Archive
R needs some bureaucracy
Writing a program in R is almost bureaucracy free: variables don’t need to be declared, the language does a reasonable job of guessing the type a value might need to be automatically be converted to, there is no need to create a function having a special name that gets called at program startup, the commonly used library functions are ready and waiting to be called and so on.
Not having a bureaucracy is all well and good when programs are small or short lived. Large programs need a bureaucracy to provide compartmentalization (most changes to X need to be prevented from having an impact outside of X, doing this without appropriate language support eventually burns out anybody juggling it all in their head) and long lived programs need a bureaucracy to provide version control (because R and its third-party libraries change over time).
Automatically installing a package from CRAN always fetches the latest version. This is all well and good during initial program development. But will the code still work in six months time? Perhaps the author of one of the packages used in the program submits a new version of that package to CRAN and this new version behaves slightly differently, breaking the previously working program. Once the problem is located the developer has either to update their code or manually install the older version of the package. Life would be easier if it was possible to specify the required package version number in the call to the library function.
Discovering that my code depends on a particular version of a CRAN package is an irritation. Discovering that two packages I use each have a dependency on different versions of the same package is a nightmare. Having to square this circle is known in the Microsoft Windows world as DLL hell.
There is a new paper out proposing a system of dependency versioning for package management. The author proposes adding a version parameter to the library function, plus lots of other potentially useful functionality.
Apart from changing the behavior of functions a program calls, what else can a package author do to break developer code? They can create new functions and variables. The following is some code that worked last week:
library("foo") # The function get_question is in this package library("bar") # The function give_answer_42 is in this package (the_question=get_question()) give_answer_42(the_question) |
between last week and today the author of package foo (or perhaps the author of one of the packages that foo has a dependency on) has added support for the function solve_problem_42 and it is this function that will now get called by this code (unless the ordering of the calls to library are switched). What developers need to be able to write is:
library("foo", import=c("the_question")) # The function get_question is in this package library("bar", import=c("give_answer_42")) # The function give_answer_42 is in this package (the_question=get_question()) give_answer_42(the_question) |
to stop this happening.
The import parameter enables developers to introduce some compartmentalization into my programs. Yes, R does have namespace management for packages, and I’m pleased to see that its use will be mandatory in R version 3.0.0, but this does not protect programs from functions the package author intends to export.
I’m not sure whether this import suggestion will connect with R users (who look very laissez faire to me), but I get very twitchy watching a call to library go off and install lots of other stuff and generate warnings about this and that being masked.
Language usage in Google’s ngram viewer
I thought I would join the fun that people are having with Google’s new ngram viewer. The raw data (only a subset for bigrams and longer ngrams) was also enticing, but at 35+ gigabytes for the compressed 1/2/3-grams of English-all I decided to forgo the longer n-grams.
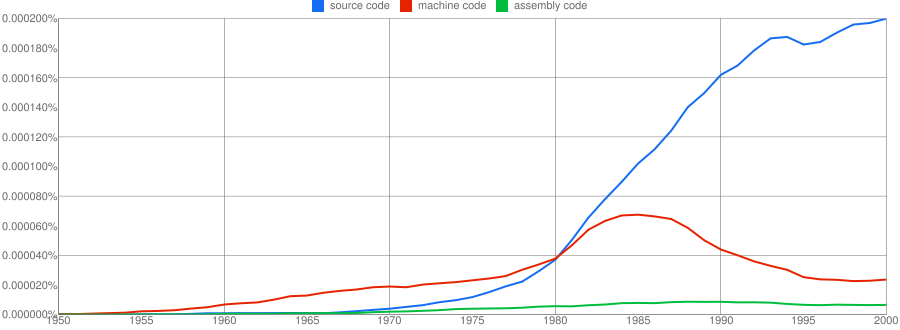
We all know that in the dim and distant past most programmers wrote in machine code, but it was not until 1980 that “source code” appeared more frequently in books that “machine code”.
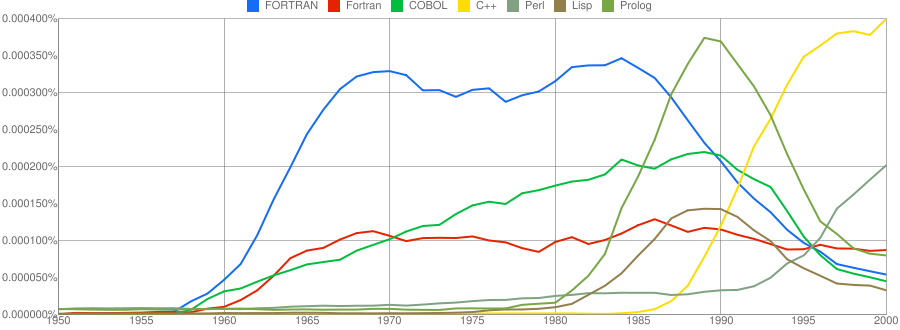
Computer language popularity is a perennial question. Fortran and Cobol address very different markets and I would have expected their usage to follow similar patterns, with “COBOL” having the obvious usage pattern for them both to follow. Instead, both “FORTRAN” and “Fortran” peaked within 10 years, with one staying there for another 20 years before declining and the other still going strong in 2000 (and still ahead of “PHP” and “Python” in 2000; neither shown to keep the clutter down). I am surprised to see “Prolog” usage being so much greater than “Lisp” and I would have expected “Lisp” to have a stronger presence in the 1970s.
