Archive
Zig is the next fashionable language
New programming languages are constantly being created, with most remaining unknown outside a small circle of friends. Every 5-10 years or so, a few of these languages break out to become fashionable to use. In the early 1980s, I was a fan of Pascal and had conversations with developers trying to figure out why they were fans of C. Yes, C was once the fashionable language to talk about. One of these languages went on to be used almost everywhere, while the other had the common fate of fading into obscurity.
Fashion serves a purpose. People, not just developers, enjoy experimenting, feel a need for self-expression, with a “fresh start” making them feel new and energized. Following fashion provides a means of fulfilling these desires. Developers who don’t need to earn a living using established languages are able to invest their time being part of the growing community of the current fashionable language.
Over the last 5-10 years Rust and Go were fashionable languages, with Julia being part of the trend vibe for a few years in the mid 2010s.
This last year, I have noticed a significant decline in articles extolling Go and meeting developers using it. In the last 6 months, I have seen a marked growth in criticism of Rust (very slow compilation speed in particular).
Fashion requires change and reinvention, because widespread use ruins its specialness. When Rust is no longer perceived to be fashionable (I think Go is already at this point), a new language will be ‘chosen’ to fill the void. Which languages are the likely candidates?
For some time, I have been telling people that my candidate language is Zig. My original whimsical reason was that very few programming languages have names starting with letters near the end of the alphabet (the preponderance of language names start with a letter near the beginning).
Experience has taught me that technical merits have little to do with language choice, clearly illustrated by the wide use of PHP and JavaScript.
A necessary condition for a language to become fashionable is that it be usable on the widely available software development platforms of the day (which is how PHP and JavaScript catapulted their user growth), another is that there be at least one core developer generally available to respond to user questions. The first condition provides something to use, and the second the basis for a welcoming community.
New languages are created on a regular basis by PhD students, but these implementations are a means to an end, i.e., publishing papers about some technique. There might be something to use, but rarely a welcoming community.
Andrew Kelley, the creator of Zig and president of the Zig foundation, quit his job in 2018 to work full-time on Zig. Andrew has put a lot of effort into building a community and raising funds to hire people.
Doing all the necessary things is not enough, there is luck and timing is important. The start date for Zig is four years after the start date for Rust. Not long enough for Rust to become unfashionable and need a replacement. However, seven years after leaving his job, Andrew is still working on Zig. Persistence is also an important success factor.
While I don’t actively follow Zig, I do visit sites where fringe languages are regularly discussed. Over the last six months, there has been a noticeable increase in Zig related discussions, and somebody has written a Zig book. Given that Zig related discussions are uncommon, this uptick may just be noise.
To me, Zig looks ready to go, and also has an appealing backstory (i.e., created by a lone developer working hard over many years) that contrasts with the Rust/Go perceived backstory (i.e., created in the bowls of an, not at the time, ‘evil’ corporation). I have not seen any other contenders for the next fashionable language.
Will LLMs cause fashionable languages to stop being a thing? Perhaps in the long term, or perhaps a new criterion for being fashionable will be not-known to LLMs. At the moment, developers are very aware of the failing of LLM code generation. In the short term, I think that fashionable languages will remain a thing.
A new career in software development: advice for non-youngsters
Lately I have been encountering non-young people looking to switch careers, into software development. My suggestions have centered around the ageism culture and how they can take advantage of fashions in software ecosystems to improve their job prospects.
I start by telling them the good news: the demand for software developers outstrips supply, followed by the bad news that software development culture is ageist.
One consequence of the preponderance of the young is that people are heavily influenced by fads and fashions, which come and go over less than a decade.
The perception of technology progresses through the stages of fashionable, established and legacy (management-speak for unfashionable).
Non-youngsters can leverage the influence of fashion’s impact on job applicants by focusing on what is unfashionable, the more unfashionable the less likely that youngsters will apply, e.g., maintaining Cobol and Fortran code (both seriously unfashionable).
