Archive
Dennard scaling a necessary condition for Moore’s law
Dennard scaling was a necessary, but not sufficient, condition for Moore’s law to play out over many decades. Transistors generate heat, and continually adding more transistors to a device will eventually cause it to melt, because the generated heat cannot be removed fast enough. However, if the fabrication of transistors on the surface of a monolithic silicon semiconductor follows the Dennard scaling rules, then more, smaller transistors can be added without any increase in heat generated per unit area. These scaling rules were first given in the 1974 paper Design of Ion-Implanted MOSFET’S with Very Small Physical Dimensions by Dennard, Gaensslen, Hwa-Nien, Rideout, Bassous, and LeBlanc.
The plot below shows a vertical slice through a Metal–Oxide–Semiconductor Field-Effect Transistor (the kind of transistor used to build microprocessors), with the fabrication parameters applicable to Dennard scaling labelled. A transistor has three connections (only one is show), to the Source, the Drain, and the Gate. The Source and Drain are doped with an element from Group V to produce a surplus of electrons, while the substrate is doped with an element from Group III to create holes that accept electrons. A voltage applied to the Gate creates an electric field that modifies the shape of the depletion region (area above blue dashed line), enabling the flow of electrons between the Source and Drain to be switched on or off.
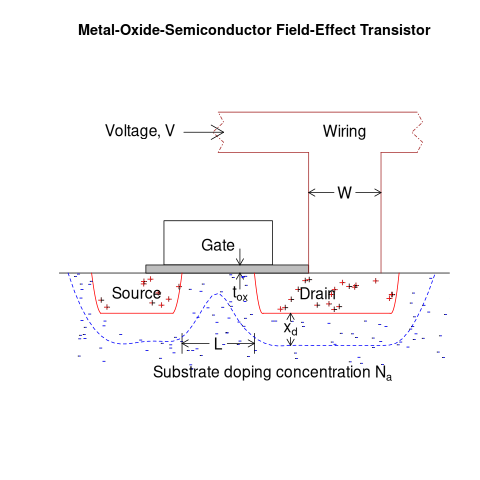
The parameters are: operating voltage,  , width of the connecting wires,
, width of the connecting wires,  , length of the channel between the Source and Drain,
, length of the channel between the Source and Drain,  , thickness of the dielectric material (e.g., silicon oxynitride) under the Gate (shown in grey),
, thickness of the dielectric material (e.g., silicon oxynitride) under the Gate (shown in grey),  , doping concentration,
, doping concentration,  , and length of the depletion region,
, and length of the depletion region,  .
.
The power,  , consumed by any electronic device is
, consumed by any electronic device is  , where
, where  is the current through it and the voltage across it. In an ideal transistor, in the off state
is the current through it and the voltage across it. In an ideal transistor, in the off state  and no power is consumed, and in the on state is at its maximum, but
and no power is consumed, and in the on state is at its maximum, but  and no power is consumed. Power is only consumed during the transition between the two states, when both and are non-zero. In real transistors, there is some amount of leakage in the off/on states and a small amount of power is consumed.
and no power is consumed. Power is only consumed during the transition between the two states, when both and are non-zero. In real transistors, there is some amount of leakage in the off/on states and a small amount of power is consumed.
Increasing the frequency,  , at which a transistor is operated increases the number of state transitions, which increases the power consumed. The power consumed per unit time by a transistor is
, at which a transistor is operated increases the number of state transitions, which increases the power consumed. The power consumed per unit time by a transistor is  . If there are
. If there are  transistors per unit area, the power consumed within that area is:
transistors per unit area, the power consumed within that area is:  .
.
The current, , can be written in terms of the factors that control it, as:  .
.
If the values of , , , and are all reduced by a factor of  (often around 30%, giving
(often around 30%, giving  ), then
), then  is reduced by a factor of
is reduced by a factor of  ,
, ^2=2") .
.
