Archive
Many coding mistakes are not immediately detectable
Earlier this week I was reading a paper discussing one aspect of the legal fallout around the UK Post-Office’s Horizon IT system, and was surprised to read the view that the Law Commission’s Evidence in Criminal Proceedings Hearsay and Related Topics were citing on the subject of computer evidence (page 204): “most computer error is either immediately detectable or results from error in the data entered into the machine”.
What? Do I need to waste any time explaining why this is nonsense? It’s obvious nonsense to anybody working in software development, but this view is being expressed in law related documents; what do lawyers know about software development.
Sometimes fallacies become accepted as fact, and a lot of effort is required to expunge them from cultural folklore. Regular readers of this blog will have seen some of my posts on long-standing fallacies in software engineering. It’s worth collecting together some primary evidence that most software mistakes are not immediately detectable.
A paper by Professor Tapper of Oxford University is cited as the source (yes, Oxford, home of mathematical orgasms in software engineering). Tapper’s job title is Reader in Law, and on page 248 he does say: “This seems quite extraordinarily lax, given that most computer error is either immediately detectable or results from error in the data entered into the machine.” So this is not a case of his words being misinterpreted or taken out of context.
Detecting many computer errors is resource intensive, both in elapsed time, manpower and compute time. The following general summary provides some of the evidence for this assertion.
Two events need to occur for a fault experience to occur when running software:
- a mistake has been made when writing the source code. Mistakes include: a misunderstanding of what the behavior should be, using an algorithm that does not have the desired behavior, or a typo,
- the program processes input values that interact with a coding mistake in a way that produces a fault experience.
That people can make different mistakes is general knowledge. It is my experience that people underestimate the variability of the range of values that are presented as inputs to a program.
A study by Nagel and Skrivan shows how variability of input values results in fault being experienced at different time, and that different people make different coding mistakes. The study had three experienced developers independently implement the same specification. Each of these three implementations was then tested, multiple times. The iteration sequence was: 1) run program until fault experienced, 2) fix fault, 3) if less than five faults experienced, goto step (1). This process was repeated 50 times, always starting with the original (uncorrected) implementation; the replications varied this, along with the number of inputs used.
How many input values needed to be processed, on average, before a particular fault is experienced? The plot below (code+data) shows the numbers of inputs processed, by one of the implementations, before individual faults were experienced, over 50 runs (sorted by number of inputs needed before the fault was experienced):
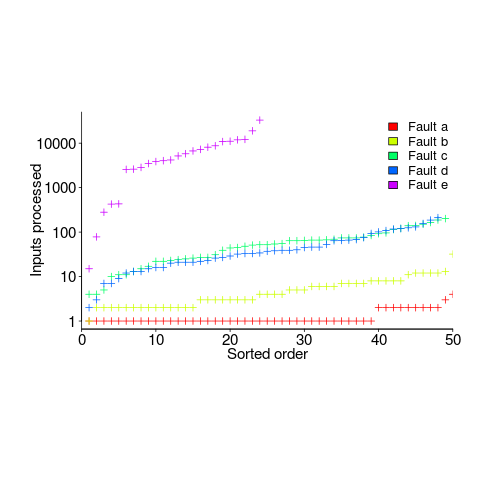
The plot illustrates that some coding mistakes are more likely to produce a fault experience than others (because they are more likely to interact with input values in a way that generates a fault experience), and it also shows how the number of inputs values processed before a particular fault is experienced varies between coding mistakes.
