Archive
Is the code reuse problem now solved?
Writing a program to solve a problem involves breaking the problem down into subcomponents that have a known coding solution, and connecting the input/output of these subcomponents into sequences that produced the desired behavior.
When computers first became available, developers had to write every subcomponent. It was soon noticed that new programs contained some functionality that was identical to functionality present in previously written programs, and software libraries were created to reduce development cost/time through reuse of existing code. Developers have being sharing code since the very start of computing.
To be commercially viable, computer manufacturers discovered that they not only had to provide vendor specific libraries, they also had to support general purpose functionality, e.g., sorting and maths libraries.
The Internet significantly reduced the cost of finding and distributing software, enabling an explosion in the quality and quantity of publicly available source code. It became possible to write major subcomponents by gluing together third-party libraries and packages (subject to licensing issues).
Diversity of the ecosystems in which libraries/packages have to function means that developers working in different environments have to apply different glue. Computing diversity increases costs.
A lot of effort was invested in trying to increase software reuse in a very diverse world.
In the 1990 there was a dramatic reduction in diversity, caused by a dramatic reduction in the number of distinct cpus, operating systems and compilers. However, commercial and personal interests continue to drive the creation of new cpus, operating systems, languages and frameworks.
The reduction in diversity has made it cheaper to make libraries/packages more widely available, and reduced the variety of glue coding patterns. However, while glue code contains many common usage patterns, they tend not to be sufficiently substantial or distinct enough for a cost-effective reuse solution to be readily apparent.
The information available on developer question/answer sites, such as Stackoverflow, provides one form of reuse sharing for glue code.
The huge amounts of source code containing shared usage patterns are great training input for large languages models, and widespread developer interest in these patterns means that the responses from these trained models is of immediate practical use for many developers.
LLMs appear to be the long sought cost-effective solution to the technical problem of code reuse; it’s too early to say what impact licensing issues will have on widespread adoption.
One consequence of widespread LLM usage is a slowing of the adoption of new packages, because LLMs will not know anything about them. LLMs are also the death knell for fashionable new languages, which is a very good thing.
Growth in number of packages for widely used languages
These days a language’s ecosystem of add-ons, such as packages, is often more important than the features provided by the language (which usually only vary in their syntactic sugar, and built-in support for some subset of commonly occurring features).
Use of a particular language grows and shrinks, sometimes over very many decades. Estimating the number of users of a language is difficult, but a possible proxy is ecosystem activity in the form of package growth/decline. However, it will take many several decades for the data needed to test how effective this proxy might be.
Where are we today?
The Module Counts website is the home for a project that counts the number of libraries/packages/modules contained in 26 language specific repositories. Daily data, in some cases going back to 2010, is available as a csv 🙂 The following are the most interesting items I discovered during a fishing expedition.
The csv file contains totals, and some values are missing (which means specifying an ‘ignore missing values’ argument to some functions). Some repos have been experiencing large average daily growth (e.g., 65 for PyPI, and 112 for Maven Central-Java), while others are more subdued (e.g., 0.7 for PERL and 3.9 for R’s CRAN). Apart from a few days, the daily change is positive.
Is the difference in the order of magnitude growth due to number of active users, number of packages that currently exist, a wide/narrow application domain (Python is wide, while R’s is narrow), the ease of getting a package accepted, or something else?
The plots below show how PyPI has been experiencing exponential growth of a kind (the regression model fitted to the daily total has the form  , where
, where  is the number of days since 2010-01-01; the red line is the daily diff of this equation), while Ruby has been experiencing a linear decline since late 2014 (all code+data):
is the number of days since 2010-01-01; the red line is the daily diff of this equation), while Ruby has been experiencing a linear decline since late 2014 (all code+data):
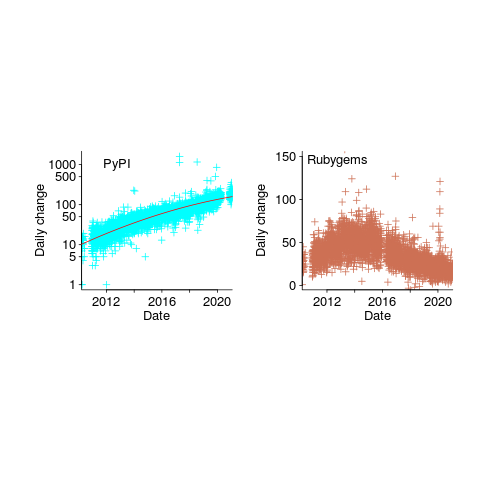
Will the five-year decline in new submissions to Rubygems continue, and does this point to an eventual demise of Ruby (a few decades from now)? Rubygems has years to go before it reaches PERL’s low growth rate (I think PERL is in terminal decline).
