Archive
Whole-program optimization: there’s gold in them hills
Information is the life-blood of compiler optimization and compiler writers are always saying “If only this-or-that were known, we could do this optimization.”
Burrowing down the knowing this-or-that rabbit-hole leads to requiring that code generation be delayed until link-time, because it is only at link-time that all the necessary information is available.
Whole program optimization, as it is known, has been a reality in the major desktop compilers for several years, in part because computers having 64G+ of memory have become generally available (compiler optimization has always been limited by the amount of memory available in developer computers). By reality, I mean compilers support whole-program-optimization flags and do some optimizations that require holding a representation of the entire program in memory (even Microsoft, not a company known for leading edge compiler products {although they have leading edge compiler people in their research group} supports an option having this name).
It is still early days for optimizations that are “whole-program”, rather like the early days of code optimization (when things like loop unrolling were leading edge and even constant folding was not common).
An annoying developer characteristic is writing code that calls a function every five statements, on average. Calling a function means that all those potentially reusable values that have been loaded into registers, before the call, cannot be safely used after the call (figuring out whether it is worth saving/restoring around the call is hard; yes developers, it’s all your fault that us compiler writers have such a tough job :-P).
Solutions to the function call problem include inlining and flow-analysis to figure out the consequences of the call. However, the called function calls other functions, which in-turn burrow further down the rabbit hole.
With whole-program optimization, all the code is available for analysis; given enough memory and processor time, lots of useful information can be figured out. Most functions are only called once, so there are lots of savings to be had from using known parameter values (many are numeric literals) to figure out whether an if-statement is necessary (i.e., is dead code) and how many times loops iterate.
More fully applying known techniques is the obvious easy use-case for whole-program optimization, but the savings probably won’t be that big. What about new techniques that previously could not even be attempted?
For instance, walking data structures until some condition is met is a common operation. Loading the field/member being tested and the next/prev field, results in one or more cache lines being filled (on the assumption that values adjacent in storage are likely to be accessed in the immediate future). However, data structures often contain many fields, only a few of which need to be accessed during the search process, when the next value needed is in another instance of the struct/record/class it is unlikely to already be available in the loaded cache line. One useful optimization is to split the data structure into two structures, one holding the fields accessed during the iterative search and the other holding everything else. This data-remapping means that cache lines are more likely to contain the next value accessed approaches increases the likelihood that cache lines will hold values needed in the near future; the compiler looks after the details. Performance gains of 27% have been reported
One study of C++ found that on average 12% of members were dead, i.e., never accessed in the code. Removing these saved 4.4% of storage, but again the potential performance gain comes from improve the cache hit ratio.
The row/column storage layout of arrays is not cache friendly, using Morton-order layout can have a big performance impact.
There are really really big savings to be had by providing compilers with a means of controlling the processor’s caches, e.g., instructions to load and flush cache lines. At the moment researchers are limited to simulations show that substantial power savings+some performance gain are possible.
Go forth and think “whole-program”.
Happy 30th birthday to GCC
Thirty years ago today Richard Stallman announced the availability of a beta version of gcc on the mod.compilers newsgroup.
Everybody and his dog was writing C compilers in the late 1980s and early 1990s (a C compiler validation suite vendor once told me they had sold over 150 copies; a compiler vendor has to be serious to fork out around $10,000 for a validation suite). Did gcc become the dominant open source because one compiler would inevitably become dominant, or was there some collection of factors that gave gcc a significant advantage?
I think gcc’s market dominance was driven by two environmental factors, with some help from a technical compiler implementation decision.
The technical implementation decision was the use of RTL as the optimization+code generation strategy. Jack Davidson’s 1981 PhD thesis (and much later the LCC book) describe the gory details. The code generators for nearly every other C compiler was closely tied to the machine being targeted (because the implementers were focused on getting a job done, not producing a portable compiler system). Had they been so inclined Davidson and Christopher Fraser could have been the authors of the dominant C compiler.