I think the C++ crowd will be surprised to see that in 2000 usage was not much greater than what “FORTRAN” had enjoyed for 20 years.
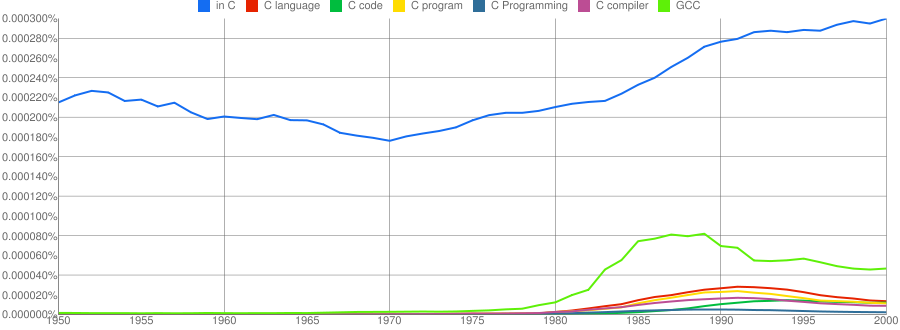
“C”, as in language, usage is obviously different to reliably measure. I have tried the obvious bigrams. Looking at some of the book matches for the phrase “in C” shows that the OCR process has sometimes inserted spaces that probably did not exist in the original, the effect being to split words and create incorrect bigrams. The phrase “in C” would also appear in books on music.
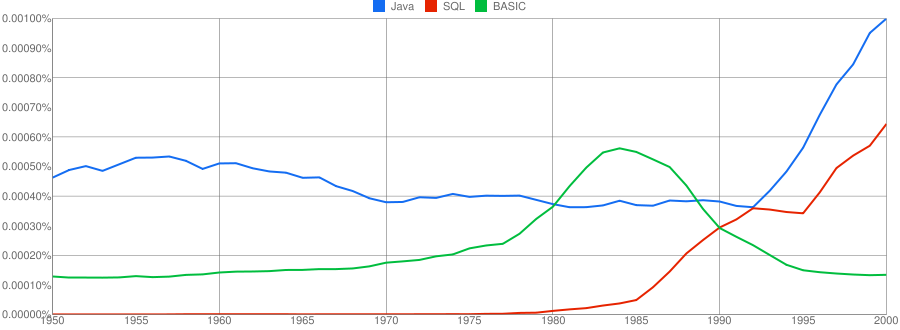
I have put the three words “Java”/”SQL”/”BASIC” in a separate plot because their usage swamps that of the other languages. Java obviously has multiple non-computer related uses and subtracting the estimated background usage suggests a language usage similar to that of “SQL”. There is too much noise for the usage of “Basic” to tell us much.
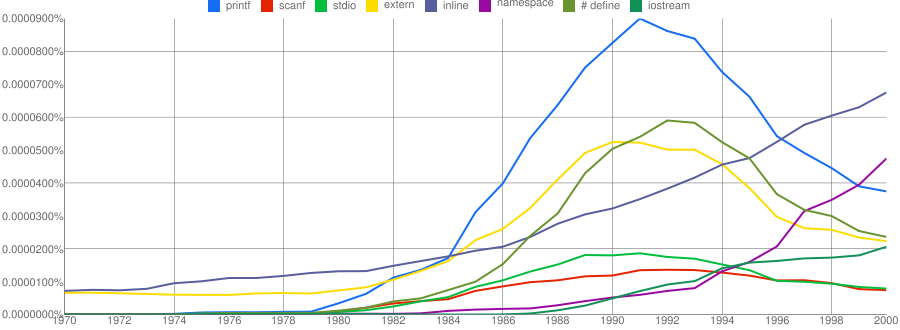
One way of comparing C/C++ language usage is to look source code usage where they are likely to differ. I/O, in the form of printf/scanf and stdio/iostream, is one obvious choice and while the expected C usage starts to declines in the 1990s the C++ usage just shows a stead growth (perhaps the <</>> usage, which does not appear in the Google viewer, has a dramatic growth during this time period).
Surprisingly #define also follows a similar pattern of decline. Even allowing for the rabid anti-macro rhetoric of the C++ in-crowd I would not have expected such a rapid decline. Perhaps this is some artifact of the book selection process used by Google; but then "namespace" shows a healthy growth around this time period.
The growth of "inline" over such a long period of time is a mystery. Perhaps some of this usage does not relate to a keyword appearing within source code examples but to text along the lines of "put this inline to make it faster".
What usage should we expect for the last decade? A greater usage of "PHP" and "Python" is an obvious call to make, along with the continuing growth of SQL, I think "UML" will also feature prominently. Will "C++" show a decline in favor or "Java" and what about "C#"? We will have to wait and see.
Recent Comments