Archive
Identifier names chosen to hold the same information
Identifier naming is a contentious issue dominated by opinions and existing habits, with almost no experimental evidence (rather like software engineering practices in general).
One study found that around 40% of all non-white-space characters in the visible source of C programs are identifiers (comments representing 31% of the characters in the .c files), representing 29% of the visible tokens in the .c files.
Some years ago I spent a long time studying the word related experiments run by psychologists, looking for possible parallels with identifier usage. The crucial identifier naming factor is the semantic associations a name triggers in the reader’s mind. Choosing a name requires making a cost-benefit tradeoff. The greater quantity of information that might be communicated by longer names has to be balanced against both the cost of reading the name and ignoring the name when searching for other information.
The semantic association network present in a person’s head is the result of the words they have encountered and the context in which they were encountered. Different people are likely to make different associations. Shared culture and experiences increases the likelihood of shared naming associations.
A study by Nelson, McEvoy, and Schreiber gave subjects (over time, 6,000 students at the University of South Florida) a booklet containing 100 words, and asked them to write down the first word that came to mind that was meaningfully related or strongly associated to each of these words (data here, a total of 612,627 responses to 5,024 distinct words). The mean number of different responses to the same word was 14.4, with a standard deviation of 5.2.
There are patterns in the names of identifiers. For instance, operands of bitwise and logical operators have names that include words whose semantics is associated with the operations usually performed by these operands, such as: flag, status, state, and mask. One experiment (with a small sample size) found that developers make use of operand names to make operator precedence decisions.
A study by Feitelson, Mizrahi, Noy, Shabat, Eliyahu, and Sheffer, investigated the variable names chosen by developers to hold specific information. The 334 subjects (students and professional developers) were asked to suggest a name for a variable, constant, or data structure based on a description of the information it would contain, plus other questions relating to interpreting the semantics associated with a name.
The authors cite a problem that I think is actually a benefit: “A major problem in studying spontaneous naming is that the description of the context and the question itself necessarily use words.” When writing code a well-chosen name communications information about the context, which helps readers understand what is going on. The authors’ solution to this perceived problem was to give the description in either Hebrew or English (the subjects were native Hebrew speakers who are fluent in English), with subjects providing the name in English.
The answers to the 21 name generation questions had a mean of 53 distinct names (standard deviation 20.2; code and data). The table below shows the names chosen and the number of subjects choosing that name after seeing the description in Hebrew or English, for one of the questions.
Name Hebrew English b_elevator_door_state 1 b_is_door_open 1 curr_state 2 current_doors_state 1 door 3 1 door_current_status 1 door_is_closed 1 door_is_open 1 door_open 3 door_stat 1 door_state 10 12 door_status 4 doorstate 1 1 elevator_door_state 1 1 elevator_state 1 is_closed 1 1 is_door_closed 2 1 is_door_open 11 3 is_door_opened 2 2 is_elevator_open 1 is_o_pen 1 is_open 7 5 is_opened 2 state 1 status 1 status_of_door 1 |
While the names are distinct, some only differ by a permutation of words, e.g., door_is_open and is_door_open, or with one word missing, e.g., door_open and is_open, or two words missing, e.g., door.
If subjects are influenced by the description (e.g., using the word ordering that appears in the description, or only words from the description), the number of unique names would be smaller than if there was no such influence. The impact of influence would be that subjects seeing the English descriptions are likely to produce fewer unique names.
In 13 out of 21 questions, Hebrew subjects produced more unique names. However, a bootstrap test shows that the difference is not statistically significant.
I think a big threat to the validity of the study is only having subjects create one name. Writing software involves creating names for many variables, which has different cost-benefit tradeoffs than when creating a single variable. The names within a program share a common context and developers tend to follow informal patterns so that naming within the code has some degree of consistency. Adhering to these patterns restricts the possible set of names that might be chosen. Also, the existing use of a name may prevent it being reused for a new variable.
Programming competitions are one source for variable names implementing the same specification, at least for short program. Longer programs are more likely to have some variation in the algorithms used to implement the same functionality.
I expect greater consistency of identifier name selection within an LLM than across developers. LLM training will direct them down existing common patterns of usage, plus some random component.
Impact of native language on variable naming
When creating a variable name, to what extent are developers influenced by their native human language?