^2}}/{{L/alpha}*{t_{ox}/alpha}}}{V/alpha}={{N*f}/alpha^2}{{W*V^3}/{L*t_{ox}}}")
The area occupied by a transistor,  , decreases by , making it possible to increase the number of transistors within the same unit area to:
, decreases by , making it possible to increase the number of transistors within the same unit area to:  . The transistors consume less power, but there are more of them, and power per unit area after the size reduction is the same as before reduction,
. The transistors consume less power, but there are more of them, and power per unit area after the size reduction is the same as before reduction,  .
.
Reducing the channel length, , has a detrimental impact on device performance. However, this can be overcome by increasing the density of the doping in the substrate, , by .
The maximum frequency at which a transistor can be operated is limited by its capacitance. The Gate capacitance is the major factor, and this decreases in proportion to the device dimensions, i.e., . A decrease in capacitance enables the operating frequency, , to increase. Capacitance was not included in the previous formula for power consumption. An alternative derivation finds that  , where
, where  is the capacitance, i.e., power consumption is unchanged when a frequency increase is matched by a corresponding decrease in capacitance.
is the capacitance, i.e., power consumption is unchanged when a frequency increase is matched by a corresponding decrease in capacitance.
The first working transistor was created in 1947 and the first MOSFET in 1959. The plot below, with data from various sources, shows the energy consumed by a transistor, fabricated in various years, switching between states, the red line is the fitted regression equation  , the green line is the fitted equation
, the green line is the fitted equation  , and the grey line shows the Landauer limit for the energy consumption of a computation at room temperature (code and data; also see The End of Moore’s Law: A New Beginning for Information Technology by Theis and Wong):
, and the grey line shows the Landauer limit for the energy consumption of a computation at room temperature (code and data; also see The End of Moore’s Law: A New Beginning for Information Technology by Theis and Wong):
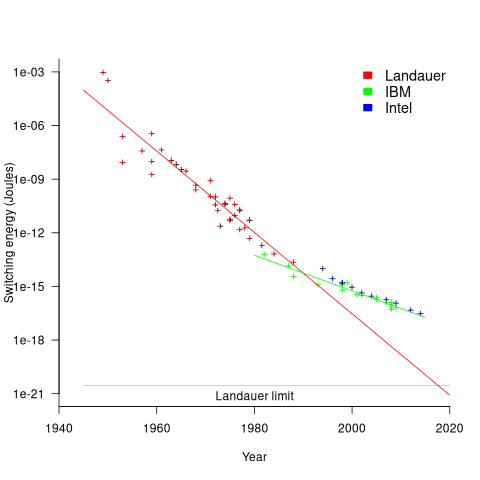
Scaling cannot go on forever. The two limits reached were voltage (difficulty reducing below 1V) and the thickness of the Gate dielectric layer (significant leakage current when less than 7 atoms thick).
The slow-down in the reduction of switching energy, in the plot above, is due to a slow-down in voltage reduction, i.e., reduction of less than .
In 2007, cpu clock frequency stopped increasing and Dennard scaling halted. In this year, the Gate and its dielectric was completely redesigned to use a high-k dielectric such as Hafnium oxide, which allowed transistor size to continue decreasing. However, since around 2014 the rate of decrease has slowed and process node numbers have become marketing values without any connection to the size of fabricated structures. Is 2014 the year that Moore’s law died? Some people think the year was 2010, while Intel still trumpet the law named after one of their founders.
CPU power consumption and bit-similarity of input
Changing the state of a digital circuit (i.e., changing its value from zero to one, or from one to zero) requires more electrical power than leaving its state unchanged. During program execution, the power consumed by each instruction depends on the value of its operand(s). The plot below, from an earlier post, shows how the power consumed by an 8-bit multiply instruction varies with the values of its two operands:
An increase in cpu power consumption produces an increase in its temperature. If the temperature gets too high, the cpu’s DVFS (dynamic voltage and frequency scaling) will slow down the processor to prevent it overheating.
When a calculation involves a huge number of values (e.g., an LLM size matrix multiply), how large an impact is variability of input values likely to have on the power consumed?
