Archive
Best tool for measuring lots of source code
Human written source code contains various common usage patterns. This blog has analysed a variety of these patterns, and in a few cases built models of processes that replicate these patterns. The data for this analysis has primarily comes from programs written in C and Java, because these are the languages that researchers most often study (tool availability and herd mentality).
Do these common usage patterns occur in other languages, or at least other C/Java like languages? I think so, and have set out to collect the necessary data. Obtaining this data requires large quantities of code written in many languages, and the ability to analyse code written in these languages.
GitHub contains huge quantities of code. There are two freely available source code analysis tools supporting many languages: Opengrep (the Open source version of semgrep) and CodeQL.
CodeQL’s method of operation had previously put me off trying it. The method is a two stage process: First a database of information is created by extracting information during a project’s build process (e.g., running existing makefiles and host compilers), followed by querying this database using a declarative language (think minimalist SQL with lots of built-in functions). This approach has the huge advantage of not having to worry about handling compiler dialects/options, however, I’m an ingrained user of tools that process individual files.
From the research perspective, CodeQL has a major feature that is not available with other tools. GitHub, who now owns CodeQL, host thousands of project databases and GitHub Actions allows third-parties to scan up to 1,000 databases of the most popular projects. Access to existing CodeQL databases removes the need to download repo/build project/store database locally.
CodeQL, like other static analysis tools, was designed to find issues/problems in code, and so might not support the kind of functionality I needed to extract source code measurements. The best way to find out if the data of interest could be extracted is to try and do it.
In the best developer tradition, I downloaded a prebuilt release (available for Linux, Windows and Mac; called CodeQL Bundles), skimmed the documentation, ran a simple QL script and spent an hour or two trying to figure out why I was getting Java runtime errors, e.g., “no String-argument constructor/factory method to deserialize from String value“.
Progress would have been faster if I had used Visual Studio Code, available free from the owners of GitHub, rather than the command line. The documentation is not command line oriented. Visual Studio handles details like creating a qlpack.yml file (whose necessary existence I eventually found out about). Also, the harmless looking metadata appearing in comments is necessary and had better match the output parameters of the query. How hard is it to warn that a file could not be found, or that metadata is missing?
The code databases are queried using the declarative language QL, which is a kind of minimal SQL (with the select appearing last, rather than first). The import statement specifies the language, or rather the name of a library module.
The imported library contains classes for each language construct (e.g., BlockStmt, Function, ArrayExpr, etc). In the query below, the line “from LocalScopeVariable lv” extracts all local scope variables, which can subsequently be referred to via the name lv. The where line lists conditions that must be met (in this example, not be a parameter and not be accessed; testing for unused variables). The select line invokes methods that return various kinds of information about the class, e.g., the name of the variable, and location within the source.
/** * @id compound-stmt * @kind problem * @problem.severity warning */ import cpp from LocalScopeVariable lv where not lv instanceof Parameter and not exists(lv.getAnAccess()) select "", ""+lv.getName()+ ","+lv.getLocation().getStartLine()+ ","+lv.getLocation().getEndLine()+ ","+lv.getEnclosingFunction()+","+bs.getFile() |
The output generated is driven by the select, whose number/kind of arguments must match that specified by the metadata.
Developers can write and call functions, such as this one:
predicate header_suffix(string fstr) { fstr = "h" or fstr = "H" or fstr = "hpp" } |
The QL language is a declarative logical query language with roots in Datalog (subset of Prolog). The claim that it is an object-oriented language is technically correct, in that it groups functions into things called classes and supports various constructs usually found in object-oriented languages. The language has the feel of an academic project that happened to be used in a tool that was in the right place at the right time. Using host compilers to enable the tool to support many languages must have been very attractive to GitHub.
Coding in a declarative logic language requires a major mindset change. There are no loops, if statements or assignments. The query is one, potentially very long and complicated, predicate. A mindset change is necessary, but not sufficient, some fluency with the library of functions available is also needed. For instance, the isSideEffectFree predicate is true/false, but does not return a value (so there is nothing to print). I wanted to output 0/1, depending on whether a function was side effect free or not. When asked, all the LLMs questioned insisted that QL supported if-statements and assignment, just like other languages. After lots of dead-ends, an LLM claimed that “CodeQL automatically treats boolean expressions in count as 1/0″, and a test run showed this to be the case:
count(int dummy | dummy = 1 and func.isSideEffectFree() | dummy) |
The QL scripts needed to extract all the data of immediate interest to me were easily implemented. Looking at existing scripts has given me some ideas for more patterns I might measure. CodeQL currently supports 10 languages, and their classes appear to be slightly different (my initial focus is C, C++, Java and Python).