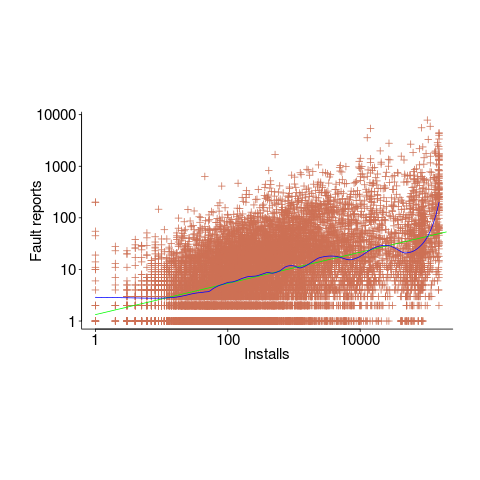
Real-world evidence of the impact of user input on reported faults is provided by the Ultimate Debian Database, which provides information on the number of reported faults and the number of installs for 14,565 packages. The plot below shows how the number of reported faults increases with the number of times a package has been installed; one interpretation is that with more installs there is a wider variety of input values (increasing the likelihood of a fault experience), another is that with more installs there is a larger pool of people available to report a fault experience. Green line is a fitted power law,  , blue line is a fitted loess model.
, blue line is a fitted loess model.
The source containing a mistake may be executed without a fault being experienced; reasons for this include:
- the input values don’t result in the incorrect code behaving differently from the correct code. For instance, given the made-up incorrect code
if (x < 8)(i.e.,8was typed rather than7), the comparison only produces behavior that differs from the correct code whenxhas the value7, - the input values result in the incorrect code behaving differently than the correct code, but the subsequent path through the code produces the intended external behavior.
Some of the studies that have investigated the program behavior after a mistake has deliberately been introduced include:
- checking the later behavior of a program after modifying the value of a variable in various parts of the source; the results found that some parts of a program were more susceptible to behavioral modification (i.e., runtime behavior changed) than others (i.e., runtime behavior not change),
- checking whether a program compiles and if its runtime behavior is unchanged after random changes to its source code (in this study, short programs written in 10 different languages were used),
- 80% of radiation induced bit-flips have been found to have no externally detectable effect on program behavior.
What are the economic costs and benefits of finding and fixing coding mistakes before shipping vs. waiting to fix just those faults reported by customers?
Checking that a software system exhibits the intended behavior takes time and money, and the organization involved may not be receiving any benefit from its investment until the system starts being used.
In some applications the cost of a fault experience is very high (e.g., lowering the landing gear on a commercial aircraft), and it is cost-effective to make a large investment in gaining a high degree of confidence that the software behaves as expected.
In a changing commercial world software systems can become out of date, or superseded by new products. Given the lifetime of a typical system, it is often cost-effective to ship a system expected to contain many coding mistakes, provided the mistakes are unlikely to be executed by typical customer input in a way that produces a fault experience.
Beta testing provides selected customers with an early version of a new release. The benefit to the software vendor is targeted information about remaining coding mistakes that need to be fixed to reduce customer fault experiences, and the benefit to the customer is checking compatibility of their existing work practices with the new release (also, some people enjoy being able to brag about being a beta tester).
- One study found that source containing a coding mistake was less likely to be changed due to fixing the mistake than changed for other reasons (that had the effect of causing the mistake to disappear),
- Software systems don't live forever; systems are replaced or cease being used. The plot below shows the lifetime of 202 Google applications (half-life 2.9 years) and 95 Japanese mainframe applications from the 1990s (half-life 5 years; code+data).
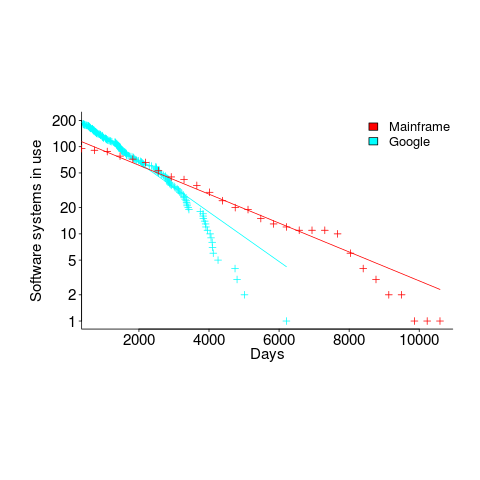
Not only are most coding mistakes not immediately detectable, there may be sound economic reasons for not investing in detecting many of them.
