Archive
Unused function parameters
I have started redoing the source code measurements that appear in my C book, this time using a lot more source, upgraded versions of existing tools, plus some new tools such as Coccinelle and R. The intent is to make the code and data available in a form that is easy for others to use (I am hoping that one or more people will measure the same constructs in other languages) and to make some attempt at teasing out relationships in the data (previously the data was simply plotted with little or no explanation).
While it might be possible to write a paper on every language construct measured, I don’t have the time to do the work. Instead, I will use this blog to make a note of the interesting things that crop up during the analysis of each construct I measure.
First up are unused function parameters (code and data), which at around 11% of all parameters are slightly more common than unused local variables (Figure 190.1). In the following plot black circles are the total number of functions having a given number of parameters, red circles a given number of unused parameters, blue line a linear regression fit of the red circles, and the green line is derived from black circle values using a formula I concocted to fit the data and have no theoretical justification for it.
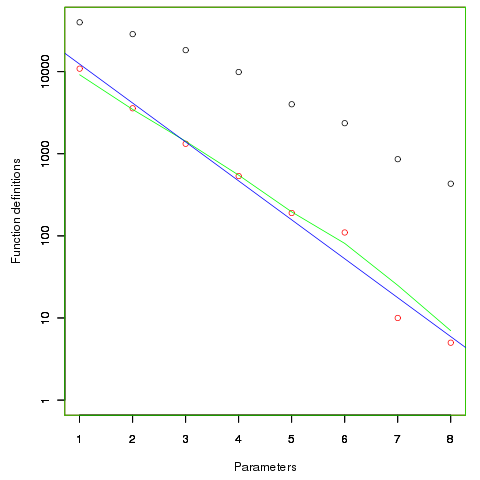
The number of functions containing a given number of unused parameters drops by around a factor of three for each additional unused parameter. Why is this? The formula I came up with for estimating the number of functions containing  unused parameters is:
unused parameters is:  , where
, where  is the total number of function definitions containing
is the total number of function definitions containing  parameters.
parameters.
Which parameter, for those functions defined with more than one, is most likely to be unused? My thinking was that the first parameter might either hold the most basic information (and so rarely be unused) or hold information likely to be superseded when new parameters are added (and so commonly be unused), either way I considered later parameters as often being put there for later use (and therefore more likely to be unused). The following plot is for eight programs plus the sum of them all; for all functions defined with between one and eight parameters, the percentage of times the  ‘th parameter is unused is given. The source measured contained 104,493 function definitions containing more than one parameter with 16,643 of these functions having one or more unused parameter, there were a total of 235,512 parameters with 25,886 parameters being unused.
‘th parameter is unused is given. The source measured contained 104,493 function definitions containing more than one parameter with 16,643 of these functions having one or more unused parameter, there were a total of 235,512 parameters with 25,886 parameters being unused.
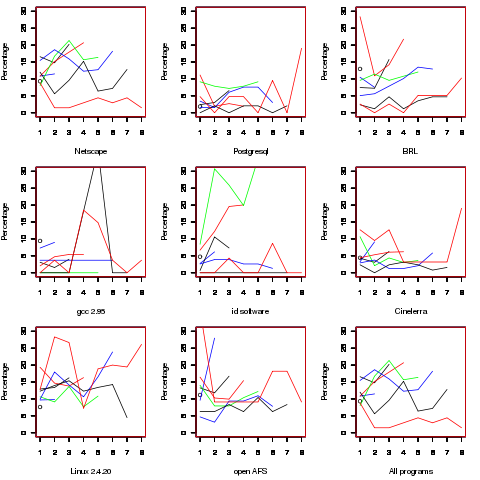
There is no obvious pattern to which parameters are likely to be unused, although a lot of the time the last parameter is more likely to be unused than the penultimate one.
Looking through the raw data I noticed that there seemed to be some clustering of names of unused parameters, in particular if the ‘th parameter was unused in two adjacent ‘unused parameter’ functions they often had the same name. The following plot is for all measured source and gives the percentage of same name occurrences; the matching process analyses function definitions in the order they occur within a source file and having found one unused parameter its name is compared against the corresponding parameter in the next function definition with the same number of parameters and having an unused parameter at the same position.
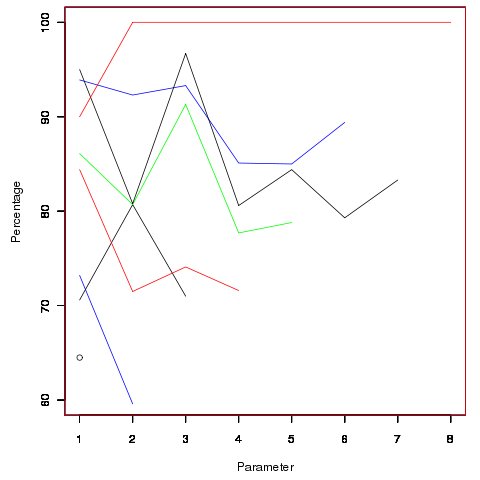
Before getting too excited about this pattern, we should ask if something similar exists for the used parameters. When I get around to redoing the general parameter measurements, I will look into this question. The numbers of occurrences for functions containing eight parameters is close to minimal.
The functions containing these same-name unused parameters appear to also have related function names. Is this a case of related function being grouped together, often sharing parameter names, and when one of them has an unused parameter the corresponding parameter in the others is also unused?
Is there a correlation between number of parameters and number of statements, are functions containing lots of statements less likely to have unused parameters? What effect does software evolution have (most of this kind of research measures executable code, not variable definitions)?
Recent Comments