Visual Studio Code is required to run multi-repository variant analysis, i.e., scan up to 1,000 project databases on GitHub. It was after installing the CodeQL extension that I discovered how much smoother the process is within this IDE, compared to the command line (and off course the output is slightly different). There may be alternatives to Visual Studio, but I’m sticking with what the official documentation says.
Stepping back, is CodeQL a useful tool?
For me it is currently very useful, because of the large number of project databases. Some practice is needed to achieve some fluency in the use of a declarative logic language, not a major hurdle.
The need to run queries against a project database may be a major inconvenience for some developers, depending on working practices. Those practicing continuous integration should be ok.
semgrep: the future of static analysis tools
When searching for a pattern that might be present in source code contained in multiple files, what is the best tool to use?
The obvious answer is grep, and grep is great for character-based pattern searches. But patterns that are token based, or include information on language semantics, fall outside grep‘s model of pattern recognition (which does not stop people trying to cobble something together, perhaps with the help of complicated sed scripts).
Those searching source code written in C have the luxury of being able to use Coccinelle, an industrial strength C language aware pattern matching tool. It is widely used by the Linux kernel maintainers and people researching complicated source code patterns.
Over the 15+ years that Coccinelle has been available, there has been a lot of talk about supporting other languages, but nothing ever materialized.
About six months ago, I noticed semgrep and thought it interesting enough to add to my list of tool bookmarks. Then, a few days ago, I read a brief blog post that was interesting enough for me to check out other posts at that site, and this one by Yoann Padioleau really caught my attention. Yoann worked on Coccinelle, and we had an interesting email exchange some 13-years ago, when I was analyzing if-statement usage, and had subsequently worked on various static analysis tools, and was now working on semgrep. Most static analysis tools are created by somebody spending a year or so working on the implementation, making all the usual mistakes, before abandoning it to go off and do other things. High quality tools come from people with experience, who have invested lots of time learning their trade.
The documentation contains lots of examples, and working on the assumption that things would be a lot like using Coccinelle, I jumped straight in.
The pattern I choose to search for, using semgrep, involved counting the number of clauses contained in Python if-statement conditionals, e.g., the condition in: if a==1 and b==2: contains two clauses (i.e., a==1, b==2). My interest in this usage comes from ideas about if-statement nesting depth and clause complexity. The intended use case of semgrep is security researchers checking for vulnerabilities in code, but I’m sure those developing it are happy for source code researchers to use it.
As always, I first tried building the source on the Github repo, (note: the Makefile expects a git clone install, not an unzipped directory), but got fed up with having to incrementally discover and install lots of dependencies (like Coccinelle, the code is written on OCaml {93k+ lines} and Python {13k+ lines}). I joined the unwashed masses and used pip install.
The pattern rules have a yaml structure, specifying the rule name, language(s), message to output when a match is found, and the pattern to search for.
After sorting out various finger problems, writing C rather than Python, and misunderstanding the semgrep output (some of which feels like internal developer output, rather than tool user developer output), I had a set of working patterns.
The following two patterns match if-statements containing a single clause (if.subexpr-1), and two clauses (if.subexpr-2). The option commutative_boolop is set to true to allow the matching process to treat Python’s or/and as commutative, which they are not, but it reduces the number of rules that need to be written to handle all the cases when ordering of these operators is not relevant (rules+test).
rules: - id: if.subexpr-1 languages: [python] message: if-cond1 patterns: - pattern: | if $COND1: # we found an if statement $BODY - pattern-not: | if $COND2 or $COND3: # must not contain more than one condition $BODY - pattern-not: | if $COND2 and $COND3: $BODY severity: INFO - id: if.subexpr-2 languages: [python] options: commutative_boolop: true # Reduce combinatorial explosion of rules message: if-cond2 pattern-either: - patterns: - pattern: | if $COND1 or $COND2: # if statement containing two conditions $BODY - pattern-not: | if $COND3 or $COND4 or $COND5: # must not contain more than two conditions $BODY - pattern-not: | if $COND3 or $COND4 and $COND5: $BODY - patterns: - pattern: | if $COND1 and $COND2: $BODY - pattern-not: | if $COND3 and $COND4 and $COND5: $BODY - pattern-not: | if $COND3 and $COND4 or $COND5: $BODY severity: INFO |
The rules would be simpler if it were possible for a pattern to not be applied to code that earlier matched another pattern (in my example, one containing more clauses). This functionality is supported by Coccinelle, and I’m sure it will eventually appear in semgrep.
