Archive
Why did organizations fund the creation of the first computers?
What were the events that drove organizations to fund the creation of the first computers?
I suspect that many readers do not appreciate how long scientific/engineering calculations took before electronic computers became available, or the huge number of clerical staff employed to process the paperwork associated with running any sizeable business.
If somebody wanted to know the logarithm of some value, or the sine/cosine of an angle, they looked up the answer in a table. Individuals owned small booklets of tables supplying some level of granularity and number of significant digits. My school boy booklet contains 60-pages of tables, all to five digits of output accuracy, with logarithm supporting four-digit input values and the sine/cosine/tangent tables having an input granularity of hundredth of a degree.
The values in these tables were calculated by human computers; with the following being among the most well known (for more details, see Calculation and Tabulation in the Nineteenth Century: Airy versus Babbage by Doron Swade, and The History of Mathematical Tables: from Sumer to Spreadsheets edited by Campbell-Kelly, Croarken, Flood, and Robson):
- In 1624 Henry Briggs published logarithms for the integer ranges 1-20,000 and 90,001-100,000 (to 14 decimal places), followed some years later by tables of sine and logarithm of sine; in 1628 Adriaan Vlacq publishing tables that filled in the missing values (to 10 decimal places). In 1783 Jurij Vega published a bug-fixed and extended version of Vlacq’s tables.
In 1827 Charles Babbage (that Babbage) published Table of Logarithms of the Natural Numbers from 1 to 10800. These tables were based on corrected versions of these tables, a rigorous nine-stage proofreading process was followed to prevent new mistakes creeping in.
Today, one person can publish A reconstruction of the tables of Briggs’ Arithmetica logarithmica (1624), with an appendix containing 300 pages of calculated values,
- between 1794 and 1799, Gaspard de Prony employed sixty to eighty computers to calculate the logarithms of the integers from 1 to 200,000 to fifteen significant digits (rounding issues sometimes required calculating 25 decimal digits; published in eighteen volumes). Around 400 man-years.
Logarithms and trigonometric functions are very widely used, creating incentives for investing in calculating and publishing tables. While it may be financially worthwhile investing in producing tables for some niche markets (e.g. Life tables for insurance companies), there is an unmet demand that will only be filled by a dramatic drop in the cost of computing simple expressions.
Babbage’s Difference engine was designed to evaluate polynomial expressions and print the results; perfect for publishing tables. While Babbage did not build a Difference engine, starting in 1837, engines based on Babbage’s design were built and sold commercially by the Swede Per Georg Scheutz.
Mechanical calculators improve accuracy and speed the process up. Vacuum tubes are invented in 1904 and become widely used to process analogue signals. World War II created an urgent demand for the results of a variety of time-consuming calculations, e.g., accurate ballistic tables, and valve computers were built. The plot below shows the cost per million operations for manual, mechanical and valve computers (code+data):
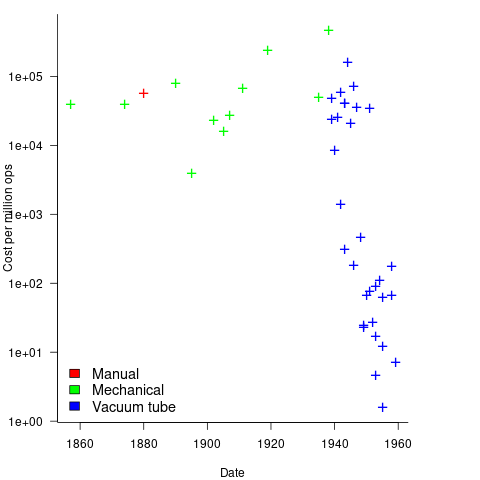
To many observers at the start of the 1950s, the market for electronic computers appeared to be organizations who needed to perform large amounts of scientific/engineering calculation.
Most businesses perform simple calculations on many unrelated values, e.g., banks have to credit/debit the appropriate account when money is deposited/withdrawn. There is no benefit in having a machine that can perform hundreds of calculations per second unless it can be fed data fast enough to keep it busy.
