Archive
OSI licenses: number and survival
There is a lot of source code available which is said to be open source. One definition of open source is software that has an associated open source license. Along with promoting open source, the Open Source Initiative (OSI) has a rigorous review process for open source licenses (so they say, I have no expertise in this area), and have become the major licensing brand in this area.
Analyzing the use of licenses in source files and packages has become a niche research topic. The majority of source files don’t contain any license information, and, depending on language, many packages don’t include a license either (see Understanding the Usage, Impact, and Adoption of Non-OSI Approved Licenses). There is some evolution in license usage, i.e., changes of license terms.
I knew that a fair-few open source licenses had been created, but how many, and how long have they been in use?
I don’t know of any other work in this area, and the fastest way to get lots of information on open source licenses was to scrape the brand leader’s licensing page, using the Wayback Machine to obtain historical data. Starting in mid-2007, the OSI licensing page kept to a fixed format, making automatic extraction possible (via an awk script); there were few pages archived for 2000, 2001, and 2002, and no pages available for 2003, 2004, or 2005 (if you have any OSI license lists for these years, please send me a copy).
What do I now know?
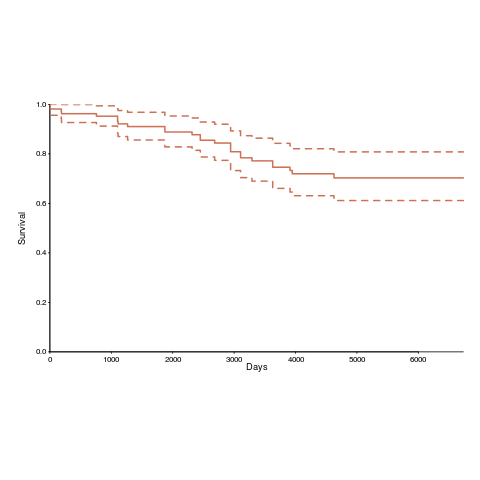
Over the years OSI have listed 110107 different open source licenses, and currently lists 81. The actual number of license names listed, since 2000, is 205; the ‘extra’ licenses are the result of naming differences, such as the use of dashes, inclusion of a bracketed acronym (or not), license vs License, etc.
Below is the Kaplan-Meier survival curve (with 95% confidence intervals) of licenses listed on the OSI licensing page (code+data):
How many license proposals have been submitted for review, but not been approved by OSI?
Patrick Masson, from the OSI, kindly replied to my query on number of license submissions. OSI doesn’t maintain a count, and what counts as a submission might be difficult to determine (OSI recently changed the review process to give a definitive rejection; they have also started providing a monthly review status). If any reader is keen, there is an archive of mailing list discussions on license submissions; trawling these would make a good thesis project 🙂
Learning from some legal decisions
The British and Irish Legal Information Institute provides “Access to Freely Available British and Irish Public Legal Information”. Searching the England and Wales High Court (Technology and Construction Court) Decisions throws up some interesting reading (when searching on software).
For those who have never seen a decent sized project go wrong from the inside, DE BEERS UK LIMITED (Formerly: THE DIAMOND TRADING COMPANY LIMITED) vs. ATOS ORIGIN IT SERVICES UK LIMITED provides a well written example. De Beers contracted Atos to write some software. The development of the software did not go well. Were the original requirements/spec underdone or were subsequent personnel not up to the job? Difficult to tell from the Decision, as is the reason Atos thought they had a chance of winning a court case.
SAP UK LIMITED vs. DIAGEO GREAT BRITAIN LIMITED was a licensing dispute, or more accurately an example of why it is important to check what your third-party software gets up to. Diageo had signed a licensing agreement with SAP and 5,800 Diageo users had used a Salesforce.com app which, unknown to them, made use of SAP. The end result was a bill for £55 million, which Diageo had not been expecting.
There are probably more interesting cases to learn from, but I am supposed to be writing a book in my ‘spare’ time.
Long tail licensing
Team ‘Long Tail Licensing’ (Richard, Pavel, Gary and yours truly) took part in the Fintech startupbootcamp hackathon at the weekend.