The first environment factor was the creation of a support ecosystem around gcc. The glue that nourished this ecosystem was the money made writing code generators for the never ending supply of new cpus that companies were creating (that needed a C compiler). In the beginning Cygnus Solutions were the face of gcc+tools; Michael Tiemann, a bright affable young guy, once told me that he could not figure out why companies were throwing money at them and that perhaps it was because he was so tall. Richard Stallman was not the easiest person to get along with and was probably somebody you would try to avoid meeting (I don’t know if he has mellowed). If Cygnus had gone with a different compiler, they had created 175 host/target combinations by 1999, gcc would be as well-known today as Hurd.
Yes, people writing Masters and PhD thesis were using gcc as the scaffolding for their fancy new optimization techniques (e.g., here, here and here), but this work essentially played the role of an R&D group trying to figure out where effort ought to be invested writing production code.
Sun’s decision to unbundle the development environment (i.e., stop shipping a C compiler with every system) caused some developers to switch to another compiler, some choosing gcc.
The second environment factor was the huge leap in available memory on developer machines in the 1990s. Compiler vendors cannot ship compilers that do fancy optimization if developers don’t have computers with enough memory to hold the optimization information (many, many megabytes). Until developer machines contained lots of memory, a one-man band could build a compiler producing code that was essentially as good as everybody else. An open source market leader could not emerge until the man+dog compilers could be clearly seen to be inferior.
During the 1990s the amount of memory likely to be available in developers’ computers grew dramatically, allowing gcc to support more and more optimizations (donated by a myriad of people targeting some aspect of code generation that they found interesting). Code generation improved dramatically and man+dog compilers became obviously second/third rate.
Would things be different today if Linus Torvalds’ had not selected gcc? If Linus had chosen a compiler licensed under a more liberal license than copyleft, things might have turned out very differently. LLVM started life in 2003 and one of my predictions for 2009 was its demise in the next few years; I failed to see the importance of licensing to Apple (who essentially funded its development).
Eventually, success.
With success came new existential threats, in particular death by a thousand forks.
A serious fork occurred in 1997. Stallman was clogging up the works; fortunately he saw the writing on the wall and in 1999 stepped aside.
Money is what holds together the major development teams supporting gcc and llvm. What happens when customers wanting support for new back-ends dries up, what happens when major companies stop funding development? Do we start seeing adverts during compilation? Chris Lattner, the driving force behind llvm recently moved to Tesla; will it turn out that his continuing management was as integral to the continuing success of llvm as getting rid of Stallman was to the continuing success of gcc?
Will a single mainline version of gcc still be the dominant compiler in another 30 years time?
Time will tell.
Impact of compiler optimization level on recovery from a hardware error
I have previously written about cosmic-ray induced faults in cpus and some of the compiler research being done to recover from such hardware faults. If your program is executing in an environment where radiation may cause hardware bit-flips to occur and you don’t have access to a research compiler providing some level of recovery, is it better to compile with high or low levels of optimization?
Short answer: Using gcc with optimization options O2 or O3 reduces the probability that a bit-flip will change the external behavior of a program, compared to option O0.
The longer answer is below as another draft section from my book Empirical software engineering with R book. As always comments welcome.
Software masking of hardware faults
Like all hardware cpus are subject to intermittent faults, these faults may flip the value of a bit in a program visible register, a bit in an executable instruction or some internal processor state (causes include cosmic rays, and electrical wear of the material from which circuits are built).
If a bit-flip randomly occurs at some point during a program’s execution, is it less likely to effect external program behavior when the code has been built with high levels of compiler optimization or built with optimization disabled or at a low level?
- many optimizations reduce the number of instructions executed (reducing execution time reduces the probability of encountering a bit-flip) and makes more efficient use of registers (e.g., keeping needed values in registers over longer periods of time and reducing the time intervals when a registers is not in use; which increases the probability that a bit-flip will propagate to external behavior),
- fewer compiler optimizations is likely to result in an increased number of instructions executed (increasing the probability that a bit-flip will occur during program execution) and results in lower register usage efficiency (e.g., longer periods of time between the last use of register contents and a new value being loaded; increasing the probability that a bit-flip will modify a value that is never used again).
A study by Cook and Zilles flipped one bit in an executing program (100 evenly distributed points in the program were chosen and 100 instructions from each of those points were used as fault injection points, giving a total of 10,000 individual tests to be run) and monitored the impact on subsequent execution; this process was repeated between 32 and 244 times for each injection point, once for every bit in the 32-bit instruction, zero, one or two of its 64-bit input registers and one possible 64-bit output result register (i.e., the bit-flip only involved the current instruction and its input/output, not the contents of any other register or main memory).
