Archive
Predicted impact of LLM use on developer ecosystems
LLMs are not going to replace developers. Next token prediction is not the path to human intelligence. LLMs provide a convenient excuse for companies not hiring or laying off developers to say that the decision is driven by LLMs, rather than admit that their business is not doing so well
Once the hype has evaporated, what impact will LLMs have on software ecosystems?
The size and complexity of software systems is limited by the human cognitive resources available for its production. LLMs provide a means to reduce the human cognitive effort needed to produce a given amount of software.
Using LLMs enables more software to be created within a given budget, or the same amount of software created with a smaller budget (either through the use of cheaper, and presumably less capable, developers, or consuming less time of more capable developers).
Given the extent to which companies compete by adding more features to their applications, I expect the common case to be that applications contain more software and budgets remain unchanged. In a Red Queen market, companies want to be perceived as supporting the latest thing, and the marketing department needs something to talk about.
Reducing the effort needed to create new features means a reduction in the delay between a company introducing a new feature that becomes popular, and the competition copying it.
LLMs will enable software systems to be created that would not have been created without them, because of timescales, funding, or lack of developer expertise.
I think that LLMs will have a large impact on the use of programming languages.
The quantity of training data (e.g., source code) has an impact on the quality of LLM output. The less widely used languages will have less training data. The table below lists the gigabytes of source code in 30 languages contained in various LLM training datasets (for details see The Stack: 3 TB of permissively licensed source code by Kocetkov et al.):
Language TheStack CodeParrot AlphaCode CodeGen PolyCoder HTML 746.33 118.12 JavaScript 486.2 87.82 88 24.7 22 Java 271.43 107.7 113.8 120.3 41 C 222.88 183.83 48.9 55 C++ 192.84 87.73 290.5 69.9 52 Python 190.73 52.03 54.3 55.9 16 PHP 183.19 61.41 64 13 Markdown 164.61 23.09 CSS 145.33 22.67 TypeScript 131.46 24.59 24.9 9.2 C# 128.37 36.83 38.4 21 GO 118.37 19.28 19.8 21.4 15 Rust 40.35 2.68 2.8 3.5 Ruby 23.82 10.95 11.6 4.1 SQL 18.15 5.67 Scala 14.87 3.87 4.1 1.8 Shell 8.69 3.01 Haskell 6.95 1.85 Lua 6.58 2.81 2.9 Perl 5.5 4.7 Makefile 5.09 2.92 TeX 4.65 2.15 PowerShell 3.37 0.69 FORTRAN 3.1 1.62 Julia 3.09 0.29 VisualBasic 2.73 1.91 Assembly 2.36 0.78 CMake 1.96 0.54 Dockerfile 1.95 0.71 Batchfile 1 0.7 Total 3135.95 872.95 715.1 314.1 253.6 |
The major companies building LLMs probably have a lot more source code (as of July 2023, the Software Heritage had over  unique source code files); this table gives some idea of the relative quantities available for different languages, subject to recency bias. At the moment, companies appear to be training using everything they can get their hands on. Would LLM performance on the widely used languages improve if source code for most of the 682 languages listed on Wikipedia was not included in their training data?
unique source code files); this table gives some idea of the relative quantities available for different languages, subject to recency bias. At the moment, companies appear to be training using everything they can get their hands on. Would LLM performance on the widely used languages improve if source code for most of the 682 languages listed on Wikipedia was not included in their training data?
Traditionally, developers have had to spend a lot of time learning the technical details about how language constructs interact. For the first few languages, acquiring fluency usually takes several years.
It’s possible that LLMs will remove the need for developers to know much about the details of the language they are using, e.g., they will define variables to have the appropriate type and suggest possible options when type mismatches occur.
Removing the fluff of software development (i.e., writing the code) means that developers can invest more cognitive resources in understanding what functionality is required, and making sure that all the details are handled.
Removing a lot of the sunk cost of language learning removes the only moat that some developers have. Job adverts could stop requiring skills with particular programming languages.
