Archive
Deep dive looking for good enough reliability models
A previous post summarised the main highlights of my trawl through the software reliability research papers/reports/data, which failed to find any good enough models for estimating the reliability of a software system. This post summarises a deep dive into the technical aspects of the research papers.
I am now a lot more confident that better than worst case models for calculating software reliability don’t yet exist (perhaps the problem does not have a solution). By reliability, I mean the likelihood that a fault will be experienced during 1-hour of operation (1-hour is the time interval often used in safety critical standards).
All the papers assume that time to next new fault experience can be effectively modelled using timing information on the previously discovered distinct faults. Timing information might be cpu time, or elapsed time during testing or customer use, or even number of tests. Issues of code coverage and the correspondence between tests and customer usage are rarely mentioned.
Building a model requires making assumptions about the world. Given the data used, all the models assume that there is a relationship connecting the time between successive distinct faults, e,g, the Jelinski-Moranda model assumes that the time between fault experiences has an exponential distribution and that the exponent is the same for all faults. While the Jelinski-Moranda model does not match the behavior seen in the available datasets, it is widely discussed (its simplicity makes it a great example, with the analysis being straightforward and the result easy to explain).
Much of the fault timing data comes from the test process, with the rest coming from customer usage (either cpu or elapsed; like today’s cloud usage, mainframe time usage was often charged). What connection does a model fitted to data on the faults discovered during testing have with faults experienced by customers using the software? Managers want to minimise the cost of testing (one claimed use case for these models is estimating the likelihood of discovering a new fault during testing), and maximising the number of faults found probably has a higher priority than mimicking customer usage.
The early software reliability papers (i.e., the 1970s) invariably proposed a new model and then checked how well it fitted a small dataset.
While the top, must-read paper on software fault analysis was published in 1982, it has mostly remained unknown/ignored (it appeared as a NASA report written by non-academics who did not then promote their work). Perhaps if Nagel and Skrivan’s work had become widely known, today we might have a practical software reliability model.
Reliability research in the 1980s was dominated by theoretical analysis of the previously proposed models and their variants, finding connections between them and building more general models. Ramos’s 2009 PhD thesis contains a great overview of popular (academic) reliability models, their interconnections, and using them to calculate a number.
I did discover some good news. Researchers outside of software engineering have been studying a non-software problem whose characteristics have a direct mapping to software reliability. This non-software problem involves sampling from a population containing subpopulations of varying sizes (warning: heavy-duty maths), e.g., oil companies searching for new oil fields of unknown sizes. It looks, perhaps (the maths is very hard going), as-if the statisticians studying this problem have found some viable solutions. If I’m lucky, I will find a package implementing the technical details, or find a gentle introduction. Perhaps this thread will have a happy ending…
An aside: When quickly deciding whether a research paper is worth reading, if the title or abstract contains a word on my ignore list, the paper is ignored. One consequence of this recent detailed analysis is that the term NHPP has been added to my ignore list for software reliability issues (it has applicability for hardware).
Good enough reliability models: still an unknown
Estimating the likelihood that a software system will operate as intended, for some period of time, is one of the big problems within the field of software reliability research. When software does not operate as intended, a fault, or bug, or hallucination is said to have occurred.
Three events need to occur for a user of a software system to experience a fault:
- a developer writes code that does not always behave as intended, i.e., a coding mistake,
- the user of the software feeds it input that causes the coding mistake to produce unintended behavior,
- the unintended behavior percolates through the system to produce a visible fault (sometimes an unintended behavior does not percolate very far, and does not produce any change of visible behavior).
Modelling each kind of event and their interaction is a huge undertaking. Researchers in one of the major subfields of software reliability take a global approach, e.g., they model time to next fault experience, using data on the number of faults experienced per given amount of cpu/elapsed time (often obtained during testing). Modelling the fault data obtained during testing results in a model of the likelihood of the next fault experienced using that particular test process. This is useful for doing a return-on-investment calculation to decide whether to do more testing. If the distribution of inputs used during testing is similar to the distribution of customer inputs, then the model can be of use in estimating the rate of customer fault experiences.
Is it possible to use a model whose design was driven by data from testing one or more software systems to estimate the rate of fault experiences likely when testing other software systems?
