Archive
4,000 vs 400 vs 40 hours of software development practice
What is the skill difference between professional developers and newly minted computer science graduates?
Practice, e.g., 4,000 vs. 400 hours
People get better with practice, and after two years (around 4,000 hours) a professional developer will have had at least an order of magnitude more practice than most students; not just more practice, but advice and feedback from experienced developers. Most of these 4,000 hours are probably not the deliberate practice of 10,000 hours fame.
It’s understandable that graduates with a computing degree consider themselves to be proficient software developers; this opinion is based on personal experience (i.e., working with other students like themselves), and not having spent time working with professional developers. It’s not a joke that a surprising number of academics don’t appreciate the student/professional difference, the problem is that some academics only ever get to see a limit range of software development expertise (it’s a question of incentives).
Surveys of student study time have found that for Computer science, around 50% of students spend 11 hours or more, per week, in taught study and another 11 hours or more doing independent learning; let’s take 11 hours per week as the mean, and 30 academic weeks in a year. How much of the 330 hours per year of independent learning time is spent creating software (that’s 1,000 hours over a three-year degree, assuming that any programming is required)? I have no idea, and picked 40% because it matched up with 4,000.
Based on my experience with recent graduates, 400 hours sounds high (I have no idea whether an average student spends 4-hours per week doing programming assignments). While a rare few are excellent, most are hopeless. Perhaps the few hours per week nature of their coding means that they are constantly relearning, or perhaps they are just cutting and pasting code from the Internet.
Most graduates start their careers working in industry (around 50% of comp sci/maths graduates work in an ICT profession; UK higher-education data), which means that those working in industry are ideally placed to compare the skills of recent graduates and professional developers. Professional developers have first-hand experience of their novice-level ability. This is not a criticism of computing degrees; there are only so many hours in a day and lots of non-programming material to teach.
Many software developers working in industry don’t have a computing related degree (I don’t). Lots of non-computing STEM degrees give students the option of learning to program (I had to learn FORTRAN, no option). I don’t have any data on the percentage of software developers with a computing related degree, and neither do I have any data on the average number of hours non-computing STEM students spend on programming; I’ve cosen 40 hours to flow with the sequence of 4’s (some non-computing STEM students spend a lot more than 400 hours programming; I certainly did). The fact that industry hires a non-trivial number of non-computing STEM graduates as software developers suggests that, for practical purposes, there is not a lot of difference between 400 and 40 hours of practice; some companies will take somebody who shows potential, but no existing coding knowledge, and teach them to program.
Many of those who apply for a job that involves software development never get past the initial screening; something like 80% of people applying for a job that specifies the ability to code, cannot code. This figure is based on various conversations I have had with people about their company’s developer recruitment experiences; it is not backed up with recorded data.
Some of the factors leading to this surprisingly high value include: people attracted by the salary deciding to apply regardless, graduates with a computing degree that did not require any programming (there is customer demand for computing degrees, and many people find programming is just too hard for them to handle, so universities offer computing degrees where programming is optional), concentration of the pool of applicants, because those that can code exit the applicant pool, leaving behind those that cannot program (who keep on applying).
Apologies to regular readers for yet another post on professional developers vs. students, but I keep getting asked about this issue.
Where are we with models of human learning?
Learning is an integral part of writing software. What have psychologists figured out about the characteristics of human learning?
A study of memory, published in 1885, kicked off the start of modern psychology research. At the start of the 1900s, learning research was still closely tied to the study of the characteristics of what we now call working memory, e.g., measuring the time taken for subjects to correctly recall sequences of digits, nonsense syllables, words and prose. By the 1930s, learning was a distinct subject in its own right.
What is now known as the power law of learning was first proposed in 1926. Wikipedia is right to use the phrase power law of practice, since it is some measure of practice that appears in the power law of learning equation:  , where:
, where:  is the time taken to do the task,
is the time taken to do the task, is some measure of practice (such as the number of times the subject has performed the task), and
is some measure of practice (such as the number of times the subject has performed the task), and  ,
,  , and
, and  are constants fitted to the data.
are constants fitted to the data.
