Archive
Apollo guidance computer software development process
MIT’s Draper Lab implemented the primary Guidance, Navigation and Control System (GNCS) for the Apollo spacecraft, i.e., the hardware+software (the source code is now available on GitHub). Project Apollo ran from 1961 to 1972, and many MIT project reports are available (the five volume set: “MIT’s Role in Project Apollo” probably contains more than you want to know).
What development processes were used to implement the Apollo GNCS software?
For decades, I was told that large organizations, such as NASA, used the Waterfall method to develop software. Did the implementation of the Apollo GNCS software use a Waterfall process?
Readers will be familiar with the wide gulf that can exist between documented management plans and what developers actually did (which is rarely documented). One technique for gaining insight into development practices is to follow the money. Implementation work is a cost, and a detailed cost breakdown timeline of the various development activities provides some insight into the work flow. Gold dust: Daniel Rankin’s 1972 Master’s thesis lists the Apollo project software development costs for each 6-month period from the start of 1962 until the end of 1970; it also gives the number of 16-bit words (the size of an instruction) contained in each binary release, along with the number of new instructions.
The GNCS computer contained 36,864 16-bit words of read-only memory and 2,048 words of read/write memory. The Apollo spacecraft contained two GNCS computers. The plot below shows the cumulative number of new code (in words) contained in all binary releases and the instructions contained in each binary release, with Apollo numbers at the release date of the code for that mission; grey lines show read only word limit and read-only plus twice read/write word limit (code+data):
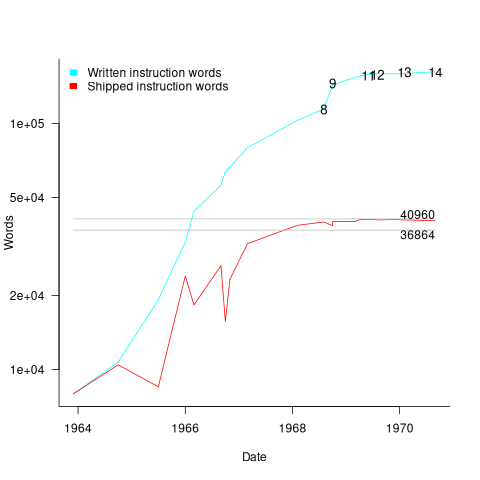
Four times as many instructions appeared over all releases, than made it into the final release. The continual turn-over of code in each release implies an iterative development process prior to the first manned launch, Apollo 8 (possibly an iterative waterfall process). After the first moon landing, Apollo 11, there were very few code changes for Apollo 12/13/14 (no data is available for the Apollo 15/16/17 missions).
The plot below shows thousands of dollars spent on the various software development activities within each 6-month period; the computing items are the cost of computer usage (code+data):
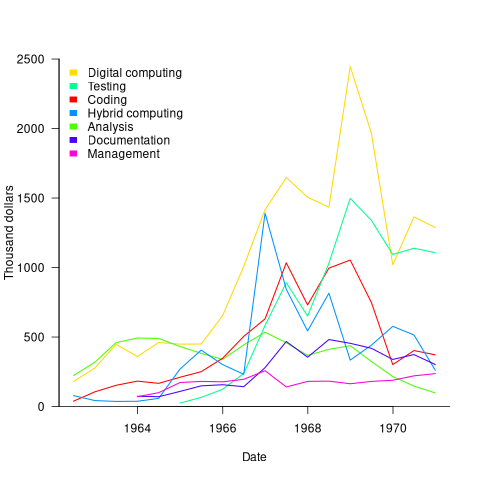
The plot suggests that most activities are ongoing over most of the decade. As expected, Coding costs significantly decrease before the release used during the first Moon landing, and testing costs continue at a high rate across the Apollo 11/12/13/14 missions. Why didn’t the Documentation costs go down when the Coding costs went down? Perhaps this was for some upcoming changes (not the Lunar rover which was built by Boeing). Activities in the legend are ordered by total amount spent; totals below:
Digital_Computer $18,373,000 Testing $ 9,786,000 Coding $ 8,233,000 Hybrid_Computer $ 7,190,000 Analysis $ 6,580,000 Documentation $ 4,177,000 Management $ 2,654,000 |
I think this data clearly shows that the Apollo GNCS software was developed using an iterative approach, and given that the cost of Coding was only twice as much as Documentation, within these iterations some form of Waterfall process was probably used.
What can be learned from studying long gone development practices?
Current ideas about the best way of building a software system are heavily influenced by the ideas that captured the attention of previous generations of developers. Can anything of practical use be learned from studying long gone techniques for building software systems?