The 2022 paper: Understanding the Impact of Input Entropy on FPU, CPU, and GPU Power by S. Bhalachandra, B. Austin, S. Williams, and N. J. Wright, compared matrix multiple power consumption when all elements of the matrices had the same values (i.e., minimum entropy) and when all elements had different random values (i.e., maximum entropy).
The plot below shows the power consumed by an NVIDIA A100 Ampere GPU while multiplying two 16,384 by 16,384 matrices (performed 100 times). The GPU was power limited to 400W, so the random value performance was lower at 18.6 TFLOP/s, against 19.4 TFLOP/s for same values; (I don’t know why the startup times differ; code+data):
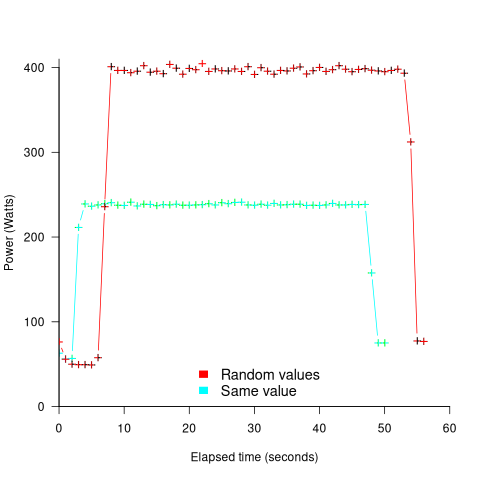
This 67% performance difference is more than an interesting factoid. Large computations are distributed over multiple GPUs, and the output from each GPU is sometimes feed as input to other GPUs. The flow of computations around a cluster of GPUs needs to be synchronised, and having compute time depend on the distribution of the input values makes life complicated.
Is it possible to organise a sequence of calculation to reduce the average power consumed?
The higher order bits of small integers are zero, but how many long calculations involve small integers? The bit pattern of floating-point values are more difficult to predict, but I’m sure there is a PhD thesis or two waiting to be written around this issue.
How will C code in 2045 look different from today?
What constructs will be in such common use in C source code written by developers in 2045 that people looking at C written in 2015 will know it comes from a much earlier era (a previous post looked back at C written in 1986)?
C is a high level language that allows developers to get close to the hardware, so to get some idea of what everyday C might be like in 2045 we have to ask what everyday hardware will be like 10-20 years from now (the C standard committee waits for hardware feature to become established before adding features to support them).
I think the following hardware trends will have a big impact on the future appearance of C source code:
Power consumption: Runtime performance is an integral part of the design of C. In the past performance has been about program execution time and/or memory usage; the spread of mobile computing has created a third strand: electrical power consumption. A variety of techniques have been proposed for reducing program power consumption, including: type specifiers that enable developers to tell the compiler accuracy can be traded off against power in calculations involving a given variable and scaling cpu voltage/frequency in non-time critical code (researchers are currently trying to do this without developer involvement, but a storage/type specifier like register or inline would provide useful information to the compiler),
Unreliable hardware: running hardware at lower voltages (to reduce power consumption) increases the probability of noise having an effect on program output, as does use of smaller line widths in cpu fabrication (more chips per die increases manufacturer profits). Proposed solutions include adding type specifiers to variables that can tolerate holding approximate values or more making probabilistic assertions.
Non-volatile memory: Like most languages C has an implicit model of programs sitting on a slow storage device, e.g., hard disk, and being loaded into very fast storage for execution. Non-volatile storage could have a very dramatic impact on this view of the world. For years gaming consoles have stored code+data as a memory image in ROM for rapid loading, but being able to write to storage that is only an order of magnitude slower than main memory opens up all sorts of interesting opportunities. The concept of named address spaces defined in Programming languages – C – Extensions to support embedded processors is waiting to expand out of its current niche of C on embedded processors.