For the next 70 years some form of power law did a good job of fitting the learning data produced by researchers. Then in 1997 a paper pointed out that researchers were fitting aggregate data (i.e., one equation fitted to all subject data), and that an exponential equation was a better fit to individual subject response times:  . The power law appeared to be the result of aggregating the exponential response performance of multiple subjects; oops.
. The power law appeared to be the result of aggregating the exponential response performance of multiple subjects; oops.
What is the situation today, 25 years later? Do the subsystems of our brains produce a power law or exponential improvement in performance, with practice?
The problem with answering this question is that both equations can fit the available data quite well, with one being a technically better fit than the other for different datasets. The big difference between the two equations is in their tails, however, it is costly and time-consuming to obtain enough data to distinguish between them in this region.
When discussing learning in my evidence-based software engineering book, I saw no compelling reason to run counter to the widely cited power law, but I did tell readers about the exponential fit issue.
Studies of learnings have tended to use simple tasks; subjects are usually only available for a short time, and many task repetitions are needed to model the impact of learning. Simple tasks tend to be dominated by one primary activity, which means that subjects can focus their learning on this one activity.
Complicated tasks involve many activities, each potentially providing distinct learning opportunities. Which activities will a subject focus on improving, will the performance on one activity improve faster than others, will the approach chosen for one activity limit the performance on a second activity?
For a complicated task, the change in performance with amount of practice could be a lot more complicated than a single power law/exponential equation, e.g., there may be multiple equations with each associated with one or more activities.
In the previous paragraph, I was careful to say “could be a lot more complicated”. This is because the few datasets of organizational learning show a power law performance improvement, e.g., from 1936 we have the most cited study Factors Affecting the Cost of Airplanes, and the less well known but more interesting Liberty shipbuilding from the 1940s.
If the performance of something involving multiple people performing many distinct activities follows a power law improvement with practice, then the performance of an individual carrying out a complicated task might follow a simple equation; perhaps the combined form of many distinct simple learning activities is a simple equation.
Researchers are now proposing more complicated models of learning, along with fitting them to existing learning datasets.
Which equation should software developers use to model the learning process?
I continue to use a power law. The mathematics tend to be straight-forward, and it often gives an answer that is good enough (because the data fitted contains lots of variance). If it turned out that an exponential would be easier to work with, I would be happy to switch. Unless there is a lot of data in the tail, the difference between power law/exponent is usually not worth worrying about.
There are situations where I have failed to successfully add a learning (power law) component to a model. Was this because there was no learning present, or was the learning not well-fitted by a power law? I don’t know, and I cannot think of an alternative equation that might work, for these cases.
Learning useful stuff from the Cognitive capitalism chapter of my book
What useful, practical things might professional software developers learn from the Cognitive capitalism chapter in my evidence-based software engineering book?
This week I checked the cognitive capitalism chapter; what useful things did I learn (combined with everything I learned during all the other weeks spent working on this chapter)?
Software systems are the product of cognitive capitalism (more commonly known as economics).
My experience is that most software developers don’t know anything about economics, so everything in this chapter is likely to be new to them. The chapter is more tutorial like than the other chapters.
Various investment models are discussed. The problem with these kinds of models is obtaining reliable data. But, hopefully the modelling ideas will prove useful.
Things I learned about when writing the chapter include: social learning, group learning, and Open source licensing is a mess.
Building software systems usually requires that many of the individuals involved to do lots of learning. How do people decide what to learn, e.g., copy others or strike out on their own? This problem is not software specific, in fact social learning appears to be one of the major cognitive abilities that separates us from other apes.
Organizational learning and forgetting is much talked about, and it was good to find some data dealing with this. Probably not applicable to most people.
Open source licensing is a mess in that software containing a variety of, possible incompatible, licenses often gets mixed together. What future lawsuits await?
For me, potentially the most immediately useful material was group learning; there are some interesting models for how this sometimes works.