Little is currently known about developer career progression, which means it’s not possible to say anything about how it might change.
Since they were first created, programming languages have fascinated developers. They are the fashion icon of software development, with youngsters wanting to program in the latest language, or at least not use the languages used by their parents. If developers don’t invest in learning language details, they have nothing language related to discuss with other developers. Programming languages will cease to be a fashion icon (cpus used to be a fashion icon, until developers did not need to know details about them, such as available registers and unique instructions). Zig could be the last language to become fashionable.
I don’t expect the usage of existing language features to change. LLMs mimic the characteristics of the code they were trained on.
When new constructs are added to a popular language, it can take years before they start to be widely used by developers. LLMs will not use language constructs that don’t appear in their training data, and if developers are relying on LLMs to select the appropriate language construct, then new language constructs will never get used.
By 2035 things should have had time to settle down and for the new patterns of developer behavior to be apparent.
Discussing new language features is more fun than measuring feature usage in code
How often are the features supported by a programming language used by developers in the code that they write?
This fundamental question is rarely asked, let alone answered (my contribution).
Existing code is what developers spend their time reading, compilers translating to machine code, and LLMs use as training data.
Frequently used language features are of interest to writers of code optimizers, who want to know where to focus their limited resources (at least I did when I was involved in the optimization business; I was always surprised by others working in the field having almost no interest in measuring user’s code), and educators ought to be interested in teaching what students are mostly likely to be using (rather than teaching the features that are fun to talk about).
The unused, or rarely used language features are also of interest. Is the feature rarely used because developers have no use for the feature, or does its semantics prevent it being practically applied, or some other reason?
Language designers write books, papers, and blog posts discussing their envisaged developer usage of each feature, and how their mental model of the language ties everything together to create a unifying whole; measurements of actual source code very rarely get discussed. Two very interesting reads in this genre are Stroustrup’s The Design and Evolution of C++ and Thriving in a Crowded and Changing World: C++ 2006–2020.
Languages with an active user base are often updated to support new features. The ISO C++ committee is aims to release a new standard every three years, Java is now on a six-month release cycle, and Python has an annual release cycle. The primary incentives driving the work needed to create these updates appears to be:
- sales & marketing: saturation exposure to adverts proclaiming modernity has warped developer perception of programming languages, driving young developers to want to be associated with those perceived as modern. Companies need to hire inexperienced developers (who are likely still running on the modernity treadmill), and appearing out of date can discourage developers from applying for a job,
- designer hedonism and fuel for the trainer/consultant gravy train: people create new programming languages because it’s something they enjoy doing; some even leave their jobs to work on their language full-time. New language features provides material to talk about and income opportunities for trainers/consultants.
Note: I’m not saying that adding new features to a language is bad, but that at the moment worthwhile practical use to developers is a marketing claim rather than an evidence-based calculation.
Those proposing new language features can rightly point out that measuring language usage is a complicated process, and that it takes time for new features to diffuse into developers’ repertoire. Also, studying source code measurement data is not something that appeals to many people.
Also, the primary intended audience for some language features is library implementors, e.g., templates.
There have been some studies of language feature usage. Lambda expressions are a popular research subject, having been added as a new feature to many languages, e.g., C++, Java, and Python. A few papers have studied language usage in specific contexts, e.g., C++ new feature usage in KDE.
The number of language features invariably grow and grow. Sometimes notice is given that a feature will be removed from a future reversion of the language. Notice of feature deprecation invariably leads to developer pushback by the subset of the community that relies on that feature (measuring usage would help prevent embarrassing walk backs).
If the majority of newly written code does end up being created by developers prompting LLMs, then new language features are unlikely ever to be used. Without sufficient training data, which comes from developers writing code using the new features, LLMs are unlikely to respond with code containing new features.
I am not expecting the current incentive structure to change.
Growth in number of packages for widely used languages
These days a language’s ecosystem of add-ons, such as packages, is often more important than the features provided by the language (which usually only vary in their syntactic sugar, and built-in support for some subset of commonly occurring features).
