Archive
Statistical techniques not needed to analyze software engineering data
One of the methods I used to try to work out what statistical techniques were likely to be useful to software developers, was to try to apply techniques that were useful in other areas. Of course, applying techniques requires the appropriate data to apply them to.
Extreme value statistics are used to spot patterns in rare events, e.g., frequency of rivers over spilling their banks and causing extensive flooding. I have tried and failed to find any data where Extreme value theory might be applicable. There probably is some such data, somewhere.
The fact that I have spent a lot of time looking for data and failed to find particular kinds of data, suggests that occurrences are rare. If data needing a particular kind of analysis technique is rare, there is no point including a discussion of the technique in a book aimed at providing general coverage of material.
I have spent some time looking for data drawn from a zero-inflated Poisson distribution. Readers are unlikely to have ever heard of this and might well ask why I would be interested in such an obscure distribution. Well, zero-truncated Poisson distributions crop up regularly (the Poisson distribution applies to count data that starts at zero, when count data starts at one the zeroes are said to be truncated and the Poisson distribution has to be offset to adjust for this). There is a certain symmetry to zero-truncated/inflated (although the mathematics involved is completely different), plus there is probably a sunk cost effect (i.e., I have spent time learning about them, I am going to find the data).
I spotted a plot in a paper investigating record data structure usage in Racket, that looked like it might be well fitted by a zero-inflated Poisson distribution. Tobias Pape kindly sent me the data (number of record data structures having a given size), which I then failed miserably to fit to any kind of Poisson related distribution; see plot below; data points along red line through the plus symbols (code+data):
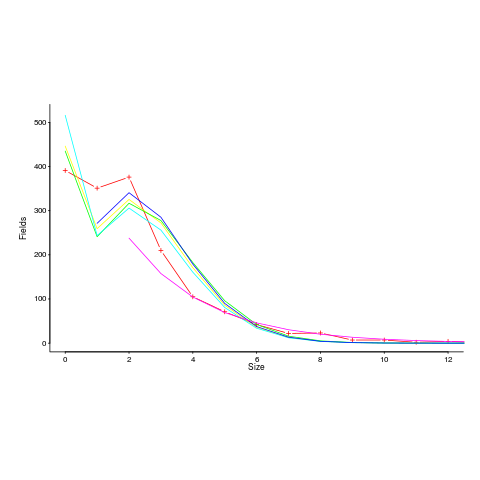
I can only imagine what the authors thought of my reason for wanting the data (I made data requests to a few other researchers for similar reasons; and again I failed to fit the desired distribution).
I had expected to make more use of time series analysis; but, it has just not been that applicable.
Machine learning is useful for publishing papers, but understanding what is going on is the subject of my book, not building black boxes to make predictions.
It is possible that researchers are not publishing work relating to data that requires statistical techniques I have not used, because they don’t know how to analyze the data or the data is too hard to collect. Inability to use the correct techniques to analyze data is rarely a reason for not publishing a paper. Data being too hard to collect is very believable, as-is the data rarely occurring in software engineering related work.
There are statistical tests I have intentionally ignored, the Mann–Whitney U test (aka, the Wilcoxon rank-sum test) and the t-test probably being the most well-known. These tests became obsolete once computers became generally available. If you are ever stuck on a desert island without a computer, these are the statistical tests you will have to use.
A signature for the “embeddedness” of source code and developers?
Patterns in the use of source code can tell us a lot about the people who wrote the code, the characteristics of the hardware it runs on and what the application is all about.