Are there any short term patterns, say at the weekly level? Autocorrelation is a technique for estimating the extent to which today’s value is affected by values from the immediate past (usually one or two measurement periods back, i.e., yesterday or the day before that). The two plots below show the autocorrelation for daily changes, with lag in days:
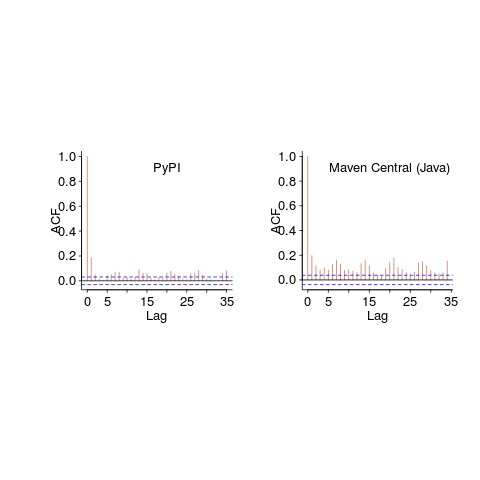
The recurring 7-day ‘peaks’ show the impact of weekends (I assume). Is the larger ”weekend-effect’ for Java, compared to PyPI, due to Java usage including a greater percentage of commercial developers (who tend not to work at the weekend)?
I did not manage to find any seasonal effect, e.g., more submissions during the winter than the summer. But I only checked a few of the languages, and only for a single peak (see code for details).
Another way of tracking package evolution is version numbering. For instance, how often do version numbers change, and which component, e.g., major/minor. There have been a couple of studies looking at particular repos over a few years, but nobody is yet recording broad coverage daily, over the long term 😉
Predicting the future with data+logistic regression
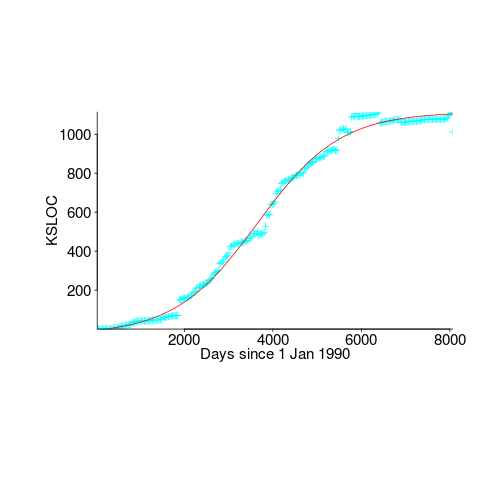
Predicting the peak of data fitted by a logistic equation is attracting a lot of attention at the moment. Let’s see how well we can predict the final size of a software system, in lines of code, using logistic regression (code+data).
First up is the size of the GNU C library. This is not really a good test, since the peak (or rather a peak) has been reached.
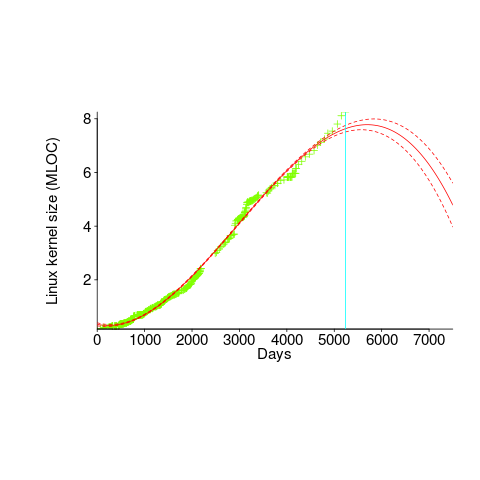
We need a system that has not yet reached an easily recognizable peak. The Linux kernel has been under development for many years, and lots of LOC counts are available. The plot below shows a logistic equation fitted to the kernel data, assuming that the only available data was up to day: 2,900, 3,650, 4,200, and 5,000+ (code+data). Can you tell which fitted line corresponds to which number of days?