The monitoring process consisted of two parallel executions containing the modified processor state and the unmodified processor state. The behavior of the two executions were compared to see if the fault did not propagate (a passing trial, e.g., a bit-wise AND of a register with 0xff when a bit-flip has been applied to one of the top 24 bits of the register, also the values in a branch not-equal are usually not-equal and a bit-flip is likely to maintain that state), caused a failure (either due to a compulsory event caused by a hardware trap such as an invalid instruction or an incorrectly aligned memory access, or what was called an error model event such as a control flow mismatch or writing a different value to storage), or is inconclusive (pass/fail did not occur within 10,000 executed instructions of the fault injection point).
Data
The available data consists of the normalised number of program executions having one of the behaviors pass, fail (compulsory), fail (error model, broken down into control flow and store related cases) or inconclusive for nine programs from the SPEC2000 integer benchmark compiled using gcc version 4.0.2 and the DEC C compiler (henceforth called O0, O2 and O3, for osf the O4 option was used.
There are nine measurements for each of the nine SPEC programs, repeated at 3 optimization levels for gcc and once for osf (the osf data is not analysed here).
Is the data believable?
Injecting bit-flip faults at all points in a program and monitoring for subsequence changes in external behavior would be an enormous task, sets of 100 instructions starting from 100 locations appears to be an unbiased sample.
The error model used checks for changes of control flow and different values being stored to memory, it does not check for actual changes in external program behavior. This model biases the measurements in favour of more bit-flips being counted as generating an error than would occur in practice.
Predictions made in advance
Does compiler optimization level change the probability that a bit-flip will cause a change in external program behavior?
No hypothesis is proposed suggesting that compiler optimization level will increase, decrease or have no effect on the probability of a bit-flip effecting external program behavior.
Applicable techniques
The data was originally a count of the number of instances and this has been normalised to a value between 0 and 100. The same number of programs were executed at all optimization levels.
Non-parametric techniques have to be used because nothing is known about the distribution of values.
The [Wilcoxon signed-rank test] is a test for two dependent samples while the [Mann-Whitney U test] is a test for two independent samples. To what extent does running gcc at different optimization levels make it a different compiler? Given that we are testing for the possibility that compiler optimizations do effect the results then it is necessary to treat the samples as being independent.
The function wilcox.test will perform a Mann-Whitney test if the parameter paired is FALSE (the default) and will generate a confidence interval if the parameter conf.int is TRUE (the default is FALSE).
Results
The Mann-Whitney test of the various measurements obtained using the O2 and O3 options finds no worthwhile difference between them. There are interesting differences in the values obtained using both of two options and the O0 option, as follows:
- Pass
-
Comparing percentage of pass behaviors for
O0andO2we see: p-values = 0.005 and 0.005
> wilcox.test(gcc.o0$pass.masked, gcc.o2$pass.masked, conf.int=TRUE)
Wilcoxon rank sum test with continuity correction
data: gcc.o0$pass.masked and gcc.o2$pass.masked
W = 8, p-value = 0.004697
alternative hypothesis: true location shift is not equal to 0
95 percent confidence interval:
-15.449995 -2.020001
sample estimates:
difference in location
-7.480088
The wilcox.test function returns an estimate of the difference between the two means and a negative value occurs if the second argument (the higher optimization level in this case) has a greater mean than the first argument (which is always the O0 option in these results).
O0/O3 95% confidence interval: -15.579959 -1.909965, mean: -4.780058
- Fail (compulsory)
-
-
Memory protection fault: pvalues = 0.002 and 0.005
O0/O295%: 2.1 7.5, mean: 4.9
O0/O395%: 1.9 7.3, mean: 4.1 -
Invalid instruction: p-values = 0.045 and 0.053
O0/O295%: -8.0e-01 -4.9e-08, mean: -0.5
O0/O395%: -6.4e-01 5.1e-06, mean: -0.3
-
Memory protection fault: pvalues = 0.002 and 0.005
- Fail (error model)
-
-
Control flow: p-values = 0.0008 and 0.002
O0/O295%: -10.8 -3.8, mean: -7.0
O0/O395%: -10.5 -3.7, mean: -6.8 -
Store related: p-values = 0.002 and 0.003
O0/O295%: 4.78 22.02, mean: 11.24
O0/O395%: 4.93 18.78, mean: 10.51
-
Control flow: p-values = 0.0008 and 0.002
Discussion
O2 and O3 options differences
The issue of optimization performance differences between the gcc O2 and O3 options is covered in [another section] of this book. That analysis found that the only difference between the two options was an increase in code size with O3, probably because of function inlining.