Use of a particular language grows and shrinks, sometimes over very many decades. Estimating the number of users of a language is difficult, but a possible proxy is ecosystem activity in the form of package growth/decline. However, it will take many several decades for the data needed to test how effective this proxy might be.
Where are we today?
The Module Counts website is the home for a project that counts the number of libraries/packages/modules contained in 26 language specific repositories. Daily data, in some cases going back to 2010, is available as a csv 🙂 The following are the most interesting items I discovered during a fishing expedition.
The csv file contains totals, and some values are missing (which means specifying an ‘ignore missing values’ argument to some functions). Some repos have been experiencing large average daily growth (e.g., 65 for PyPI, and 112 for Maven Central-Java), while others are more subdued (e.g., 0.7 for PERL and 3.9 for R’s CRAN). Apart from a few days, the daily change is positive.
Is the difference in the order of magnitude growth due to number of active users, number of packages that currently exist, a wide/narrow application domain (Python is wide, while R’s is narrow), the ease of getting a package accepted, or something else?
The plots below show how PyPI has been experiencing exponential growth of a kind (the regression model fitted to the daily total has the form  , where
, where  is the number of days since 2010-01-01; the red line is the daily diff of this equation), while Ruby has been experiencing a linear decline since late 2014 (all code+data):
is the number of days since 2010-01-01; the red line is the daily diff of this equation), while Ruby has been experiencing a linear decline since late 2014 (all code+data):
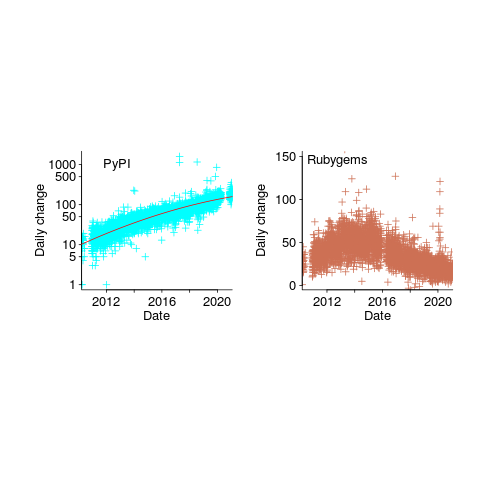
Will the five-year decline in new submissions to Rubygems continue, and does this point to an eventual demise of Ruby (a few decades from now)? Rubygems has years to go before it reaches PERL’s low growth rate (I think PERL is in terminal decline).
Are there any short term patterns, say at the weekly level? Autocorrelation is a technique for estimating the extent to which today’s value is affected by values from the immediate past (usually one or two measurement periods back, i.e., yesterday or the day before that). The two plots below show the autocorrelation for daily changes, with lag in days:
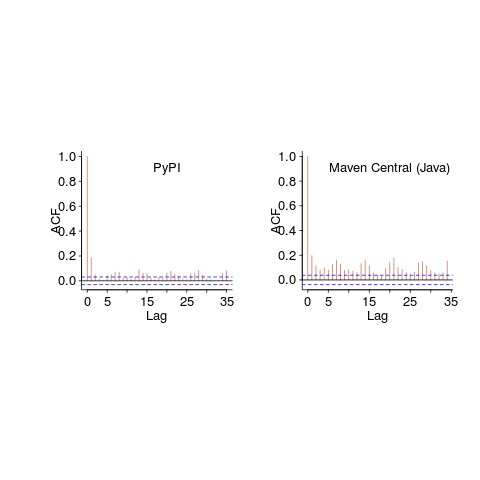
The recurring 7-day ‘peaks’ show the impact of weekends (I assume). Is the larger ”weekend-effect’ for Java, compared to PyPI, due to Java usage including a greater percentage of commercial developers (who tend not to work at the weekend)?
I did not manage to find any seasonal effect, e.g., more submissions during the winter than the summer. But I only checked a few of the languages, and only for a single peak (see code for details).