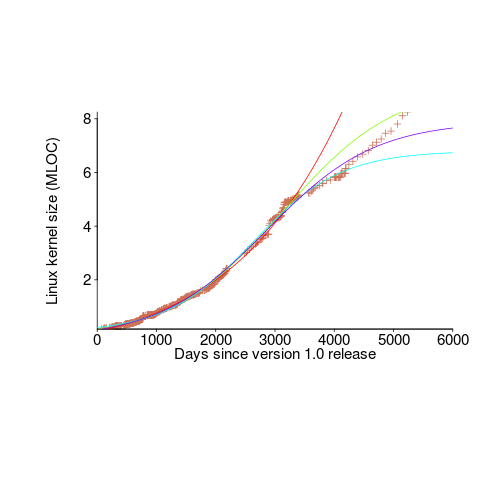
The underlying ‘problem’ is that we are telling the fitting software to fit a particular equation; the software does what it has been told to do, and fits a logistic equation (in this case).
A cubic polynomial is also a great fit to the existing kernel data (red line to the left of the blue line), and this fitted equation can be extended into future (to the right of the blue line); dotted lines are 95% confidence bounds. Do any readers believe the future size of the Linux kernel predicted by this cubic model?
Predicting the future requires lots of data on the underlying processes that drive events. Modelling events is an iterative process. Build a model, check against reality, adjust model, rinse and repeat.
If the COVID-19 experience trains people to be suspicious of future predictions made by models, it will have done something positive.
The 520’th post
This is the 520’th post on this blog, which will be 10-years old tomorrow. Regular readers may have noticed an increase in the rate of posting over the last few months; at the start of this month I needed to write 10 posts to hit my one-post a week target (which has depleted the list of things I keep meaning to write about).
What has happened in the last 10-years?
- I no longer visit libraries, which are becoming coffee shops+wifi hot-spots where people who have librarian in their job title, hot desk; books, they are around here somewhere. I used to regularly visit libraries, particularly while working on my C book. No libraries have so far needed to be visited, for the writing of my evidence-based software engineering book,
- many old manuals, reports, books and magazines became freely available for download, via sites like the Internet Archive, Bitsavers and the Defense Technical Information Center; for second hand books there is AbeBooks. Site like Research Gate, Semantic Scholar and Google Scholar are fantastic sources for more recent work; for new books there is Amazon,
- Github became the place to make source code+stuff available,
- researchers in software engineering started to become interested in evidence-based research. In the UK the CREST Open Workshops were a fantastic series of events; I went to about a third of them, and there were often a couple of gold nuggets per event (a change of funding means running future events will require a lot more work),
- smart phones became the last, next, major software consumer ecosystem (capturing a large percentage of the world’s population means there is no room left for something bigger), and the cloud started on its path to being 99% of the commercial software ecosystem,
- Python joined the short-list to become the world’s primary programming language (assuming that people still run programs outside of the browser). The decline of PERL became very obvious, and work on adding new features to Cobol stopped (work on adding features to Fortran is still going strong),
- known faults are now being automatically fixed by modifying the source code (using genetic programming). This has yet to move out of research, but we all know where it’s going,
- whole program optimization of systems containing millions of lines of code became a viable option for commercial developers (a topic of late night discussion for compiler writers in the 1980s, and perhaps earlier decades, when having more than 64K of memory was treated as nirvana),
- after 20-years of being the only major open source compiler tool-chain, gcc got some serious competition. I originally predicted that llvm would disappear, failing to recognize that Apple were supporting it for licensing reasons,
- the death throes of Moore’s law went from subtle to, isn’t it dead yet?
I probably missed several major events hiding in plain sight, either because I am too close to them or blinkered.
What did not happen in the last 10 years?
- No major new languages. These require major new hardware ecosystems; in the smartphone market Android used Java and iOS made use of existing languages. There were the usual selection of fashion/vanity driven wannabes, e.g., Julia, Rust, and Go. The R language started to get noticed, but it has been around since 1995, and Python looks set to eventually kill it off,
- no accident killing 100+ people has been attributed to faults in software. Until this happens, software engineering has a dead bodies problem,
- the creation of new software did not slow down from its break-neck speed,
- in the first few years of this blog I used to make yearly predictions, which did not happen (most of the time).
Now I can relax for 9.5 years, before scurrying to complete 1,040 posts, i.e., the rate of posting will now resume its previous, more sedate, pace.
Dead trees have been replaced by a paywall
Every now and again I see a reference to that looks like an interesting paper that was published before the Internet age (i.e., pre last 90’s and not available for free download). I keep a list of such references and when I am near a university with a good library I stop off to look them up; unless there is an urgent need this is very much a background task and before last week my last such visit was over three years ago.
