Archive
Estimation experiments: specification wording is mostly irrelevant
Existing software effort estimation datasets provide information about estimates made within particular development environments and with particular aims. Experiments provide a mechanism for obtaining information about estimates made under conditions of the experimenters choice, at least in theory.
Writing the code is sometimes the least time-consuming part of implementing a requirement. At hackathons, my default estimate for almost any non-trivial requirement is a couple of hours, because my implementation strategy is to find the relevant library or package and write some glue code around it. In a heavily bureaucratic organization, the coding time might be a rounding error in the time taken up by meeting, documentation and testing; so a couple of months would be considered normal.
If we concentrate on the time taken to implement the requirements in code, then estimation time and implementation time will depend on prior experience. I know that I can implement a lexer for a programming language in half-a-day, because I have done it so many times before; other people take a lot longer because they have not had the amount of practice I have had on this one task. I’m sure there are lots of tasks that would take me many days, but there is somebody who can implement them in half-a-day (because they have had lots of practice).
Given the possibility of a large variation in actual implementation times, large variations in estimates should not be surprising. Does the possibility of large variability in subject responses mean that estimation experiments have little value?
I think that estimation experiments can provide interesting information, as long as we drop the pretence that the answers given by subjects have any causal connection to the wording that appears in the task specifications they are asked to estimate.
If we assume that none of the subjects is sufficiently expert in any of the experimental tasks specified to realistically give a plausible answer, then answers must be driven by non-specification issues, e.g., the answer the client wants to hear, a value that is defensible, a round number.
A study by Lucas Gren and Richard Berntsson Svensson asked subjects to estimate the total implementation time of a list of tasks. I usually ignore software engineering experiments that use student subjects (this study eventually included professional developers), but treating the experiment as one involving social processes, rather than technical software know-how, makes subject software experience a lot less relevant.
Assume, dear reader, that you took part in this experiment, saw a list of requirements that sounded plausible, and were then asked to estimate implementation time in weeks. What estimate would you give? I would have thrown my hands up in frustration and might have answered 0.1 weeks (i.e., a few hours). I expected the most common answer to be 4 weeks (the number of weeks in a month), but it turned out to be 5 (a very ‘attractive’ round number), for student subjects (code+data).
The professional subjects appeared to be from large organizations, who I assume are used to implementations including plenty of bureaucratic stuff, as well as coding. The task specification did not include enough detailed information to create an accurate estimate, so subjects either assumed their own work environment or played along with the fresh-faced, keen experimenter (sorry Lucas). The professionals showed greater agreement in that the range of value given was not as wide as students, but it had a more uniform distribution (with maximums, rather than peaks, at 4 and 7); see below. I suspect that answers at the high end were from managers and designers with minimal coding experience.
What did the experimenters choose weeks as the unit of estimation? Perhaps they thought this expressed a reasonable implementation time (it probably is if it’s not possible to use somebody else’s library/package). I think that they could have chosen day units and gotten essentially the same results (at least for student subjects). If they had chosen hours as the estimation unit, the spread of answers would have been wider, and I’m not sure whether to bet on 7 (hours in a working day) or 10 being the most common choice.
Fitting a regression model to the student data shows estimates increasing by 0.4 weeks per year of degree progression. I was initially baffled by this, and then I realized that more experienced students expect to be given tougher problems to solve, i.e., this increase is based on self-image (code+data).
The stated hypothesis investigated by the study involved none of the above. Rather, the intent was to measure the impact of obsolete requirements on estimates. Subjects were randomly divided into three groups, with each seeing and estimating one specification. One specification contained four tasks (A), one contained five tasks (B), and one contained the same tasks as (A) plus an additional task followed by the sentence: “Please note that R5 should NOT be implemented” (C).
A regression model shows that for students and professions the estimate for (A) is about 1-2 weeks lower than (B), while (A) estimates are 3-5 weeks lower than (C) estimated.
What are subjects to make of an experimental situation where the specification includes a task that they are explicitly told to ignore?
How would you react? My first thought was that the ignore R5 sentence was itself ignored, either accidentally or on purpose. But my main thought is that Relevance theory is a complicated subject, and we are a very long way away from applying it to estimation experiments containing supposedly redundant information.