Another way of tracking package evolution is version numbering. For instance, how often do version numbers change, and which component, e.g., major/minor. There have been a couple of studies looking at particular repos over a few years, but nobody is yet recording broad coverage daily, over the long term 😉
An academic programming language paper about R
The R language has passed another milestone, a paper aimed at the academic programming language community (or at least one section of this community) has been written about it, Evaluating the Design of the R Language by Morandat, Hill, Osvald and Vitek. Hardly earth shattering news, but it may have some impact on how R is viewed by nonusers of the language (the many R users in finance probably don’t care that R seems to have been labeled as the language for doing statistics). The paper is well written and contains some very interesting information as well as a few mistakes, although it will probably read like gobbledygook to anybody not familiar with academic programming language research. What follows has something of the form of an R users guide to reading this paper, plus some commentary.
The paper has roughly three parts, the first gives an overview of R, the second is a formal definition of a subset and the third an initial report of an analysis of R usage. For me and I imagine you dear reader the really interesting stuff is in the third section.
When giving a language overview to people who know other computer languages it makes sense to leverage that knowledge, this is why the discussion has a world view from the perspective of languages rarely associated with R: Scheme, Haskell and CLOS. I found some of the discussion of R constructs to be much more informative and less confusing than that in nearly all R books/tutorials I have read, but then they are written from a detailed operational programming language perspective. One criticism of this overview is that it does not give any hint as to why R has such a large following (saying that users found it more useful than these languages would send the wrong kind of signal ;-).
What is a formal description of a subset of R (i.e., done purely using mathematics) doing in the second part? Well, until recently very little academic software engineering was empirically based and was populated by people I would classify as failed mathematicians without the common sense needed to be engineers. Things are starting to change but research that measures things, particularly people, is still regarded as not being respectable in some quarters. In this case the formal definition is playing the role of a virility symbol showing that the authors are obviously regular guys who happen to be indulging in a bit of empirical research.
A surprising number of papers measuring the usage of real software contain formal definitions of a subset of the language being measured. Subsets are used because handling the complete language is a big project that usually involves one or more people getting a PhD out of the work. The subset chosen have to look plausible to readers who understand the mathematics but not the programming language, broadly handle all the major constructs but not get involved with all the fiddly details that need years of work and many pages to describe.
The third part contains the real research, which is really about one implementation of R and the characteristics of R source in the CRAN and Bioconductor repositories, and contains lots of interesting information. Note: the authors are incorrect to aim nearly all of the criticisms in this subsection at R, these really apply to the current implementation of R and might not apply to a different implementation.
In a previous post I suggested some possibilities for speeding up the execution of R programs that depended on R usage characteristics. The Morandat paper goes a long way towards providing numbers for some of these usage characteristics (e.g., 37% of function parameters are assigned to and 36% of vectors contain a single value).
What do we learn from this first batch of measurements? R users rarely use many of the more complicated features (e.g., object oriented constructs {and this paper has been accepted at the European Conference on Object-Oriented Programming}), a result usually seen for other languages. I was a bit surprised that R programs were only 40% smaller than equivalent C programs. I think part of the reason is that some of the problems used for benchmarking are not the kind that would usually be solved using R and I did not see any ‘typical’ R programs being coded up in C for comparison, another possibility is that the authors were not thinking in R when writing the code.
One big measurement topic the authors missed is comparing their general findings with usage measurements of other languages. I think they will find lots of similar patterns of usage.
The complaint that R has been defined by the successive releases of its only implementation, rather than a written specification, applies to all widely used languages, at least in their early days. Back in the day a major reason for creating language standards for Pascal and then C was so that other implementations could be created; the handful of major languages whose specification was written before the first implementation (e.g., PL/1, Ada) have/are dieing out. Are multiple implementations needed in an Open Source world? The answer seems to be no for Perl and yes for PHP, Ruby etc. The effort needed to create a written specification for the R language might be better invested improving the efficiency of the current implementation so that a better alternative is not needed.