The number of coding mistakes will differ between systems (because they have different sizes, and/or different developer abilities), and the testers’ ability will be different, and the extent to which mistaken behavior percolates through code will differ. However, it is possible for there to be a general model for rate of fault experiences that contains various parameters that need to be fitted for each situation.
Since that start of the 1970s, researchers have been searching for this general model (the first software reliability model is thought to be: “Program errors as a birth-and-death process” by G. R. Hudson, Report SP-3011, System Development Corp., 1967 Dec 4; please send me a copy, if you have one).
The image below shows the 18 models discussed in the 1987 book “Software Reliability: Measurement, Prediction, Application” by Musa, Iannino, and Okumoto (later editions have seriously watered down the technical contents, and lack most of the tables/plots). It’s to be expected that during the early years of a new field, many different models will be proposed and discussed.
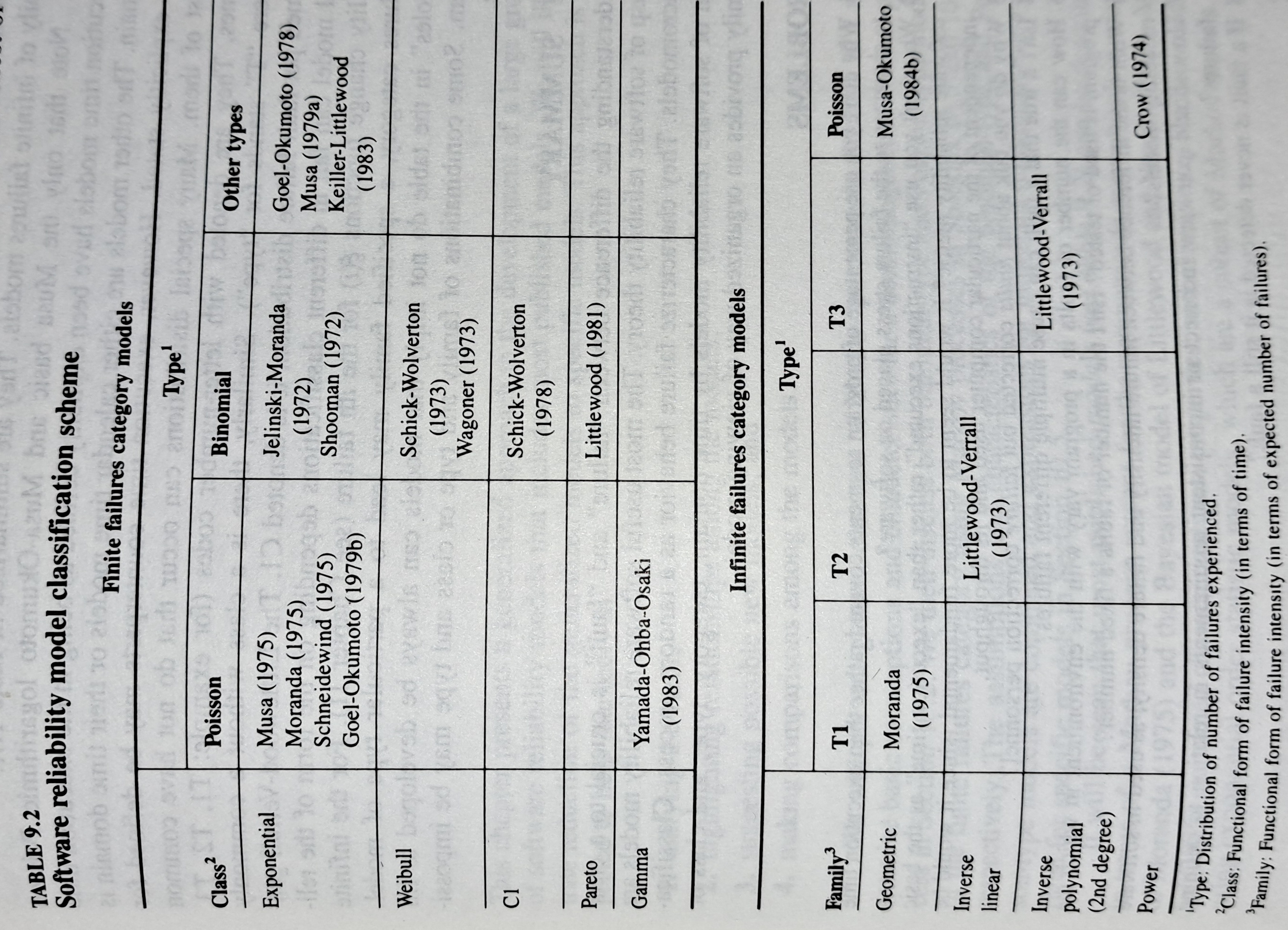
Did researchers discover a good-enough general model for rate of fault experiences?
