Archive
Halstead & McCabe metrics: The wisdom of the ancients
Study after study finds that the predictive power of both the Halstead metric and the McCabe cyclomatic complexity metric is no better than counting lines of code, for the characteristics of interest. Why do people continue to use and cite the Halstead and McCabe metrics?
My experience, talking to people, is that many believe these metrics have greater predictive power than lines of code. Sometimes I explain the situation, other times I move on.
Those who are aware of the facts often continue to use these metrics. Why do they do this?
Given the lack of alternative metrics that are more effective than lines of code, for the claimed uses of Halstead/McCabe, following the herd is the easy option (I regularly point this out to people, after explaining that Halstead/McCabe don’t do what is claimed on the tin). Tools are available to calculate the metrics; the manual effort is clicking buttons or running a command.
Why were the Halstead/McCabe metrics ‘successful’, in that they are the ones people cite/use today?
Both were formulated in the mid-1970s, when the discussion around measuring software started in earnest, so they had some first-mover advantage (within a few years they were both being suggested for use by US Military). Individuals promoted their ideas: Maurice Halstead was a senior professor, with colleagues and lots of graduate students, who advertised the metric via their publications; Thomas McCabe was working for the NSA when his famous paper was published, and went on to form a company working in the area of source code analysis.
The Halstead/McCabe metrics can both be calculated by processing the source one line at a time (just count decision points for McCabe, no need for the pretentious graph theory stuff). In the 1970s, computer memory was often measured in kilobytes, which made it difficult to implement complicated metrics that required keeping dependency information in memory.
Metrics based on the subroutine/function/procedure/method as the measured unit of source code had an implementation and usage advantage over metrics based on larger units of code.
In the 1990s, object-oriented programming, in the form of C++ and then Java, took off. The common view, by those caught up in the times, was that object-oriented software was so different from what went before that it needed its own metrics.
The 1991 paper: Towards a Metrics Suite for Object Oriented Design, by Chidamber and Kemerer, introduced the six CK metrics (as they become known; 1992 update). The nearest this paper comes to citing the Halstead/McCabe work is to say: “Some early work has recognized the shortcomings of existing metrics and the need for new metrics especially designed for OO.” The paper followed in the footsteps of the earlier work in not providing any evidence for the claims made (the update contains histograms of metric values from a C++ project and a Smalltalk project).
The 1996 paper: Evaluating the Impact of Object-Oriented Design on Software Quality, by Abreu and Melo, introduced the MOOD metrics (Metrics for Object-Oriented Design).
At the end of 2022 the total citation counts returned by Google Scholar were: McCabe 8,670, Halstead 4,900, CK 8,160, and MOOD 354.
The plot below shows the number of new citations returned by Google Scholar, each year, for the respective metrics papers (or book for Halstead; code+data):
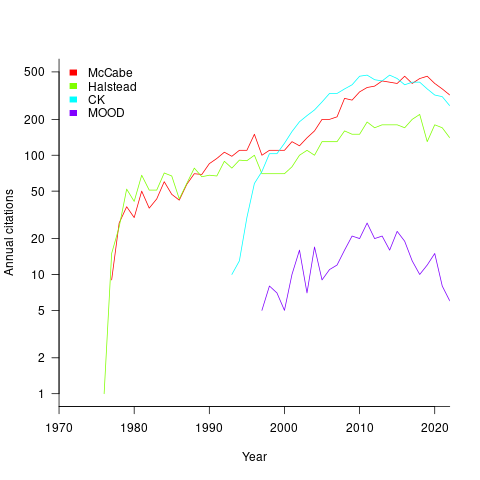
The ongoing growth in annual rate of citation probably has more to do with the growth in the number of software papers published each year, rather than these metric papers being cited by an expanding number of research fields.
Do authors tend to cite one or the other of Halstead/McCabe, or both?
Using Google Scholar’s ‘search within’ option to find the subset of papers that included a string matching the title of a paper: 46% of the Halstead citations include a citation of the McCabe paper, and 25% of the McCabe citations include a citation of the Halstead paper.
The Inciteful’s paper network (with citation counts: Halstead 1,052 and McCabe 4,970) found 657 papers citing both (62% of the Halstead total, 12% of the McCabe).
It’s not possible to make use of the OpenCitations API because it is DOI based, and the Halstead citation is a book.
Developers do not remember what code they have written
The size distribution of software components used in building many programs appears to follow a power law. Some researchers have and continue to do little more than fit a straight line to their measurements, while those that have proposed a process driving the behavior (e.g., information content) continue to rely on plenty of arm waving.
I have a very simple, and surprising, explanation for component size distribution following power law-like behavior; when writing new code developers ignore the surrounding context. To be a little more mathematical, I believe code written by developers has the following two statistical properties:
- nesting invariance. That is, the statistical characteristics of code sequences does not depend on how deeply nested the sequence is within
if/for/while/switchstatements, - independent of what went immediately before. That is the choice of what statement a developer writes next does not depend on the statements that precede it (alternatively there is no short range correlation).
Measurements of C source show that these two properties hold for some constructs in some circumstances (the measurements were originally made to serve a different purpose) and I have yet to see instances that significantly deviate from these properties.
How does writing code following these two properties generate a power law? The answer comes from the paper Power Laws for Monkeys Typing Randomly: The Case of Unequal Probabilities which proves that Zipf’s law like behavior (e.g., the frequency of any word used by some author is inversely proportional to its rank) would occur if the author were a monkey randomly typing on a keyboard.
To a good approximation every non-comment/blank line in a function body contains a single statement and statements do not often span multiple lines. We can view a function definition as being a sequence of statement kinds (e.g., each kind could be if/for/while/switch/assignment statement or an end-of-function terminator). The number of lines of code in a function is closely approximated by the length of this sequence.
The two statistical properties listed above allow us to treat the selection of which statement kind to write next in a function as mathematically equivalent to a monkey randomly typing on a keyboard. I am not suggesting that developers actually select statements at random, rather that the set of higher level requirements being turned into code are sufficiently different from each other that developers can and do write code having the properties listed.
Switching our unit of measurement from lines of code to number of tokens does not change much. Every statement has a few common forms that occur most of the time (e.g., most function calls contain no parameters and most assignment statements assign a scalar variable to another scalar variable) and there is a strong correlation between lines of code and token count.
What about object-oriented code, do developers follow the same pattern of behavior when creating classes? I am not aware of any set of measurements that might help answer this question, but there have been some measurements of Java that have power law-like behavior for some OO features.
Recent Comments