Archive
Half-life of software as a service, services
How is software used to provide a service (e.g., the software behind gmail) different from software used to create a product (e.g., sold as something that can be installed)?
This post focuses on one aspect of the question, software lifetime.
The Killed by Google website lists Google services and products that are no more. Cody Ogden, the creator of the site, has open sourced the code of the website; there are product start/end dates!
After removing 20 hardware products from the list, we are left with 134 software services. Some of the software behind these services came from companies acquired by Google, so the software may have been used to provide a service pre-acquisition, i.e., some calculated lifetimes are underestimates.
The plot below shows the number of Google software services (blue) having a given lifetime (calculated as days between Google starting/withdrawing service), mainframe software from the 1990s (red; only available at yearly resolution), along with fitted exponential regression lines (code+data):
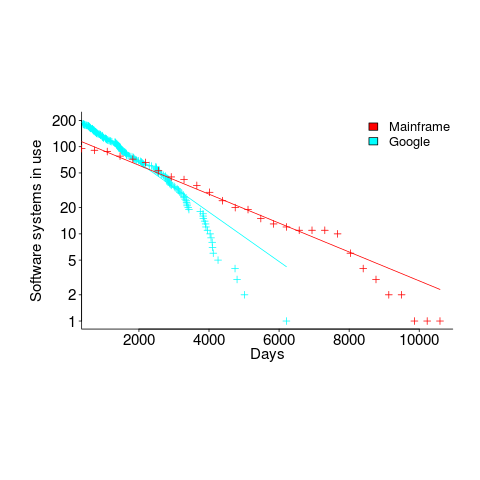
Overall, an exponential is a good fit (squinting to ignore the dozen red points), although product culling is not exponentially ruthless at short lifetimes (newly launched products are given a chance to prove themselves).
The Google service software half-life is 1,500 days, about 4.1 years (assuming the error/uncertainty is additive, if it is multiplicative {i.e., a percentage} the half-life is 1,300 days); the half-life of mainframe software is 2,600 days (with the same assumption about the kind of error/uncertainty).
One explanation of the difference is market maturity. Mainframe software has been evolving since the 1950s and probably turned over at the kind of rate we saw a few years ago with Internet services. By the 1990s things had settled down a bit in the mainframe world. Will software-based services on the Internet settle down faster than mainframe software? Who knows.
Based on this Google data, the cost/benefit ratio when deciding whether to invest in reducing future software maintenance costs, is going to have to be significantly better than the ratio calculated for mainframe software.
Software system lifetime data is extremely hard to find (this is only the second set I have found). Any pointers to other lifetime data very welcome, e.g., a collection of Microsoft product start/end dates 🙂
APIs can, for the time being, be copyrighted
There was an interesting turn of events in the Oracle vs. Google Java API lawsuit last friday. The original trial judge had ruled that an API are not copyrightable; last week the US federal Court of appeals reversed this decision, APIs are copyrightable. This legal battle is not over and the ruling can flip and flop its way up to the US supreme court, and not being a lawyer I’m happy to leave the legal discussion to others. Let’s assume that Oracle eventually win their Java API copyright claim, what does that mean for computer language usage and software developers?
If Oracle’s API copyright claim is upheld then they are potentially in line for a huge payout (Google might get to wiggle out of paying much via a fair use justification). I’m sure that some people will claim that this ‘win’ will kill off Java, even if this is true (I don’t think it is), what do the suits care? Give me a billion dollars and I will happily support the removal of any computer language from planet Earth.
In the early days of Android Google needed Java compatibility more than Java needed anything to do with Android. Now Android has such a commanding market share Google does not need to worry so much about Java compatibility. If Oracle had any interest in the future of Java they would be worried that this court case could result in Google switching the Android ecosystem to using a slightly incompatible Java-like language. In practice this court case is the only real opportunity for Oracle to make serious money from their Java intellectual property and they are not that excited about a steady stream of peanuts from future goings on.
What does Oracle winning the API copyright claim mean for developers?
If Google do launch a Java-like language then Java’s “write once run anywhere” mantra will be less true than it currently is (by avoiding a few traps and not straying too far from the well trodden path Java developers can create programs that are remarkable portable). In its market niche there is no other language that comes close to providing the kind of portability that Java offers, so existing users will be annoyed at having to worry about one more portability issue but are unlikely to jump ship.
The much more interesting question is the impact an Oracle win has on other companies producing products that include an API; they now have something to wave at competitors who have API-alike (I just made that word up) products. Any developer using an API that has its very own copyright discussion thread is likely to become a bit twitchy. The general result will be a cloud of uncertainty over some existing APIs from some providers.