It’s hard to say. There is not enough reliability data to be confident that any of the umpteen proposed models is consistently better at predicting than any other. I believe that the evidence-based state of the art has not yet progressed beyond the 1982 report Software Reliability: Repetitive Run Experimentation and Modeling by Nagel and Skrivan.
Fitting slightly modified versions of existing models to a small number of tiny datasets has become standard practice in this corner of software engineering research (the same pattern of behavior has occurred in software effort estimation). The image below shows 16 models from a 2021 paper.
Nearly all the reliability data used to create these models is from systems built in the 1960s and 1970s. During these decades, software systems were paid for organizations that appreciated the benefits of collecting data to build models, and funding the necessary research. My experience is that few academics make an effort to talk to people in industry, which means they are unlikely to acquire new datasets. But then researchers are judged by papers published, and the ecosystem they work within is willing to publish papers extolling the virtues of another variant of an existing model.

The various software fault datasets used to create reliability models tends to be scattered in sometimes hard to find papers (yes, it is small enough to be printed in papers). I have finally gotten around to organizing all the public data that I have in one place, a Reliability data repo on GitHub.
If you have a public fault dataset that does not appear in this repo, please send me a copy.
Survival of CVEs in the Linux kernel
Software contained in safety related applications has to have a very low probability of failure.
How is a failure rate for software calculated?
The people who calculate these probabilities, or at least claim that some program has a suitably low probability, don’t publish the details or make their data publicly available.
People have been talking about using Linux in safety critical applications for over a decade (multiple safety levels are available to choose from). Estimating a reliability for the Linux kernel is a huge undertaking. This post is taking a first step via a broad brush analysis of a reliability associated dataset.
Public fault report logs are a very messy data source that needs a lot of cleaning; they don’t just contain problems caused by coding mistakes, around 50% are requests for enhancement (and then there is the issue of multiple reports having the same root cause).
CVE number are a curated collection of a particular kind of fault, i.e., information-security vulnerabilities. Data on 2,860 kernel CVEs is available. The data includes the first released version of the kernel containing the problem, and the version of the fixed release. The plot below shows the survival curve for kernel CVEs, with confidence intervals in blue/green (code+data):
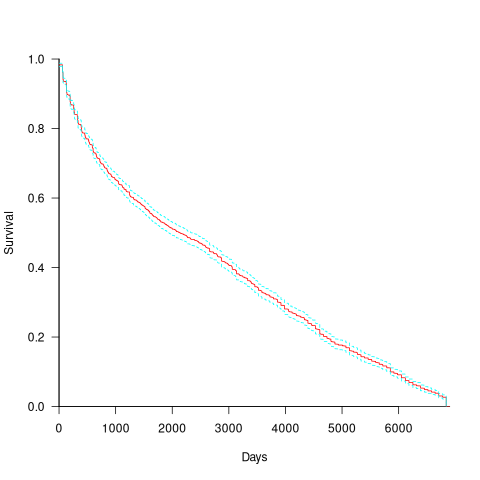
The survival curve appears to have two parts: the steeper decline during the first 1,000 days, followed by a slower, constant decline out to 16+ years.
Some good news is that many of these CVEs are likely to be in components that would not be installed in a safety critical application.
1970s: the founding decade of software reliability research
Reliability research is a worthwhile investment for very large organizations that fund the development of many major mission-critical software systems, where reliability is essential. In the 1970s, the US Air Force’s Rome Air Development Center probably funded most of the evidence-based software research carried out in the previous century. In the 1980s, Rome fell, and the dark ages lasted for many decades (student subjects, formal methods, and mutation testing).
