Archive
Benchmarking fuzzers
Fuzzing has become a popular area of research in the reliability & testing community, with a stream of papers claiming to have created a better tool/algorithm. The claims of ‘betterness’, made by the authors, often derive from the number of previously unreported faults discovered in some collection of widely used programs.
Developers in industry will be interested in using fuzzing if it provides a cost-effective means of discovering coding mistakes that are likely to result in customers experiencing a serious fault. This requirement roughly translates to: minimal cost for finding maximal distinct mistakes (finding the same mistake more than once is wasted effort); whether a particular coding mistake is likely to produce a serious customer fault is a decision decided by people.
How do different fuzzing tools compare, when benchmarking the number of distinct mistakes they each find, for a given amount of cpu time?
TL;DR: I don’t know, and this approach is probably not a useful way of comparing fuzzers.
Fuzzing researchers are currently competing on the number of previously unreported faults discovered, i.e., not listed in the fuzzed program’s database of fault reports. Most research papers only report the number of distinct faults discovered in each program fuzzed, the amount of wall clock hours/days used (sometimes weeks), and the characteristics of the computer/cluster on which the campaign was run. This may be enough information to estimate an upper bound on faults per unit of cpu time; more detailed data is rarely available (I have emailed the authors of around a dozen papers asking for more detailed data).
A benchmark based on comparing faults discovered per unit of cpu time only makes sense when the new fault discovery rate is roughly constant. Experience shows that discovery time can vary by orders of magnitude.
Code coverage is a fuzzer performance metric that is starting to be widely used by researchers. Measures of coverage include: statements/basic blocks, conditions, or some object code metric. Coverage has the advantage of providing defined fuzzer objectives (e.g., generate input that causes uncovered code to be executed), and is independent of the number of coding mistakes present in the code.
How is a fuzzer likely to be used in industry?
The fuzzing process may be incremental, discovering a few coding mistakes, fixing them, rinse and repeat; or, perhaps fuzzing is run in a batch over, say, a weekend when the test machine is available.
The current research approach is batch based, not fixing any of the faults discovered (earlier researchers fixed faults).
Not fixing discovered faults means that underlying coding mistakes may be repeatedly encountered, which wastes cpu time because many fuzzers terminate the run when the program they are testing crashes (a program crash is a commonly encountered fuzzing fault experience). The plot below shows the number of occurrences of the same underlying coding mistake, when running eight fuzzers on the program JasPer; 77 distinct coding mistakes were discovered, with three fuzzers run over 3,000 times, four run over 1,500 times, and one run 62 times (see Green Fuzzing: A Saturation-based Stopping Criterion using Vulnerability Prediction by Lipp, Elsner, Kacianka, Pretschner, Böhme, and Banescu; code+data):
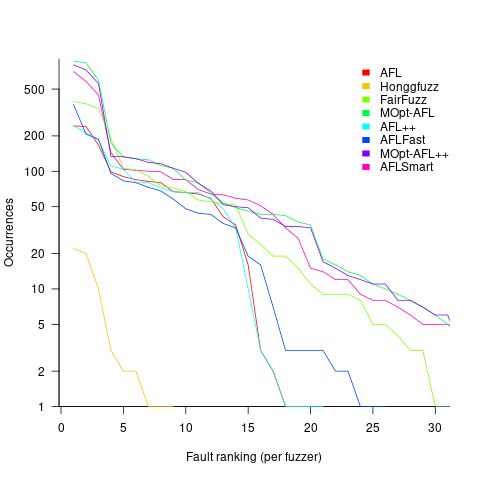
I have not seen any paper where the researchers attempt to reduce the number of times the same root cause coding mistake is discovered. Researchers are focused on discovering unreported faults; and with around 98% of fault discoveries being duplicates, appear to have resources to squander.
If developers primarily use a find/fix iterative process, then duplicate discoveries will be an annoying drag on cpu time. However, duplicate discoveries are going to make it difficult to effectively benchmark fuzzers.
Mutation testing: its days in the limelight are over
How good a job does a test suite do in detecting coding mistakes in the program it tests?
Mutation testing provides one answer to this question. The idea behind mutation testing is to make a small change to the source code of the program under test (i.e., introduce a coding mistake), and then run the test suite through the mutated program (ideally one or more tests fail, as-in different behavior should be detected); rinse and repeat. The mutation score is the percentage of mutated programs that cause a test failure.
While Mutation testing is 50-years old this year (although the seminal paper did not get published until 1978), the computing resources needed to research it did not start to become widely available until the late 1980s. From then, until fuzz testing came along, mutation testing was probably the most popular technique studied by testing researchers. A collected bibliography of mutation testing lists 417 papers and 16+ PhD thesis (up to May 2014).
Mutation testing has not been taken up by industry because it tells managers what they already know, i.e., their test suite is not very good at finding coding mistakes.