It so happened that, at the start of the 1950s, the US banking system was facing a crisis, the growth in the number of cheques being written meant that it would soon take longer than one day to process all the cheques that arrived in one day. In 1950 Bank of America managed 4.6 million checking accounts, and were opening 23,000 new account per month. Bank of America was then the largest bank in the world, and had a keen interest in continued growth. They funded the development of a bespoke computer system for processing cheques, the ERMA Banking system, which went live in 1959. The plot below shows the number of cheques processed per year by US banks (code+data):
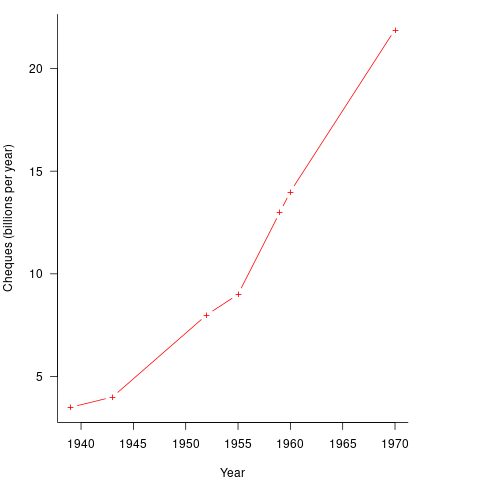
The ERMA system included electronic storage for holding account details, and data entry was speeded up by encoding account details on a magnetic strip included within every cheque.
Businesses are very interested in an integrated combination of input devices plus electronic storage plus compute. There are more commerce oriented businesses than scientific/engineering businesses, and commercial businesses usually have a lot more money to spend, i.e., the real money to be made by selling computers was the business data processing market.
The plot below shows the decreasing cost of hard disc storage (blue, right axis), along with the decreasing computing cost of valve based computers (red, left axis; code+data):
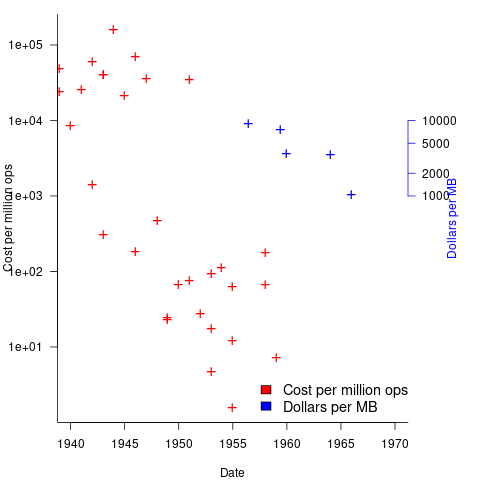
There was a larger business demand to be able to store information electronically, and the hard disc was invented by IBM, roughly 15 years after the first electronic computers.
The very different application demands of data processing and scientific/engineering are reflected in the features supported by the two languages designed in the 1950s, and widely used for the rest of the century: Cobol and Fortran.
Data processing involves simple operations on large quantities of data stored in a potentially huge number of different combinations (the myriad of mechanical point-of-sale terminals stored data in a myriad of different formats, which evolved over time, and the demand for backward compatibility created spaghetti data well before spaghetti code existed). Cobol has extensive functionality supporting the layout and format of input and output data, and simplistic coding constructs.
Scientific/engineering code involves complex calculations on some amount of input. Fortran has extensive functionality supporting program control flow, and relatively basic support for data input/output.
A third major application domain is real-time processing, such as SAGE. However, data on this domain is very hard to find, so it is not discussed.
How did Agile become the product development zeitgeist?
From the earliest days of computing, people/groups have proposed software development techniques, and claiming them to be effective/productive ways of building software systems. Agile escaped this well of widely unknowns to become the dominant umbrella term for a variety of widely used software development methodologies (I’m talking about the term Agile, not any of the multitude of techniques claiming to be the true Agile way). How did this happen?
The Agile Manifesto was published in 2001, just as commercial use of the Internet was going through its exponential growth phase.
During the creation of a new market, as the Internet then was, there are no established companies filling the various product niches; being first to market provides an opportunity for a company to capture and maintain a dominate market share. Having a minimal viable product, for customers to use today, is critical.