Anybody introducing a new API will have to answer the ‘copyright’ question: “Do you claim copyright on your API?” In practice a very very small percentage of APIs ever get copied/cloned, because most fail or the competition comes up with what they think is a better API.
Would I care if a company claims copyright on its API and says it will sue anybody who copies/clones it? Obviously I have to use that API if it is the only way to get a job done, but what if I had a choice between it and a non-copyrighted API? I don’t think the question of copyright would be an issue for me, but I would be concerned if any company was being overly legalistic; do I really want to deal with a company more interested in legal matters than supporting developers? I think not.
Relative spacing of operands affects perception of operator precedence
What I found most intriguing about Google Code Search (shutdown Nov 2011) was how quickly searches involving regular expressions returned matches. A few days ago Russ Cox, the implementor of Code Search not only explained how it worked but also released the source and some precompiled binaries. Google’s database of source code did not include the source of R, so I decided to install CodeSearch on my local machine and run some of my previous searches against the latest (v2.14.1) R source.
In 2007 I ran an experiment that showed developers made use of variable names when making binary operator precedence decisions. At about the same time two cognitive psychologists, David Landy and Robert Goldstone, were investigating the impact of spacing on operator precedence decisions (they found that readers showed a tendency to pair together the operands that were visibly closer to each other, e.g., a with b in a+b * c rather than b with c).
As somebody very interested in finding faults in code the psychologists research findings on spacing immediately suggested to me the possibility that ‘incorrectly’ spaced expressions were a sign of failure to write code that had the intended behavior. Feeding some rather complicated regular expressions into Google’s CodeSearch threw up a number of ‘incorrectly’ spaced expressions. However, this finding went no further than an interesting email exchange with Landy and Goldstone.
Time to find out whether there are any ‘incorrectly’ spaced expressions in the R source. cindex (the tool that builds the database used by csearch) took 3 seconds on a not very fast machine to process all of the R source (56M byte) and build the search database (10M byte; the Linux database is a factor of 5.5 smaller than the sources).
The search:
csearch "w(+|-)w +(*|/) +w" |
returned a few interesting matches:
... modules/internet/nanohttp.c: used += tv_save.tv_sec + 1e-6 * tv_save.tv_usec; modules/lapack/dlapack0.f: $ ( T*( ONE+SQRT( ONE+S / T ) ) ) ) modules/lapack/dlapack2.f: S = Z( 3 )*( Z( 2 ) / ( T*( ONE+SQRT( ONE+S / T ) ) ) ) modules/lapack/dlapack4.f: $ ( T*( ONE+SQRT( ONE+S / T ) ) ) ) |
There were around 15 matches of code like 1e-6 * var (because the pattern w is for alphanumeric sequences and that is not a superset of the syntax of floating-point literals).
The subexpression ONE+S / T is just the sort of thing I was looking for. The three instances all involved code that processed tridiagonal matrices in various special cases. Google search combined with my knowledge of numerical analysis was not up to the task of figuring out whether the intended usage was (ONE+S)/T or ONE+(S/T).
Searches based on various other combination of operator pairs failed to match anything that looked suspicious.
There was an order of magnitude performance difference for csearch vs. grep -R -e (real 0m0.167s vs. real 0m2.208s). A very worthwhile improvement when searching much larger code bases with more complicated patterns.
Program analysis via information leakage
The use of software in high value transactions has created an interesting new field of software research that investigates the leakage of information from programs. The kind of information leaked, so-called sideband information, can take various forms, including:
- The amount of time taken to perform some operation. Many developers instinctively do their best to ensure that code does not take any longer to execute than it has to. In the case of one commonly used authentication system, the time taken to fail to authenticate an encryption key provided useful information on how close one trial encryption-key was compared to another (the closer the trial key to the actual key, the longer the authentication took to fail). The obvious implementation technique to foil this kind of attack is to add random delays into the authentication process.
It has even proved possible to perform timing attacks against a remote machine over the Internet to remote
- Use of some part of the value of secure information, by a system library function, to create the value passed back to the caller, e.g.,
if (secret_value & 0xf000) // Tell the caller that the top 'secret' four bits are set return 1; else return 0;
Researchers have been able to analyse the information flow of input values through some very large C programs.
- Analyse of network traffic routing information to work out who is talking to who. Various kinds of anonymizers have been created in attempt to make various forms of Internet traffic untraceable.
Any Internet program is accessible to information flow analysis. Using these techniques to analyse the search algorithm used by Google might be overly ambitious. A Google algorithm that might be within reach of is the one used by Adwords; the behavior of this algorithm is of interest to a growing number of people.
Information leakage techniques are becoming more widely known and developers working on programs containing a security component now need to consider how they can prevent information being leaked to attackers who sample program behavior looking for exploitable weaknesses.
Recent Comments