During the writing of my software engineering book, I was spending a lot of time researching the development techniques used during the twentieth century, and one day I suddenly realised that this was a waste of time. While early software developers tend to be eulogized today, the reality is that they were mostly people who had little idea what they were doing, who through personal competence of being in the right place at the right time managed to produce something good enough. On the whole, twentieth century software development techniques are only of historical interest. Yes, some timeless development principles were discovered, and these can be integrated into today’s techniques (which may also turn out to be of their-time).
My experience of software development in the late 1970s and 1980s is that there was rarely any connection between what management told the world about the development process, and how those reporting to the manager actually did the development.
If you are a manager in a world where software development is still very new, and you are given the job of managing the development of a software system, how do you go about it? A common approach is to apply the techniques that are already being used to run the manager’s organization. On a regular basis, managers came up with the idea of applying techniques from the science of industrial production (which is still happening today).
In the 1970s and 1980s there were usually very visible job hierarchies, and sharply defined roles. Organizations tended to use their existing job hierarchies and roles to create the structure for their software development employees. For years after I started work as a graduate, managers and secretaries were surprised to see me typing; secretaries typed, men did not type, and women developers fumed when they were treated like secretaries (because they had been seen typing).
The manual workers performed data entry, operated the computer (e.g., mounted tapes, and looked after the printer). The junior staff often started with the job title programmer, or perhaps junior programmer and there might be senior programmers; on paper these people wrote the code to implement the functionality specified by a systems analyst (or just analyst, or business analyst, perhaps with added junior or senior). Analysts did not to write code and programmers only coded what the specification they were given, at least according to management.
Pay level was set by the position in the job hierarchy, with those higher up earning more than those below them, and job titles/roles were also mapped to positions in the hierarchy. This created, in theory, a direct correspondence between pay and job title/role. In practice, organizations wanted to keep their productive employees, and so were flexible about the correspondence between pay and title, e.g., during their annual review some people were more interested in the status provided by a job title, while others wanted more money and did not care about job titles. Add into this mix the fact that pay/title levels rarely matched up between organizations, it soon became obvious to all that software job titles were a charade.
How should the people at the sharp end go about building a software system?
Structured programming was the widely cited technique in the 1970s. Consultants promoted their own variants, with Jackson structured programming being widely known in the UK, with regular courses and consultants offering to train staff. Today, structured programming appears remarkably simplistic, great for writing tiny programs (it has an academic pedigree), but not for anything larger than a thousand lines. Part of its appeal may have been this simplicity, many programs were small (because computer memory was measured in kilobytes) and management often thought that problems were simple (a recurring problem). There were a few adaptations that tried to address larger scale issues, e.g., Warnier/Orr structured programming.
The military were major employers of software developers in the 1960s and 1970s. In the US Work Breakdown Structure was mandated by the DOD for project development (for all projects, not just software), and in the UK we had MASCOT. These mandated development methodologies were created by committees, and have not been experimentally tested to be better/worse than any other approach.
I think the best management technique for successfully developing a software system in the 1970s and 1980s (and perhaps in the following decades), is based on being lucky enough to have a few very capable people, and then providing them with what is needed to get the job done while maintaining the fiction to upper management that the agreed bureaucratic plan is being followed.
There is one technique for producing a software system that rarely gets mentioned: keep paying for development until something good enough is delivered. Given the life-or-death need an organization might have for some software systems, paying what it takes may well have been a prevalent methodology during the early days of major software development.
To answer the question posed at the start of this post. What might be learned from a study of early software development techniques is the need for management to have lots of luck and to be flexible; funding is easier to obtain when managing a life-or-death project.
Having all the source code in one file
An early, and supposedly influential, analysis of the Coronavirus outbreak was based on results from a model whose 15,000 line C implementation was contained in a single file. There has been lots of tut-tutting from the peanut gallery, about the code all being in one file rather than distributed over many files. The source on Github has been heavily reworked.
Why do programmers work with all the code in one file, rather than split across multiple files? What are the costs and benefits of having the 15K of source in one file, compared to distributing it across multiple files?
There are two kinds of people who work with code all in one file, novices and really capable developers. Richard Stallman is an example of a very capable developer who worked using files containing huge amounts of code, as anybody who looked at the early sources of gcc will be all to familiar.
The benefit of having all the code in one file is that it is easy to find stuff and make global changes. If the source is scattered over multiple files, then working on the code entails knowing which file to look in to find whatever; there is a learning curve (these days screens have lots of pixels, and editors support multiple windows with a different file in each window; I’m sure lots of readers work like this).