Readers might have a completely different learning experience from reading the cognitive capitalism chapter. What useful things did you learn from the cognitive capitalism chapter?
Impact of group size and practice on manual performance
How performance varies with group size is an interesting question that is still an unresearched area of software engineering. The impact of learning is also an interesting question and there has been some software engineering research in this area.
I recently read a very interesting study involving both group size and learning, and Jaakko Peltokorpi kindly sent me a copy of the data.
That is the good news; the not so good news is that the experiment was not about software engineering, but the manual assembly of a contraption of the experimenters devising. Still, this experiment is an example of the impact of group size and learning (through repeating the task) on time to complete a task.
Subjects worked in groups of one to four people and repeated the task four times. Time taken to assemble a bespoke, floor standing rack with some odd-looking connections between components was measured (the image in the paper shows something that might function as a floor standing book-case, if shelves were added, apart from some component connections getting in the way).
The following equation is a very good fit to the data (code+data). There is theory explaining why ") applies, but the division by group-size was found by suck-it-and-see (in another post I found that time spent planning increased with teams size).
applies, but the division by group-size was found by suck-it-and-see (in another post I found that time spent planning increased with teams size).
There is a strong repetition/group-size interaction. As the group size increases, repetition has less of an impact on improving performance.
![time = 0.16+ 0.53/{group size} - log(repetitions)*[0.1 + {0.22}/{group size}]](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_981.5_b0d171bba046801a68ce5dc8ae1d6115.png "time = 0.16+ 0.53/{group size} - log(repetitions)*[0.1 + {0.22}/{group size}]")
The following plot shows one way of looking at the data (larger groups take less time, but the difference declines with practice), lines are from the fitted regression model:
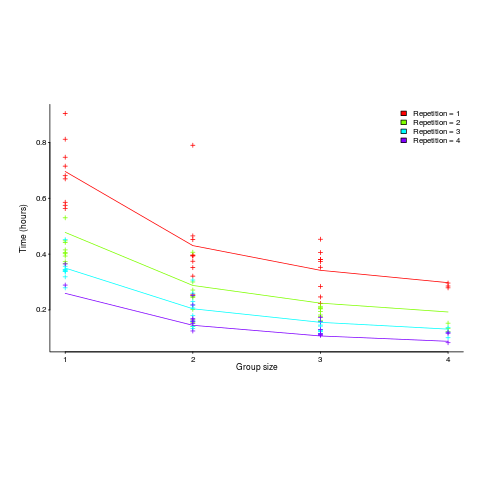
and here is another (a group of two is not twice as fast as a group of one; with practice smaller groups are converging on the performance of larger groups):
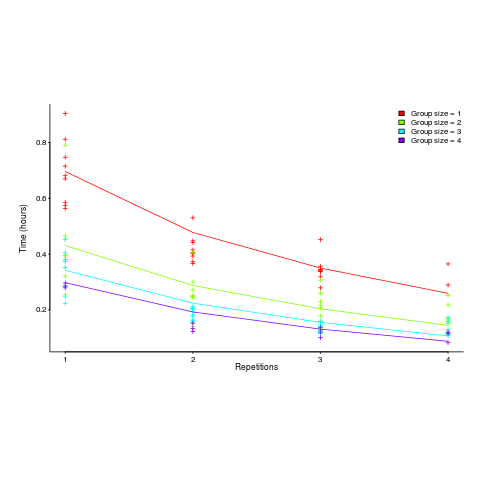
Would the same kind of equation fit the results from solving a software engineering task? Hopefully somebody will run an experiment to find out 🙂
Undergraduates and learning to program
I last looked at the research on teaching programming around 10 years ago and I have been catching up with what has been going on; in brief: same old, same old. One of the best papers on the subject is still: Language-independent conceptual “Bugs”
The research activity is still focused on making the tools and language ‘better’. There is a defining silence on the possibility that those doing the teaching could not teach their way out of a paper bag. Nobody is brave enough to suggest that teacher training might be a worthwhile investment, or that lectures oriented to what is useful (rather than what the lecturer finds interesting) would be appreciated by students.