If there is no significant difference in the code generated by the O2/O3 options then no difference in bit-flip behavior is expected, and none was seen.
Changes in failure rates
The results show a decrease in store related errors at high optimization levels and an increase in control flow related errors. Why is this?
Optimizing register usage is a very important optimization and one of its consequences is a reduction in the number of stores to memory and loads having a corrupted address triggering a protection fault . A reduction in the number of memory related instructions executed will feed through into a reduction in the number of failures classified as store related or memory protection faults and this is seen in the shift in mean value of fails between high and low optimization levels.
Keeping a value containing an injected bit-flip in a register for a longer period of program execution (rather than being stored to memory and loaded back later) provides the opportunity for it to work its way through subsequent instructions and either disappear (being counted as a pass) or cause a control flow failure. It is likely that some of the change stored values flagged by the error model do not an impact on external program behavior and the pass count at low optimization levels is lower than would occur in practice.
Changes in pass rate
The additional optimizations of register usage enabled by the O2/O3 options reduces memory accesses which leads to a reduction in memory protection errors, an unrecoverable fault under all circumstances. The numbers suggest that while this is a major factor in the increased pass rate, contributions are made by other sources, e.g., bit-flips not contributing to the result calculated by an instruction; the data is not sufficiently detailed to enable a reliable estimate of this contribution to be made.
The pass rate is likely to be an underestimate because the error model classifies storing a different value as a failure, however the different value might not result in a change of external program behavior, e.g., the value stored might never be used again. Some of the stores classified as errors for the O0 option have no lasting affect in practice (and being kept in registers for O2/O3 had the opportunity to be masked out). No data is available for enable an estimate to be made for the percentage of these bit-flips have no lasting affect.
The average pass rate for gcc using the O0 option was 28% and this increased to around 36% when the O2/O3 options were used.
Other processors
How likely is it that the bit-flip pass rates seen on the Alpha (average of 36% for high optimization, 28% for low) would also occur on other processors?
The Alpha registers contain 64-bit and instructions operating on just 32 or 16 of those bits are supported. A study by Loh of the Alpha running SPEC2000 programs found that 48% of executed instructions operated on 64-bits, 24% on 32-bits and 28% on 16-bits. Based on these numbers 33% of single bit-flips of a 64-bit register would not be expected to affect the result of an instruction (the table below gives the percentages measured by Cook et al).
| injection site | O3 | O2 | O0 |
|---|---|---|---|
|
instruction
|
28.2
|
29.2
|
21.3
|
|
input register1
|
49.0
|
50.0
|
40.5
|
|
input register2
|
26.5
|
28.5
|
17.9
|
|
output register
|
39.6
|
41.9
|
34.7
|
A lot of software is based on using 32-bit integers and it might be expected that a much lower percentage of register bit-flips would result in pass behavior, compared to a 64-bit processor (where most operations that access 64 bits involve addresses). However, 32-bit processors usually contain instructions for operating on just 8-bits of a register and use of these instructions creates more opportunities for bit-flips to have no lasting consequences.
The measurements of Cook and Zilles have shown how interrelated instruction set interactions are. Without measurements from 32-bit processors it is not possible to estimate the extent to which bit-flips will impact external program behavior.
Conclusion
Compiling source using high levels of compiler optimization reduces the likelihood that a randomly occurring bit-flip during program execution will effect external program behavior. For processors that perform memory access checks the largest decrease in bit-flip induced faults is a reduction in memory protection faults.
Optimization generally reduces the number of instructions executed by a program, reducing the probability that a bit-flip will occur between the start and end of execution, further increasing the advantage of optimized code over non-optimized.
