Archive
Identifier names chosen to hold the same information
Identifier naming is a contentious issue dominated by opinions and existing habits, with almost no experimental evidence (rather like software engineering practices in general).
One study found that around 40% of all non-white-space characters in the visible source of C programs are identifiers (comments representing 31% of the characters in the .c files), representing 29% of the visible tokens in the .c files.
Some years ago I spent a long time studying the word related experiments run by psychologists, looking for possible parallels with identifier usage. The crucial identifier naming factor is the semantic associations a name triggers in the reader’s mind. Choosing a name requires making a cost-benefit tradeoff. The greater quantity of information that might be communicated by longer names has to be balanced against both the cost of reading the name and ignoring the name when searching for other information.
The semantic association network present in a person’s head is the result of the words they have encountered and the context in which they were encountered. Different people are likely to make different associations. Shared culture and experiences increases the likelihood of shared naming associations.
A study by Nelson, McEvoy, and Schreiber gave subjects (over time, 6,000 students at the University of South Florida) a booklet containing 100 words, and asked them to write down the first word that came to mind that was meaningfully related or strongly associated to each of these words (data here, a total of 612,627 responses to 5,024 distinct words). The mean number of different responses to the same word was 14.4, with a standard deviation of 5.2.
There are patterns in the names of identifiers. For instance, operands of bitwise and logical operators have names that include words whose semantics is associated with the operations usually performed by these operands, such as: flag, status, state, and mask. One experiment (with a small sample size) found that developers make use of operand names to make operator precedence decisions.
A study by Feitelson, Mizrahi, Noy, Shabat, Eliyahu, and Sheffer, investigated the variable names chosen by developers to hold specific information. The 334 subjects (students and professional developers) were asked to suggest a name for a variable, constant, or data structure based on a description of the information it would contain, plus other questions relating to interpreting the semantics associated with a name.
The authors cite a problem that I think is actually a benefit: “A major problem in studying spontaneous naming is that the description of the context and the question itself necessarily use words.” When writing code a well-chosen name communications information about the context, which helps readers understand what is going on. The authors’ solution to this perceived problem was to give the description in either Hebrew or English (the subjects were native Hebrew speakers who are fluent in English), with subjects providing the name in English.
The answers to the 21 name generation questions had a mean of 53 distinct names (standard deviation 20.2; code and data). The table below shows the names chosen and the number of subjects choosing that name after seeing the description in Hebrew or English, for one of the questions.
Name Hebrew English b_elevator_door_state 1 b_is_door_open 1 curr_state 2 current_doors_state 1 door 3 1 door_current_status 1 door_is_closed 1 door_is_open 1 door_open 3 door_stat 1 door_state 10 12 door_status 4 doorstate 1 1 elevator_door_state 1 1 elevator_state 1 is_closed 1 1 is_door_closed 2 1 is_door_open 11 3 is_door_opened 2 2 is_elevator_open 1 is_o_pen 1 is_open 7 5 is_opened 2 state 1 status 1 status_of_door 1 |
While the names are distinct, some only differ by a permutation of words, e.g., door_is_open and is_door_open, or with one word missing, e.g., door_open and is_open, or two words missing, e.g., door.
If subjects are influenced by the description (e.g., using the word ordering that appears in the description, or only words from the description), the number of unique names would be smaller than if there was no such influence. The impact of influence would be that subjects seeing the English descriptions are likely to produce fewer unique names.
In 13 out of 21 questions, Hebrew subjects produced more unique names. However, a bootstrap test shows that the difference is not statistically significant.
I think a big threat to the validity of the study is only having subjects create one name. Writing software involves creating names for many variables, which has different cost-benefit tradeoffs than when creating a single variable. The names within a program share a common context and developers tend to follow informal patterns so that naming within the code has some degree of consistency. Adhering to these patterns restricts the possible set of names that might be chosen. Also, the existing use of a name may prevent it being reused for a new variable.
Programming competitions are one source for variable names implementing the same specification, at least for short program. Longer programs are more likely to have some variation in the algorithms used to implement the same functionality.
I expect greater consistency of identifier name selection within an LLM than across developers. LLM training will direct them down existing common patterns of usage, plus some random component.
Naming convergence in a network of pairwise interactions
While naming and categorizing things are perhaps the two most contentious issues in software engineering, there is often a great deal of similarity in the names and categorizes used by unconnected groups. These characteristics of naming and categorization are general observed behaviors across cultures and languages, with software engineering being a particular example.