I have always thought that researching the teaching of programming had no practical purpose, other than possibly helping universities increase the number of students graduating with computing degrees (some universities are solving the problem students have with programming by offering degrees that don’t involve being able to program). I still think that teaching programming to school children is at best a waste of time.
My experience with students learning to program is from a very long time ago. The process involved listening to confusing and disjoint lectures, reading books and figuring out what worked by trial and error. Students were not taught to program, they got thrown in at the deep and were expected to survive. Anybody who could handle this stood some chance of being able to handle developing software in the ‘real world’; universities were (accidentally) graduating people with the skills industry needed. However, these days universities are supposed to be customer focused, what industry needs is irrelevant (my experience of sitting on departmental industry panels is that the head of department tells us what they are thinking of doing {i.e., new courses for which there will be lots of paying students} and we try to talk him/her out of the sillier ideas); too many fee paying students find programming too hard, let’s offer computing degrees that don’t require any programming has been the only workable solution to-date.
Would you hire a recent graduate, for a development role, who had trouble figuring out how to fix syntax errors in their code? Surely, the minimum requirement is somebody who gets some pleasure from coding, even if they don’t want to spend lots of time doing it.
There is a shortage of software developers and flying turkeys are still with us.
Learning a cpu’s instruction set
A few years ago I wrote about the possibility of secret instruction sets making a comeback and the minimum information needed to write a code generator. A paper from the sporadic (i.e., they don’t release umpteen slices of the same overall paper), but always interesting, group at Stanford describes a tool that goes a long way to solving the secret instruction set problem; stratified synthesis learns an instruction set, starting from a small set of known instructions.
After feeding in 51 base instructions and 11 templates, 1,795.42 instruction ‘formulas’ were learned (119.42 were 8-bit constant instructions, every variant counted as 1/256 of an instruction); out of a maximum of 3,683 possible instructions (depending on how you count instructions).
As well as discovering ‘new’ instructions, they also discovered bugs in the Intel 64 and IA-32 Architectures Software Developer Manuals. In my compiler writing days, bugs in cpu documentation were a pet hate (they cause huge amounts of time to be wasted).
The initial starting information used is rather large, from the perspective of understanding the instruction set of an unknown cpu. I’m sure others will be working to reduce the necessary startup information needed to obtain useful results. The Intel Management Engine is an obvious candidate for investigation.
Vendors sometimes add support for instructions without publicizing them and sometimes certain bit patterns happen to do something sensible in a particular version of a design because some random pattern of bits happens to do whatever it does without being treated as an illegal opcode. Your journey down the rabbit hole starts here.
On a related note, I continue to be amazed that widely used disassemblers fail to correctly handle surprisingly many, documented, x86 opcodes; benchmarks from 2010 and 2016
Power law of practice in software implementation
People get better with practice. The power law of practice specifies  , where:
, where:  is the response time, the amount of practice and , and are constants. However, sometimes an exponential equation is a better fit for to the data:
is the response time, the amount of practice and , and are constants. However, sometimes an exponential equation is a better fit for to the data: } + c") . There are theoretical reasons for liking a power law (e.g., it can be derived from the chunking of information), but it is difficult to argue with the exponential fitting so much data better than a power law.
. There are theoretical reasons for liking a power law (e.g., it can be derived from the chunking of information), but it is difficult to argue with the exponential fitting so much data better than a power law.
The plot below, from a study by Alteneder, shows the time taken to solve the same jig-saw puzzle, for 35 trials (red); followed by a two week pause and another 35 trials (in blue; if anybody else wants to try this, a dedicated weekend should be long enough to complete over 20 trials). The lines are fitted power law and exponential equations (code+data). Can you tell which is which?