There is lots of evidence that variable names are either English words, abbreviations of English words, or some combination of these two. Source code containing a large percentage of identifiers using words from other languages does exist, but it requires effort to find; there is a widely expressed view that source should be English based (based on my experience of talking to non-native English speakers, and even the odd paper discussing the issue, e.g., Language matters).
Given that variable names can prove information that reduces the effort needed to understand code, and that most code is only ever read by the person who wrote it, developers should make the most of their expertise in using their native language.
To what extent do non-native English-speaking developers make use of their non-English native language?
I have found it very difficult to even have a discussion around this question. When I broach the subject with non-native English speakers, the response is often along the lines of “our develo0pers speak good English.” I am careful to set the scene by telling them of my interest in naming, and that I think there are benefits for developers to make use of their native language. The use of non-English languages in software development is not yet a subject that is open for discussion.
I knew that sooner or later somebody would run an experiment…
How Developers Choose Names is another interesting experiment involving Dror Feitelson (the paper rather confusingly refers to it as a survey, a post on an earlier experiment).
What makes this experiment interesting is that bilingual subjects (English and Hebrew) were used, and the questions were in English or Hebrew. The 230 subjects (some professional, some student) were given a short description and asked to provide an appropriate variable/function/data-structure name; English was used for 26 of the question, and Hebrew for the other 21 questions, and subjects answered a random subset.
What patterns of Hebrew usage are present in the variable names?
Out of 2017 answers, 14 contained Hebrew characters, i.e., not enough for statistical analysis. This does not mean that all the other variable names were only derived from English words, in some cases Hebrew words appeared via transcription using the 26 English letters. For instance, using “pinuk” for the Hebrew word that means “benefit” in English. Some variables were created from a mixture of Hebrew and English words, e.g., deservedPinuks and pinuksUsed.
Analysing this data requires someone who is fluent in Hebrew and English. I am not a fluent, or even non-fluent, Hebrew speaker. My role in this debate is encouraging others, and at last I have some interesting data to show people.
The paper spends time showing how for personal preferences result in a wide selection of names being chosen by different people for the same quantity. I cannot think of any software engineering papers that have addressed this issue for variable names, but there is lots of evidence from other fields; also see figure 7.33.
Those interested in searching source code for the impact of native-language might like to look at the names of variables appearing as operands of the bitwise and logical operators. Some English words occur much more frequently in the names of these variable, compared to variables that are operands of arithmetic operators, e.g., flag, status, and signal. I predict that non-native English-speaking developers will make use of corresponding non-English words.
Adjectives in source code analysis
The use of adjectives to analysis source code is something of a specialist topic. This post can only increase the number of people using adjectives for this purpose (because I don’t know anybody else who does 😉
Until recently the only adjective related property I used to help analyse source was relative order. When using multiple adjective, people have a preferred order, e.g., in English size comes before color, as in “big red” (“red big” sounds wrong), and adjectives always appear before the noun they modify. Native speakers of different languages have various preferred orders. Source code may appear to only contain English words, but adjective order can provide a clue about the native language of the developer who wrote it, because native ordering leaks into English usage.
Searching for adjective patterns (or any other part-of-speech pattern) in identifiers used to be complicated (identifiers first had to be split into their subcomponents). Now, thanks to Vadim Markovtsev, 49 million token-split identifiers are available. Happy adjective pattern matching (Size Shape Age Color is a common order to start with; adjective pairs are found in around 0.1% of identifiers; some scripts).
Until recently, gradable adjectives were something that I had been vaguely aware of; these kinds of adjectives indicate a position on a scale, e.g., hot/warm/cold water. The study Grounding Gradable Adjectives through Crowdsourcing included some interesting data on the perceived change of an attribute produced by the presence by a gradable adjective. The following plot shows perceived change in quantity produced by some quantity adjectives (code+data):

How is information about gradable adjectives useful for analyzing source code?
One pattern that jumps out of the plot is that variability, between people, increases as the magnitude specified by the adjective increases (the x-axis shows standard deviations from the mean response). Perhaps the x-axis should use a log scale, there are lots of human related response characteristics that are linear on a log scale (I’m using the same scale as the authors of the study; the authors were a lot more aggressive in removing outliers than I have been), e.g., response to loudness of sound and Hick’s law.