Changes in optimization performance of gcc over time
The SPEC benchmarks came out a year after the first release of gcc (in fact gcc was and still is one of the programs included in the benchmark). Compiling the SPEC programs using the gcc option -O2 (sometimes -O3) has always been the way to measure gcc performance, but after 25 years does this way of doing things tell us anything useful?
The short answer: No
The longer answer is below as another draft section from my book Empirical software engineering with R book. As always comments welcome.
Changes in optimization performance of gcc over time
The GNU Compiler Collection <book gcc-man_12> (GCC) is under active development with its most well known component, the C compiler gcc, now over 25 years old. After such a long period of development is the quality of code generated by gcc still improving and if so at what rate? The method typically used to measure compiler performance is to compile the [SPEC] benchmarks with a small set of optimization options switched on (e.g., the O2 or O3 options) and this approach is used for the analysis performed here.
Data
Vladimir N. Makarow measured the performance of 9 releases of gcc, occurring between 2003 and 2010, on the same computer using the same benchmark suite (SPEC2000); this data is used in the following analysis.
The data contains the [SPEC number] (i.e., runtime performance) and code size measurements on 12 integer programs (11 in C and one in C+\+) from SPEC2000 compiled with gcc versions 3.2.3, 3.3.6, 3.4.6, 4.0.4, 4.1.2, 4.2.4, 4.3.1, 4.4.0 and 4.5.0 at optimization levels O2 and O3 (the mtune=pentium4 option was also used) 32-bit for the Intel Pentium 4 processor.
The same integer programs and 14 floating-point programs (10 in Fortran and 4 in C) were compiled for 64-bits, again with the O2 and O3 options (the mpc64 floating-point option was also used), using gcc versions 4.0.4, 4.1.2, 4.2.4, 4.3.1, 4.4.0 and 4.5.0.
Is the data believable?
The following are two fitness-for-purpose issues associated with using programs from SPEC2000 for these measurements:
-
the benchmark is designed for measuring processor performance not
compiler performance, -
many of its programs have been used for compiler benchmarking for
many years and it is likely that gcc has already been tuned to do
well on this benchmark.
The runtime performance measurements were obtained by running each programs once, SPEC requires that each program be run three times and the middle one chosen. Multiple measurements of each program would have increased confidence in their accuracy.
Predictions made in advance
Developers continue to make improvements to gcc and it is hoped that its optimization performance is increasing, knowing that performance is at a steady state or decreasing performance is also of interest.
No hypothesis is proposed for how optimization performance, as measured by the O2 and O3 options, might change between releases of gcc over the period 2003 to 2010.
The gcc documentation says that using the O3 option causes more optimizations to be performed than when the O2 option is used and therefore we would expect better performance for programs compiled with O3.
Applicable techniques
Modelling individual O2 and O3 option performance
One technique for modelling changes in optimization performance is to build a linear model that fits the gcc version (i.e., version is the predictor variable) to the average performance of the code it generate, calculating the averaged performance over each of the programs measured with the corresponding version of gcc. The problem with this approach is that by calculating an average it is throwing away information that is available about the variation in performance across different programs.
Building a [mixed-effects] model would make use of all the data when fitting a relationship between two quantities where there is a recurring random component (i.e., the SPEC program used). The optimizations made are likely to vary between different SPEC programs, we could treat the performance variations caused by difference in optimization as being random and having an impact on the mean performance value of all programs.
Programs differ in the magnitude of their SPEC number and code size, the measurements were converted to the percentage change compared against the values obtained using the earliest version of gcc in the measurement set.
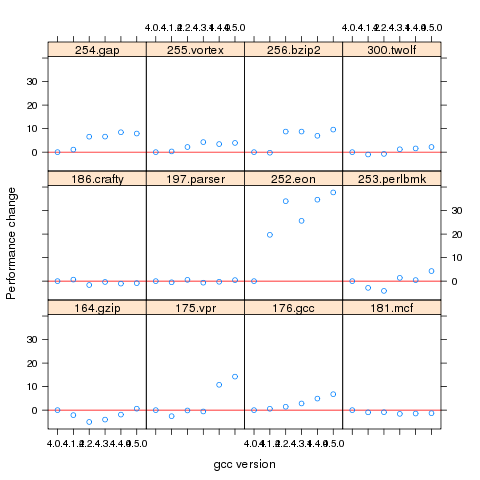
Figure 1. Percentage change in SPEC number (relative to version 4.0.4) for 12 programs compiled using 6 different versions of gcc (compiling to 64-bits with the O3 option).
