It is possible to implement a universal computer using a cpu that has a single instruction, subtract-and-branch-if-lessthan-or-equal-to-zero. This is all very well, but processors based on using a single instruction are a bit thin on the ground and the processor to hand is likely to support a larger number of simpler instructions.
A subtract-and-branch-if-lessthan-or-equal-to-zero instruction could be implemented on a register based machine using the appropriate sequence of load-from-memory, subtract-two-registers, store-register-to-memory and jump-if-subtract-lessthan-or-equal instructions. Information about other instructions, such as add and multiply, would be useful for code optimization. (The Turing machine model of computation is sufficiently far removed from how most programs and computers operate that it is not considered further.)
Are we done? In theory yes, in practice no. A couple pf practical problems have been glossed over; how do source literals (e.g., "Hello World") initially get written to storage, where does the storage used by the program come from and what is the file format of an executable?
Literals that are not created using an instruction (most processors have instructions for loading an integer constant into a register) are written to a part of the executable file that is read into storage by the loader on program startup. All well and good if we know enough about the format of an executable file to be able to correct generate this information and can get the operating system to put in the desired storage location. Otherwise we have to figure out some other solution.
If we know two storage locations containing values that differ by one a sequence of instructions could subtract one value from the other to eventually obtain any desired value. This bootstrap process would speed up as a wider range of know value/location pairs was built up.
How do we go about obtaining a chunk of storage? An executable file usually contains information on the initial amount of storage needed by a program when it is loaded. Calls to the heap manager are another way of obtaining storage. Again we need to know where to write the appropriate information in the executable file.
What minimum amount of storage might be expected to be available? A program executing within a stack/heap based memory model has a default amount of storage allocated for the stack (a minimum of 16k I believe under Mac OS X or iPhone OS). A program could treat the stack as its storage. Ideally what we need is the ability to access storage via an offset from the stack pointer, at worse we would have to adjust the stack pointer to the appropriate offset, pop the value into a register and then reset the stack pointer; storing would involve a push.
Having performed some calculation we probably want to communicate one or more values to the outside world. A call to a library routine, such as printf, needs information on the parameter passing conventions (e.g., which parameters get stored in which registers or have storage allocated for them {a function returning a structure type usually has the necessary storage allocated by the calling function with the address passed as an extra parameter}) and the location of any return value. If ABI information is not available a bit of lateral thinking might be needed to come up with an alternative output method.
I have not said anything about making use of signals and exception handling. These are hard enough to get right when documentation is available. The Turing machine theory folk usually skip over these real-world issues and I will join them for the time being.
Recent Comments