Archive
LLMs and doing software engineering research
This week I attended the 65th COW workshop, the theme was Automated Program Repair and Genetic Improvement.
I first learned about using genetic programming to automatically fix reported faults at the 1st COW workshop in 2009. Claire Le Goues, a PhD student at that workshop, now a professor, returned to talk about the latest program repair work of her research group.
COW speakers are usually very upbeat, but uncertainty about the future was the general feeling I got from speakers at this workshop. The cause of this uncertainty was the topic of some talks and conversations: LLMs. Adding an LLM into the program repair process can produce a dramatic performance improvement.
Isn’t a dramatic performance improvement and a new technique great news for everyone? The performance improvement increases the likelihood of industrial adoption, and a new technique creates many opportunities for new research.
Despite claiming otherwise, most academics have zero interest in industrial adoption of their work, and some actively disdain practical uses of their work.
Major new techniques are great for PhD students; they provide an opportunity to kick-start a career by being in at the start of a new research area.
A major new technique can obsolete an established researcher’s expensively acquired area of expertise (expensive in personal time and effort). The expertise that enables a researcher to make state-of-the-art contributions to an active research area is a valuable asset; it can be used to attract funding, students and peer esteem. When a new technique dramatically improves the state-of-the-art, there is a sharp drop in the value of what is now yesterday’s know-how.
A major new technique removes some existing barriers to entering a field, and creates its own new ones. The result is that new people start working in a field, and some existing experts stop working in it.
At the workshop, I saw this process starting in automated program repair, and I imagine it’s also starting in many other research fields. It will probably take 3–5 years for the dust to start to settle; existing funded projects have to complete, and academia does not move that quickly.
A recent review of the use of LLMs in software engineering research found 229 papers; the table below shows the number of papers per year:
Papers Year
7 2020
11 2021
51 2022
160 2023 to end July |
Assuming, say, 10K software engineering papers per year, then LLM related papers should be around 3% this year, likely in double figures next year, and possibly over 50% the year after.
Is research in software engineering en route to becoming another subfield of prompt engineering research?
Percolation of the impact of coding mistakes through a program
Programs containing serious coding mistakes can sometimes work surprisingly well. Experienced developers invariably have a story to tell about a program in production use that contained a coding mistake so bad, that it should have prevented the program producing any reliably output. My story relates to a Z80 cpu emulator I had written, which was successfully booting/running CP/M and several applications. One application was sometimes behaving erratically. I eventually traced the problem to the implementation of one of the add instructions (there are 13 special cases), which had been cut/pasted from the implementation of the corresponding subtract instruction, except that I had forgotten to change the result calculation from using a subtract to using an add, i.e., the instruction was performing a subtract, not an add. I was flabbergasted that so much emulated code appeared to be working in the presence of what to me was a crippling coding mistake.
There have been a handful of studies investigating the ability of programs containing coding mistakes to function correctly, or at least well enough to be usable.
- The earliest paper I have found is from 2005; Rinard, Cadar and Nguyen changed the termination condition of 326
for-loopsin the Pine email client, with<becoming<=, and>becoming>=. While the resulting program exhibited obvious anomalies, the researchers were able to use it to send and receive email, - a study by Danglot, Preux, Baudry and Monperrus investigated the propagation of single perturbations in 10 short Java programs (42 to 568 LOC, perturbed by adding/subtracting 1 from an expression somewhere in the code). The plot below shows the likelihood that a perturbation at some point in the code will have no impact on the output; code+data,

- a study by Cho of the impact of soft errors (i.e., radiation induced bit-flips) found that over 80% of bit-flips had no detectable impact on program behavior.
This week I attended the 63rd CREST Open Workshop; the topic was genetic improvement of software, i.e., GI randomly combines members of a population of programs, only keeping the children that pass some fitness test, rinses and repeats until one or more programs reach some acceptance threshold.
The GI community recently discovered that program output is often unaffected by a small perturbation to program execution, e.g., randomly adding one to the result of a binary operation.
A study by Langdon, Al-Subaihin and Clark tracked the effect of perturbations in the evaluation of an expression tree. The expression trees were created using genetic programming, with the fitness function being the difference between the value obtained by evaluating the expression tree and a sixth order polynomial. The binary operators in the expression tree were multiply and addition, with the leaf node value, x, taking a value between -0.97789 and 0.979541; the trees were a lot deeper than the one below, containing between 8.9k and 863k nodes/leafs, with tree depth varying from 121 to 5,103.