Fitting a linear model requires at least two sets of [interval data]. The gcc version numbers are [ordinal values] and the following are two possible ways of mapping them to interval values:
-
there have been over 150 different released versions of gcc and a
particular version could be mapped to its place in this sequence. -
the date of release of a version can be mapped to the number of
days since the first release.
If version releases are organized around new functionality added then it makes sense to use version sequence number. If the performance of a new optimization was proportional to the amount of effort (e.g., man days) that went into its implementation then it would make sense to use days between releases.
The versions tested by Makarow were each from a different secondary release within a given primary version line and at roughly yearly intervals (two years separated the first pair and one month another pair).
There have been approximately 25 secondary releases in the 25 year project and using a release version sequence number starting at 20 seems like a reasonable choice.
Internally a compiler optimizer performs many different kinds of optimizations (gcc has over 160 different options for controlling machine independent optimization behavior). While the implementation of a new optimization is a gradual process involving many days of work, from the external user perspective it either exists and does its job when a given optimization level is supported or it does not exist.
What is the shape of the performance/release-version relationship? In the first few years of a compilers development it is to be expected that all the known major (i.e., big impact) optimization will be implemented and thereafter newly added optimizations have a progressively smaller impact on overall performance. Given gcc’s maturity it looks reasonable to assume that new releases contain a few additional improvement that have an incremental impact, i.e., the performance/release-version relationship is assumed to be linear (no other relationship springs out of a plot of the data).
A mixed-effects model can be created by calling the R function lme from the package nlme. The only difference between the following call to lme and a call to lm is the third argument specifying the random component.
t.lme=lme(value ~ variable, data=lme.O2, random = ~ 1 | Name) |
The argument random = ~ 1 | Name specifies that the random component effects the mean value of the result (when building a model this translates to an effect on the value of the intercept of the fitted equation) and that Name (of the program) is the grouped variable.
To specify that the random effect applies to the slope of the equation rather than its intercept the call is as follows:
t.lme=lme(value ~ variable, data=lme.O2, random = ~ variable -1 | Name) |
To specify that both the slope and the intercept are effected the -1 is omitted (for this gcc data the calculation fails to converge when both can be effected).
Since the measurements are about different versions of gcc it is to be expected that the data format has a separate column for each version of gcc (the format that would be used to pass data lm) as follows:
Name v3.2.3 v3.3.6 v3.4.6 v4.0.4 v4.1.2 v4.2.4 v4.3.1 v4.4.0 v4.5.0 1 164.gzip 933 932 957 922 933 939 917 969 955 2 175.vpr 562 561 577 576 586 585 576 589 588 3 176.gcc 1087 1084 1159 1135 1133 1102 1146 1189 1211 |
The relationship between the three variables in the call to lme is more complicated and the data needs to be reorganize so that one column contains all of the values, one the gcc version numbers and another column the program names. The function melt from package reshape2 can be used to restructure the data to look like:
Name variable value 11 256.bzip2 v3.2.3 0.000000 12 300.twolf v3.2.3 0.000000 13 SPECint2000 v3.2.3 0.000000 14 164.gzip v3.3.6 -0.107181 15 175.vpr v3.3.6 -0.177936 16 176.gcc v3.3.6 -0.275989 17 181.mcf v3.3.6 0.148810 |
Comparing O2 and O3 option performance
When comparing two samples the [Wilcoxon signed-rank test] and the [Mann-Whitney U test] spring to mind. However, some of the expected characteristics of the data violate some of the properties that these tests assume hold (e.g., every release include new/updated optimizations which is likely to result in the performance of each release having a different mean and variance).
The difference in performance between the two optimization levels could be treated as a set of values that could be modelled using the same techniques applied above. If the resulting model have a line than ran parallel with the x-axis and was within the appropriate confidence bounds we could claim that there was no measurable difference between the two options.