Often the pattern of usage needs a lot of work to understand and many remain completely baffling, but every now and again the forces driving a pattern leap off the page. One such pattern is visible in the plot below; data courtesy of Jacob Engblom and the cbook data is from my C book (assuming you know something about the nitty gritty of embedded software development). It shows the percentage of functions defined to have a given number of parameters:
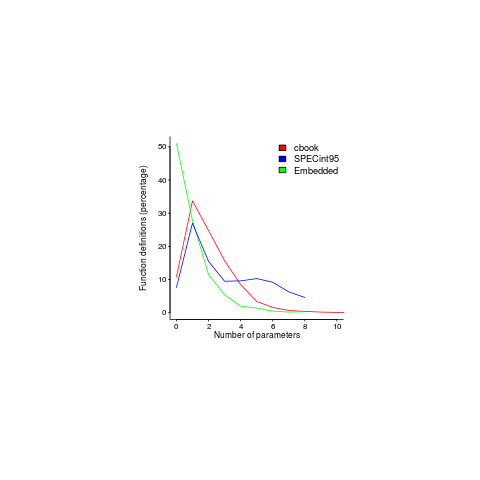
Embedded software has to run in very constrained environments. The hardware is often mass produced and saving a penny per device can add up to big savings, so the cheapest processor is chosen and populated with the smallest possible memory; developers have to work with what they are given. Power consumption may be down below one watt, so clock speeds are closer to 1 MHz than 1 GHz.
Parameter passing is a relatively expensive operation and there are major savings, relatively speaking, to be had by using global variables. Experienced embedded developers know this and this plot is telling us that they are acting on this knowledge.
The following are two ways of interpreting the embedded data (I cannot think of any others that make sense):
- the time/resource critical functions use globals rather than parameters and all the other functions are written more or less the same as in a non-embedded environment. In statistical terms this behavior is described by a zero-inflated model,
- there is pressure on the developer to reduce the number of parameters in all function definitions.
This data contains counts, so a Poisson distribution is the obvious candidate for our model.
My attempts to fit a zero-inflated model failed miserably (code+data). A basic Poisson distribution fitted everything reasonably well (let’s ignore that tiresome bump in the blue line); plus signs are the predictions made from each fitted model.
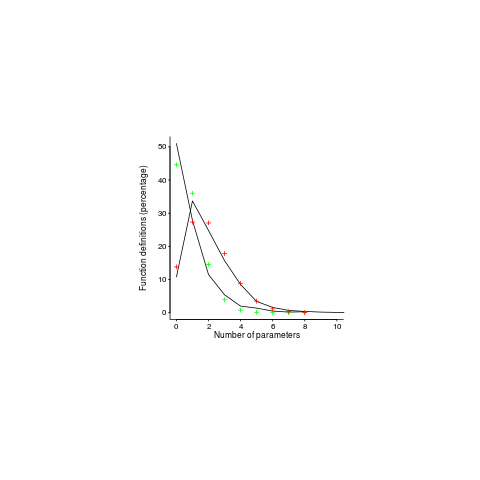
For desktop developers, the distribution of function definitions having a given number of parameters follows a Poisson distribution with a λ of 2, while for embedded developers λ is 0.8.
What about values of λ between 0.8 and 2; perhaps the λ of a project’s, or developer’s, code parameter count can be used as an indicator of ’embeddedness’?
What is needed to parameter count data from a range of 4-bit, 8-bit and 16-bit systems and measurements of developers who have been working in the field for, say, 4, 8, 16 years. Please let me know.
The data is from a Masters thesis written in 1999, is it still relevant today? Have modern companies become kinder to developers and stopped making their life so hard by saving pennies when building mass produced products; are modern low-power devices being used so values can be passed via parameters rather than via globals, or are they being used for applications where even less power is available?
One difference from 20 years ago is that embedded devices are more mainstream, easier to get hold of and sales opportunities abound. This availability creates an environment where developers with a desktop development mentality (which developers new to embedded always seem to have had) don’t get to learn about the overheads of parameter passing.
Have compilers gotten better at reducing the function parameter overhead? The most obvious optimization is inlining a function at the point of call. If the function is only called once, this works fine, with multiple calls the generated code can get larger (one of the things we are trying to avoid). I don’t have any reliable data on modern compiler performance int his area, but then I have not looked hard. Pointers to benchmarks welcome.
Does embedded software have any other signatures that differentiate it from desktop software (other than the obvious one of specifying address in definitions of global variables)? Suggestions welcome.
Recent Comments