The benefits of applying to work with unfashionable technology include more than a smaller job applicant pool:
- new technology (fashion is about the new) often experiences a period of rapid change, and keeping up with change requires time and effort. Does somebody with a family, or outside interests, really want to spend time keeping up with constant change at work? I suspect not,
- systems depending on unfashionable technology have been around long enough to prove their worth, the sunk cost has been paid, and they will continue to be used until something a lot more cost-effective turns up, i.e., there is more job security compared to systems based on fashionable technology that has yet to prove their worth.
There is lots of unfashionable software technology out there. Software can be considered unfashionable simply because of the language in which it is written; some of the more well known of such languages include: Fortran, Cobol, Pascal, and Basic (in a multitude of forms), with less well known languages including, MUMPS, and almost any mainframe related language.
Unless you want to be competing for a job with hordes of keen/cheaper youngsters, don’t touch Rust, Go, or anything being touted as the latest language.
Databases also have a fashion status. The unfashionable include: dBase, Clarion, and a whole host of 4GL systems.
Be careful with any database that is NoSQL related, it may be fashionable or an established product being marketed using the latest buzzwords.
Testing and QA have always been very unsexy areas to work in. These areas provide the opportunity for the mature applicants to shine by highlighting their stability and reliability; what company would want to entrust some young kid with deciding whether the software is ready to be released to paying customers?
More suggestions for non-young people looking to get into software development welcome.
Researching programming languages
What useful things might be learned from evidence-based research into programming languages?
A common answer is researching how to design a programming language having a collection of desirable characteristics; with desirable characteristics including one or more of: supporting the creation of reliable, maintainable, readable, code, or being easy to learn, or easy to understand, etc.
Building a theory of, say, code readability is an iterative process. A theory is proposed, experiments are run, results are analysed; rinse and repeat until a theory having a good enough match to human behavior is found. One iteration will take many years: once a theory is proposed, an implementation has to be built, developers have to learn it, and spend lots of time using it to enable longer term readability data to be obtained. This iterative process is likely to take many decades.
Running one iteration will require 100+ developers using the language over several years. Why 100+? Lots of subjects are needed to obtain statistically meaningful results, people differ in their characteristics and previous software experience, and some will drop out of the experiment. Just one iteration is going to cost a lot of money.
If researchers do succeed in being funded and eventually discovering some good enough theories, will there be a mass migration of developers to using languages based on the results of the research findings? The huge investment in existing languages (both in terms of existing code and developer know-how) means that to stand any chance of being widely adopted these new language(s) are going to have to deliver a substantial benefit.
I don’t see a high cost multi-decade research project being funded, and based on the performance improvements seen in studies of programming constructs I don’t see the benefits being that great (benefits in use of particular constructs may be large, but I don’t see an overall factor of two improvement).
I think that creating new programming languages will continue to be a popular activity (it is vanity research), and I’m sure that the creators of these languages will continue to claim that their language has some collection of desirable characteristics without any evidence.
What programming research might be useful and practical to do?
One potentially practical and useful question is the lifecycle of programming languages. Where the components of the lifecycle includes developers who can code in the language, source code written in the language, and companies dependent on programs written in the language (who are therefore interested in hiring people fluent in the language).
Many languages come and go without many people noticing, a few become popular for a few years, and a handful continue to be widely used over decades. What are the stages of life for a programming language, what factors have the largest influence on how widely a language is used, and for how long it continues to be used?
Sixty years worth of data is waiting to be collected and collated; enough to keep researchers busy for many years.
The uses of a lifecycle model, that I can thinkk of, all involve the future of a language, e.g., how much of a future does it have and how might it be extended.
Some recent work looking at the rate of adoption of new language features includes: On the adoption, usage and evolution of Kotlin Features on Android development, and Understanding the use of lambda expressions in Java; also see section 7.3.1 of Evidence-based software engineering.
A study, a replication, and a rebuttal; SE research is starting to become serious
tldr; A paper makes various claims based on suspect data. A replication finds serious problems with the data extraction and analysis. A rebuttal paper spins the replication issues as being nothing serious, and actually validating the original results, i.e., the rebuttal is all smoke and mirrors.