There is at least one language construct that is likely to be rarely seen by developers working in 2045: inline. The reason that today’s developers have been given the ability to define functions inline is that compilers are not yet good enough to reliably make good function inlining decisions, rather like they were not good enough to reliability make good register allocation decisions 30 years ago (ok, register can still be useful for developers using weird and wonderful processor architectures or brain dead compilers).
I have not yet said anything about parallel processing or multiprocessor hardware. The C11 Standard updated C99 to provide generic support (i.e., _Atomic plus associated sequence point wording updates and the threads library) for this kind of hardware. Support for a specific parallel/multiprocessor model will happen if a specific model becomes the industry standard (rather like IEEE floating-point not being anointed by C90 because it was not yet what every hardware vendor used; other formats were on their last legs and by C99 could be treated as dead).
Power consumed by different instruction operand value pairs
We are all used to the idea that program performance (e.g., cpu, storage and power consumption) varies across different input data values. A very interesting new paper illustrates how the power consumption of individual instructions varies as instruction operand values change.
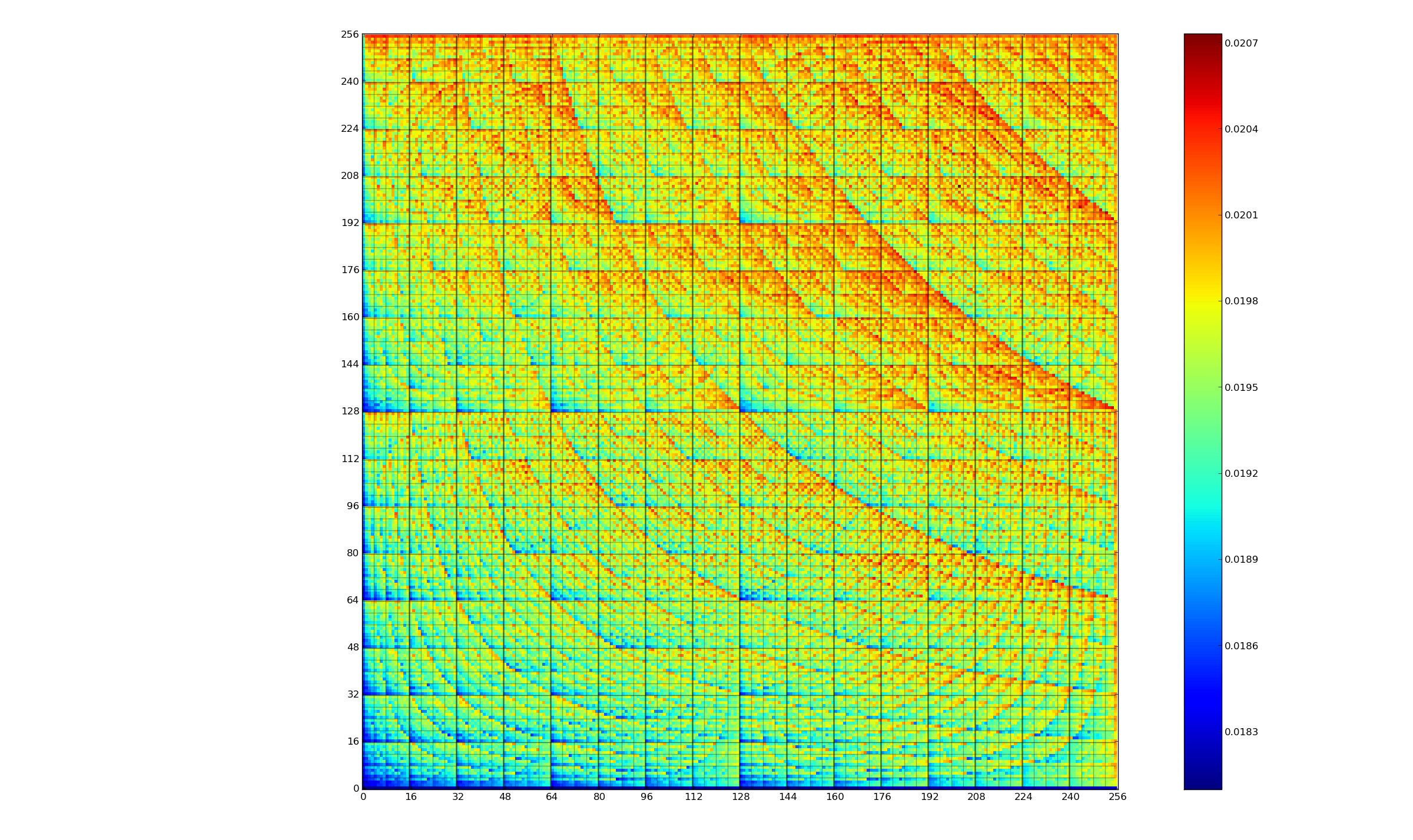
The graph below (thanks to Kerstin for sending me a color version, scale is in Joules) is a heatmap of the power consumed by the 8-bit multiply instruction of an XMOS XCore Atmel AVR cpu for all possible 8-bit values (with both operands in registers and producing a 16-bit result). Spare a thought for James Pallister who spent weeks of machine time properly gathering this data; by properly I mean he took account of the variability of modern processor power consumption and measured multiple devices (to relax James researches superoptimizing for minimal power consumption).
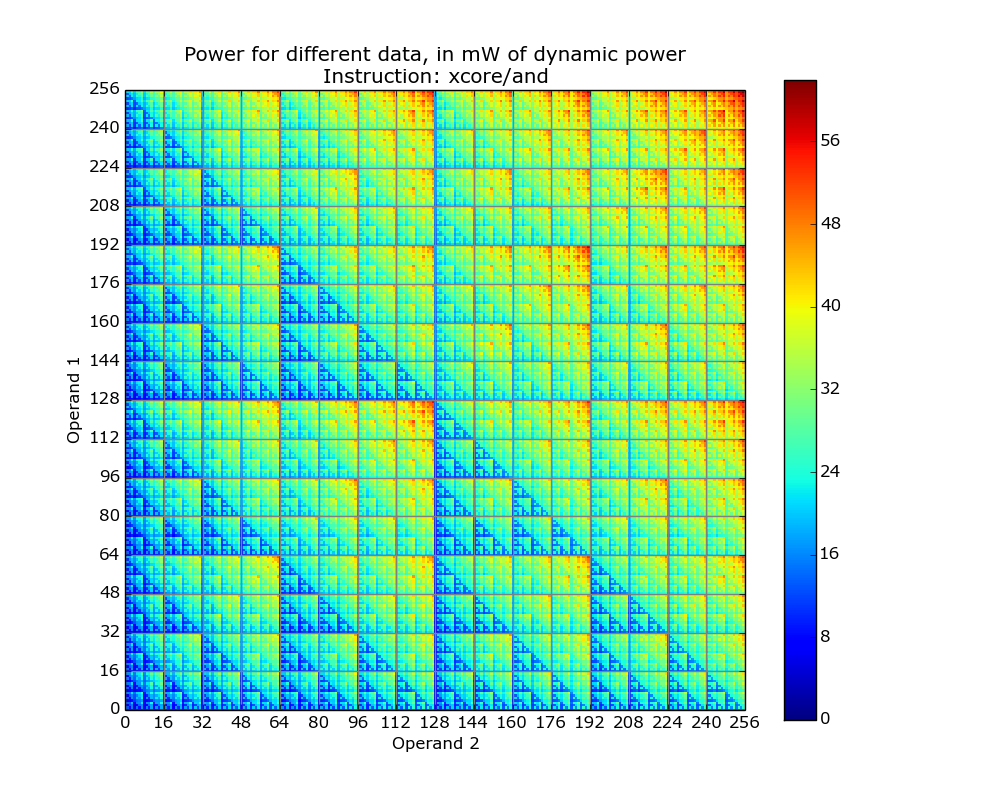
Why is power consumption not symmetric across the diagonal from bottom left to top right? I naively assumed power consumption would be independent of operand order. Have a think before seeing one possible answer further down.