Many years ago, when 64K was a lot of memory, I sometimes had to do developer support: people would come to me complaining that the computer was preventing them writing a larger program. What had happened was they had hit the capacity limit of the editor. The source now had to be spread over multiple files to get over this ‘limitation’. In practice people experienced the benefits of using multiple files, e.g., editor loading files faster (because they were a lot smaller) and reduced program build time (because only the code that changed needed to be recompiled).
These days, 15K of source can be loaded or compiled in a blink of an eye (unless a really cheap laptop is being used). Computing power has significantly reduced these benefits that used to exist.
What costs might be associated with keeping all the source in one file?
Monolithic code makes sharing difficult. I don’t know anything about the development environment within which these researched worked. If there were lots of different programs using the same algorithms, or reading/writing the same file formats, then code reuse often provides a benefit that makes it worthwhile splitting off the common functionality. But then the researchers has to learn how to build a program from multiple source files, which a surprising number are unwilling to do (at least it has always been surprising to me).
Within a research group, sharing across researchers might be a possible (assuming they are making some use of the same algorithms and file formats). Involving multiple people in the ongoing evolution of software creates a need for some coordination. At the individual level it may be more cost-efficient for people to have their own private copies of the source, with savings only occurring at the group level. With software development having a low status in academia, I don’t see any of the senior researchers willingly take on a management role, for this code. Perhaps one of the people working on the code is much better than the others (it often happens), but are they going to volunteer themselves as chief dogs body for the code?
In the world of Open Source, where source code is available, cut-and-paste is rampant (along with wholesale copying of files). Working with a copy of somebody else’s source removes a dependency, and if their code works well enough, then go for it.
A cost often claimed by the peanut gallery is that having all the code in a single file is a signal of buggy code. Given that most of the programmers who do this are novices, rather than really capable developers, such code is likely to contain many mistakes. But splitting the code up into multiple files will not reduce the number of mistakes it contains, just distribute them among the files. Correlation is not causation.
For an individual developer, the main benefit of splitting code across multiple files is that it makes developers think about the structure of their code.
For multi-person projects there are the added potential benefits of reusing code, and reducing the time spent reading other people’s code (it’s no fun having to deal with 10K lines when only a few functions are of interest).
I’m not saying that the original code is good, bad, or indifferent. What I am saying is that the having all the source in one file may, or may not, be the most effective way of working. It’s complicated, and I have no problem going with the flow (and limiting the size of the source files I write), but let’s not criticise others for doing what works for them.
Has the seed that gets software development out of the stone-age been sown?
A big puzzle for archaeologists is why Stone Age culture lasted as long as it did (from approximately 2.5 millions years ago until the start of the copper age around 6.3 thousand years ago). Given the range of innovation rates seen in various cultures through-out human history, a much shorter Stone Age is to be expected. A recent paper proposes that low population density is what maintained the Stone Age status quo; there was not enough contact between different hunter gather groups for widespread take up of innovations. Life was tough, and the viable lifetime of individual groups of people may not have been long enough for them to be likely to pass on innovations (either their own ones encountered through contact with other groups).
Software development is often done by small groups that don’t communicate with other groups and regularly die out (well there is a high turn-over, with many of the more experienced people moving on to non-software roles). There are sufficient parallels between hunter gathers and software developers to suggest both were/are kept in a Stone Age for the same reason, lack of a method that enables people to obtain information about innovations and how worthwhile these might be within a given environment.
A huge barrier to the development of better software development practices is the almost complete lack of significant quantities of reliable empirical data that can be used to judge whether a claimed innovation is really worthwhile. Companies rarely make their detailed fault databases and product development history public; who wants to risk negative publicity and lawsuits just so academics have some data to work with.
At the start of this decade, public source code repositories like SourceForge and public software fault repositories like Bugzilla started to spring up. These repositories contain a huge amount of information about the characteristics of the software development process. Questions that can be asked of this data include: what are common patterns of development and which ones result in fewer faults, how does software evolve and how well do the techniques used to manage it work.
Empirical software engineering researchers are now setting up repositories, like Promise, containing the raw data from their analysis of Open Source (and some closed source) projects. By making this raw data available, they are reducing the effort needed by other researchers to investigate their own alternative ideas (I have just started a book on empirical software engineering using the R statistical language that uses examples based on this raw data).
One of the side effects of Open Source development could be the creation of software development practices that have been shown to be better (including showing that some existing practices make things worse). The source of these practices not being what the software developers themselves do or how they do it, but the footsteps they have left behind in the sand.
Recent Comments