This tool has lots of rough edges, and is still rapidly evolving, I’m using version 0.82, released four days ago. What’s exciting is the support for multiple languages (ten are listed, with experimental support for twelve more, and three in beta). Roughly what happens is that source code is mapped to an abstract syntax tree that is common to all supported languages, which is then pattern matched. Supporting a new language involves writing code to perform the mapping to this common AST.
It’s not too difficult to map different languages to a common AST that contains just tokens, e.g., identifiers and their spelling, literals and their value, and keywords. Many languages use the same operator precedence and associativity as C, plus their own extras, and they tend to share the same kinds of statements; however, declarations can be very diverse, which makes life difficult for supporting a generic AST.
An awful lot of useful things can be done with a tool that is aware of expression/statement syntax and matches at the token level. More refined semantic information (e.g., a variable’s type) can be added in later versions. The extent to which an investment is made to support the various subtleties of a particular language will depend on its economic importance to those involved in supporting semgrep (Return to Corp is a VC backed company).
Outside of a few languages that have established tools doing deep semantic analysis (i.e., C and C++), semgrep has the potential to become the go-to static analysis tool for source code. It will benefit from the network effects of contributions from lots of people each working in one or more languages, taking their semgrep skills and rules from one project to another (with source code language ceasing to be a major issue). Developers using niche languages with poor or no static analysis tool support will add semgrep support for their language because it will be the lowest cost path to accessing an industrial strength tool.
How are the VC backers going to make money from funding the semgrep team? The traditional financial exit for static analysis companies is selling to a much larger company. Why would a large company buy them, when they could just fork the code (other company sales have involved closed-source tools)? Perhaps those involved think they can make money by selling services (assuming semgrep becomes the go-to tool). I have a terrible track record for making business predictions, so I will stick to the technical stuff.
Update
Parts of the semgrep source have changed from an Open source license to a commercial one.
Opengrep is an Open source fork of semgrep.
An experiment involving matching regular expressions
Recommendations for/against particular programming constructs have one thing in common: there is no evidence backing up any of the recommendations. Running experiments to measure the impact of particular language features on developer performance is not something that researchers do (there have been a handful of experiments looking at the impact of strong typing on developer performance; the effect measured was tiny).
In February I discovered two groups researching regular expressions. In the first post on duplicate regexs, I promised to say something about the second group. This post discusses an experiment comparing developer comprehension of various regular expressions; the paper is: Exploring Regular Expression Comprehension.
The experiment involved 180 workers on Mechanical Turk (to be accepted, workers had to correctly answer four or five questions about regular expressions). Workers/subjects performed two different tasks, matching and composition.
- In the matching task workers saw a regex and a list of five strings, and had to specify whether the regex matched (or not) each string (there was also an unsure response).
- In the composition task workers saw a regular expression, and had to create a string matched by this regex. Each worker saw 10 different regexs, which were randomly drawn from a set of 60 regexs (which had been created to be representative of various regex characteristics). I have not analysed this data yet.
What were the results?
For the matching task: given each of the pairs of regexs below, which one (of each pair) would you say workers were most likely to get correct?
R1 R2 1. tri[a-f]3 tri[abcdef]3 2. no[w-z]5 no[wxyz]5 3. no[w-z]5 no(w|x|y|z)5 4. [ˆ0-9] [\D] |
The percentages correct for (1) were essentially the same, at 94.0 and 93.2 respectively. The percentages for (2) were 93.3 and 87.2, which is odd given that the regex is essentially the same as (1). Is this amount of variability in subject response to be expected? Is the difference caused by letters being much less common in text, so people have had less practice using them (sounds a bit far-fetched, but its all I could think of). The percentages for (3) are virtually identical, at 93.3 and 93.7.