When I first saw the paper: A Large-Scale Study of Programming Languages and Code Quality in Github, the pdf almost got deleted as soon as I started scanning the paper; it uses number of reported defects as a proxy for code quality. The number of reported defects in a program depends on the number of people using the program, more users will generate more defect reports. Unfortunately data on the number of people using a program is extremely hard to come by (I only know of one study that tried to estimate number of users); studies of Java have also found that around 40% of reported faults are requests for enhancement. Most fault report data is useless for the model building purposes to which it is put.
Two things caught my eye, and I did not delete the pdf. The authors have done good work in the past, and they were using a zero-truncated negative binomial distribution; I thought I was the only person using zero-truncated negative binomial distributions to analyze software engineering data. My data analysis alter-ego was intrigued.
Spending a bit more time on the paper confirmed my original view, it’s conclusions were not believable. The authors had done a lot of work, this was no paper written over a long weekend, but lots of silly mistakes had been made.
Lots of nonsense software engineering papers get published, nothing to write home about. Everybody gets writes a nonsense paper at some point in their career, hopefully they get caught by reviewers and are not published (the statistical analysis in this paper was probably above the level familiar to most software engineering reviewers). So, move along.
At the start of this year, the paper: On the Impact of Programming Languages on Code Quality: A Reproduction Study appeared, published in TOPLAS (the first was in CACM, both journals of the ACM).
This replication paper gave a detailed analysis of the mistakes in data extraction, and the sloppy data analyse performed in the original work. Large chunks of the first study were cut to pieces (finding many more issues than I did, but not pointing out the missing usage data). Reading this paper now, in more detail, I found it a careful, well argued, solid piece of work.
This publication is an interesting event. Replications are rare in software engineering, and this is the first time I have seen a take-down (of an empirical paper) like this published in a major journal. Ok, there have been previous published disagreements, but this is machine learning nonsense.
The Papers We Love meetup group ran a mini-workshop over the summer, and Jan Vitek gave a talk on the replication work (unfortunately a problem with the AV system means the videos are not available on the Papers We Love YouTube channel). I asked Jan why they had gone to so much trouble writing up a replication, when they had plenty of other nonsense papers to choose from. His reasoning was that the conclusions from the original work were starting to be widely cited, i.e., new, incorrect, community-wide beliefs were being created. The finding from the original paper, that has been catching on, is that programs written in some languages are more/less likely to contain defects than programs written in other languages. What I think is actually being measured is number of users of the programs written in particular languages (a factor not present in the data).
Yesterday, the paper Rebuttal to Berger et al., TOPLAS 2019 appeared, along with a Medium post by two of the original authors.
The sequence: publication, replication, rebuttal is how science is supposed to work. Scientists disagree about published work and it all gets thrashed out in a series of published papers. I’m pleased to see this is starting to happen in software engineering, it shows that researchers care and are willing to spend time analyzing each others work (rather than publishing another paper on the latest trendy topic).
From time to time I had considered writing a post about the first two articles, but an independent analysis of the data meant some serious thinking, and I was not that keen (since I did not think the data went anywhere interesting).
In the academic world, reputation and citations are the currency. When one set of academics publishes a list of mistakes, errors, oversights, blunders, etc in the published work of another set of academics, both reputation and citations are on the line.
I have not read many academic rebuttals, but one recurring pattern has been a pointed literary style. The style of this Rebuttal paper is somewhat breezy and cheerful (the odd pointed phrase pops out every now and again), attempting to wave off what the authors call general agreement with some minor differences. I have had some trouble understanding how the rebuttal points discussed are related to the problems highlighted in the replication paper. The tone of the medium post is that there is nothing to see here, let’s all move on and be friends.
An academic’s work is judged by the number of citations it has received. Citations are used to help decide whether someone should be promoted, or awarded a grant. As I write this post, Google Scholar listed 234 citations to the original paper (which is a lot, most papers have one or none). The abstract of the Rebuttal paper ends with “…and our paper is eminently citable.”
The claimed “Point-by-Point Rebuttal” takes the form of nine alleged claims made by the replication authors. In four cases the Claim paragraph ends with: “Hence the results may be wrong!”, in two cases with: “Hence, FSE14 and CACM17 can’t be right.” (these are references to the original conference and journal papers, respectively), and once with: “Thus, other problems may exist!”