Last week I dropped by Reading University, where I sourced much of the non-Internet available papers for my last book. The picture below illustrates what I found, periodicals are being removed to make way for desktop space, so students can sit typing away on keyboards.

I imagine the librarian is under pressure to maximise the efficient use of his large building and having row upon row of journals, many older than most of the students, just sitting there waiting for somebody like me wanting to look at perhaps a dozen or so of them cannot be said to be that efficient.
Everything is going digital, the library catalog was full of references to where journals could be found online. The problem is that the digital content is licensed to the University and only available to members of the University (e.g., students and lecturers). Without a logon id the journals are unavailable to non-academic users. Reading are continuing their open policy to external users by offering guest accounts (“where licence conditions permit”, I will find out what is available on my next visit).
Those readers who don’t have much interaction with the academic world may not be aware of the very high rates many publishers charge for access to published papers (that are provided to them free by academics) or the large profits made by these publishers.
Academics are starting to react against the high cost of journal subscription; I’m please to see that a boycott is gathering steam.
Boycotts are very well meaning, but I suspect that most academics will continue to keep their head down and go with existing practice (young academics need to get papers published in established to move up in their world).
We the tax payers are funding the research that discovers the information needed to write a paper and paying the salaries of academics to write the papers. Why are we the tax payers providing money to university libraries to subscribe to journals whose contents we have paid to create? If the research is tax payer funded we should not have to pay to see the results.
How do we remove the paywall that currently surrounds much published research? As I see it the simplest solution is to stop providing the funding that university libraries use to pay for journal subscriptions. Yes this will cause disruption, but the incentives are for most academics to continue with the current system and or course no company is ever willing to give up on a cash cow.
What can you do? If you are in the UK you can write to your MP to make him/her aware of your views. If readers have any other ideas please make use of the comments to tell others.
What language was an executable originally written in?
Apple have recently added an unusual requirement to the iPhone developer agreement “Applications must be originally written in Objective-C, C, C++, or JavaScript …”. As has been pointed out elsewhere the real purpose is stop third party’s from acquiring any control over application development on Apple’s products; the banning of other languages is presumably regarded as acceptable collateral damage.
Is it possible to tell by analyzing an executable what language it was originally written in?
There are two ways in which executables contain source language ‘signatures’. Detecting these signatures requires knowledge of specific compiler behavior, i.e., a database of information about the behavior of compilers capable of creating the executables is needed.
Runtime library. Most compilers make use of a language specific runtime library, rather than generating inline code for some kinds of functionality. For instance, setjmp/longjmp in C and vtables in C++.
The presence of a known C runtime library does not guarantee that the application was originally written in C; it could have been written in Java and converted to C source.
The absence of a known C runtime library could mean that the source was compiled by a C compiler using a runtime system unknown to the analyzer.
The presence of a known Java, for instance, runtime library would suggest that the original source contained some Java. This kind of analysis would obviously require that the runtime library database not restrict itself to the ‘C’ languages.
Compiler behavior patterns. There is usually more than one way in which a source language construct can be translated to machine code and a compiler has to pick one of them. The perfect optimizing compiler would always make the optimal choice, but real compilers follow a fixed pattern of code generation for at least some language constructs (e.g., initialization of registers on function entry).
The presence of known code patterns in an executable is evidence that a particular compiler has been used; how much depends on the likelihood it could have been generated by other means and how many other patterns suggest the same compiler. In the case of the GNU Compiler Collection the source language might also be Fortran, Java or Ada; I don’t know enough about the behavior of GCC to provide an informed estimate of whether it is possible to recognize the source language from the translated form of constructs shared by several languages, I suspect not.
The fact that an executable can be decompiled to C is not a guarantee that it was originally written in C.
Some languages support source language constructs whose corresponding machine code is unlikely to ever be generated by source from another language. The Fortran computed goto allows constructs to be written that have no equivalent in the other languages supported by GCC (none of them allow statement labels appearing in a multi-way jump to appear before the jump test):
10 I=I+1 20 J=J+1 goto (10, 20, 30, 40) J 30 I=I+3 40 I=I*2 |
The presence of a compiled form of this kind of construct in the executable would be very suggestive of Fortran source.
Apple are famously paranoid and control freakery. It will be very interesting to see what level of compliance checking they decide to perform on executables submitted to the App Store.
On another note: What does “originally written” mean? For instance, many of the mathematical functions (e.g., sine, log, gamma, etc) contained in R were originally written in Fortran and translated to C for use in R; this C source is what is now maintained. Does this historical implementation decision mean that R cannot be legally ported to the iPhone?
Recent Comments