Researchers concluded that the reason industry had not adopted mutation testing was that it was too resource intensive (i.e., mutate, compile, build, and run tests requires successively more resources). If mutation testing was less resource intensive, then industry would use it (to find out faster what they already knew).
Creating a code mutant is not itself resource intensive, e.g., randomly pick a point in the source and make a random change. However, the mutated source may not compile, or the resulting mutant may be equivalent to one created previously (e.g., the optimised compiled code is identical), or the program takes ages to compile and build; techniques for reducing the build overhead include mutating the compiler intermediate form and mutating the program executable.
Some changes to the source are more likely to be detected by a test suite than others, e.g., replacing <= by > is more likely to be detected than replacing it by < or ==. Various techniques for context dependent mutations have been proposed, e.g., handling of conditionals.
While mutation researchers were being ignored by industry, another group of researchers were listening to industry's problems with testing; automatic test case generation took off. How might different test case generators be compared? Mutation testing offers a means of evaluating the performance of tools that arrived on the scene (in practice, many researchers and tool vendors cite statement or block coverage numbers).
Perhaps industry might have to start showing some interest in mutation testing.
A fundamental concern is the extent to which mutation operators modify source in a way that is representative of the kinds of mistakes made by programmers.
The competent programmer hypothesis is often cited, by researchers, as the answer to this question. The hypothesis is that competent programmers write code/programs that is close to correct; the implied conclusion being that mutations, which are small changes, must therefore be like programmer mistakes (the citation often given as the source of this hypothesis discusses data selection during testing, but does mention the term competent programmer).
Until a few years ago, most analysis of fixes of reported faults looked at what coding constructs were involved in correcting the source code, e.g., 296 mistakes in TeX reported by Knuth. This information can be used to generate a probability table for selecting when to mutate one token into another token.
Studies of where the source code was changed, to fix a reported fault, show that existing mutation operators are not representative of a large percentage of existing coding mistakes; for instance, around 60% of 290 source code fixes to AspectJ involved more than one line (mutations usually involve a single line of source {because they operate on single statements and most statements occupy one line}), another study investigating many more fixes found only 10% of fixes involved one line, and similar findings for a study of C, Java, Python, and Haskell (a working link to the data, which is a bit disjointed of a mess).
These studies, which investigated the location of all the source code that needs to be changed, to fix a mistake, show that existing mutation operators are not representative of most human coding mistakes. To become representative, mutation operators need to be capable of making coupled changes across multiple lines/functions/methods and even files.
While arguments over the validity of the competent programmer hypothesis rumble on, the need for multi-line changes remains.
Given the lack of any major use-cases for mutation testing, it does not look like it is worth investing lots of resources on this topic. Researchers who have spent a large chunk of their career working on mutation testing will probably argue that you never know what use-cases might crop up in the future. In practice, mutation research will probably fade away because something new and more interesting has come along, i.e., fuzz testing.
There will always be niche use-cases for mutation. For instance, how likely is it that a random change to the source of a formal proof will go unnoticed by its associated proof checker (i.e., the proof checking tool output remains unchanged)?
A study based on mutating the source of Coq verification projects found that 7% of mutations had no impact on the results.
Source code discovery, skipping over the legal complications
The 2020 US elections introduced the issue of source code discovery, in legal cases, to a wider audience. People wanted to (and still do) check that the software used to register and count votes works as intended, but the companies who wrote the software wouldn’t make it available and the courts did not compel them to do so.
I was surprised to see that there is even a section on “Transfer of or access to source code” in the EU-UK trade and cooperation agreement, agreed on Christmas Eve.
I have many years of experience in discovering problems in the source code of programs I did not write. This experience derives from my time as a compiler implementer (e.g., a big customer is being held up by a serious issue in their application, and the compiler is being blamed), and as a static analysis tool vendor (e.g., managers want to know about what serious mistakes may exist in the code of their products). In all cases those involved wanted me there, I could talk to some of those involved in developing the code, and there were known problems with the code. In court cases, the defence does not want the prosecution looking at the code, and I assume that all conversations with the people who wrote the code goes via the lawyers. I have intentionally stayed away from this kind of work, so my practical experience of working on legal discovery is zero.
The most common reason companies give for not wanting to make their source code available is that it contains trade-secrets (they can hardly say that it’s because they don’t want any mistakes in the code to be discovered).
What kind of trade-secrets might source code contain? Most code is very dull, and for some programs the only trade-secret is that if you put in the implementation effort, the obvious way of doing things works, i.e., the secret sauce promoted by the marketing department is all smoke and mirrors (I have had senior management, who have probably never seen the code, tell me about the wondrous properties of their code, which I had seen and knew that nothing special was present).
Comments may detail embarrassing facts, aka trade-secrets. Sometimes the code interfaces to a proprietary interface format that the company wants to keep secret, or uses some formula that required a lot of R&D (management gets very upset when told that ‘secret’ formula can be reverse engineered from the executable code).