The rebuttal points have a tenuous connection to the major issues raised by the replication paper, and many of them are trivial issues (compared to the real issues raised).
Summary bullet points (six of them) at the start of the Rebuttal discuss issues not covered by the rebuttal points. My favourite is the objection bullet point claiming a preference, in the replication, for the use of the Bonferroni correction rather than FDR (False Discovery Rate). The original analysis failed to use either technique, when it should have used one or the other, a serious oversight; the replication is careful and does the analysis using both.
I would be very surprised if the Rebuttal paper, in its current form, gets published in any serious journal; it’s currently on a preprint server. It is not a serious piece of work.
Somebody who has only read the Rebuttal paper would take away a strong impression that the criticisms in the replication paper were trivial, and that the paper was not a serious piece of work.
What happens next? Will the ACM appoint a committee of the great and the good to decide whether the CACM article should be retracted? We are not talking about fraud or deception, but a bunch of silly mistakes that invalidate the claimed findings. Researchers are supposed to care about the integrity of published work, but will anybody be willing to invest the effort needed to get this paper retracted? The authors will not want to give up those 234, and counting, citations.
Update
The replication authors have been quick off the mark and posted a rebuttal of the Rebuttal.
The rebuttal of the Rebuttal has been written in the style that rebuttals are supposed to be written in, i.e., a point by point analysis of the issues raised.
Now what? I have no idea.
First language taught to undergraduates in the 1990s
The average new graduate is likely to do more programming during the first month of a software engineering job, than they did during a year as an undergraduate. Programming courses for undergraduates is really about filtering out those who cannot code.
Long, long ago, when I had some connection to undergraduate hiring, around 70-80% of those interviewed for a programming job could not write a simple 10-20 line program; I’m told that this is still true today. Fluency in any language (computer or human) takes practice, and the typical undergraduate gets very little practice (there is no reason why they should, there are lots of activities on offer to students and programming fluency is not needed to get a degree).
There is lots of academic discussion around which language students should learn first, and what languages they should be exposed to. I have always been baffled by the idea that there was much to be gained by spending time teaching students multiple languages, when most of them barely grasp the primary course language. When I was at school the idea behind the trendy new maths curriculum was to teach concepts, rather than rote learning (such as algebra; yes, rote learning of the rules of algebra); the concept of number-base was considered to be a worthwhile concept and us kids were taught this concept by having the class convert values back and forth, such as base-10 numbers to base-5 (base-2 was rarely used in examples). Those of us who were good at maths instantly figured it out, while everybody else was completely confused (including some teachers).
My view is that there is no major teaching/learning impact on the choice of first language; it is all about academic fashion and marketing to students. Those who have the ability to program will just pick it up, and everybody else will flounder and do their best to stay away from it.
Richard Reid was interested in knowing which languages were being used to teach introductory programming to computer science and information systems majors. Starting in 1992, he contacted universities roughly twice a year, asking about the language(s) used to teach introductory programming. The Reid list (as it became known), was regularly updated until Reid retired in 1999 (the average number of universities included in the list was over 400); one of Reid’s ex-students, Frances VanScoy, took over until 2006.
The plot below is from 1992 to 2002, and shows languages in the top with more than 3% usage in any year (code+data):
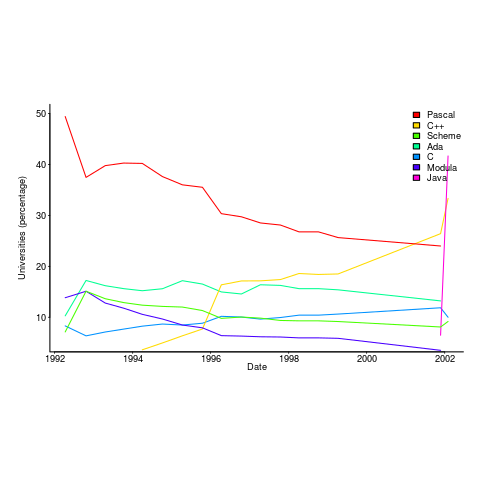
Looking at the list again reminded me how widespread Pascal was as a teaching language. Modula-2 was the language that Niklaus Wirth designed as the successor of Pascal, and Ada was intended to be the grown up Pascal.