Distorting the input profile, to stress test a program
A fault is experienced in software when there is a mistake in the code, and a program is fed the input values needed for this mistake to generate faulty behavior.
There is suggestive evidence that the distribution of coding mistakes and inputs generating fault experiences both have an influence of fault discovery.
How might these coding mistakes be found?
Testing is one technique, it involves feeding inputs into a program and checking the resulting behavior. What are ‘good’ input values, i.e., values most likely to discover problems? There is no shortage of advice for manually writing tests, suggesting how to select input values, but automatic generation of inputs is often somewhat random (relying on quantity over quality).
Probabilistic grammar driven test generators are trivial to implement. The hard part is tuning the rules and the probability of them being applied.
In most situations an important design aim, when creating a grammar, is to have one rule for each construct, e.g., all arithmetic, logical and boolean expressions are handled by a single expression rule. When generating tests, it does not always make sense to follow this rule; for instance, logical and boolean expressions are much more common in conditional expressions (e.g., controlling an if-statement), than other contexts (e.g., assignment). If the intent is to mimic typical user input values, then the probability of generating a particular kind of binary operator needs to be context dependent; this might be done by having context dependent rules or by switching the selection probabilities by context.
Given a grammar for a program’s input (e.g., the language grammar used by a compiler), decisions have to be made about the probability of each rule triggering. One way of obtaining realistic values is to parse existing input, counting the number of times each rule triggers. Manually instrumenting a grammar to do this is a tedious process, but tool support is now available.
Once a grammar has been instrumented with probabilities, it can be used to generate tests.
Probabilities based on existing input will have the characteristics of that input. A recent paper on this topic (which prompted this post) suggests inverting rule probabilities, so that common becomes rare and vice versa; the idea is that this will maximise the likelihood of a fault being experienced (the assumption is that rarely occurring input will exercise rarely executed code, and such code is more likely to contain mistakes than frequently executed code).
I would go along with the assumption about rarely executed code having a greater probability of containing a mistake, but I don’t think this is the best test generation strategy.
Companies are only interested in fixing the coding mistakes that are likely to result of a fault being experienced by a customer. It is a waste of resources to fix a mistake that will never result in a fault experienced by a customer.
What input is likely to interact with coding mistakes to be the root cause of faults experienced by a customer? I have no good answer to this question. But, given there are customer input contains patterns (at least in the world of source code, and I’m told in other application domains), I would generate test cases that are very similar to existing input, but with one sub-characteristic changed.
In the academic world the incentive is to publish papers reporting loads-of-faults-found, the more the merrier. Papers reporting only a few faults are obviously using inferior techniques. I understand this incentive, but fixing problems costs money and companies want a customer oriented rationale before they will invest in fixing problems before they are reported.
The availability of tools that automate the profiling of a program’s existing input, followed by the generation of input having slightly, or very, different characteristics make it easier to answer some very tough questions about program behavior.
Top, must-read paper on software fault analysis
What is the top, must read, paper on software fault analysis?
Software Reliability: Repetitive Run Experimentation and Modeling by Phyllis Nagel and James Skrivan is my choice (it’s actually a report, rather than a paper). Not only is this report full of interesting ideas and data, but it has multiple replications. Replication of experiments in software engineering is very rare; this work was replicated by the original authors, plus Scholz, and then replicated by Janet Dunham and John Pierce, and then again by Dunham and Lauterbach!
I suspect that most readers have never heard of this work, or of Phyllis Nagel or James Skrivan (I hadn’t until I read the report). Being published is rarely enough for work to become well-known, the authors need to proactively advertise the work. Nagel, Dunham & co worked in industry and so did not have any students to promote their work and did not spend time on the academic seminar circuit. Given enough effort it’s possible for even minor work to become widely known.