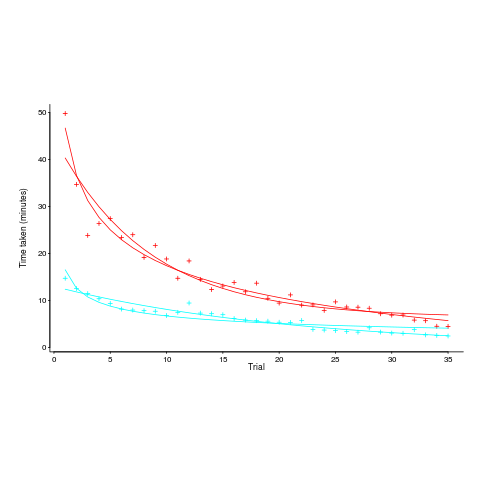
To find out if the same behavior occurs with software we need data on developers implementing the identical applications multiple times. I know of two experiments where the same application has been implemented multiple times by the same people, and where the data is available. Please let me know if you know of any others.
Zislis timed himself implementing 12 algorithms from the CACM collection in each of three languages, iterating four times (my copy came from the Purdue library, which as I write this is not listing the report). The large number of different programs implemented, coupled with the use of multiple languages, makes it difficult to separate out learning effects.
Lui and Chan ran an experiment where 24 developers (8 pairs {pair programming} and 8 singles) implemented the same application four times. The plot below shows the time taken to complete each implementation (singles top, pairs bottom, with black cross showing predictions made by a power law fit).
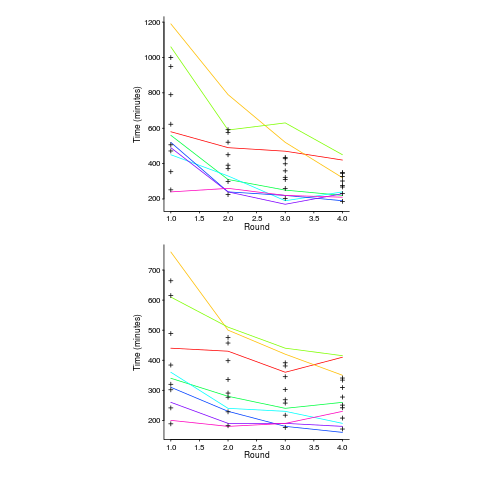
Different subjects start the experiment with different amounts of ability and past experience. Before starting, subjects took a multiple choice test of their knowledge. If we take the results of this test as a proxy for the ability/knowledge at the start of the experiment, then the power law equation becomes (a similar modification can be made to the exponential equation):
^{-b} + c")
That is, the test score is treated as equivalent to performing some number of rounds of implementation). A power law is a better fit than exponential to this data (code+data); the fit captures the general shape, but misses lots of what look like important details.
The experiment was run over successive weekends. So there was opportunity for some forgetting to occur during the week days, and the amount forgotten will vary between people. It is easy to think of other issues that could have influenced subject performance.
This experiment must rank as one of the most interesting software engineering experiments performed to date.
Does native R usage exist?
Note to R users: Users of other languages enjoy spending lots of time discussing the minutiae of the language they use, something R users don’t appear to do; perhaps you spend your minutiae time on statistics which I don’t yet know well enough to spot when it occurs). There follows a minutiae post that may appear to be navel-gazing to you (interesting problem at the end though).
In various posts written about learning R I have said “I am trying to write R like a native”, which begs the question what does R written by a native look like? Assuming for a moment that ‘native R’ exists (I give some reasons why it might not below) how…
To help recognise native R it helps to start out by asking what it is not. Let’s start with an everyday analogy; if I listen to a French/German/American person speaking English I can usually tell what country they are from, they have patterns of usage that we in merry England very rarely, if ever, use; the same is true for programming languages. Back in the day when I spent several hours a day programming in various languages I could often tell when somebody showing me some Pascal code had previously spent many years writing Fortran or that although they were now using Fortran they had previously used Algol 60 for many years.
If expert developers can read R source and with high accuracy predict the language that its author previously spent many years using, then the source is not native R.