As the team name suggests the plan was to implement a system of payment and licensing for products in the long tail, i.e., a large number of low value products. Paypal is good for long tail payment but does not provide a way for third parties to verify that a transaction has occurred (in fact Paypal does its best to keep transactions secret from everybody except those directly involved).
Our example use case was licensing of individual Github repositories. Most of today’s 3.4 million developers with accounts on Github would rather add more features to their code than try to sell it; the 16.7 million repositories definitely qualifies as a long tail of low value products (i.e., under £100). Yes, Paypal could be (and is) used as a method of obtaining payment, but there is no friction-free method for handling licensing (e.g., providing proof of licensing to third parties).
Long Tail Licensing’s implementation used cryptocurrency for both payment and proof of licensing (by storing license information in the blockchain). For the hackathon we set up out own private Bitcoin blockchain to act as a test rig, supply fast mining and provide near instantaneous response.
To use Long Term Licensing a developer creates the file .cryptolicense in the top level directory of their repo; this file contain information on the amount to pay, cryptocurrency account details and text of licensing terms. A link in the README.md file points at our server, which validates the .cryptocurrency file and sets up a payment transaction from the licensee’s Bitcoin wallet; the licensee confirms the transaction and the payment is made.
The developer’s chosen license information is included in the transactions blockchain, providing the paperwork that third-parties can view to verify what has been licensed. This licensing information could be in plain text or use public key encryption to restrict who can read it (e.g., eBay could publish a public key that third parties could encrypt information so that only eBay’s compliance department could read it).
The implementation code includes links to private servers and other stuff that it should not be be; hackathon code is rarely written with security in mind. So those involved would rather it not be pushed to Github (perhaps it will get tidied up and made suitable for public consumption at a later date).
We did not win any of the prizes :-(. Well done to Manoj (a frequent hackathon collaborator) and his team for winning the $100k of Google cloud time prize.
Licensing to decide the result of gcc vs llvm?
I was not surprised to hear today that Nvidia are halting development of their in-house C/C++ compiler and switching to one of the Open Source compilers. It is a lot cheaper to have one or two people looking after a company’s interests in a compiler developed by somebody else than having an in-house development group. It will be interesting to see how much longer Intel continues to fund their in-house compiler.
Nvidia chose llvm and gave a variety of technical reasons why this was the best choice over gcc.
One advantage (from Nvidia’s point of view) not mentioned is that llvm is licensed under a BSD style agreement. This means Nvidia don’t have to release the source code of any modifications or additions they make (they said these will be kept closed source); gcc is licensed under the GNU General Public License which requires source to be released. Arch rivals AMD (well, the ATI bit of AMD that does graphics hardware) also promote llvm, and I’m sure Nvidia does not want to help them in any way.
The licensing difference between gcc and llvm has the potential to make a big difference to the finances of both development teams.
My understanding of gcc funding is that most of it comes from back-end work (i.e., a company pays to have gcc work or do a better job on some [I imagine their] processor). Given a choice, would these companies rather release the source they paid to have written/modified or keep it closed? Some probably don’t care and hope that by making the source available others will help find and fix problems (i.e., there is a benefit to making it available), on the other hand companies introducing processors with fancy new features will want to minimise any technology that competitors can get for free.
In the years to come, it is possible that gcc will loose a significant amount of this back-end income to llvm because of licensing.
PhD projects are the life-blood of new compiler optimization techniques and for many years source code from them has often ended up as the experimental version of a new optimization phase of gcc. Many students are firm believers in making source freely available and shy away from being involved in non-GPL projects. Will this deter them from using llvm in their research (there may be a growing trend favoring llvm over gcc in research, or the llvm people may be better than the gcc folk at marketing {not hard})?
If llvm does not get the new fancy optimizations for ‘free’ they are going to have to spend money doing the implementing themselves or have their performance slowly fall behind that of gcc. Will this cost be more or less than the additional income from closed source customers?
We are unlikely to know the impact that licensing has on the fortunes of both compilers until the end of this decade. Perhaps designing and building a new processor will not be economically worthwhile in 10 years, perhaps all the worthwhile optimizations will be done. We will have to wait and see.
Update 4 Jan 2012: Video (235M) of talk on status of effort to make llvm the default compiler in FreeBSD at LLVM 2011 Developer’s meeting.
Recent Comments