The study run by Nagel and Skrivan first had three experienced developers independently implement the same specification. Each of these three implementations was then tested, multiple times. The iteration sequence was: 1) run program until fault experienced, 2) fix fault, 3) if less than five faults experienced, goto step (1). The measurements recorded were fault identity and the number of inputs processed before the fault was experienced.
This process was repeated 50 times, always starting with the original (uncorrected) implementation; the replications varied this, along with the number of inputs used.
For a fault to be experienced, there has to be a mistake in the code and the ‘right’ input values have to be processed.
How many input values need to be processed, on average, before a particular fault is experienced? Does the average number of inputs values needed for a fault experience vary between faults, and if so by how much?
The plot below (code+data) shows the numbers of inputs processed, by one of the implementations, before individual faults were experienced, over 50 runs (sorted by number of inputs):

Different faults have different probabilities of being experienced, with fault a being experienced on almost any input and fault e occurring much less frequently (a pattern seen in the replications). There is an order of magnitude variation in the number of inputs processed before particular faults are experienced (this pattern is seen in the replications).
Faults were fixed as soon as they were experienced, so the technique for estimating the total number of distinct faults, discussed in a previous post, cannot be used.
A plot of number of faults found against number of inputs processed is another possibility. More on that another time.
Suggestions for top, must read, paper on software faults, welcome (be warned, I think that most published fault research is a waste of time).
Fault density: so costly to calculate that few values are reliable
Fault density (i.e., number of faults per thousand lines of code) often appears in claims relating to software quality.
Fault density sounds like a very useful value to know; unfortunately most quoted values are meaningless and because obtaining reliable data is very costly.
The starting point for calculating fault density is the number of reported faults (I will leave the complexity of what constitutes a line of code for a future post). Most faults don’t get reported.
If there are no reported faults, fault density is zero. The more often software is executed the more likely a fault will be experienced (i.e., the large the range of input values thrown at a program the more likely it will go down a path containing a fault). Comparing like-with-like requires knowing how many different kinds of input a program processed to experience a given number of faults; we don’t want to fall into the trap of claiming heavily used code is less fault prone than lightly used code.
What counts as a fault? One study found that 46% of reported faults in Open Source bug tracking systems were misclassified (e.g., a fault report was actually a request for enhancement). Again, comparing like-with-like requires agreement on what constitutes a fault.
How should faults in code that is no longer shipped be counted? If the current version of a program contains 100K lines and previous versions contained 50K lines that have been deleted, should the faults in those 50K lines contribute to the fault density of the current program? I would say not, which means somebody has to figure out which reported faults apply to code in the current version of the program.
I am aware of less than half a dozen fault density values that I would consider reliable (most calculated during the Rome period). Everything else is little better than reading tea-leafs.
Power consumed by different instruction operand value pairs
We are all used to the idea that program performance (e.g., cpu, storage and power consumption) varies across different input data values. A very interesting new paper illustrates how the power consumption of individual instructions varies as instruction operand values change.
The graph below (thanks to Kerstin for sending me a color version, scale is in Joules) is a heatmap of the power consumed by the 8-bit multiply instruction of an XMOS XCore Atmel AVR cpu for all possible 8-bit values (with both operands in registers and producing a 16-bit result). Spare a thought for James Pallister who spent weeks of machine time properly gathering this data; by properly I mean he took account of the variability of modern processor power consumption and measured multiple devices (to relax James researches superoptimizing for minimal power consumption).