In a fast-growing market, product functionality is likely to be fluid until good enough practices are figure out, i.e., there is a lack of established products whose functionality new entrants need to match or exceed.
The Agile Manifesto’s principles of early, continuous delivery, and welcoming of changing requirements are great strategic advice for building products in a new fast-growing market.
Now, I’m not saying that the early Internet based companies were following a heavy process driven approach, discovered Agile and switched to this new technique. No.
I’m claiming that the early Internet based companies were releasing whatever they had, with a few attracting enough customers to fund further product development. Based on customer feedback, or not, support was added for what were thought to be useful new features. If the new features kept/attracted customers, the evolution of the product could continue. Did these companies describe their development process as throw it at the wall and see what sticks? Claiming to be following sound practices, such as doing Agile, enables a company to appear to be in control of what they are doing.
The Internet did more than just provide a new market, it also provided a mechanism for near instantaneous zero cost product updates. The time/cost of burning thousands of CDs and shipping them to customers made continuous updates unrealistic, pre-Internet. Low volume shipments used to be made to important customers (when developing a code generator for a new computer, I sometimes used to receive OS updates on a tape, via the post-office).
The Agile zeitgeist comes from its association with many, mostly Internet related, successful software projects.
While an Agile process works well in some environments (e.g., when the development company can decide to update the software, because they run the servers), it can be problematic in others.
Agile processes are dependent on customer feedback, and making updates available via the Internet does not guarantee that customers will always install the latest version. Building software systems under contract, using an Agile process, only stands a chance of reaping any benefits when the customer is a partner in the same process, e.g., not using a Waterfall approach like the customer did in the Surrey police SIREN project.
Agile was in the right place at the right time.
The 520’th post
This is the 520’th post on this blog, which will be 10-years old tomorrow. Regular readers may have noticed an increase in the rate of posting over the last few months; at the start of this month I needed to write 10 posts to hit my one-post a week target (which has depleted the list of things I keep meaning to write about).
What has happened in the last 10-years?
- I no longer visit libraries, which are becoming coffee shops+wifi hot-spots where people who have librarian in their job title, hot desk; books, they are around here somewhere. I used to regularly visit libraries, particularly while working on my C book. No libraries have so far needed to be visited, for the writing of my evidence-based software engineering book,
- many old manuals, reports, books and magazines became freely available for download, via sites like the Internet Archive, Bitsavers and the Defense Technical Information Center; for second hand books there is AbeBooks. Site like Research Gate, Semantic Scholar and Google Scholar are fantastic sources for more recent work; for new books there is Amazon,
- Github became the place to make source code+stuff available,
- researchers in software engineering started to become interested in evidence-based research. In the UK the CREST Open Workshops were a fantastic series of events; I went to about a third of them, and there were often a couple of gold nuggets per event (a change of funding means running future events will require a lot more work),
- smart phones became the last, next, major software consumer ecosystem (capturing a large percentage of the world’s population means there is no room left for something bigger), and the cloud started on its path to being 99% of the commercial software ecosystem,
- Python joined the short-list to become the world’s primary programming language (assuming that people still run programs outside of the browser). The decline of PERL became very obvious, and work on adding new features to Cobol stopped (work on adding features to Fortran is still going strong),
- known faults are now being automatically fixed by modifying the source code (using genetic programming). This has yet to move out of research, but we all know where it’s going,
- whole program optimization of systems containing millions of lines of code became a viable option for commercial developers (a topic of late night discussion for compiler writers in the 1980s, and perhaps earlier decades, when having more than 64K of memory was treated as nirvana),
- after 20-years of being the only major open source compiler tool-chain, gcc got some serious competition. I originally predicted that llvm would disappear, failing to recognize that Apple were supporting it for licensing reasons,
- the death throes of Moore’s law went from subtle to, isn’t it dead yet?
I probably missed several major events hiding in plain sight, either because I am too close to them or blinkered.
What did not happen in the last 10 years?