The plot below shows the number of subjects making a given estimate, in days; exp0to2 were student subjects (dashed line joins estimate that include a half-hour value, solid line whole hour), exp3 MSc students, and exp4 professional developers (code+data):
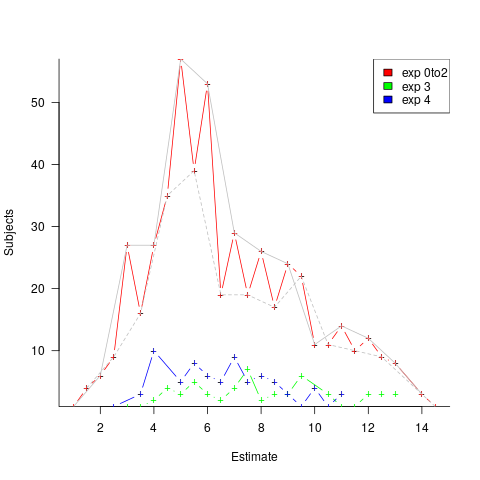
I hope that the authors of this study run more experiments, ideally working on the assumption that there is no connection between specification and estimate (apart from trivial examples).
Number of digits in floating-point literals
Some of the interesting floating-point literals detected by the numbers program not only look uninteresting but plain wrong. For instance, almost every program I analyze appears to contain a literal denoting the ratio of the diameter of the Earth to at least one minor planet. One problem is that most of the numbers contained in the interesting number database are only likely to occur in very specific circumstances and as the size of this database grows the percentage of inappropriate matches grows.
I could (and at some point probably will have to) assign an interestingness level to numbers, but this goes against one of the original aims of identifying the operations performed by unknown source.
An alternative idea is to create a connection between the fuzziness of the matching process and the probability of the literal being encountered in code. For instance, a more exact match might be required for 0.5 because it contains few mantissa digits and sits within a range of values that are commonly encountered, while a much fuzzier match might be used for 1.879623e+3 because it contains more digits and occupies a less commonly encountered range of values.
Floating-point literals often contain leading or trailing zeros, e.g., 0.001, 100.0, 1e+2
or 0.50. Does the presence of these zeros change the probability of a particular mantissa being encountered? For instance the literals 100.0 and 1e+2 have the same numeric value but different numbers of mantissa digits.
Another issue is developer intent. Why did a developer write 0.50, did they simply want two digits to appear after the decimal point because the surrounding literals in the source contain two digits and it makes the visual appearance look better or does this usage denote a quantity whose accuracy is known to two decimal digits?
The following figure is derived from 1 million non-zero floating-point literals contained in ten large, computationally intensive programs.
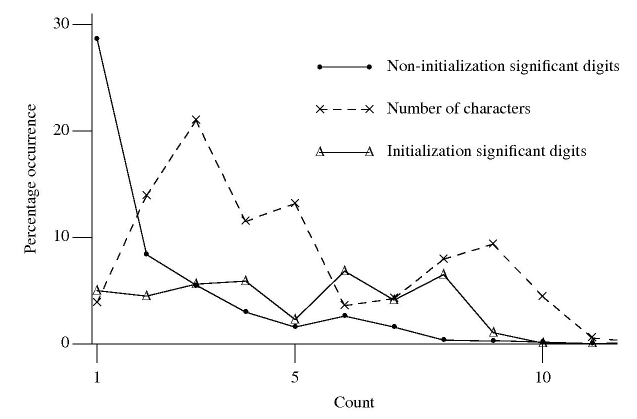
The dashed line denotes the percentage of mantissas containing a given number of characters, including leading/trailing zeros and any decimal point.
The two solid lines denote the digit count of the mantissas with any leading/trailing zeros removed, along with any decimal point, e.g., both 100.0 and 1e+2 would be considered to contain one digit.
It seemed to me that floating-point literals appearing within an initializer attached to a variable definition often contain more digits than literals that appear elsewhere. The solid, triangle tagged, solid line that spends most of its time around 5% are floating-point literals appearing within an initializer (to be exact they are literals separated from another literal by a comma {with some simplistic handling of Fortran line continuation}). The bullet tagged line are all other literals.
I was partially right about the characteristics of floating-point literals in initializers. It turns out the probability of encountering a mantissa containing a given number of digits is approximately constant within an initializer (a more sophisticated analysis might show an upward trend with increasing numbers of digits).
The mantissa digit count outside of initializers has the kind of probability distribution I was looking for. Hopefully this distribution will contribute to a useful measure of interestingness.
Recent Comments