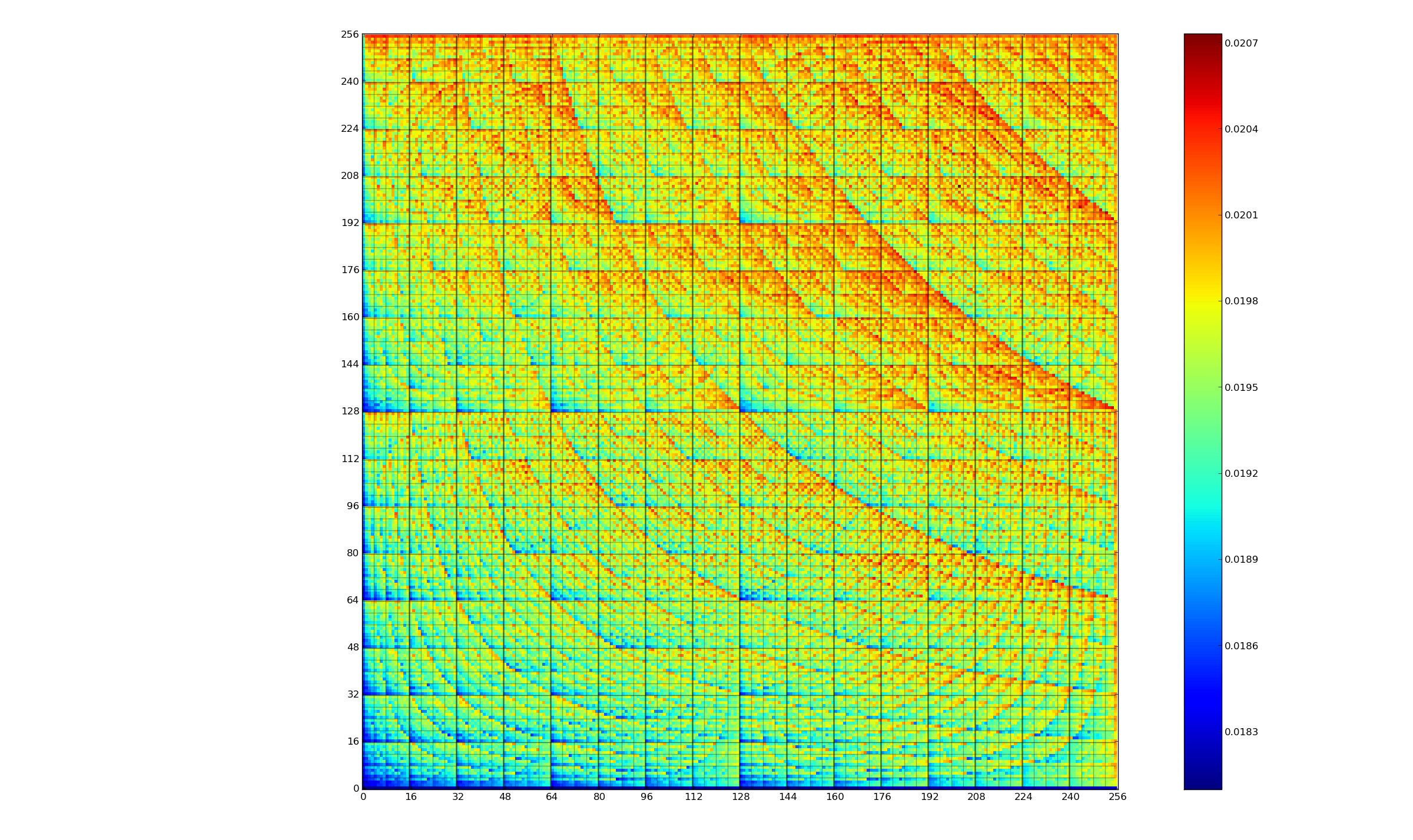
Why is power consumption not symmetric across the diagonal from bottom left to top right? I naively assumed power consumption would be independent of operand order. Have a think before seeing one possible answer further down.
The important thing you need to know about digital hardware power consumption is that change of state (i.e., 0-to-1 or 1-to-0) is what consumes most of the power in digital circuits (there is still a long way to go before the minimum limit set by the Margolus–Levitin theorem is reached).