At the moment, it looks as if my estimate of the value of a “small x” is going to be relatively closer to another developers “small x“, than our relative estimated value for a “huge x“.
Experimental method for measuring benefits of identifier naming
I was recently came across a very interesting experiment in Eran Avidan’s Master’s thesis. Regular readers will know of my interest in identifiers; while everybody agrees that identifier names have a significant impact on the effort needed to understand code, reliably measuring this impact has proven to be very difficult.
The experimental method looked like it would have some impact on subject performance, but I was not expecting a huge impact. Avidan’s advisor was Dror Feitelson, who kindly provided the experimental data, answered my questions and provided useful background information (Dror is also very interested in empirical work and provides a pdf of his book+data on workload modeling).
Avidan’s asked subjects to figure out what a particular method did, timing how long it took for them to work this out. In the control condition a subject saw the original method and in the experimental condition the method name was replaced by local and parameter names were replaced by single letter identifiers; in all cases the method name was replaced by xxx andxxx. The hypothesis was that subjects would take longer for methods modified to use ‘random’ identifier names.
A wonderfully simple idea that does not involve a lot of experimental overhead and ought to be runnable under a wide variety of conditions, plus the difference in performance is very noticeable.
The think aloud protocol was used, i.e., subjects were asked to speak their thoughts as they processed the code. Having to do this will slow people down, but has the advantage of helping to ensure that a subject really does understand the code. An overall slower response time is not important because we are interested in differences in performance.
Each of the nine subjects sequentially processed six methods, with the methods randomly assigned as controls or experimental treatments (of which there were two, locals first and parameters first).
The procedure, when a subject saw a modified method was as follows: the subject was asked to explain the method’s purpose, once an answer was given (or 10 mins had elapsed) either the local or parameter names were revealed and the subject had to again explain the method’s purpose, and when an answer was given the names of both locals and parameters was revealed and a final answer recorded. The time taken for the subject to give a correct answer was recorded.
The summary output of a model fitted using a mixed-effects model is at the end of this post (code+data; original experimental materials). There are only enough measurements to have subject as a random effect on the treatment; no order of presentation data is available to look for learning effects.
Subjects took longer for modified methods. When parameters were revealed first, subjects were 268 seconds slower (on average), and when locals were revealed first 342 seconds slower (the standard deviation of the between subject differences was 187 and 253 seconds, respectively; less than the treatment effect, surprising, perhaps a consequence of information being progressively revealed helping the slower performers).
Why is subject performance less slow when parameter names are revealed first? My thoughts: parameter names (if well-chosen) provide clues about what incoming values represent, useful information for figuring out what a method does. Locals are somewhat self-referential in that they hold local information, often derived from parameters as initial values.
What other factors could impact subject performance?
The number of occurrences of each name in the body of the method provides an opportunity to deduce information; so I think time to figure out what the method does should less when there are many uses of locals/parameters, compared to when there are few.
The ability of subjects to recognize what the code does is also important, i.e., subject code reading experience.
There are lots of interesting possibilities that can be investigated using this low cost technique.
Linear mixed model fit by REML ['lmerMod']
Formula: response ~ func + treatment + (treatment | subject)
Data: idxx
REML criterion at convergence: 537.8
Scaled residuals:
Min 1Q Median 3Q Max
-1.34985 -0.56113 -0.05058 0.60747 2.15960
Random effects:
Groups Name Variance Std.Dev. Corr
subject (Intercept) 38748 196.8
treatmentlocals first 64163 253.3 -0.96
treatmentparameters first 34810 186.6 -1.00 0.95
Residual 43187 207.8
Number of obs: 46, groups: subject, 9
Fixed effects:
Estimate Std. Error t value
(Intercept) 799.0 110.2 7.248
funcindexOfAny -254.9 126.7 -2.011
funcrepeat -560.1 135.6 -4.132
funcreplaceChars -397.6 126.6 -3.140
funcreverse -466.7 123.5 -3.779
funcsubstringBetween -145.8 125.8 -1.159
treatmentlocals first 342.5 124.8 2.745
treatmentparameters first 267.8 106.0 2.525
Correlation of Fixed Effects:
(Intr) fncnOA fncrpt fncrpC fncrvr fncsbB trtmntlf
fncndxOfAny -0.524
funcrepeat -0.490 0.613
fncrplcChrs -0.526 0.657 0.620
funcreverse -0.510 0.651 0.638 0.656
fncsbstrngB -0.523 0.655 0.607 0.655 0.648
trtmntlclsf -0.505 -0.167 -0.182 -0.160 -0.212 -0.128
trtmntprmtf -0.495 -0.184 -0.162 -0.184 -0.228 -0.213 0.673 |
Word length lexical decision data
Well chosen identifier names can reduce the effort needed to understand the code containing them, compared to badly chosen identifiers.