While there is plenty of discussion about which language to teach first, doing this teaching is a low status activity (there is more fun to be had with the material taught to the final year students). One consequence is lack of any real incentive for spending time changing the course (e.g., using a new language). The Open University continued teaching Pascal for years, because material had been printed and had to be used up.
C++ took a while to take-off because of its association with C (which was very out of fashion in academia), and Java was still too new to risk exposing to impressionable first-years.
A count of the total number of languages listed, between 1992 and 2002, contains a few that might not be familiar to readers.
Ada Ada/Pascal Beta Blue C
1087 1 10 3 667
C/Java C/Scheme C++ C++/Pascal Eiffel
1 1 910 1 29
Fortran Haskell HyperTalk ISETL ISETL/C
133 12 2 30 1
Java Java/Haskell Miranda ML ML/Java
107 1 48 16 1
Modula-2 Modula-3 Oberon Oberon-2 ObjPascal
727 24 26 7 22
Orwell Pascal Pascal/C Prolog Scheme
12 2269 1 12 752
Scheme/ML Scheme/Turing Simula Smalltalk SML
1 1 14 33 88
Turing Visual-Basic
71 3 |
I had never heard of Orwell, a vanity language foisted on Oxford Mathematics and Computation students. It used to be common for someone in computing departments to foist their vanity language on students; it enabled them to claim the language was being used and stoked their ego. Is there some law that enables students to sue for damages?
The 1990s was still in the shadow of the 1980s fashion for functional programming (which came back into fashion a few years ago). Miranda was an attempt to commercialize a functional language compiler, with Haskell being an open source reaction.
I was surprised that Turing was so widely taught. More to do with the stature of where it came from (university of Toronto), than anything else.
Fortran was my first language, and is still widely used where high performance floating-point is required.
ISETL is a very interesting language from the 1960s that never really attracted much attention outside of New York. I suspect that Blue is BlueJ, a Java IDE targeting novices.
Hack, a template for improving code reliability
My sole prediction for 2014 has come true, Facebook have announced the Hack language (if you don’t know that HHVM is the Hip Hop Virtual Machine you are obviously not a trendy developer).
This language does not follow the usual trend in that it looks useful, rather than being fashion fluff for corporate developers to brag about. Hack extends an existing language (don’t the Facebook developers know about not-invented-here?) by adding features to improve code reliability (how uncool is that) and stuff that will sometimes enable faster code to be generated (which has always been cool).
Well done Facebook. I hope this is the start of a trend of adding features to a language that help developers improve code reliability.
Hack extends PHP to allow programmers to express intent, e.g., this variable only ever holds integer values. Compilers can then check that the code follows the intent and flag when it doesn’t, e.g., a string is assigned to the variable intended to only hold integers. This sounds so trivial to be hardly worth bothering about, but in practice it catches lots of minor mistakes very quickly and saves huge amounts of time that would otherwise be spent debugging code at runtime.
Yes, Hack has added static typing into a dynamically typed language. There is a generally held view that static typing prevents programmers doing what needs to be done and that dynamic typing is all about freedom of expression (who could object to that?) Static typing got a bad name because early languages using it were too disciplinarian in a few places and like the very small stone in a runners shoe these edge cases came to dominate thinking. Dynamic languages are great for small programs and showing off to spotty teenagers students, but are expensive to maintain and a nightmare to work with on 10K+ line systems.
The term gradual typing is a good description for Hack’s type system. Developers can take existing PHP code and gradually give types to existing variables in a piecemeal fashion or add new code that uses types into code that does not. The type checker figures out what it can and does not get too upperty about complaining. If a developer can be talked into giving such a system a try they quickly learn that they can save a lot of debugging time by using it.