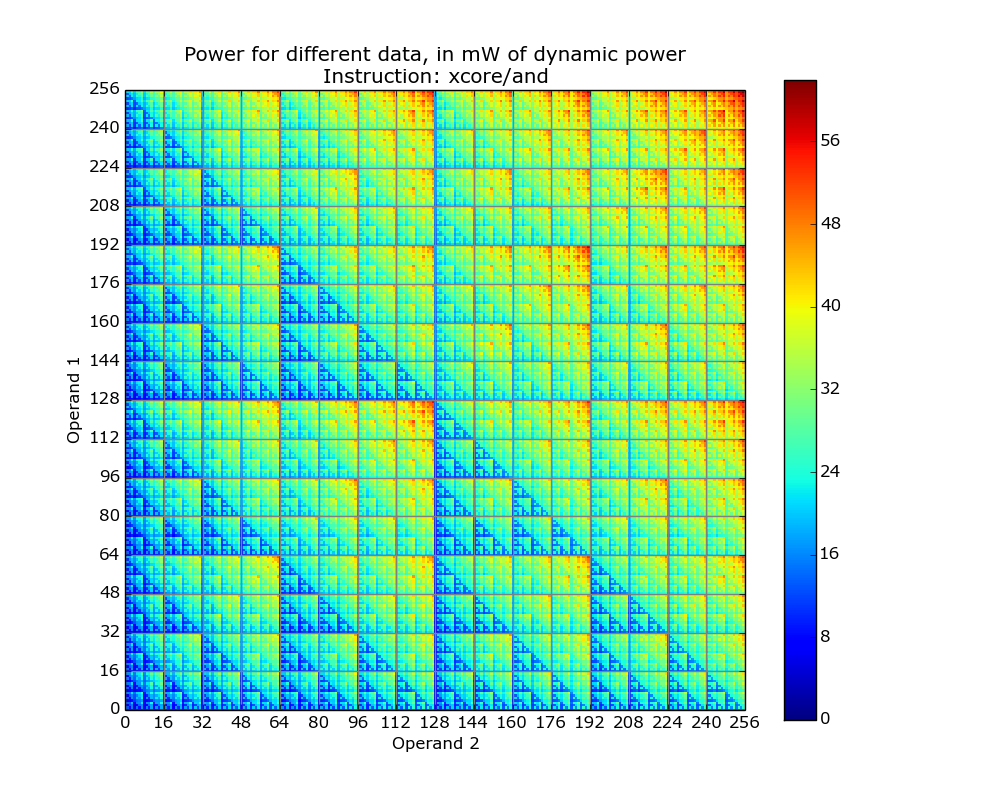
The plot below is for the bit-wise AND instruction on a XMOS XCore cpu and its fractal-like appearance maps straight to the changing bit-patterns generated by the instruction (Jeremy Morse did this work).
Anyone interested in doing their own power consumption measurements should get a MAGEEC Energy Measurement Kit and for those who are really hardcore the schematics are available for you to build one yourself.
Why is power consumption asymmetrical? Think of paper and pencil multiplication, the smaller number is written under the larger number to minimise the number of operations that need to be performed. The ‘popular’ explanation of the top plot is that the cpu does the multiply in whatever order the operand values happen to be in, i.e., not switching the values to minimise power consumption. Do you know of any processors that switch operand order to minimise power consumption? Would making this check cost more than the saving? Chip engineers, where are you?
A plug for the ENTRA project and some of the other people working with James, Kerstin and Jeremy: Steve Kerrison and Kyriakos Georgiou.
Programs spent a lot of time repeating themselves
Inexperienced software developers are always surprised that programs used by lots of people can contain many apparently non-trivial faults and yet continue to operate satisfactorily; experienced developers become familiar with this state of affairs and tend to shrug their shoulders. I have previously written about how software is remarkably fault tolerant. I think this fault tolerance is telling us something important about the characteristics of software and while I have some ideas about what it might be I don’t yet have a good handle (or data) on what is going on to lay out my argument.
In this article I’m going to talk about another characteristic of program execution which I think is connected to program fault tolerance and is also very surprising.