Needless to say the authors suggested committing the fatal programming language research mistake.
The authors have created an interesting set of tools for static and dynamic analysis of R and I look forward to reading more about their findings in future papers.
Language usage in Google’s ngram viewer
I thought I would join the fun that people are having with Google’s new ngram viewer. The raw data (only a subset for bigrams and longer ngrams) was also enticing, but at 35+ gigabytes for the compressed 1/2/3-grams of English-all I decided to forgo the longer n-grams.
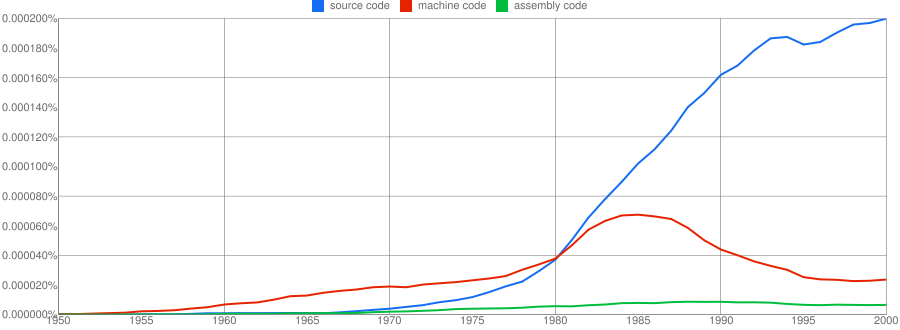
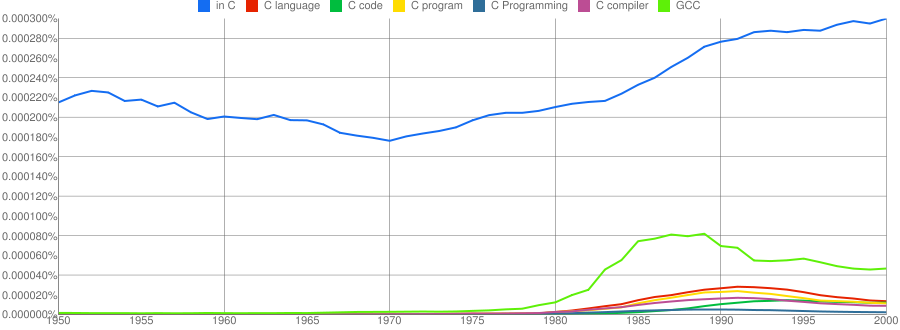
We all know that in the dim and distant past most programmers wrote in machine code, but it was not until 1980 that “source code” appeared more frequently in books that “machine code”.
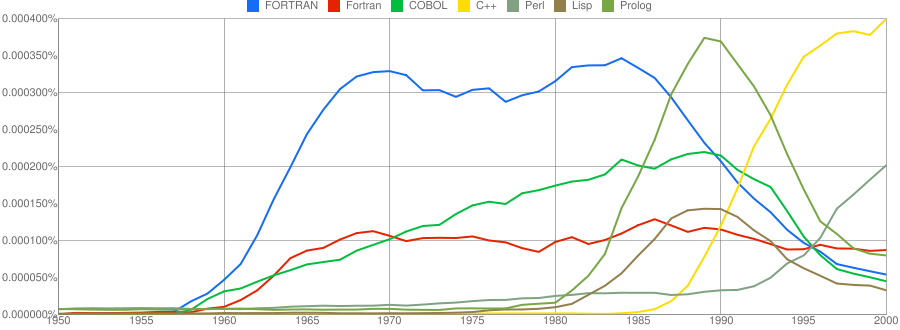
Computer language popularity is a perennial question. Fortran and Cobol address very different markets and I would have expected their usage to follow similar patterns, with “COBOL” having the obvious usage pattern for them both to follow. Instead, both “FORTRAN” and “Fortran” peaked within 10 years, with one staying there for another 20 years before declining and the other still going strong in 2000 (and still ahead of “PHP” and “Python” in 2000; neither shown to keep the clutter down). I am surprised to see “Prolog” usage being so much greater than “Lisp” and I would have expected “Lisp” to have a stronger presence in the 1970s.