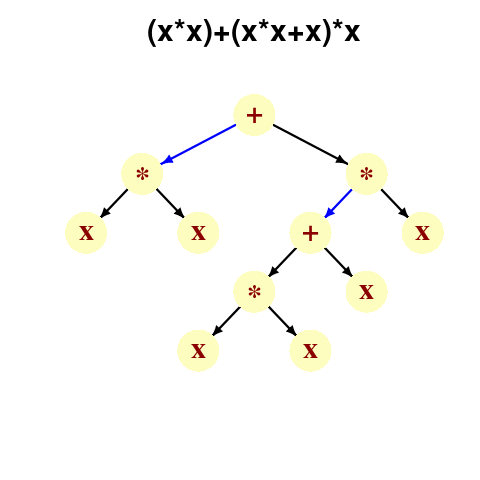
During the evaluation of an expression tree the result of one of the multiply/add operations was perturbed by adding one to its value. The subsequent evaluation of the remainder of the expression tree was tracked, comparing original/perturbed calculated values until either the root node was reached (and the final result was different), or the original/perturbed subtree result values synchronized, i.e., became the same. The distance, in nodes, between perturbation and value synchronization was recorded.
In all, ten expression trees were created, and each node in every tree was perturbed once per run; there were 10 runs using 10 different values of x.
The plot below shows results from two expression trees (different colors). Each point is the distance before original/perturbed values synchronised (for those cases where this happened) against the number of runs having this distance (for the same tree; code+data, and thanks to Bill for explaining things):
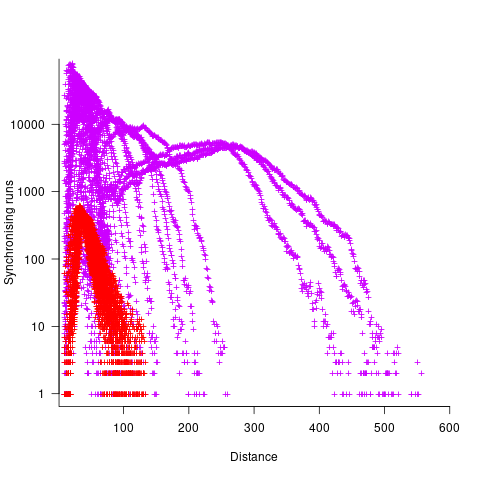
For the larger tree, there is a distinct pattern for each of the ten input values, x. This shows that synchronisation distance can be affected by the input value (which is to be expected). Perhaps this pattern is not present in the smaller tree, or the points are too close together to see it.
The opportunities available to a perturbation for travelling some distance depends on the size and characteristics of the expression tree, with a large thin tree providing more opportunities for longer distance travel than a large bushy tree.
It will take some well thought through experiments to unpick the contributions made by the tree characteristics, problem characteristics, and the prevalence of binary operators unlikely to be affected by small changes to their operand value, e.g., there is roughly a 50% chance that a relational comparison will be unaffected by a small change to one of its operands.
If you know of any other studies investigating coding mistake percolation, please let me know.
Tool for tuning the use of floating-point types
A common problem when writing code that performs floating-point arithmetic is figuring out which of the available three (usually) possible floating-point types to use (e.g., float, double or long double). Some language ‘solve’ this problem by only having one possibility (e.g., R) and some implementations of languages that offer three types use the same representation for all of them (e.g., 32 bits).
The type float often represents the least precision/range of values but occupies the smallest amount of storage and operations on it have traditionally been the fastest, type long double often represents the greatest precision/range of values but occupies the most storage and operations on it are generally the slowest. Applying the Goldilocks principle the type double is very often selected.
Anyone who has worked with floating-point values will be familiar with some of the ways they can bite very hard. Once a function that uses floating-point types is written the general advice is to leave it alone.
Precimonious is an interesting new tool that searches for possible performance/accuracy trade-offs; it randomly selects a floating-point declaration, changes the type used, executes the resulting program and compares the output against that produced by the original program. Users of the tool specify the maximum error (difference in output values) they are willing to accept and Precimonious searches for a combination of changes to the floating-point types contained within a program that result in a faster program that does not exceed this maximum error.
The performance improvements cited in the paper (which includes the doyen of floating-point in its long list of authors) cluster around zero and worthwhile double figure percentage (max 41.7%); sometimes no improvements were found until the maximum error was reduced from  to
to  .
.
Perhaps a combination of Precimonious and a tool that attempts to improve accuracy is the next step 🙂
There is resistance to using search based methods to fix faults. Perhaps tools like Precimonious will help developers get used to the idea of search assisted software development.
I wonder how long it will be before we see commentary in bug reports such as the following:
- that combination of values was not in the Precimonious test set,
- Precimonious cannot find a sufficiently optimized program within the desired error tolerance for that rarely seen combination of values. Won’t fix.
Programming using genetic algorithms: isn’t that what humans already do ;-)
Some time ago I wrote about the use of genetic programming to fix faults in software (i.e., insertion/deletion of random code fragments into an existing program). Earlier this week I was at a lively workshop, Genetic Programming for Software Engineering, with some of the very active researchers in this new subfield.