I would like to see gradual typing introduced into R, but perhaps the language does not cause its users enough grief to make this happen (it is R’s libraries that cause the grief):
- Compared to PHP’s quirks the R quirk’s are pedestrian. In the interest of balance I should point out that Javascript can at times be as quirky as PHP and C++ error messages can be totally incomprehensible to everybody (including the people who wrote the compiler).
- R programs are often small, i.e., 100 lines’ish. It is only when programs, written in dynamically typed languages, start to exceed around 10k+ lines that they start to fall in on themselves unless that one person who has everything in his head is there to hold it all up.
However, there is a sort of precedent: Perl programs tend to be short (although I don’t think they are as short as R) and it gradually introduced the option of stronger typing. But Perk did/does have one person who was the recognized language designer who could lead the process; R has a committee.
A prediction for 2014
When I first started writing this blog I used to make prediction for the coming year. After a couple of years I stopped doing this, the world of computer languages changes very slowly, i.e., I was mostly proved wrong.
I recently realised that Facebook had not yet launched their own general programming language; such an event must be a sure fire prediction for 2014.
Stop trying to argue that the world does not need a new programming language. The reason companies launch their own language is self image (in the way Hollywood superstars launch their own perfumes and fashion lines).
Back in the day IBM launched PL/1, we had Ada from the US DOD, C# and F# from Microsoft, Google has Go and Mozilla has Rust.
Facebook has a software platform and I’m sure they feel something is missing. It must really gall their engineers to hear people from Google, Mozilla and even that old fogy Microsoft talking about ‘their’ language.
New languages are easy to invent, PhD students do it all the time. Implementing them is also cheap, a good engineer can put together a compiler and interpreter in about a year; these days, thanks to LLVM, the cost of building a machine code generator for a new language has dropped significantly (GCC is still intimidating). Libraries, where a large percentage of the work used to go, can be copied from a multitude of places (not a problem if everything is open sourced, which new language implementations tend to be these days).
One end of year tit-bit is that Google now seem to be taking Dart more seriously than just techy swagger.
2013 in the programming language standards’ world
Yesterday I was at the British Standards Institute for a meeting of IST/5, the committee responsible for programming languages. Things have been rather quiet since I last wrote about IST/5, 18 months ago. Of course lots of work has been going on (WG21 meetings, C++ Standard, are attracting 100+ people, twice a year, to spend a week trying to reach agreement on new neat features to add; I’m not sure how the ability to send email is faring these days ;-).
Taken as a whole programming languages standards work, at the ISO level, has been in decline over the last 10 years and will probably decline further. IST/5 used to meet for a day four times a year and now meets for half a day twice a year. Chairman of particular language committees, at international and national levels, are retiring and replacements are thin on the ground.
Why is work on programming language standards in decline when there are languages in widespread use that have not been standardised (e.g., Perl and PHP do not have a non-source code specification)?
The answer is low hardware/OS diversity and Open source. These two factors have significantly reduced the size of the programming language market (i.e., there are far fewer people making a living selling compilers and language related tools). In the good old-days any computer company worth its salt had its own cpu and OS, which of course needed its own compiler and the bigger vendors had third parties offering competing compilers; writing a compiler was such a big undertaking that designers of new languages rarely gave the source away under non-commercial terms, even when this happened the effort involved in a port was heroic. These days we have a couple of cpus in widespread use (and unlikely to be replaced anytime soon), a couple of OSs and people are queuing up to hand over the source of the compiler for their latest language. How can a compiler writer earn enough to buy a crust of bread let alone attend an ISO meeting?
Creating an ISO language standard, through the ISO process, requires a huge amount of work (an estimated 62-person years for C99; pdf page 20). In a small market, few companies have an incentive to pay for an employee to be involved in the development process. Those few languages that continue to be worked on at the ISO level have niche markets (Fortran has supercomputing and C had embedded systems) or broad support (C and now C++) or lots of consultants wanting to be involved (C++, not so much C these days).
The new ISO language standards are coming from national groups (e.g., Ruby from Japan and ECMAscript from the US) who band together to get the work done for local reasons. Unless there is a falling out between groups in different nations, and lots of money is involved, I don’t see any new language standards being developed within ISO.