An identifier might have a name that creates a semantic association in the mind of the reader about the role of the variable within a function definition (e.g., outer_counter) or an association with the information contained in the variable (e.g., max_fruit).
Code is not always read like prose text, developers might quickly scan through the source looking for something. In this case short identifier names are best because it reduces the number of characters that need to be scanned.
If you want to make life difficult for anyone who has to read your code, add a visually boring common prefix to every identifier, e.g., uacc. Readers start looking up a word in memory based in the first few characters while they process the remaining characters in a word, and eye tracking studies have found that that character sequence information is used to plan eye saccades (where to move the eyes next). A short bland sequence can really throw a spanner in the works of our over-learned reading skills.
I once researched a detailed analysis of the issues involved in a cost/benefit analysis of identifier selection. The good news is that I think I covered everything, the bad news is that the various kinds of data on human character sequence usage needed to perform the analysis was/is not available.
Today I got my hands on lots of performance data on the affect of word length on visual word recognition; thanks to Boris New (code and data)
The plot below shows the mean response time of 819 subjects performing a lexical decision task (respond yes/no on whether a character sequence is a word or nonword); each subject was tested on a subset of around 3,000 out of 33,608 words.
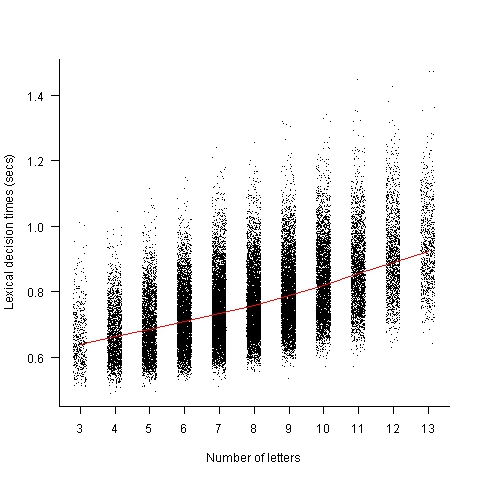
Note, this data is for single words. There are bound to be all sorts of interaction effects when two words/nonwords occur together in an identifier, e.g., semantic priming.
Word length is only one of several factors that have been found to effect people’s performance in processing words; others include the word frequency effect and age of acquisition (when the word was learned, which is correlated with word frequency).
Have fun with this.
My R naming nemesis
When learning a new language I try to make an effort to write it like a native developer. R has one language feature that has been severely testing my desire to write like a native and this afternoon I realized that most of the people reading my code will also experience the same jarring sensation on encountering this construct, so I am not going to use it any more.
What is this language feature that induces a Stroop effect in my mind? It is the use of the period character as part of an identifier’s name (e.g., foo.bar). In almost all of the hundreds of thousands of lines of code I have read over the years this character is used as an operator, it selects a member/field of a struct/record. I’m sure that if I tried long enough and hard enough I could get used to using this character being part of an identifier; after a year or so writing Cobol I got used to the arithmetic minus character being permitted within identifiers (e.g., foo-bar), but that was 20 years ago and my neurons will probably take much longer to adapt this time around.
Most of the R I am writing will be distributed with my book Empirical software engineering with R and I think readers will experience the same jarring sensation I do (apart from those who have not yet been exposed to large amounts of non-R code). I have convinced myself that this is a good enough reason to give up trying to figure out how to use . in identifier name (I have been concocting all sorts of rules involving . being used to separate the primary part of the name and _ the secondary parts, e.g., total.red_light [yes, I should get out more often]; the underscore vs. camel case debate still erupts every now and again, let’s avoid creating more debate by introducing more choice).