Studies have found that a particular name for a thing is likely to become adopted by a group, if around 25% of its members actively promote the use of the name. The terms tipping point and critical mass have been applied to the 25% quantity.
What factors could cause 25% of the members of a group to select a particular name, and why does a tipping point occur at around this percentage?
The paper Experimental evidence for scale-induced category convergence across populations by Douglas Guilbeault (PhD thesis behind the paper), Andrea Baronchelli, and Damon Centola experimentally investigated factors that can cause a name to be adopted by 25% of a group’s members, and the researchers proposed a model that exhibits behavior similar to the experimental results (the supplement contains the technical details).
The experiment asked subjects to play the “Grouping Game”. The 1,480 online subjects were divided into networks containing either 2, 6, 8, 24 or 50 members. The interaction between members of a network only occurred via randomly selected pairs (the same pair for the network of two), with one person designated as the speaker and the other as the hearer. A pair saw three randomly selected images, such as the one below. For the speaker only, one of the images was highlighted, and they had to give a name containing at most six characters to the image. The hearer saw the name given by the speaker to one of the images, and had 30 seconds to choose the image they considered to have been named. If the image selected by the hearer was the one named by the speaker, both received a small payment, otherwise an even smaller amount was deducted from their final payment. Each subject played 100 rounds with the randomly chosen members of their network.

The images were created as a series of 50+ distinct patterns whose shape slowly morphed along a continuum, as in the following image:

The experimental results were that larger networks converged to a consistent, within group, naming of the images (using a few names), while smaller groups rarely converged and used many different names. The researchers proposed that as the network size grew, common names were encountered more often than rarer names, increasing the likelihood of reaching a tipping point. This behavior is similar to the birthday paradox, where there is a 50% probability that in a room of 23 people, two people will share the same birthday.
In the experiment, some networks included confederates trained to use a small subset of names, i.e., the researchers created a common set of names. It was hypothesized built-in human preferences would produce common patterns in the real world that, for larger groups, would cause tipping points to occur, amplifying the more common patterns to become group norms.
The supplement to the paper develops a theoretical model based on the probability of  identical items being contained in a sample of
identical items being contained in a sample of  items, when sampling without replacement. The solution involves the hypergeometric distribution, which is difficult to deal with analytically, so simulation is needed. The results show a tipping point at around 25%.
items, when sampling without replacement. The solution involves the hypergeometric distribution, which is difficult to deal with analytically, so simulation is needed. The results show a tipping point at around 25%.
The plot below shows a density plot for one 50-subject network over 15 trials (after 100 rounds of pairwise interaction), with each color denoting one of the 14 chosen names (height of the curve denotes likelihood of the same name being chosen for that image; code and data):
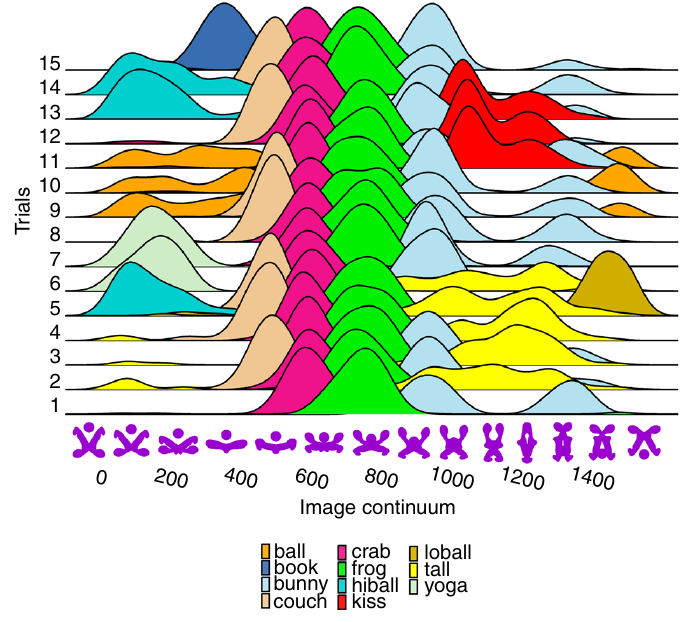
This plot shows that the same name is often used across trials, and naming boundaries between some images.