Proposal for a change of approach to programming language teaching
In a previous post I explained why I think developers don’t really know any computer language, and in this post I want to outline how I think we should adapt to this reality and radically change the approach taken to teaching students about using a computer language. First, a couple of points:
- The programming community needs to change its attitude towards language knowledge from being an end in itself to being something that is ok to acquire on an as needed basis. Developers don’t need to know much about the programming language they use in order to get their job done, get over it. Spending time learning the ins and outs of a language’s semantics rarely provides a worthwhile return on investment compared to time spent learning something else, such as the application domain or customer requirements,
- designing a new, ‘simpler’ programming language is not a solution; the existing languages in common use are not going away anytime soon and creating a new general purpose language is only going to overload developers with more stuff to learn and yet another runtime system to interface to,
- we need to concentrate on suggestions about what students and developers should be doing and not what they should not be doing. This is not only a good teaching principle it avoids the problem of having to come up with a good list of things not to do (coding standard recommendations are very rarely based on any evidence apart from the proposers own point of view and even the ones that make it through peer review are little more than group think or a waste of time).
The response to the existing state of affairs should be to approach the teaching of programming languages as an exercise in teaching students only what they need to know to do useful work, rather than acting on the belief that students should strive to be experts in the language they use and burdening them with lots of pointless language details. The exact minimum-set of knowledge could vary across different industries and application domains, so the set might need to be a bit larger than the minimum to be on the safe side.
Invariably some developers will need to know more than the minimum-set, so we also need to figure out what ‘template’ knowledge (or whatever term is used, an alternative is behavior patterns or patterns of behavior) should be included in the next level of language knowledge, this can be documented and made available to anybody who wants to read it; there may or may not be more levels before a developer is told to go and read a reference book or the language reference manual to figure out what they need to know.
This is minimum-set approach, with the opportunity to progress to successively more detailed levels, is often used for learning human languages, computer languages are not any different.
I would expect there to be some variation in the minimum-set between different languages, and would resist the temptation to try and create a ‘common minimum’ until some experience had been gained in teaching single languages.
How would the minimum-set of language knowledge be chosen? Simple. Students need to learn those construct they are likely to use most of the time, and that question can be answered by measuring a large amount of existing source code. Results from measurements that have been made typically show a small number of constructs are used a large percentage of the time. For instance, measurements of C source find that the 33.2% of for-loops have the form: for (assignment ; identifier < identifier ; identifier++), where identifier might be two or more different identifiers; allowing the central test to have the form identifier < expression takes the percentage to over 50%. I would expect the same pattern of usage to occur in source written in other languages but don't have any number to back up that assertion.
Perhaps the most important pattern of (developer) behavior is what its discoverer, Jorma Sajaniemi, calls the roles of variables (each variable is used to hold a particular kind of information, e.g., most wanted holder, stepper, container, etc).
One pattern of behavior that I am more or less completely in the dark about is class/package usage. There is the famous book on design patterns which the authors did a good job of promoting, but I have yet to see any empirical evidence showing the claimed benefits. The analysis of class/package behavioral usage is non-trivial, but it can be done.
Would I insist that developers only use constructs list in the suggested minimum-set (plus possible extras)? No. The purpose of this proposal is to help students and developers learn what they need to know to get a job done. Figuring out what language constructs, if any, should be avoided at all costs is a very tough problem which at the end of the day might not be worth solving.
A minimum-set knowledge of the language being used does not imply poor quality code. Most code is simple anyway, the complicated stuff invariably revolves around the algorithms that need to be used, and a skillful developer is one who uses straightforward language constructs to create easy to maintain code, not one who writes code that relies on detailed knowledge of some language feature.
I expect this proposal to adopt a minimum-set approach to language teaching will draw an angry reaction from the cottage industry that makes its living from writing and giving seminars on the latest trends in language-X. Don't panic guys, managers are well aware that this kind of knowledge rarely has any impact of developer performance and the actual motivation for sending employees on such seminars is to keep them happy (it can be a much more effective way of keeping staff than simply giving them a pay rise).
Recent Comments