The important thing you need to know about digital hardware power consumption is that change of state (i.e., 0-to-1 or 1-to-0) is what consumes most of the power in digital circuits (there is still a long way to go before the minimum limit set by the Margolus–Levitin theorem is reached).
The plot below is for the bit-wise AND instruction on a XMOS XCore cpu and its fractal-like appearance maps straight to the changing bit-patterns generated by the instruction (Jeremy Morse did this work).
Anyone interested in doing their own power consumption measurements should get a MAGEEC Energy Measurement Kit and for those who are really hardcore the schematics are available for you to build one yourself.
Why is power consumption asymmetrical? Think of paper and pencil multiplication, the smaller number is written under the larger number to minimise the number of operations that need to be performed. The ‘popular’ explanation of the top plot is that the cpu does the multiply in whatever order the operand values happen to be in, i.e., not switching the values to minimise power consumption. Do you know of any processors that switch operand order to minimise power consumption? Would making this check cost more than the saving? Chip engineers, where are you?
A plug for the ENTRA project and some of the other people working with James, Kerstin and Jeremy: Steve Kerrison and Kyriakos Georgiou.
Running Average Power Limit: a new target for viruses
I have been learning about the Running Average Power Limit, RAPL, feature that Intel introduced with their Sandy Bridge architecture. RAPL is part of a broader framework providing access to all kinds of interesting internal processor state (e.g., detailed instruction counts, cache accesses, branch information etc; use PAPI to get at the numbers on your system, existing perf users need at least version 3.14 of the Linux kernel).
My interest in RAPL is in using it to monitor the power consumed by short code sequences that are alternative implementations of some functionality. There are some issues that need to be sorted out before this is possible at the level of granularity I want to look at.
I suspect that RAPL might soon move from a very obscure feature to something that is very widely known and talked about; it provides a means for setting an upper limit on the average power consumed by a processor, under software control.
Some environmental activists are very militant and RAPL sounds like it can help save the planet by limiting the average power consumed by computers. Operating systems do provide various power saving options, but I wonder how widely they are used aggressively; one set of building based measurements shows a fairly constant rate of power consumption, smaller set showing a bit of daily variation.
How long will it be before a virus targeting RAPL appears?
Limiting the average power consumed by a processor is likely to result in programs running more slowly. Will the average user notice? Slower browser response could be caused by all sorts of things. Users are much more likely to notice a performance problem when watching a high definition video.
For service providers RAPL is another target to add to the list of possible denial-of-service attacks.
Ternary radix will have to wait for photonic computers
Computer cpu economics suggest that a ternary radix representation rather than binary should be used for representing integer values. The economic cost of a cpu is is roughly proportional to  , where
, where  is the integer radix and
is the integer radix and  is the width, in bits, of the basic integer type (for simplicity I’m assuming there is only one and that the bus width has the same value); the maximum value that can be represented is
is the width, in bits, of the basic integer type (for simplicity I’m assuming there is only one and that the bus width has the same value); the maximum value that can be represented is  .
.
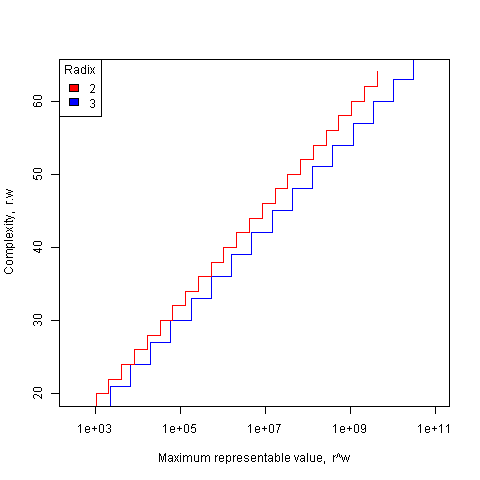
If we fix the maximum representable value  and ask which value of minimises , then we need to differentiate
and ask which value of minimises , then we need to differentiate  w.r.t. , giving
w.r.t. , giving ^2})") and this equals 0 when
and this equals 0 when  (the closest integer to
(the closest integer to  is 3).
is 3).