Having ruled out any code that is obviously (to a suitably knowledgeable person) not native R, is everything that is left native R? No, native language users share common characteristics; native speakers recognize these characteristics and feel at home. I’m not saying these characteristics are good, bad or indifferent any more than my southern English accent is better/worse than northern English or American accents; it is just the way people around here speak.
Having specified what I think is native R (I would apply the same rules to any language) it is time to ask whether it actually exists.
I’m sure there are people out there whose first language was R and who have spent a lot more time using R over, say, five years rather than any other language. Such people are unlikely to have picked up any noticeable coding accents from other languages and so can be treated as native.
Now we come to the common characteristics requirement, this is where I think an existence problem may exist.
How does one learn to use a language fluently? Taking non-R languages I am familiar with the essential ingredients seem to be:
- spending lots of time using the language, say a couple of hours a day for a few years
- talking to other, heavy, users of the language on a daily basis (often writing snippets of code when discussing problems they are working on),
- reading books and articles covering language usage.
I am not saying that these activities create good programmers, just that they result in language usage characteristics that are common across a large percentage of the population. Talking and reading provides the opportunity to learn specific techniques and writing lots of code provides the opportunity to make use these techniques second nature.
Are these activities possible for R?
- I would guess that most R programs are short, say under 150 lines. This is at least an order of magnitude shorter (if not two or three orders of magnitude) than program written in Java/C++/C/Fortran/etc. I know there are R users out there who have been spending a couple of hours a day using R over several years, but are they thinking about R coding or think about the statistics and what the data analysis really means. I suspect they are spending most of this R-usage thinking time on the statistics and data analysis,
- I can easily imagine groups of people using R and individuals having the opportunity to interact with other R users (do they talk about R and write snippets of code to describe their problem? I don’t work in an R work environment, so I don’t know the answer),
- Where are the R books and articles on language usage? They don’t exist, not in the sense of Sutter’s “Effective C++: 55 Specific Ways to Improve Your Programs and Designs” (there must be a several dozen of this kind of book for C++) Bloch’s “Java Puzzlers: Traps, Pitfalls, and Corner Cases” (probably only a handful for Java) and Koenig’s “C: Traps and Pitfalls” (again a couple of dozen for C). In places Crawley’s “The R Book” has the feel of this kind of book, but Matloff’s “The Art of R Programming” is really an introduction to R for people who already know another language (no discussion of art of R as such). R users write about statistics and data analysis, with the language being a useful tool.
I suspect that many people are actually writing R for short amounts of time to solve data analysis problems they spend a lot of time thinking about; they don’t discuss R the language much (so little opportunity to learn about the techniques that other people use) and they don’t write much code (so little opportunity to try out many new techniques).
Yes, there may be a few people who do spend a couple of hours a day thinking about R the language and also get to write lots of code, these people are more like high priests than your average user.
For the last two years I have been following a no for-loops policy in an attempt to make myself write R how the natives write it. I am beginning to suspect that this view of native R is really just me imposing beliefs from usage of other language that support whole vector/array operations, e.g., APL.
I encountered the following coding problem yesterday. Do you think the non-loop version should be how it is done in R or is the loop version more ‘natural’?