Organizations sponsor research into software reliability because they want to find ways of reducing the number of coding mistakes, and/or the impact of these mistakes, and/or reduce the cost of achieving a given level of reliability.
Control requires understanding, and understanding reliability first requires figuring out the factors that are the primarily drivers of program reliability.
How did researchers go about finding these primary factors? When researching a new field (e.g., software reliability in the 1970s), people can simply collect the data that is right in front of them that is easy to measure.
For industrial researchers, data was collected from completed projects, and for academic researchers, the data came from student exercises.
For a completed project, the available data are the reported errors and the source code. This data be able to answer questions such as: what kinds of error occur, how much effort is needed to fix them, and how common is each kind of error?
Various classification schemes have been devised, including: functional units of an application (e.g., computation, data management, user interface), and coding construct (e.g., control structures, arithmetic expressions, function calls). As a research topic, kinds-of-error has not attracted much attention; probably because error classification requires a lot of manual work (perhaps the availability of LLMs will revive it). It’s a plausible idea, but nobody knows how large an effect it might be.
Looking at the data, it is very obvious that the number of faults increases with program size, measured in lines of code. These are two quantities that are easily measured and researchers have published extensively on the relationship between faults (however these are counted) and LOC (counted by function/class/file/program and with/without comments/blank lines). The problem with LOC is that measuring it appears to be too easy, and researchers keep concocting more obfuscated ways of counting lines.
What do we now know about the relationship between reported faults and LOC? Err, … The idea that there is an optimal number of LOC per function for minimizing faults has been debunked.
People don’t appear to be any nearer understanding the factors behind software reliability than at the end of the 1970s. Yes, tool support has improved enormously, and there are effective techniques and tools for finding and tracking coding mistakes.
Mistakes in programs are put there by the people who create the programs, and they are experienced by the people who use the programs. The two factors rarely researched in software reliability are the people building the systems and the people using them.
Fifty years later, what software reliability books/reports from the 1970s have yet to be improved on?
The 1987 edition (ISBN 0-07-044093-X) of “Software Reliability: Measurement, Prediction, Application” by Musa, Iannino, and Okumoto is based on research done in the 1970s (the 1990 professional edition is not nearly as good). Full of technical details, but unfortunately based on small datasets.
The 1978 book Software Reliability by Thayer, Lipow and Nelson, remains a go-to source for industrial reliability research data.
A good example of the industrial research funded by the Air Force is the 1979 report Software Data Baseline Analysis by D. L. Fish and T. Matsumoto. This is worth looking at just to learn how few rows of data later researchers have been relying on.
The units of measurement for software reliability
How do the people define software reliability? One answer can be found by analyzing defect report logs: one study found that 42.6% of fault reports were requests for an enhancement, changes to documentation, or a refactoring request; a study of NASA spaceflight software found that 63% of reports in the defect tracking system were change requests.
Users can be thought of as broadly defining software reliability as the ability to support current (i.e., the software works as intended) and future needs (i.e., functionality that the user does not yet know they need, e.g., one reason I use R, rather than Python, for data analysis, is because I believe that if a new-to-me technique is required, a package+documentation supporting this technique is more likely to be available in R).
Focusing on current needs, the definition of software reliability depends on the perspective of who you ask, possibilities include:
- commercial management: software reliability is measured in terms of cost-risk, i.e., the likelihood of losing an amount £/$ as a result of undesirable application behavior (either losses from internal use, or customer related losses such as refunds, hot-line support, and good will),
- Open source: reliability has to be good enough and at least as good as comparable projects. The unit of reliability might be fault experiences per use of the program, or the number of undesirable behaviors encountered when processing pre-existing material,
- user-centric: mean time between failure per uses of the application, e.g., for a word processor, documents written/edited. For compilers, mean time between failure per million lines of source translated,
- academic and perhaps a generic development team: mean time between failure per million lines/instructions executed by the application. The definition avoids having to deal with how the software is used,
- available data: numeric answers require measurement data to feed into a calculation. Data that is relatively easy to collect is cpu time consumed by tests that found some number of faults, or perhaps wall time, or scraping the bottom of the barrel the number of tests run.
If an organization wants to increase software reliability, they can pay to make the changes that increase reliability. Pointing this fact out to people can make them very annoyed.