Those R functions that include a . in their name will stand out from the crowd, [arm waving on] perhaps this will help differentiate them as ‘statistics stuff'[arm waving off]. There is always plan B if my unilateral naming decision looks too unilateral, a global renaming script.
Perhaps the use of periods in identifiers can be used as a test for being a native R developer. A simple timing test involving a sequence of characters appears on a screen with the developer having to respond as quickly as possible on the number of identifiers being displayed; I’m sure I would be much slower to give a ‘1’ response to total.count than to total_count, displaying total count and total.count on twp separate lines and asking me to quickly specify which line contained the most identifiers would turn me into a nervous wreck. Responses from a dozen or so different sequences ought to be enough be able to distinguish Jonny foreigner from the natives.
I don’t have a problem with $, which R uses as the column/list item selection operator, a character permitted by some compilers for commonly used languages as part of an identifier. This is because I have not read lots of code containing this identifier naming usage.
For my previous book I did a survey of the linguistic and cognitive psychology issues involved in identifier naming. This did a good job of debunking existing ideas about what constitutes good naming practices, but did not come up with any concrete recommendations to replace them (nature abhors a vacuum and the existing pop psychology naming ideas remained).
These days people write PhDs on identifier naming issues (method names, (not yet completed) correlation with quality and code comprehension to name a few); there is even a subfield within this field, how best to split an identifier into its component parts (e.g., refPtr is probably an abbreviation of reference pointer).
Using identifier prefixes results in more developer errors
Human speech communication has to be processed in real time using a cpu with a very low clock rate (i.e., the human brain whose neurons fire at rates between 10-100 Hz). Biological evolution has mitigated the clock rate problem by producing a brain with parallel processing capabilities and cultural evolution has chipped in by organizing the information content of languages to take account of the brains strengths and weaknesses. Words provide a good example of the way information content can be structured to be handled by a very slow processor/memory system, e.g., 85% of English words start with a strong syllable (for more details search for initial in this detailed analysis of human word processing).
Given that the start of a word plays an important role as an information retrieval key we would expect the code reading performance of software developers to be affected by whether the identifiers they see all start with the same letter sequence or all started with different letter sequences. For instance, developers would be expected to make fewer errors or work quicker when reading the visually contiguous sequence consoleStr, startStr, memoryStr and lineStr, compared to say strConsole, strStart, strMemory and strLine.
An experiment I ran at the 2011 ACCU conference provided the first empirical evidence of the letter prefix effect that I am aware of. Subjects were asked to remember a list of four assignment statements, each having the form id=constant;, perform an unrelated task for a short period of time and then recall information about the previously seen constants (e.g., their value and which variable they were assigned to).
During recall subjects saw a list of five identifiers and one of the questions asked was which identifier was not in the previously seen list? When the list of identifiers started with different letters (e.g., cat, mat, hat, pat and bat) the error rate was 2.6% and when the identifiers all started with the same letter (e.g., pin, pat, pod, peg, and pen) the error rate was 5.9% (the standard deviation was 4.5% and 6.8% respectively, but ANOVA p-value was 0.038). Having identifiers share the same initial letter appears to double the error rate.
This looks like great news; empirical evidence of software developer behavior following the predictions of a model of human human speech/reading processing. A similar experiment was run in 2006, this asked subjects to remember a list of three assignment statements and they had to select the ‘not seen’ identifier from a list of four possibilities. An analysis of the results did not find any statistically significant difference in performance for the same/different first letter manipulation.
The 2011/2006 experiments throw up lots of questions, including: does the sharing a prefix only make a difference to performance when there are four or more identifiers, how does the error rate change as the number of identifiers increases, how does the error rate change as the number of letters in the identifier change, would the effect be seen for a list of three identifiers if there was a longer period between seeing the information and having to recall it, would the effect be greater if the shared prefix contained more than one letter?
Don’t expect answers to appear quickly. Experimenting using people as subjects is a slow, labour intensive process and software developers don’t always answer the question that you think they are answering. If anybody is interested in replicating the 2011 experiment the tools needed to generate the question sheets are available for download.