Software differs from hardware in that for a given set of inputs a program will always produce the same output, it will not wear out like hardware and eventually do something different (to simplify things I’m ignoring the possible consequences of uninitialized variables and treating any timing dependencies as part of the input set). So for a fault to be observed different input is required (assuming one exists and none appeared for the first input set).
I used to assume that during a program’s execution the basic cpu operations (e.g., binary arithmetic and bitwise operations) processed a huge number of different combinations of input values (e.g., there are  combinations of input value for a 16-bit add operation) and was very surprised to find out this is not the case. For many programs around 80% of all executed instructions are repeat instructions, that is a given instruction, such as add, operates on the same combinations of input values that it has previously operated on (while executing the program) to generate an output value that is identical to the one previously generated from these input values. If we count the number of static instructions in the program (i.e., the number of assembly instructions in a listing of the disassembled executable program) then 20% of them account for 90% of the repeated instructions; so a small amount of code (i.e., 20%) is not only responsible for most dynamically executed instructions but around 72% (i.e., 80%*90%) of these instructions repeat previous computations. If a large percentage of a what goes on internally within a program is repetition is it any surprise that once it works for a reasonable set of inputs it will probably work on other inputs?
combinations of input value for a 16-bit add operation) and was very surprised to find out this is not the case. For many programs around 80% of all executed instructions are repeat instructions, that is a given instruction, such as add, operates on the same combinations of input values that it has previously operated on (while executing the program) to generate an output value that is identical to the one previously generated from these input values. If we count the number of static instructions in the program (i.e., the number of assembly instructions in a listing of the disassembled executable program) then 20% of them account for 90% of the repeated instructions; so a small amount of code (i.e., 20%) is not only responsible for most dynamically executed instructions but around 72% (i.e., 80%*90%) of these instructions repeat previous computations. If a large percentage of a what goes on internally within a program is repetition is it any surprise that once it works for a reasonable set of inputs it will probably work on other inputs?
Hang on you say, perhaps the percentage of repeat instructions is very high for a given set of external input values (e.g., a file to compress, compile or display as a jpeg) but there is a lot of variation in the set of repeat instructions between different external inputs. Measurements suggest this is not the case, with around 20% of dynamic instructions having input values that can be traced to external program input (12-30% come from globally initialized variables and the rest are generated internally).
There is a technical detail that reduces the repeat instruction percentages given about by a factor of two; researchers always like to give the most favorable numbers and for this discussion we need to make a distinction between local repetition which counts one instruction and its inputs/outputs at a particular point in the code and global repetition which counts all instructions of a given kind irrespective of where they occur in the code. A discussion of fault behavior needs to look at local repetition, not global repetition; there is a factor of two difference in the dynamic percentage and some reduction in the percentage of static instructions involved.
Sometimes the term redundant computation is used, as if the cpu should remember what happened last time it executed an instruction with a particular set of inputs and reuse the answer it got last time. Researchers have proposed caching the results of executing an instruction with a given set of input values and speeding things up or saving power by reusing previous results rather than recalculating them (a possible speedup of 13% on SPEC95 is claimed for a reuse buffer containing 4096 entries).
So a small percentage of the instructions in a program account for most of the execution time (a generally known characteristic) and around 30% of the executed instructions operate on input values they have processed before to produce output they have produced before (to the extent that a cache containing a few thousand entries is big enough to hold the a large percentage of the duplicates). If encountering a new fault requires different execution behavior to occur then having a large percentage of a program always doing the same thing (i.e., same input values same output value) will have a significant impact on the likelihood of encountering a fault. Part of the reason programs are fault tolerant is because external input values don’t have a big an impact on program behavior as we might have thought.
Researchers have also investigated repeats involving units larger than one instruction, such as sub-blocks (a sequence of instructions smaller than a basic block) and even complete functions or just the mathematical ones.
The raw data is obtained using cpu simulators to monitor programs as they are executed, logging the values read as input by an instruction and the value generated as output (in most cases the values are read from registers and written to a register). A single study might log billions of instructions from the SPEC benchmark.
Recent Comments