The genetic algorithm works by having a population of different programs, selecting X% of the best (as measured by some fitness function), making random mutations to those chosen and/or combining bits of programs with other programs; these modified programs are fed back to the fitness function and the whole process iterates until an acceptable solution is found (or a maximum iteration limit is reached).
There are lots of options to tweak; the fitness function gets to decide who has children and is obviously very important, but it can only work with what get generated by the genetic mutations.
The idea I was promoting, to anybody unfortunate enough to be standing in front of me, was that the pattern of usage seen in human written code provides lots of very useful information for improving the performance of genetic algorithms in finding programs having the desired characteristics.
I think that the pattern of usage seen in human written code is driven by the requirements of the problems being solved and regular occurrence of the same patterns is an indication of the regularity with which the same requirements need to be met. As a representation of commonly occurring requirements these patterns are pre-tuned templates for genetic mutation and information to help fitness functions make life/death decisions (i.e., doesn’t look human enough, die!)
There is some noise in existing patterns of code usage, generated by random developer habits and larger fluctuations caused by many developers following the style in some popular book. I don’t have a good handle on estimating the signal to noise ratio.
There has been some work comparing the human maintainability of patches that have been written by genetic algorithms/humans. One of the driving forces behind this work is the expectation that the final patch will still be controlled by humans; having a patch look human-written like is thought to increase the likelihood of it being ‘accepted’ by developers.
Genetic algorithms are also used to improve the runtime performance of programs. Bill Langdon reported that the authors of a program ‘he’ had speeded up by a factor of 70 had not responded to his emails. This may be a case of the authors not knowing how to handle something somewhat off the beaten track; it took a while for Linux developers to start responding to batches of fault reports generated as part of software analysis projects by academic research groups.
One area where human-like might not always be desirable is test case generation. It is easy to find faults in compilers by generating random source code (the syntax/semantics of the randomness follows the rules of the language standard). This approach results in an unmanageable number of fault. Is it worth fixing a fault generated by code that looks like it would never be written by a person? Perhaps the generator should stick to producing test cases that at least look like the code might be written by a person.
Software maintenance via genetic programming
Genetic algorithms have been used to find solution to a wide variety of problems, including compiler optimizations. It was only a matter of time before somebody applied these techniques to fixing faults in source code.
When I first skimmed the paper “A Genetic Programming Approach to Automated Software Repair” I was surprised at how successful the genetic algorithm was, using as it did such a relatively small amount of cpu resources. A more careful reading of the paper located one very useful technique for reducing the size of the search space; the automated software repair system started by profiling the code to find out which parts of it were executed by the test cases and only considered statements that were executed by these tests for mutation operations (they give a much higher weighting to statements only executed by the failing test case than to statements executed by the other tests; I am a bit surprised that this weighting difference is worthwhile). I hate to think of the amount of time I have wasted trying to fix a bug by looking at code that was not executed by the test case I was running.
I learned more about this very interesting system from one of the authors when he gave the keynote at a workshop organized by people associated with a source code analysis group I was a member of.
The search space was further constrained by only performing mutations at the statement level (i.e., expressions and declarations were not touched) and restricting the set of candidate statements for insertion into the code to those statements already contained within the code, such as if (x != NULL) (i.e., new statements were not randomly created and existing statements were not modified in any way). As measurements of existing code show most uses of a construct are covered by a few simple cases and most statements are constructed from a small number of commonly used constructs. It is no surprise that restricting the candidate insertion set to existing code works so well. Of course no fault fix that depends on using a statement not contained within the source will ever be found.
There is ongoing work looking at genetic modifications at the expression level. This
work shares a problem with GA driven test coverage algorithms; how to find ‘magic numbers’ (in the case of test coverage the magic numbers are those that will cause a controlling expression to be true or false). Literals in source code, like those on the web, tend to follow a power’ish law but the fit to Benford’s law is not good.
Once mutated source that correctly processes the previously failing test case, plus continuing to pass the other test cases, has been generated the code is passed to the final phase of the automated software repair system. Many mutations have no effect on program behavior (the DNA term intron is sometimes applied to them) and the final phase removes any of the added statements that have no effect on test suite output (Westley Weimer said that a reduction from 50 statements to 10 statements is common).
Might the ideas behind this very interesting research system end up being used in ‘live’ software? I think so. There are systems that operate 24/7 where faults cost money. One can imagine a fault being encountered late at night, a genetic based system fixing the fault which then updates the live system, the human developers being informed and deciding what to do later. It does not take much imagination to see the cost advantages driving expensive human input out of the loop in some cases.
An on-going research topic is the extent to which a good quality test suite is needed to ensure that mutated fault fixes don’t introduce new faults. Human written software is known to often be remarkably tolerant to the presence of faults. Perhaps ensuring that software has this characteristic is something that should be investigated.
Recent Comments