For many years I have strongly recommended that developers don’t prefix a set of identifiers sharing some attribute with a common letter sequence (its great to finally have some experimental backup, however small). If it is considered important that an attribute be visible in an identifiers spelling put it at the end of the identifier.
See you all at the ACCU conference tomorrow and don’t forget to bring a pen/pencil. I have only printed 40 experiment booklets, first come first served.
The complexity of three assignment statements
Once I got into researching my book on C I was surprised at how few experiments had been run using professional software developers. I knew a number of people on the Association of C and C++ Users committee, in particular the then chair Francis Glassborow, and suggested that they ought to let me run an experiment at the 2003 ACCU conference. They agreed and I have been running an experiment every year since.
Before the 2003 conference I had never run an experiment that had people as subjects. I knew that if I wanted to obtain a meaningful result the number of factors that could vary had to be limited to as few as possible. I picked a topic which has probably been the subject of more experiments that any other topics, short term memory. The experimental design asked subjects to remember a list of three assignment statements (e.g., X = 5;), perform an unrelated task that was likely to occupy them for 10 seconds or so, and then recognize the variables they had previously seen within a list and recall the numeric value assigned to each variable.
I knew all about the factors that influenced memory performance for lists of words: word frequency, word-length, phonological similarity, how chunking was often used to help store/recall information and more. My variable names were carefully chosen to balance all of these effects and the information content of the three assignments required slightly more short term memory storage than subjects were likely to have.
The results showed none of the effects that I was expecting. Had I found evidence that a professional software developer’s brain really did operate differently than other peoples’ or was something wrong with my experiment? I tried again two years later (I ran a non-memory experiment the following year while I mulled over my failure) and this time a chance conversation with one of the subjects after the experiment uncovered one factor I had not controlled for.
Software developers are problem solvers (well at least the good ones are) and I had presented them with a problem; how to remember information that appeared to require more storage than available in their short term memories and accurately recall it shortly afterwards. The obvious solution was to reduce the amount of information that needed to be stored by simply remembering the first letter of every variable (which one of the effects I was controlling for had insured was unique) not the complete variable name.
I ran another experiment the following year and still did not obtain the expected results. What was I missing now? I don’t know and in 2008 I ran a non-memory based experiment. I still have no idea what techniques my subjects are using to remember information about three assignment statements that are preventing me getting the results I expect.
Perhaps those researchers out there that claim to understand the processes involved in comprehending a complete function definition can help me out by explaining the mental processes involved in remembering information about three assignment statements.
The probability of encountering a given variable
If I am reading through the body of a function, what is the probability of a particular variable being the next one I encounter? A good approximation can be calculated as follows: Count the number of occurrences of all variables in the function definition up to the current point and work out the percentage occurrence for each of them, the probability of a particular variable being seen next is approximately equal to its previously seen percentage. The following graph is the evidence I give for this approximation.
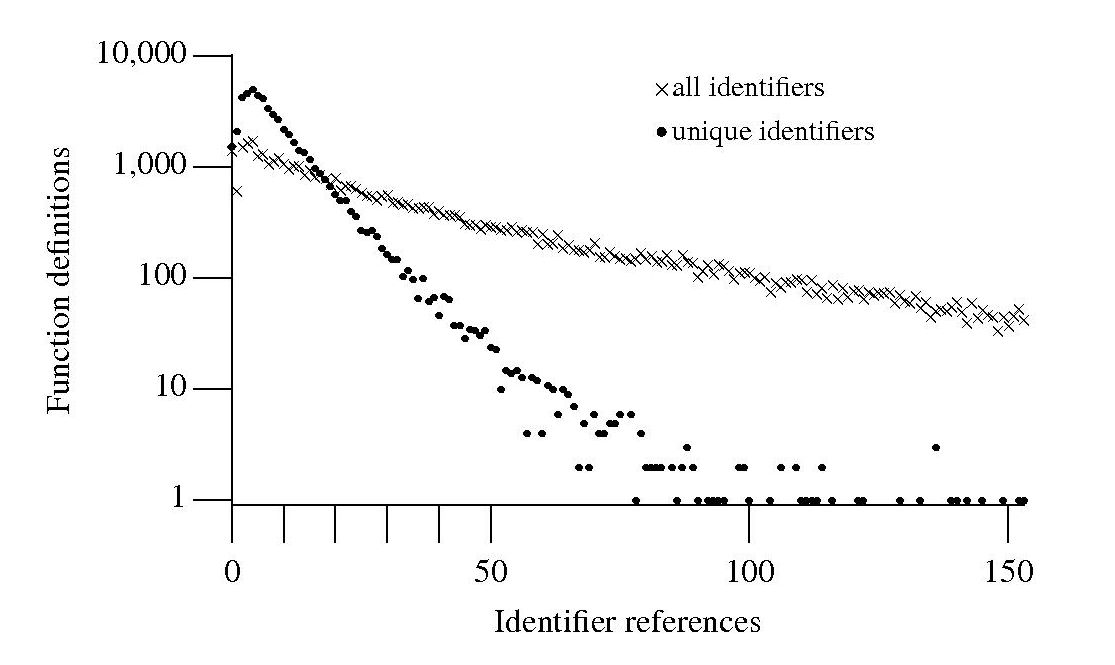
The graph shows a count of the number of C function definitions containing identifiers that are referenced a given number of times, e.g., if the identifier x is referenced five times in one function definition and ten times in another the function definition counts for five and ten are both incremented by one. That one axis is logarithmic and the bullets and crosses form almost straight lines hints that a Zipf-like distribution is involved.