The percentages for (4) were 58 and 73.3, which surprised me. But then I have been using regexs since before \D support was generally available. The MTurk generation have it easy not having to use the ‘hard stuff’ 😉
See Table III in the paper for more results.
This matching data might be analysed using Item Response theory, which can take into account differences in question difficulty and worker/subject ability. The plot below looks complicated, but only because there are so many lines. Each numbered colored line is a different regex, worker ability is on the x-axis (greater ability on the right), and the y-axis is the probability of giving a correct answer (code+data; thanks to Peipei Wang for fixing the bugs in my code):
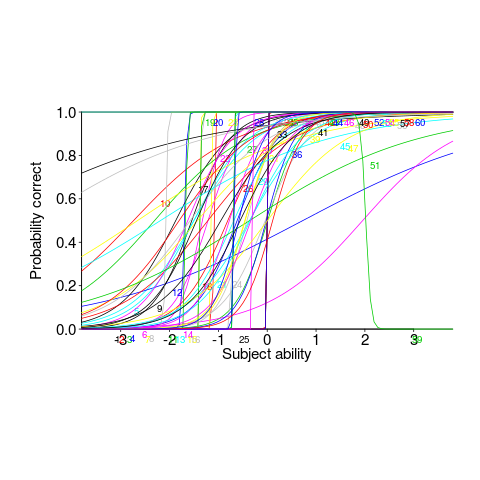
Yes, for question 51 the probability of a correct answer decreases with worker ability. Heads are being scratched about this.
There might be some patterns buried in amongst all those lines, e.g., particular kinds of patterns require a given level of ability to handle, or correct response to some patterns varying over the whole range of abilities. These are research questions, and this is a blog article: answers in the comments 🙂
This is the first experiment of its kind, so it is bound to throw up more questions than answers. Are more incorrect responses given for longer regexs, particularly if they cannot be completely held in short-term memory? It is convenient for the author to use a short-hand for a range of characters (e.g., a-f), and I was expecting a difference in performance when all the letters were enumerated (e.g., abcdef); I had theories for either one being less error-prone (I obviously need to get out more).
Patterns of regular expression usage: duplicate regexs
Regular expressions are widely used, but until recently they were rarely studied empirically (i.e., just theory research).
This week I discovered two groups studying regular expression usage in source code. The VTSBULeeLab has various papers analysing 500K distinct regular expressions, from programs written in eight languages and StackOverflow; Carl Chapman and Peipei Wang have been looking at testing of regular expressions, and also ran an interesting experiment (I will write about this when I have decoded the data).
Regular expressions are interesting, in that their use is likely to be purely driven by an application requirement; the use of an integer literals may be driven by internal housekeeping requirements. The number of times the same regular expression appears in source code provides an insight (I claim) into the number of times different programs are having to solve the same application problem.
The data made available by the VTSBULeeLab group provides lots of information about each distinct regular expression, but not a count of occurrences in source. My email request for count data received a reply from James Davis within the hour 🙂
The plot below (code+data; crates.io has not been included because the number of regexs extracted is much smaller than the other repos) shows the number of unique patterns (y-axis) against the number of identical occurrences of each unique pattern (x-axis), e.g., far left shows number of distinct patterns that occurred once, then the number of distinct patterns that each occur twice, etc; colors show the repositories (language) from which the source was obtained (to extract the regexs), and lines are fitted regression models of the form:  , where:
, where:  is driven by the total amount of source processed and the frequency of occurrence of regexs in source, and
is driven by the total amount of source processed and the frequency of occurrence of regexs in source, and  is the rate at which duplicates occur.
is the rate at which duplicates occur.
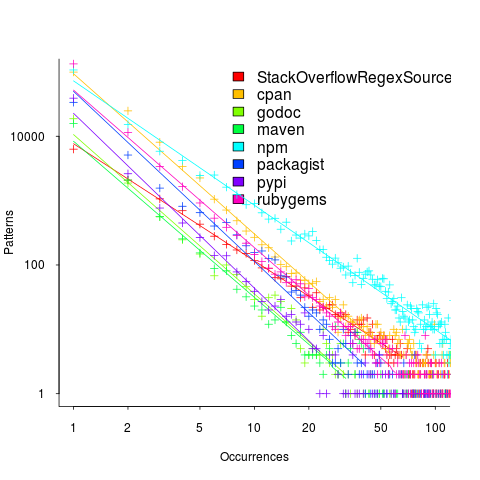
So most patterns occur once, and a few patterns occur lots of times (there is a long tail off to the unplotted right).