I think the C++ crowd will be surprised to see that in 2000 usage was not much greater than what “FORTRAN” had enjoyed for 20 years.
“C”, as in language, usage is obviously different to reliably measure. I have tried the obvious bigrams. Looking at some of the book matches for the phrase “in C” shows that the OCR process has sometimes inserted spaces that probably did not exist in the original, the effect being to split words and create incorrect bigrams. The phrase “in C” would also appear in books on music.
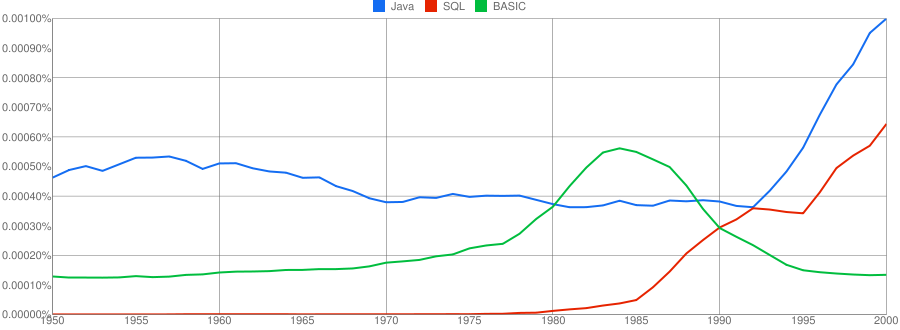
I have put the three words “Java”/”SQL”/”BASIC” in a separate plot because their usage swamps that of the other languages. Java obviously has multiple non-computer related uses and subtracting the estimated background usage suggests a language usage similar to that of “SQL”. There is too much noise for the usage of “Basic” to tell us much.
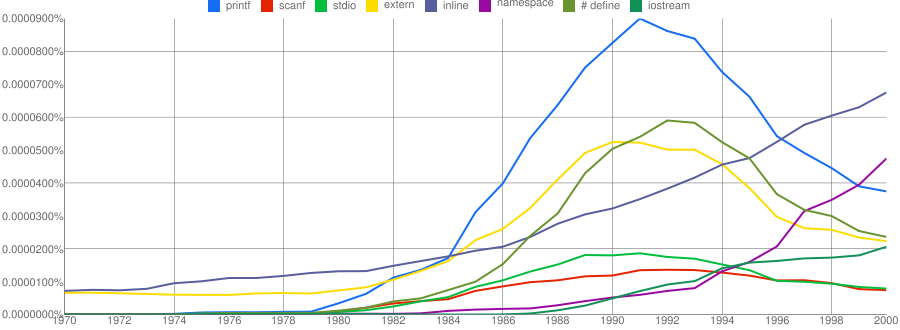
One way of comparing C/C++ language usage is to look source code usage where they are likely to differ. I/O, in the form of printf/scanf and stdio/iostream, is one obvious choice and while the expected C usage starts to declines in the 1990s the C++ usage just shows a stead growth (perhaps the <</>> usage, which does not appear in the Google viewer, has a dramatic growth during this time period).
Surprisingly #define also follows a similar pattern of decline. Even allowing for the rabid anti-macro rhetoric of the C++ in-crowd I would not have expected such a rapid decline. Perhaps this is some artifact of the book selection process used by Google; but then "namespace" shows a healthy growth around this time period.
The growth of "inline" over such a long period of time is a mystery. Perhaps some of this usage does not relate to a keyword appearing within source code examples but to text along the lines of "put this inline to make it faster".
What usage should we expect for the last decade? A greater usage of "PHP" and "Python" is an obvious call to make, along with the continuing growth of SQL, I think "UML" will also feature prominently. Will "C++" show a decline in favor or "Java" and what about "C#"? We will have to wait and see.
Recent Comments