Electronic Evidence and Electronic Signatures: book
Electronic Evidence and Electronic Signatures by Stephen Mason and Daniel Seng is not the sort of book that I would normally glance at twice (based on its title). However, at this start of the year I had an interesting email conversation with the first author, a commentator who worked for the defence team on the Horizon IT project case, and he emailed with the news that the fifth edition was now available (there’s a free pdf version, so why not have a look; sorry Stephen).
Regular readers of this blog will be interested in chapter 4 (“Software code as the witness”) and chapter 5 (“The presumption that computers are ‘reliable'”).
Legal arguments are based on precedent, i.e., decisions made by judges in earlier cases. The one thing that stands from these two chapters is how few cases have involved source code and/or reliability, and how simplistic the software issues have been (compared to issues that could have been involved). Perhaps the cases involving complicated software issues get simplified by the lawyers, or they look like they will be so difficult/expensive to litigate that the case don’t make it to court.
Chapter 4 provided various definitions of source code, all based around the concept of imperative programming, i.e., the code tells the computer what to do. No mention of declarative programming, where the code specifies the information required and the computer has to figure out how to obtain it (SQL being a widely used language based on this approach). The current Wikipedia article on source code is based on imperative programming, but the programming language article is not so narrowly focused (thanks to some work by several editors many years ago 😉
There is an interesting discussion around the idea of source code as hearsay, with a discussion of cases (see 4.34) where the person who wrote the code had to give evidence so that the program output could be admitted as evidence. I don’t know how often the person who wrote the code has to give evidence, but these days code often has multiple authors, and their identity is not always known (e.g., author details have been lost, or the submission effectively came via an anonymous email).
Chapter 5 considers the common law presumption in the law of England and Wales that ‘In the absence of evidence to the contrary, the courts will presume that mechanical instruments were in order. Yikes! The fact that this is presumption is nonsense, at least for computers, was discussed in an earlier post.
There is plenty of case law discussion around the accuracy of devices used to breath-test motorists for their alcohol level, and defendants being refused access to the devices and associated software. Now, I’m sure that the software contained in these devices contains coding mistakes, but was a particular positive the result of a coding mistake? Without replicating the exact conditions occurring during the original test, it could be very difficult to say. The prosecution and Judges make the common mistake of assuming that because the science behind the test had been validated, the device must produce correct results; ignoring the fact that the implementation of the science in software may contain implementation mistakes. I have lost count of the number of times that scientist/programmers have told me that because the science behind their code is correct, the program output must be correct. My retort that there are typos in the scientific papers they write, therefore there may be typos in their code, usually fails to change their mind; they are so fixated on the correctness of the science that possible mistakes elsewhere are brushed aside.
The naivety of some judges is astonishing. In one case (see 5.44) a professor who was an expert in mathematics, physics and computers, who had read the user manual for an application, but had not seen its source code, was considered qualified to give evidence about the operation of the software!
Much of chapter 5 is essentially an overview of software reliability, written by a barrister for legal professionals, i.e., it is not always a discussion of case law. A barristers’ explanation of how software works can be entertainingly inaccurate, but the material here is correct in a broad brush sense (and I did not spot any entertainingly inaccuracies).
Other than breath-testing, the defence asking for source code is rather like a dog chasing a car. The software for breath-testing devices is likely to be small enough that one person might do a decent job of figuring out how it works; many software systems are not only much, much larger, but are dependent on an ecosystem of hardware/software to run. Figuring out how they work will take multiple (expensive expert) people a lot of time.
Legal precedents are set when both sides spend the money needed to see a court case through to the end. It’s understandable why the case law discussed in this book is so sparse and deals with relatively simple software issues. The costs of fighting a case involving the complexity of modern software is going to be astronomical.
Learning useful stuff from the Reliability chapter of my book
What useful, practical things might professional software developers learn from my evidence-based software engineering book?
Once the book is officially released I need to have good answers to this question (saying: “Well, I decided to collect all the publicly available software engineering data and say something about it”, is not going to motivate people to read the book).
This week I checked the reliability chapter; what useful things did I learn (combined with everything I learned during all the other weeks spent working on this chapter)?