The following table shows values of for the various repositories (languages):
StackOverflow cpan godoc maven npm packagist pypi rubygems
-1.8 -2.5 -2.5 -2.4 -1.9 -2.6 -2.7 -2.4 |
The lower (i.e., closer to zero) the value of , the more often the same regex will appear.
The values are in the region of -2.5, with two exceptions; why might StackOverflow and npm be different? I can imagine lots of duplicates on StackOverflow, but npm (I’m not really familiar with this package ecosystem).
I am pleased to see such good regression fits, and close power law exponents (I would have been happy with an exponential fit, or any other equation; I am interested in a consistent pattern across languages, not the pattern itself).
Some of the code is likely to be cloned, i.e., cut-and-pasted from a function in another package/program. Copy rates as high as 70% have been found. In this case, I don’t think cloned code matters. If a particular regex is needed, what difference does it make whether the code was cloned or written from scratch?
If the same regex appears in source because of the same application requirement, the number of reuses should be correlated across languages (unless different languages are being used to solve different kinds of problems). The plot below shows the correlation between number of occurrences of distinct regexs, for each pair of languages (or rather repos for particular languages; top left is StackOverflow).

Why is there a mix of strong and weakly correlated pairs? Is it because similar application problems tend to be solved using different languages? Or perhaps there are different habits for cut-and-pasted source for developers using different repositories (which will cause some patterns to occur more often, but not others, and have an impact on correlation but not the regression fit).
There are a lot of other interesting things that can be done with this data, when connected to the results of the analysis of distinct regexs, but these look like hard work, and I have a book to finish.
Matching context sensitive rules and generating output using regular expressions
I have previously written about generating words that sound like an input word. My interest in reimplementing this project from many years ago was fueled by a desire to find out exactly how flexible modern regular expression libraries are (the original used a bespoke tool). I had a set of regular expressions describing a mapping from one or more letters to one or more phonemes and I wanted to use someone else’s library to do all the heavy duty matching.
The following lists some of the mapping rules. The letters between [] are the ones that are ‘consumed’ by the match and any letters/characters either side are the context required for the rule to match. The characters between // are phonemes represented using the Arpabet phonetic transcription.
@[ew]=/UW/ [giv]=/G IH V/ [g]i^=/G/ [ge]t=/G EH/ su[gges]=/G JH EH S/ [gg]=/G/ b$[g]=/G/ [g]+=/JH/ # space - start of word # $ - one or more vowels # ! - two or more vowels # + - one front vowel # : - zero or more consonants # ^ - one consonant # ; - one or more consonants # . - one voiced consonant # @ - one special consonant # & - one sibilant # % - one suffix |
After some searching I settled on using the PCRE (Perl Compatible Regular Expressions) library, which contains more functionality than you can shake a stick at.
My plan was to translate each of the 300+ rules, using awk, into a regular expression, concatenate all of these together using alternation and let PCRE handle all of the matching details; which is what I did and it worked. Along the way a few problems had to be solved…
How can the appropriate phoneme(s) be generated when a rule matches? The solution is to use what PCRE calls callouts. During matching if the sequence (?C77) is encountered in the pattern a developer defined function (set up prior to calling pcre_execute) is called with information about the current state of the match. In this example the information would include the value 77 (values between 0 and 255 are supported). By embedding a unique number in the subpattern for each rule (and writing the appropriate phoneme sequence out to a configuration file that is read on program startup) it is possible to generate the appropriate output (because there are more than 255 rules a pair of callouts are needed to specify larger values).
How can the left/right letter context be handled? Most regular expression matching works by consuming all of the matched characters, making them unavailable for matching by other parts of the regular expression during that match. PCRE supports what it calls left and right assertions, which require a pattern to match but don’t consume the matched characters, leaving them to be matched by some other part of the pattern. So the rule [ge]t is mapped to the regular expression ge(?=t) which consumes a ge followed by a t but leaves the t for matching by another part of the pattern.