The plot below shows a density plot for one 2-subject network over 15 trials (after 100 rounds of pairwise interaction), with each color denoting one of the 72 chosen names (height of the curve denotes likelihood of the same name being chosen for that image; code and data):
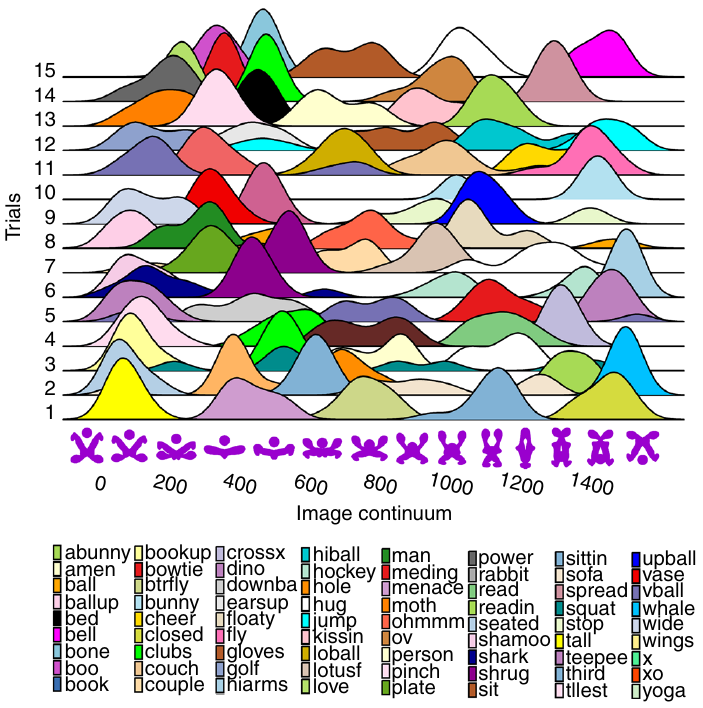
Here there is no consistent naming across trials, a much greater diversity of names appearing, and no obvious naming boundaries between images.
Impact of native language on variable naming
When creating a variable name, to what extent are developers influenced by their native human language?
There is lots of evidence that variable names are either English words, abbreviations of English words, or some combination of these two. Source code containing a large percentage of identifiers using words from other languages does exist, but it requires effort to find; there is a widely expressed view that source should be English based (based on my experience of talking to non-native English speakers, and even the odd paper discussing the issue, e.g., Language matters).
Given that variable names can prove information that reduces the effort needed to understand code, and that most code is only ever read by the person who wrote it, developers should make the most of their expertise in using their native language.
To what extent do non-native English-speaking developers make use of their non-English native language?
I have found it very difficult to even have a discussion around this question. When I broach the subject with non-native English speakers, the response is often along the lines of “our develo0pers speak good English.” I am careful to set the scene by telling them of my interest in naming, and that I think there are benefits for developers to make use of their native language. The use of non-English languages in software development is not yet a subject that is open for discussion.
I knew that sooner or later somebody would run an experiment…
How Developers Choose Names is another interesting experiment involving Dror Feitelson (the paper rather confusingly refers to it as a survey, a post on an earlier experiment).
What makes this experiment interesting is that bilingual subjects (English and Hebrew) were used, and the questions were in English or Hebrew. The 230 subjects (some professional, some student) were given a short description and asked to provide an appropriate variable/function/data-structure name; English was used for 26 of the question, and Hebrew for the other 21 questions, and subjects answered a random subset.
What patterns of Hebrew usage are present in the variable names?
Out of 2017 answers, 14 contained Hebrew characters, i.e., not enough for statistical analysis. This does not mean that all the other variable names were only derived from English words, in some cases Hebrew words appeared via transcription using the 26 English letters. For instance, using “pinuk” for the Hebrew word that means “benefit” in English. Some variables were created from a mixture of Hebrew and English words, e.g., deservedPinuks and pinuksUsed.
Analysing this data requires someone who is fluent in Hebrew and English. I am not a fluent, or even non-fluent, Hebrew speaker. My role in this debate is encouraging others, and at last I have some interesting data to show people.
The paper spends time showing how for personal preferences result in a wide selection of names being chosen by different people for the same quantity. I cannot think of any software engineering papers that have addressed this issue for variable names, but there is lots of evidence from other fields; also see figure 7.33.
Those interested in searching source code for the impact of native-language might like to look at the names of variables appearing as operands of the bitwise and logical operators. Some English words occur much more frequently in the names of these variable, compared to variables that are operands of arithmetic operators, e.g., flag, status, and signal. I predict that non-native English-speaking developers will make use of corresponding non-English words.
Variable naming based on lengths of existing variable names
Over the years I have spent a lot of time studying variable names and I sometimes encounter significant disbelief when explaining the more unusual developer variable name selection algorithms.
The following explanation from Rasmus Lerdorf, of PHP fame, provides a useful citable source for a variant on a common theme (i.e., name length).