A casual reader skimming the chapter would conclude that little was known about software reliability, and they would be right (I already knew this, but I learned that we know even less than I thought was known), and many researchers continue to dig in unproductive holes.
A reader with some familiarity with reliability research would be surprised to see that some ‘major’ topics are not discussed.
The train wreck that is machine learning has been avoided (not forgetting that the data used is mostly worthless), mutation testing gets mentioned because of some interesting data (the underlying problem is that mutation testing assumes that coding mistakes are local to one line, but in practice coding mistakes often involve multiple lines), and the theory discussions don’t mention non-homogeneous Poisson process as the basis for software fault models (because this process is not capable of solving the questions asked).
What did I learn? My highlights include:
- Anne Choa‘s work on population estimation. The takeaway from this work is that if people want to estimate the number of remaining fault experiences, based on previous experienced faults, then every occurrence (i.e., not just the first) of a fault needs to be counted,
- Phyllis Nagel and Janet Dunham’s top read work on software testing,
- the variability in the numeric percentage that people assign to probability terms (e.g., almost all, likely, unlikely) is much wider than I would have thought,
- the impact of the distribution of input values on fault experiences may be detectable,
- really a lowlight, but there is a lot less publicly available data than I had expected (for the other chapters there was more data than I had expected).
The last decade has seen fuzzing grow to dominate the headlines around software reliability and testing, and provide data for people who write evidence-based books. I don’t have much of a feel for how widely used it is in industry, but it is a very useful tool for reliability researchers.
Readers might have a completely different learning experience from reading the reliability chapter. What useful things did you learn from the reliability chapter?
Reliability chapter of ‘evidence-based software engineering’ updated
The Reliability chapter of my evidence-based software engineering book has been updated (draft pdf).
Unlike the earlier chapters, there were no major changes to the initial version from over 18-months ago; we just don’t know much about software reliability, and there is not much public data.
There are lots of papers published claiming to be about software reliability, but they are mostly smoke-and-mirror shows derived from work down one of several popular rabbit holes:
- Machine learning is a popular technique for fault prediction, and I have written about what a train wreck this research is, along with the incomplete and very noisy data that makes nearly every attempt at fault prediction a waste of time.
- Mutation testing sounds like a technique that would be useful (and it is for pumping out papers), but it has the fatal flaw of telling people what they already know (i.e., that their test suites are not very good), and targeting coding mistakes that represent around 5% of known fault experiences (around 5% of all fixes to reported faults involve changing one line; most mutation testing works by modifying a single line of code).
- Other researchers are busily adding more epicycles to models based on the nonhomogeneous Poisson process.
The growth in research on Fuzzing is the only good news (especially with the availability of practical introductory material).
There is one source of fault experience data that looks like it might be very useful, but it’s hard to get hold of; NASA has kept detailed about what happened using space missions. I have had several people promise to send me data, but none has arrived yet :-(.
Updating the reliability chapter did not take too much time, so I updated earlier chapters with data that has arrived since they were last released.
As always, if you know of any interesting software engineering data, please tell me.
Next, the Source code chapter.
Design considerations for Mars colony computer systems
A very interesting article discussing SpaceX’s dramatically lower launch costs has convinced me that, in a decade or two, it will become economically viable to send people to Mars. Whether lots of people will be willing to go is another matter, but let’s assume that a non-trivial number of people decide to spend many years living in a colony on Mars; what computing hardware and software should they take with them?
Reliability and repairability are crucial. Same-day delivery of replacement parts is not an option; the opportunity for Earth/Mars travel occurs every 2-years (when both planets are on the same side of the Sun), and the journey takes 4-10 months.
Given the much higher radiation levels on Mars (200 mS/year; on Earth background radiation is around 3 mS/year), modern microelectronics will experience frequent bit-flips and have a low survival rate. Miniaturization is great for packing billions of transistors into a device, but increases the likelihood that a high energy particle traveling through the device will create a permanent short-circuit; Moore’s law has a much shorter useful life on Mars, compared to Earth. The lesser high energy particles can flip the current value of one or more bits.
