Archive
Generating code that looks like it is human written
I am very interested in understanding the patterns of developer behavior that lead to the human characteristics that can be found in code. To help me get some idea of how well I understand this behavior I have decided to build a tool that generates source code that appears to be written by human programmers. I hope to reach a point where I can offer a challenge to tell the difference between generated code and human written code.
The three main production techniques I plan to use are, in increasing order of relatedness to humans production techniques, are:
- Random generation based on percentage occurrence of language constructs obtained from measurements of existing source. This is the simplest approach and the one furthest away from common developer behavior; even so there are things that can be learned from this information. For instance, the theory that developers are more likely to create a function once code becomes heavily nested code implies that the probability of encountering an if-statement decreases as nesting depth increases; measurements show the probability of encountering an if-statement remaining approximately constant as depth of nesting increases.
- Behavior templates. People have habits in everyday life and also when writing software. While some habits are idiosyncratic and not encountered very often there are some that appear to be generally used. For instance, developers tend to assign a fixed role to every variable they define (e.g., stepper for stepping through a succession of values and most-recent holder holding the latest value encountered in going through a succession of values).
I am expecting/hoping that generation by behavioral templates will result in code having some of the probabilistic properties seen in human code, removing the need for purely random generation driven by low level language probability measurements. For instance, the probability of a local variable appearing in a function is proportional to the percentage of its previous occurrences up to that point in the source of the function (
percentage = occurrences_of_X / occurrences_of_all_local_variables) and I am hoping that this property appears as emergent behavior from generating using the role of variable template. - Story telling. A program is like the plot of a story, it has a cast of characters (e.g., classes, functions, libraries) that perform various actions and interact with each other in order to achieve various goals, there are subplots (intermediate results are calculated, devices are initialized, etc), there are resource limits, etc.
While a lot of stories are application domain specific there are subplots common to many stories; also how a story is told can be heavily influenced by the language used, for instance Prolog programs have a completely different structure than those written in procedural languages such as Java. I want to stay away from being application specific and I don’t plan to tackle languages too far outside the common-or-garden procedural variety.
Researchers have created automatic story generators; the early generators were template based while more recent systems have used an agent based approach. Story based generation of code is my ideal, but I am a long way away from having enough knowledge of developer behavior to be more than template based.
In a previous post I described a system for automatically generating very simply C programs. I plan to build on this system to incrementally improve the ‘humanness’ of the generated code. At some point, hopefully before the end of this year, I will challenge people to tell the difference between automatically generated and human written code.
The language I have studied the most is C and this will be the main target. I don’t want to be overly C specific and am trying to decide on a good second language (i.e., lots of source available for measurement, used by lots of developers and not too different from C). JavaScript is the current front runner, it is a class-less object oriented language which is not ‘wildly’ OO (the patterns of usage in human written OO code continue to evolve at a rapid rate which can make a lot of human C++/Java code look automatically generated).
As well as being a test bed for understanding of human generated code other uses for an automatic generator include compiler stress testing and providing code snippets to an automated fault fixing tool.
Unused function parameters
I have started redoing the source code measurements that appear in my C book, this time using a lot more source, upgraded versions of existing tools, plus some new tools such as Coccinelle and R. The intent is to make the code and data available in a form that is easy for others to use (I am hoping that one or more people will measure the same constructs in other languages) and to make some attempt at teasing out relationships in the data (previously the data was simply plotted with little or no explanation).
While it might be possible to write a paper on every language construct measured, I don’t have the time to do the work. Instead, I will use this blog to make a note of the interesting things that crop up during the analysis of each construct I measure.
First up are unused function parameters (code and data), which at around 11% of all parameters are slightly more common than unused local variables (Figure 190.1). In the following plot black circles are the total number of functions having a given number of parameters, red circles a given number of unused parameters, blue line a linear regression fit of the red circles, and the green line is derived from black circle values using a formula I concocted to fit the data and have no theoretical justification for it.