“… Back when PHP had less than 100 functions and the function hashing mechanism was strlen(). In order to get a nice hash distribution of function names across the various function name lengths names were picked specifically to make them fit into a specific length bucket. This was circa late 1994 when PHP was a tool just for my own personal use and I wasn’t too worried about not being able to remember the few function names.”
Pointers to other admissions of youthful folly welcome.
Using local context to disambiguate source
Developers can often do a remarkably good job of figuring out what a snippet of code does without seeing (i.e., knowing anything about) most of the declarations of the identifiers involved. In a previous post I discussed how frequency of occurrence information could be used to help parse C without using a symbol table. Other information that could be used is the context in which particular identifiers occur. For instance, in:
f(x); y = (f)z; |
while the code f(x); is probably a function call, the use of f as the type in a cast means that f(x) is actually a definition an object x having type f.
A project investigating the analysis of partial Java programs uses this context information as its sole means of disambiguating Java source (while they do build a symbol table they do not analyze the source of any packages that might be imported). Compared to C Java parsers have it easy, but Java’s richer type system means that semantic analysis can be much more complicated.
On a set of benchmarks the researchers obtained a very reasonable 91.2% accuracy in deducing the type of identifiers.
There are other kinds of information that developers probably use to disambiguate source: the operation that the code is intended to perform and the identifier names. Figuring out the ‘high level’ operation that code performs is a very difficult problem, but the names of Java identifiers have been used to predict object lifetime and appear to be used to help deduce operator precedence. Parsing source by just looking at the identifiers (i.e., treating all punctuators and operators as whitespace) has been on my list of interesting project to do for some time, but projects that are likely to provide a more immediate interesting result keep getting in the way.
Naming used to predict object lifetime
One of the most surprising empirical results I heard about this year was that the name of a Java object could (reasonably) reliably be used to predict its lifetime on the heap. Being a huge advocate of the importance of naming I should not have been surprised.
The author, Jeremy Singer, invited me to Manchester to talk about my own experiments and I heard about his group’s latest project investigating how to subdivide a Java program so that bits of it can be executed on different processors. I suggested various ways in which naming might be used to group semantically related functionality (would it do better than simple statement colocation you ask) and await to see if the group goes with any naming ideas (my suggestions were accompanied by a fair amount of arm waving, so I might have to wait a while).
The most worthwhile R coding guidelines I know
Since my post questioning whether native R usage exists (e.g., a common set of R coding patterns) several people have asked about coding/style guidelines for R. My approach to style/coding guidelines is economic, adhering to a guideline involves paying a cost now for some future benefit. Obviously to be worthwhile the benefit must be greater than the cost, there is also the issue of who pays the cost and who reaps the benefit (why would anybody pay the cost if somebody else reaps the benefit?). The following three topics are probably where the biggest benefits are to be had and only the third is specific to R (and given the state of my R knowledge may be wrong).
Comment your code. Investing 5-10 seconds per few lines of code now could save substantially more time at some future date. Effective commenting is a skill that has to be learned, start learning now. Think of commenting as sending a text message or tweet to the person you will be in 6 months time (i.e., the person who can hum the tune but has forgotten the details).
Consistently use variable names that mean something to you. This should be a sub 2-second decision that is probably going to save you no more than 5-10 seconds, but in many cases you reap the benefit soon after the investment, without having to wait many months. Names evoke associations in your mind, take advantage of this associative lookup to reduce the cognitive load of working with your code. Effective naming is a skill that has to be learned, start learning now. There are people who ignore the evidence that different people’s linguistic preferences and associations can be very different and insist that everybody adhere to one particular naming convention; ignore them.
Code organization and structure. Experience shows that there are ways of organizing and structuring +1,000 line programs that have a significant impact on the effort needed to actively work on the code, the more code there is the greater the impact. R programs tend to be short, say around 100 lines (I dare say much longer ones exist). Apart from recommending that code be broken up into separate functions, I cannot think of any organizational/structural issue that is worth recommending for 100 lines of code (if you don’t appreciate the advantage of using separate functions you need some hands on training, not words in a blog post).
Is that it, are there no other worthwhile recommendations? There might be, I just don’t have enough experience using R to know. Does anybody else have enough experience to know? I suspect not; where would they have gotten the information needed to do the cost/benefit analysis? Even in the rare case where a detailed analysis is made for a language the results are rather thin on the ground and somewhat inconclusive.
What is the reason behind those R style guides/coding guideline documents that have been written? The following are some possibilities:
and no, I don’t have any empirical data to backup my guidelines 🙁