Reliability and repairability of electronics, compared to other compute and control options, dictates minimizing the use of electronics (pneumatics is a viable replacement for many tasks; think World War II submarines), and simple calculation can be made using a slide rule or mechanical calculator (both are reliable, and possible to repair with simple tools). Some of the issues that need to be addressed when electronic devices are a proposed solution include:
- integrated circuits need to be fabricated with feature widths that are large enough such that devices are not unduly affected by background radiation,
- devices need to be built from exchangeable components, so if one breaks the others can be used as spares. Building a device from discrete components is great for exchangeability, but is not practical for building complicated cpus; one solution is to use simple cpus, and integrated circuits come in various sizes.
- use of devices that can be repaired or new ones manufactured on Mars. For instance, core memory might be locally repairable, and eventually locally produced.
There are lots of benefits from using the same cpu for everything, with ARM being the obvious choice. Some might suggest RISC-V, and perhaps this will be a better choice many years from now, when a Mars colony is being seriously planned.
Commercially available electronic storage devices have lifetimes measured in years, with a few passive media having lifetimes measured in decades (e.g., optical media); some early electronic storage devices had lifetimes likely to be measured in decades. Perhaps it is possible to produce hard discs with expected lifetimes measured in decades, research is needed (or computing on Mars will have to function without hard discs).
The media on which the source is held will degrade over time. Engraving important source code on the walls of colony housing is one long term storage technique; rather like the hieroglyphs on ancient Egyptian buildings.
What about displays? Have lots of small, same size, flat-screens, and fit them together for greater surface area. I don’t know much about displays, so won’t say more.
Computers built from discrete components consume lots of power (much lower power consumption is a benefit of fabricating smaller devices). No problem, they can double as heating systems. Switching power supplies can be very reliable.
Radio communications require electronics. The radios on the Voyager spacecraft have been operating for 42 years, which suggests to me that reliable communication equipment can be built (I know very little about radio electronics).
What about the software?
Repairability requires that software be open source, or some kind of Mars-use only source license.
The computer language of choice is obviously C, whose advantages include:
- lots of existing, heavily used, operating systems are written in C (i.e., no need to write, and extensively test, a new one),
- C compilers are much easier to implement than, say, C++ or Java compilers. If the C compiler gets lost, somebody could bootstrap another one (lots of individuals used to write and successfully sell C compilers),
- computer storage will be a premium on Mars based computers, and C supports getting close to the hardware to maximise efficient use of resources.
The operating system of choice may not be Linux. With memory at a premium, operating systems requiring many megabytes are bad news. Computers with 64k of storage (yes, kilobytes) used to be used to do lots of useful work; see the source code of various 1980’s operating systems.
Applications can be written before departure. Maintainability and readability are marketing terms, i.e., we don’t really know how to do this stuff. Extensive testing is a good technique for gaining confidence that software behaves as expected, and the test suite can be shipped with the software.
Reliability chapter added to “Empirical software engineering using R”
The Reliability chapter of my Empirical software engineering book has been added to the draft pdf (download here).
I have been working on this draft for four months and it still needs lots of work; time to move on and let it stew for a while. Part of the problem is lack of public data; cost and schedule overruns can be rather public (projects chapter), but reliability problems are easier to keep quiet.
Originally there was a chapter covering reliability and another one covering faults. As time passed, these merged into one. The material kept evaporating in front of my eyes (around a third of the initial draft, collected over the years, was deleted); I have already written about why most fault prediction research is a waste of time. If it had not been for Rome I would not have had much to write about.
Perhaps what will jump out at people most, is that I distinguish between mistakes in code and what I call a fault experience. A fault_experience=mistake_in_code + particular_input. Most fault researchers have been completely ignoring half of what goes into every fault experience, the input profile (if the user does not notice a fault, I do not consider it experienced) . It’s incredibly difficult to figure out anything about the input profile, so it has been quietly ignored (one of the reasons why research papers on reported faults are such a waste of time).
I’m also missing an ‘interesting’ figure on the opening page of the chapter. Suggestions welcome.
I have not said much about source code characteristics. There is a chapter covering source code, perhaps some of this material will migrate to reliability.
All sorts of interesting bits and pieces have been added to earlier chapters. Ecosystems keeps growing and in years to come somebody will write a multi-volume tomb on software ecosystems.
I have been promised all sorts of data. Hopefully some of it will arrive.
As always, if you know of any interesting software engineering data, please tell me.
Source code chapter next.
Recent Comments