Results
The following is the output produced by summary for a mixed-effect model, with the random variation assumed to effect the value of intercept, created from the SPEC numbers for the integer programs compiled for 64-bit code at optimization level O2:
Linear mixed-effects model fit by REML
Data: lme.O2
AIC BIC logLik
453.4221 462.4161 -222.7111
Random effects:
Formula: ~1 | Name
(Intercept) Residual
StdDev: 7.075923 4.358671
Fixed effects: value ~ variable
Value Std.Error DF t-value p-value
(Intercept) -29.746927 7.375398 59 -4.033264 2e-04
variable 1.412632 0.300777 59 4.696612 0e+00
Correlation:
(Intr)
variable -0.958
Standardized Within-Group Residuals:
Min Q1 Med Q3 Max
-4.68930170 -0.45549280 -0.03469526 0.31439727 2.45898648
Number of Observations: 72
Number of Groups: 12
|
and the following summary output is from a linear model built from an average of the data used above.
Call:
lm(formula = value ~ variable, data = lmO2)
Residuals:
13 26 39 52 65 78
0.16961 -0.32719 0.47820 -0.47819 -0.01751 0.17508
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -28.29676 2.22483 -12.72 0.000220 ***
variable 1.33939 0.09442 14.19 0.000143 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.395 on 4 degrees of freedom
Multiple R-squared: 0.9805, Adjusted R-squared: 0.9756
F-statistic: 201.2 on 1 and 4 DF, p-value: 0.0001434
|
The biggest difference is that the fitted values for the Intercept and slope (the column name, variable, gives this value) have a standard error that is 3+ times greater for the mixed-effects model compared to the linear model based on using average values (a similar result is obtained if the mixed-effects random variation is assumed to effect the slope and the calculation fails to converge if the variation is on both intercept and slope). One consequence of building a linear model based on averaged values is that some of the variations present in the data are smoothed out. The mixed-effects model is more accurate in that it takes all variations present in the data into account.
For integer programs compiled for 32-bits there is much less difference between the mixed-effects models and linear models than is seen for 64-bit code.
-
For SPEC performance the created models show:
-
for the integer programs a rate of increase of around 0.6% (sd
0.2) per release forO2andO3options on 32-bit code
and an increase of 1.4% (sd 0.3) for 64-bit code, -
for floating-point, C programs only, a rate of increase per
release of 12% (sd 5) at 32-bits and 1.4% (sd 0.7) at 64-bits, with
very little difference between theO2andO3options.
-
for the integer programs a rate of increase of around 0.6% (sd
-
For size of generated code the created models show:
-
for integer programs 32-bit code built using
O2size is
decreasing at the rate of 0.6% (sd 0.1) per release, while for both
64-bit code andO3the size is increasing at between 0.7% (sd
0.2) and 2.5% (sd 0.4) per release, -
for floating-point, C programs only, 32-bit code built using
O2had an unacceptable p-value, while for both 64-bit code
andO3the size is increasing at between 1.6% (sd 0.3) and
9.3 (sd 1.1) per release.
-
for integer programs 32-bit code built using
Comparing O2 and O3 option performance
The intercept and slope values for the models built for the SPEC integer performance difference had p-values way too large to be of interest (a ballpark estimate of the values would suggest very little performance difference between the two options).
The program size change models showed O3 increasing, relative to O2, at 1.4% to 1.7% per release.
Discussion
The average rate of increase in SPEC number is very low and does not appear to be worth bothering about, possible reasons for this include:
-
a lot of effort has already been invested in making sure that gcc
performs well on the SPEC programs and the optimizations now being
added to gcc are aimed at programs having other kinds of
characteristics, -
gcc is a mature compiler that has implemented all of the worthwhile
optimizations and there are no more major improvements left to be
made, -
measurements based on just setting the
O2orO3
options might not provide a reliable guide to gcc optimization
performance. The command
gcc -c -Q -O2 --help=optimizers
shows that for gcc version 4.5.0 theO2option enables 91 of
the possible 174 optimization options and theO3option
enables 7 more. Performing some optimizations together sometimes
results in poorer quality code than if a subset of those
optimizations had been applied (genetic programming is being
researched as one technique for selecting the best optimizations
options to use for a given program and up to 13% improvements have
been obtained over gcc’s -O options <book Bashkansky_07>). The
percentage performance change figure above shows
that for some programs performance decreases on some releases.Whole program optimization is a major optimization area that has been addressed in recent versions of gcc, this optimizations is not enabled by the
Ooptions.