The following plot shows the maximum representable value (right point of horizontal line) that can be achieved for a given ‘cost’ when the radix is 2 and 3.
The reason binary is used in practice is purely to do with the characteristics of power consumption in electronic switching circuits (originally vacuum tube and then transistor based). Electrical power is proportional to voltage times current and a binary circuit can be implemented by switching between states where either the voltage or the current is very small, in either of these two states the power consumption is very low; it is only during the very short transition period switching between them, when the voltage and current have intermediate values, that the power consumed is relatively high. A 3-state switch would need a voltage/current combination denoting a state other than 0/1, and any such combination would consume non-trivial amounts of power (tri-state devices are used in some situations).
I have little idea about the complications of storing ternary values in memory systems, but I guess there will be complications.
In the 1960’s the Setun computer used a ternary radix and there has been the odd experimental systems since.
Are there any kinds of switching circuit whose use is not primarily dictated by device power characteristics and hence might be used to support a ternary radix? One possibility is a light based cpu (i.e., using photons rather than electrons), using polarization to specify state has been proposed. What about storage? Using Josephson junctions could provide the high speed and low power consumption required (we just need somebody to discover a room temperature superconductor).
The technology needed to build a practical cpu using a ternary radix appears to be some years in the future.
What about all the existing code containing a myriad of dependencies on the characteristics of two’s complement integer representation? If a photonic cpu became available that was ten times faster than existing cpus, or consumed 10 times less power or some combination thereof, then I’m sure here would be plenty of economic incentive to get software running on it. The problem is that 10 times better cpus are unlikely to just turn up, they will probably need to be developed in steps and the economics of progressing from step to step don’t look good.
While our civilization is likely to continue on down the binary rabbit hole, another one may have started down, or switched to, the ternary hole. I hope the SETI people are not to blinkered by the binary view of the universe.
Compiling to reduce the impact of soft errors on program output
Optimizing compilers have traditionally made code faster and smaller (sometimes a choice has to be made between faster/larger and slower/smaller). The huge growth in the use of battery power devices has created a new attribute for writers of optimizers to target, finding code sequences that minimise power consumption (I previously listed this as a major growth area in the next decade). Radiation (e.g., from cosmic rays) can cause a memory or processor bit to flip, known as a soft error, and I have recently been reading about how code can be optimized to reduce the probability that soft errors will alter the external behavior of a running program.
The soft error rate is usually quoted in FITs (Failure in Time), with 1 FIT corresponding to 1 error per  hours per megabit, or
hours per megabit, or  errors per bit-hour. A PC with 4 GB of DRAM (say 1000 FIT/Mb which increases with altitude and is 10 times greater in Denver, Colorado) has a MTBF (mean time between failure) of
errors per bit-hour. A PC with 4 GB of DRAM (say 1000 FIT/Mb which increases with altitude and is 10 times greater in Denver, Colorado) has a MTBF (mean time between failure) of  hours, around once every 33 hours. Calculating the FIT for processors is complicated.
hours, around once every 33 hours. Calculating the FIT for processors is complicated.
Uncorrected soft errors place a limit on the maximum number of computing nodes that can be usefully used by one application. At around 50,000 nodes, a system will be spending half its time saving checkpoints and restarting from previous checkpoints after an error occurs.
Why not rely on error correcting memory? Super computers containing terabytes are built containing error correcting memory, but this does not make the problem go away, it ‘only’ reduces it by around two orders of magnitude. Builders of commodity processors don’t use much error correction circuitry because it would increase costs/power consumption/etc for an increased level of reliability that the commodity market is not interested in; vendors of high-end processors add significant amounts of error correction circuitry.