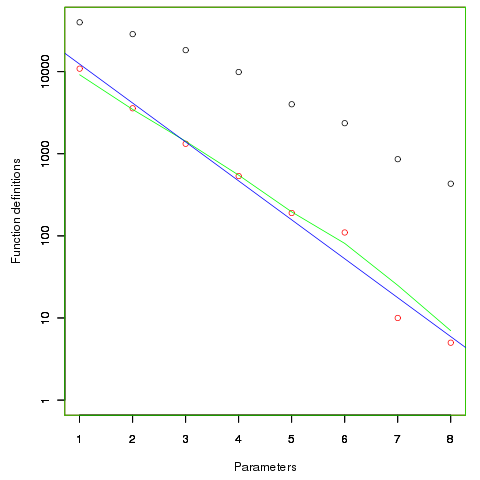
The number of functions containing a given number of unused parameters drops by around a factor of three for each additional unused parameter. Why is this? The formula I came up with for estimating the number of functions containing  unused parameters is:
unused parameters is:  , where
, where  is the total number of function definitions containing
is the total number of function definitions containing  parameters.
parameters.
Which parameter, for those functions defined with more than one, is most likely to be unused? My thinking was that the first parameter might either hold the most basic information (and so rarely be unused) or hold information likely to be superseded when new parameters are added (and so commonly be unused), either way I considered later parameters as often being put there for later use (and therefore more likely to be unused). The following plot is for eight programs plus the sum of them all; for all functions defined with between one and eight parameters, the percentage of times the  ‘th parameter is unused is given. The source measured contained 104,493 function definitions containing more than one parameter with 16,643 of these functions having one or more unused parameter, there were a total of 235,512 parameters with 25,886 parameters being unused.
‘th parameter is unused is given. The source measured contained 104,493 function definitions containing more than one parameter with 16,643 of these functions having one or more unused parameter, there were a total of 235,512 parameters with 25,886 parameters being unused.
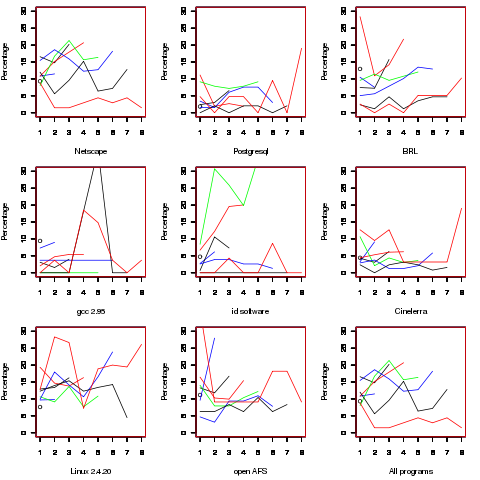
There is no obvious pattern to which parameters are likely to be unused, although a lot of the time the last parameter is more likely to be unused than the penultimate one.
Looking through the raw data I noticed that there seemed to be some clustering of names of unused parameters, in particular if the ‘th parameter was unused in two adjacent ‘unused parameter’ functions they often had the same name. The following plot is for all measured source and gives the percentage of same name occurrences; the matching process analyses function definitions in the order they occur within a source file and having found one unused parameter its name is compared against the corresponding parameter in the next function definition with the same number of parameters and having an unused parameter at the same position.
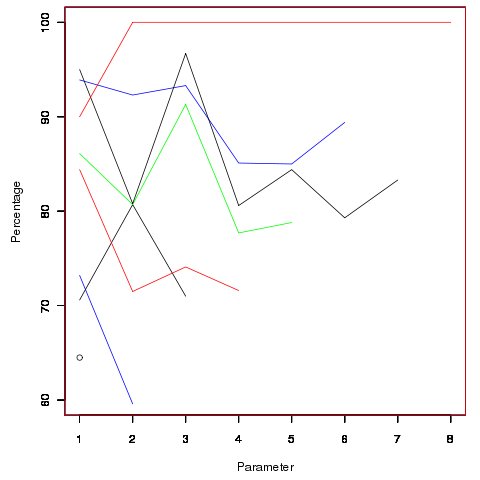
Before getting too excited about this pattern, we should ask if something similar exists for the used parameters. When I get around to redoing the general parameter measurements, I will look into this question. The numbers of occurrences for functions containing eight parameters is close to minimal.
The functions containing these same-name unused parameters appear to also have related function names. Is this a case of related function being grouped together, often sharing parameter names, and when one of them has an unused parameter the corresponding parameter in the others is also unused?
Is there a correlation between number of parameters and number of statements, are functions containing lots of statements less likely to have unused parameters? What effect does software evolution have (most of this kind of research measures executable code, not variable definitions)?
Recent Comments