Given a vector of ordered items the problem is to count the length of each subsequence of identical items,
a,a,a,b,b,a,c,c,c,c,b,c,c |
output
a 3 b 2 a 1 c 4 b 1 c 2 |
Non-looping version (looping version is easy to figure out):
subseq_len=function(feature) { r_shift=c(feature[1], feature) l_shift=c(feature, ",,,") # pad with something that will not match # Where are the boundaries between subsequences? boundary=(l_shift != r_shift) sum_matches=cumsum(!boundary) # Difference of cumulative sum at boundaries, whose value will # be off by 1 and we need to handle 'virtual' start of list at 1. t=sum_matches[boundary] seq_len=1+c(t, 0)-c(1, t) # Remove spurious value return(cbind(feature[boundary[-1]], seq_len[-length(seq_len)])) } subseq_len(c("a", "a", "b", "b", "e", "c", "c", "c", "a", "c", "c")) |
Proposal for a change of approach to programming language teaching
In a previous post I explained why I think developers don’t really know any computer language, and in this post I want to outline how I think we should adapt to this reality and radically change the approach taken to teaching students about using a computer language. First, a couple of points:
- The programming community needs to change its attitude towards language knowledge from being an end in itself to being something that is ok to acquire on an as needed basis. Developers don’t need to know much about the programming language they use in order to get their job done, get over it. Spending time learning the ins and outs of a language’s semantics rarely provides a worthwhile return on investment compared to time spent learning something else, such as the application domain or customer requirements,
- designing a new, ‘simpler’ programming language is not a solution; the existing languages in common use are not going away anytime soon and creating a new general purpose language is only going to overload developers with more stuff to learn and yet another runtime system to interface to,
- we need to concentrate on suggestions about what students and developers should be doing and not what they should not be doing. This is not only a good teaching principle it avoids the problem of having to come up with a good list of things not to do (coding standard recommendations are very rarely based on any evidence apart from the proposers own point of view and even the ones that make it through peer review are little more than group think or a waste of time).
The response to the existing state of affairs should be to approach the teaching of programming languages as an exercise in teaching students only what they need to know to do useful work, rather than acting on the belief that students should strive to be experts in the language they use and burdening them with lots of pointless language details. The exact minimum-set of knowledge could vary across different industries and application domains, so the set might need to be a bit larger than the minimum to be on the safe side.
Invariably some developers will need to know more than the minimum-set, so we also need to figure out what ‘template’ knowledge (or whatever term is used, an alternative is behavior patterns or patterns of behavior) should be included in the next level of language knowledge, this can be documented and made available to anybody who wants to read it; there may or may not be more levels before a developer is told to go and read a reference book or the language reference manual to figure out what they need to know.
This is minimum-set approach, with the opportunity to progress to successively more detailed levels, is often used for learning human languages, computer languages are not any different.
I would expect there to be some variation in the minimum-set between different languages, and would resist the temptation to try and create a ‘common minimum’ until some experience had been gained in teaching single languages.
How would the minimum-set of language knowledge be chosen? Simple. Students need to learn those construct they are likely to use most of the time, and that question can be answered by measuring a large amount of existing source code. Results from measurements that have been made typically show a small number of constructs are used a large percentage of the time. For instance, measurements of C source find that the 33.2% of for-loops have the form: for (assignment ; identifier < identifier ; identifier++), where identifier might be two or more different identifiers; allowing the central test to have the form identifier < expression takes the percentage to over 50%. I would expect the same pattern of usage to occur in source written in other languages but don't have any number to back up that assertion.
Perhaps the most important pattern of (developer) behavior is what its discoverer, Jorma Sajaniemi, calls the roles of variables (each variable is used to hold a particular kind of information, e.g., most wanted holder, stepper, container, etc).
One pattern of behavior that I am more or less completely in the dark about is class/package usage. There is the famous book on design patterns which the authors did a good job of promoting, but I have yet to see any empirical evidence showing the claimed benefits. The analysis of class/package behavioral usage is non-trivial, but it can be done.
Would I insist that developers only use constructs list in the suggested minimum-set (plus possible extras)? No. The purpose of this proposal is to help students and developers learn what they need to know to get a job done. Figuring out what language constructs, if any, should be avoided at all costs is a very tough problem which at the end of the day might not be worth solving.
A minimum-set knowledge of the language being used does not imply poor quality code. Most code is simple anyway, the complicated stuff invariably revolves around the algorithms that need to be used, and a skillful developer is one who uses straightforward language constructs to create easy to maintain code, not one who writes code that relies on detailed knowledge of some language feature.
I expect this proposal to adopt a minimum-set approach to language teaching will draw an angry reaction from the cottage industry that makes its living from writing and giving seminars on the latest trends in language-X. Don't panic guys, managers are well aware that this kind of knowledge rarely has any impact of developer performance and the actual motivation for sending employees on such seminars is to keep them happy (it can be a much more effective way of keeping staff than simply giving them a pay rise).
Recent Comments