The percentage differences in SPEC integer performance between the O2 and O3 options were very small, but varied too much to be able to build a reliable linear model from the values.
For SPEC program code size there is a significant different between the O2 and O3 options. This is probably explained by function inlining being one of the seven additional optimization enabled by O3 (inlining multiple calls to the same function often increases code size <book inlining> and changes to the inlining optimization over releases could result in more functions being inlined).
Conclusion
Either the optimizations added to gcc between 2003 and 2010 have not made any significant difference to the performance of the generated code or the established method of measuring gcc optimization performance (i.e., the SPEC benchmarks and the O2 or O3 compiler options) is no longer a reliable indicator.
Memory capacity and commercial compiler development
When I started out in the compiler business in the 80s, many commercial compilers were originally written by one person. A very good person who dedicated himself (I have never heard of a woman doing this) to the job (i.e., minimal social life) could produce a commercially viable product for a non-huge language (e.g., Fortran, Pascal, C, etc, but not C++, Ada, etc) in 12-18 months. Companies who decide to develop a compiler in-house tend to use a team of people, and take longer, because that is how they work, and they don’t want to depend on one person, and anyway such a person might not be available to them.
Commercially viable compiler development stayed within the realm of an individual effort until sometime in the early 90s. What put the single individual out of business was the growth in computer memory capacity into the hundreds of megabytes and beyond. Compilers have to be able to run within the limits of developer machines; you won’t sell many compilers that require 100M of memory if most of your customers don’t have machines with 100M+ of memory.
Code optimizers eat memory, and this prevented many optimizations that had been known about for years appearing in commercial products. Once the machines used for software development commonly contained 100M+ of memory, compiler vendors could start to incorporate these optimizations into their products.
Improvements in processor speed also helped. But developers are usually willing to let the compiler take a long time to optimize the code going into a final build, provided development compiles run at a reasonable speed.
The increase in memory capacity created the opportunity for compilers to improve, and when some did improve they made it harder for others to compete. Suddenly an individual had to spend that 12-18 months, plus many more months implementing fancy optimizations; developing a commercially viable compiler outgrew the realm of individual effort.
Some people claim that the open source model was the primary driver in killing off commercial C compiler development. I disagree. My experience of licensing compiler source was that companies preferred a commercial model they were familiar with, and reacted strongly against the idea of having to make available any changes they made to the code of an open source program. GCC (and recently llvm) succeeded because many talented people contributed fancy optimizations and these could be incorporated because developer machines contained lots of memory. If storage had not dramatically increased, gcc would probably not be the market leader it is today.
Recommendations for teachers of programming
The software developers I deal with usually have at least 3 or more years professional experience in industry (I have not taught a beginners programming class in over 25 years) and these recommendations are based on what I tell these people. I like to think that they are applicable to teaching those with a lot less experience.
First. Application domain expertise generally has greater value than programming expertise. That is, an investment of time in learning the application domain will yield a greater return on investment that learning more programming techniques.
Implications:
Second. Computer time is cheap, people time is expensive.
Implications:
Third. Most software is written to solve an immediate problem, used a few times, and then forgotten about (I know of software projects costing in the millions where the code was never used; my own contribution to never used code is somewhat smaller, but still much larger than I would have liked). The point is that writing software involves a cost/benefit trade-off, how much should I invest in making code maintainable given the risk that the benefits from this investment may not be recouped.
Implications:
Fourth. Don’t fool yourself that you are teaching programming; you probably just give a lecture or two and expect students to pick up the details from one of the assigned course books.
Implications:
Fifth. Coding style does exist and can have an effect on the cost of writing and maintaining code as well as how well a compiler can optimize it. These costs and benefits vary with the context in which the code was created and used. A good programmer will adopt a coding style appropriate to the context, just like an actor plays a role with the appropriate characterization (eg, comedy, thriller, suspense). It takes more experience than most undergraduate have to be able to properly discern what style is being used, let alone be capable of changing their own style.
Implications:
Recent Comments