- No major new languages. These require major new hardware ecosystems; in the smartphone market Android used Java and iOS made use of existing languages. There were the usual selection of fashion/vanity driven wannabes, e.g., Julia, Rust, and Go. The R language started to get noticed, but it has been around since 1995, and Python looks set to eventually kill it off,
- no accident killing 100+ people has been attributed to faults in software. Until this happens, software engineering has a dead bodies problem,
- the creation of new software did not slow down from its break-neck speed,
- in the first few years of this blog I used to make yearly predictions, which did not happen (most of the time).
Now I can relax for 9.5 years, before scurrying to complete 1,040 posts, i.e., the rate of posting will now resume its previous, more sedate, pace.
Happy 30th birthday to GCC
Thirty years ago today Richard Stallman announced the availability of a beta version of gcc on the mod.compilers newsgroup.
Everybody and his dog was writing C compilers in the late 1980s and early 1990s (a C compiler validation suite vendor once told me they had sold over 150 copies; a compiler vendor has to be serious to fork out around $10,000 for a validation suite). Did gcc become the dominant open source because one compiler would inevitably become dominant, or was there some collection of factors that gave gcc a significant advantage?
I think gcc’s market dominance was driven by two environmental factors, with some help from a technical compiler implementation decision.
The technical implementation decision was the use of RTL as the optimization+code generation strategy. Jack Davidson’s 1981 PhD thesis (and much later the LCC book) describe the gory details. The code generators for nearly every other C compiler was closely tied to the machine being targeted (because the implementers were focused on getting a job done, not producing a portable compiler system). Had they been so inclined Davidson and Christopher Fraser could have been the authors of the dominant C compiler.
The first environment factor was the creation of a support ecosystem around gcc. The glue that nourished this ecosystem was the money made writing code generators for the never ending supply of new cpus that companies were creating (that needed a C compiler). In the beginning Cygnus Solutions were the face of gcc+tools; Michael Tiemann, a bright affable young guy, once told me that he could not figure out why companies were throwing money at them and that perhaps it was because he was so tall. Richard Stallman was not the easiest person to get along with and was probably somebody you would try to avoid meeting (I don’t know if he has mellowed). If Cygnus had gone with a different compiler, they had created 175 host/target combinations by 1999, gcc would be as well-known today as Hurd.
Yes, people writing Masters and PhD thesis were using gcc as the scaffolding for their fancy new optimization techniques (e.g., here, here and here), but this work essentially played the role of an R&D group trying to figure out where effort ought to be invested writing production code.
Sun’s decision to unbundle the development environment (i.e., stop shipping a C compiler with every system) caused some developers to switch to another compiler, some choosing gcc.
The second environment factor was the huge leap in available memory on developer machines in the 1990s. Compiler vendors cannot ship compilers that do fancy optimization if developers don’t have computers with enough memory to hold the optimization information (many, many megabytes). Until developer machines contained lots of memory, a one-man band could build a compiler producing code that was essentially as good as everybody else. An open source market leader could not emerge until the man+dog compilers could be clearly seen to be inferior.
During the 1990s the amount of memory likely to be available in developers’ computers grew dramatically, allowing gcc to support more and more optimizations (donated by a myriad of people targeting some aspect of code generation that they found interesting). Code generation improved dramatically and man+dog compilers became obviously second/third rate.
Would things be different today if Linus Torvalds’ had not selected gcc? If Linus had chosen a compiler licensed under a more liberal license than copyleft, things might have turned out very differently. LLVM started life in 2003 and one of my predictions for 2009 was its demise in the next few years; I failed to see the importance of licensing to Apple (who essentially funded its development).
Eventually, success.
With success came new existential threats, in particular death by a thousand forks.
A serious fork occurred in 1997. Stallman was clogging up the works; fortunately he saw the writing on the wall and in 1999 stepped aside.
Money is what holds together the major development teams supporting gcc and llvm. What happens when customers wanting support for new back-ends dries up, what happens when major companies stop funding development? Do we start seeing adverts during compilation? Chris Lattner, the driving force behind llvm recently moved to Tesla; will it turn out that his continuing management was as integral to the continuing success of llvm as getting rid of Stallman was to the continuing success of gcc?
Will a single mainline version of gcc still be the dominant compiler in another 30 years time?
Time will tell.
Recent Comments