There are many processes that will generate a Zipf distribution, but the one that interests me here is the process where the probability of the next occurrence of an event occurring is proportional to the probability of it having previously occurred (this includes some probability of a new event occurring; follow the link to Simon’s 1955 paper).
One can think of the value (i.e., information) held in a variable as having a given importance and it is to be expected that more important information is more likely to be operated on than less important information. This model appeals to me. Another process that will generate this distribution is that of Monkeys typing away on keyboards and while I think source code contains lots of random elements I don’t think it is that random.
The important concept here is operated on. In x := x + 1; variable x is incremented and the language used requires (or allowed) that the identifier x occur twice. In C this operation would only require one occurrence of x when expressed using the common idiom x++;. The number of occurrences of a variable needed to perform an operation on it, in a given languages, will influence the shape of the graph based on an occurrence count.
One graph does not provide conclusive evidence, but other measurements also produce straightish lines. The fact that the first few entries do not form part of an upward trend is not a problem, these variables are only accessed a few times and so might be expected to have a large deviation.
More sophisticated measurements are needed to count operations on a variable, as opposed to occurrences of it. For instance, few languages (any?) contain an indirection assignment operator (e.g., writing x ->= next; instead of x = x -> next;) and this would need to be adjusted for in a more sophisticated counting algorithm. It will also be necessary to separate out the effects of global variables, function calls and the multiple components involved in a member selection, etc.
Update: A more detailed analysis is now available.
Incorrect spelling
While even a mediocre identifier name can provide useful information to a reader of the source a poorly chosen name can create confusion and require extra effort to remember. An author’s good intent can be spoiled by spelling mistakes, which are likely to be common if the developer is not a native speaker of the English (or whatever natural language is applicable).
Identifiers have characteristics which make them difficult targets for traditional spell checking algorithms; they often contain specialized words, dictionary words may be abbreviated in some way (making phonetic techniques impossible) and there is unlikely to be any reliable surrounding context.
Identifiers share many of the characteristics of search engine queries, they contain a small number of words that don’t fit together into a syntactically correct sentence and any surrounding context (e.g., previous queries or other identifiers) cannot be trusted. However, search engines have their logs of millions of previous search queries to fall back on, enabling them to suggest (often remarkably accurate) alternatives to non-dictionary words, specialist domains and recently coined terms. Because developers don’t receive any feedback on their spelling mistakes revision control systems are unlikely to contain any relevant information that can be mined.
One solution is for source code editors to require authors to fully specify all of the words used in an identifier when it is declared; spell checking and suitable abbreviation rules being applied at this point. Subsequent uses of the identifier can be input using the abbreviated form. This approach could considerably improve consistency of identifier usage across a project’s source code (it could also flag attempts to use both orderings of a word pair, e.g., number count and count number). The word abbreviation mapping could be stored (perhaps in a comment at the end of the source) for use by other tools and personalized developer preferences stored in a local configuration file. It is time for source code editors to start taking a more active role in helping developers write readable code.
Recent Comments