Most of the compiler research I am aware of involves soft errors occurring on the processor, and this topic is discussed below; there has been some work on assigning variables deemed to be critical to a subset of memory that is protected with error correcting hardware. Pointers to other compiler research involving memory soft errors welcome.
A commonly used technique for handling hardware faults is redundancy, usually redundant hardware (e.g., three processors performing the same calculating and a majority vote used to decide which of the outputs to accept). Software only approaches include the compiler generating two or more independent machine code sequences for each source code sequence whose computed values are compared at various check points and running multiple copies of a program in different threads and comparing outputs. The
Shoestring compiler (based on llvm) takes a lightweight approach to redundancy by not duplicating those code sequences that are less affected by register bit flips (e.g., the value obtained from a bitwise AND that extracts 8 bits from a 32-bit register is 75% less likely to deliver an incorrect result than an operation that depends on all 32 bits).
The reliability of single ‘thread’ generated code can be improved by optimizing register lifetimes for this purpose. A value is loaded into a register and sometime later it is used one or more times. A soft error corrupting register contents after the last use of the value it contains has no impact on program execution, the soft error has to occur between the load and last use of the value for it to possibly influence program output. One group of researchers modified a compiler (Trimaran) to order register usage such that the average interval between load and last usage was reduced by 10%, compared to the default behavior.
Developers don’t have to wait for compiler or hardware support, they can improve reliability by using algorithms that are robust in the presence of ‘faulty’ hardware. For instance, the traditional algorithms for two-process mutual exclusion are not fault-tolerant; a fault-tolerant mutual exclusion algorithm using  variables, where a single fault may occur in up to variables is available.
variables, where a single fault may occur in up to variables is available.
Program optimization given 1,000 datasets
A recent paper reminded me of a consequence of widespread availability of multi-processor systems I had failed to mention in a previous post on compiler writing in the next decade. The wide spread availability of systems containing large numbers of processors opens up opportunities for both end users of compilers and compiler writers.
Some compiler optimizations involve making decisions about what parts of a program will be executed more frequently than other parts; usually speeding up the frequently executed at the expense of slowing down the less frequently executed. The flow of control through a program is often effected by the input it has been given.
Traditionally optimization tuning has been done by feeding a small number of input datasets into a small number of programs, with the lazy using only the SPEC benchmarks and the more conscientious (or perhaps driven by one very important customer) using a few more acquired over time. A few years ago the iterative compiler tuning community started to address this lack of input benchmark datasets by creating 20 datasets for each of their benchmark programs.
Twenty datasets was certainly a step up from a few. Now one group (Evaluating Iterative Optimization Across 1000 Data Sets; written by a team of six people) has used 1,000 different input data sets to evaluate the runtime performance of a program; in fact they test 32 different programs each having their own 1,000 data sets. Oh, one fact they forgot to mention in the abstract was that each of these 32 programs was compiled with 300 different combinations of compiler options before being fed the 1,000 datasets (another post talks about the problem of selecting which optimizations to perform and the order in which to perform them); so each program is executed 300,000 times.
Standing back from this one could ask why optimizers have to be ‘pre-tuned’ using fixed datasets and programs. For any program the best optimization results are obtained by profiling it processing large amounts of real life data and then feeding this profile data back to a recompilation of the original source. The problem with this form of optimization is that most users are not willing to invest the time and effort needed to collect the profile data.
Some people might ask if 1,000 datasets is too many, I would ask if it is enough. Optimization often involves trade-offs and benchmark datasets need to provide enough information to compiler writers that they can reliably tune their products. The authors of the paper are still analyzing their data and I imagine that reducing redundancy in their dataset is one area they are looking at. One topic not covered in their first paper, which I hope they plan to address, is how program power consumption varies across the different datasets.
Where next with the large multi-processor systems compiler writers now have available to them? Well, 32 programs is not really enough to claim reasonable coverage of all program characteristics that compilers are likely to encounter. A benchmark containing 1,000 different programs is the obvious next step. One major hurdle, apart from the people time involved, is finding 1,000 programs that have usable datasets associated with them.
Recent Comments