One problem occurs for backward assertions, which are restricted to matching the same number of characters for all alternatives of the pattern. For example the backward assertion (?<=(a|ab)e) is not supported because one path through the pattern is two characters long while the other is three characters long. The rule @[ew] cannot be matched using a backward assertion because @ includes letter sequences of different length (e.g., N, J, TH). The solution is to use a callout to perform a special left context match (specified by the callout number) which works by reversing the word being matched and the left context pattern and performing a forward (rather than backward) match.
The final pattern is over 10,000 characters long and looks something like (notice that everything is enclosed in () and terminated by a + to force the longest possible match, i.e., the complete word:
(((a(?=$)(?C51)))|((?<=^)(are(?=$)(?C52)))| ... |(z(?C106)(?C55)))+ |
Now we need a method of using the letter to phoneme rules to map phonemes to letters. In some cases a phoneme sequence can be mapped to multiple letter sequences and I wanted to generate all of the possible letter sequences (e.g., cat -> K AE T -> cat, kat, qat). PCRE does support a matching function capable of returning all possible matches. However this function does not support some of the functionality required, so I decided to 'force' the single match function to generate all possible sequences by using a callout to make it unconditionally fail as the last operation of every otherwise successful match, causing the matching process to backtrack and try to find an alternative match. Not the most efficient of solutions but it saved me having to learn a lot more about the functionality supported by PCRE.
For a given sequence of phonemes it is simple enough to match it using a regular expression created from the existing rules. However, any match also needs to meet any left/right letter context requirements. Because we are generating letters left to right we have a left context that can be matched, but no right context.
The left context is matched by applying the technique used for variable length left contexts, described above, i.e., the letters generated so far are reversed and these are matched using a reversed left context pattern.
An efficient solution to matching right context would be very fiddly to implement. I took the simple approach of ignoring the right letter context until the complete phoneme sequence had been matched; the generated letter sequence out of this matching process is feed as input to the letter-to-phoneme function and the returned phoneme sequence compared against the original generating phoneme sequence. If the two phoneme sequences are identical the generated letter sequence is included in the final set of returned letter sequences. Not very computer efficient, but an efficient use of my time.
I could not resist including some optimzations. For instance, if a letter sequence only matches at the start or end of a word then the corresponding phonemes can only match at the start/end of the sequence.
I have skipped some of the minor details, which you can read about in the source of the tool.
I would be interested to hear about the libraries/tools used by readers with experience matching patterns of this complexity.
Semantic pattern matching (Coccinelle)
I have just discovered Coccinelle a tool that claims to fill a remarkable narrow niche (providing semantic patch functionality; I have no idea how the name is pronounced) but appears to have a lot of other uses. The functionality required of a semantic patch is the ability to write source code patterns and a set of transformation rules that convert the input source into the desired output. What is so interesting about Coccinelle is its pattern matching ability and the ability to output what appears to be unpreprocessed source (it has to be told the usual compile time stuff about include directory paths and macros defined via the command line; it would be unfair of me to complain that it needs to build a symbol table).
Creating a pattern requires defining identifiers to have various properties (eg, an expression in the following example) followed by various snippets of code that specify the pattern to match (in the following <… …> represents a bracketed (in the C compound statement sense) don’t care sequence of code and the lines starting with +/- have the usual patch meaning (ie, add/delete line)). The tool builds an abstract syntax tree so urb is treated as a complete expression that needs to be mapped over to the added line).
@@ expression lock, flags; expression urb; @@ spin_lock_irqsave(lock, flags); <... - usb_submit_urb(urb) + usb_submit_urb(urb, GFP_ATOMIC) ...> spin_unlock_irqrestore(lock, flags); |
Coccinelle comes with a bunch of predefined equivalence relations (they are called isomophisms) so that constructs such as if (x), if (x != NULL) and if (NULL != x) are known to be equivalent, which reduces the combinatorial explosion that often occurs when writing patterns that can handle real-world code.
It is written in OCaml (I guess there had to be some fly in the ointment) and so presumably borrows a lot from CIL, perhaps in this case a version number of 0.1.3 is not as bad as it might sound.
My main interest is in counting occurrences of various kinds of patterns in source code. A short-term hack is to map the sought-for pattern to some unique character sequence and pipe the output through grep and wc. There does not seem to be any option to output a count of the matched patterns … yet 🙂
Recent Comments