Why does a legal team want access to source code?
If the purpose is to check specific functionality, then reading the source code is probably the fastest technique. For instance, checking whether a particular set of input values can cause a specific behavior to occur, or tracing through the logic to understand the circumstances under which a particular behavior occurs, or in software patent litigation checking what algorithms or formula are being used (this is where trade-secret claims appear to be valid).
If the purpose is a fishing expedition looking for possible incorrect behaviors, having the source code is probably not that useful. The quantity of source contained in modern applications can be huge, e.g., tens to hundreds of thousands of lines.
In ancient times (i.e., the 1970s and 1980s) programs were short (because most computers had tiny amounts of memory, compared to post-2000), and it was practical to read the source to understand a program. Customer demand for more features, and the fact that greater storage capacity removed the need to spend time reducing code size, means that source code ballooned. The following plot shows the lines of code contained in the collected algorithms of the Transactions on Mathematical Software, the red line is a fitted regression model of the form:  (code+data):
(code+data):
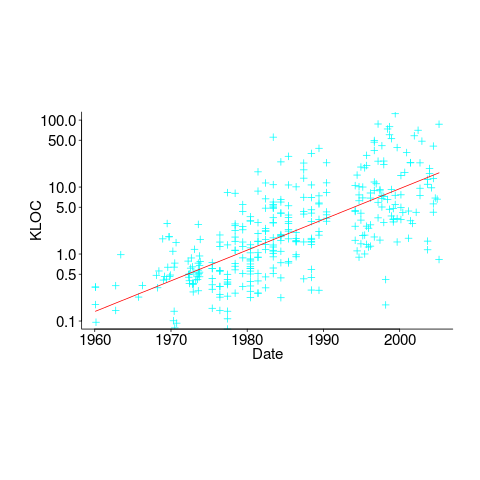
How, by reading the source code, does anybody find mistakes in a 10+ thousand line program? If the program only occasionally misbehaves, finding a coding mistake by reading the source is likely to be very very time-consuming, i.e, months. Work it out yourself: 10K lines of code is around 200 pages. How long would it take you to remember all the details and their interdependencies of a detailed 200-page technical discussion well enough to spot an inconsistency likely to cause a fault experience? And, yes, the source may very well be provided as a printout, or as a pdf on a protected memory stick.
From my limited reading of accounts of software discovery, the time available to study the code may be just days or maybe a week or two.
Reading large quantities of code, to discover possible coding mistakes, are an inefficient use of human time resources. Some form of analysis tool might help. Static analysis tools are one option; these cost money and might not be available for the language or dialect in which the source is written (there are some good tools for C because it has been around so long and is widely used).
Character assassination, or guilt by innuendo is another approach; the code just cannot be trusted to behave in a reasonable manner (this approach is regularly used in the software business). Software metrics are deployed to give the impression that it is likely that mistakes exist, without specifying specific mistakes in the code, e.g., this metric is much higher than is considered reasonable. Where did these reasonable values come from? Someone, somewhere said something, the Moon aligned with Mars and these values became accepted ‘wisdom’ (no, reality is not allowed to intrude; the case is made by arguing from authority). McCabe’s complexity metric is a favorite, and I have written how use of this metric is essentially accounting fraud (I have had emails from several people who are very unhappy about me saying this). Halstead’s metrics are another favorite, and at least Halstead and others at the time did some empirical analysis (the results showed how ineffective the metrics were; the metrics don’t calculate the quantities claimed).
The software development process used to create software is another popular means of character assassination. People seem to take comfort in the idea that software was created using a defined process, and use of ad-hoc methods provides an easy target for ridicule. Some processes work because they include lots of testing, and doing lots of testing will of course improve reliability. I have seen development groups use a process and fail to produce reliable software, and I have seen ad-hoc methods produce reliable software.
From what I can tell, some expert witnesses are chosen for their ability to project an air of authority and having impressive sounding credentials, not for their hands-on ability to dissect code. In other words, just the kind of person needed for a legal strategy based on character assassination, or guilt by innuendo.
What is the most cost-effective way of finding reliability problems in software built from 10k+ lines of code? My money is on fuzz testing, a term that should send shivers down the spine of a defense team. Source code is not required, and the output is a list of real fault experiences. There are a few catches: 1) the software probably to be run in the cloud (perhaps the only cost/time effective way of running the many thousands of tests), and the defense is going to object over licensing issues (they don’t want the code fuzzed), 2) having lots of test harnesses interacting with a central database is likely to be problematic, 3) support for emulating embedded cpus, even commonly used ones like the Z80, is currently poor (this is a rapidly evolving area, so check current status).
Fuzzing can also be used to estimate the numbers of so-far undetected coding mistakes.
How useful are automatically generated compiler tests?
Over the last decade, testing compilers using automatically generated source code has been a popular research topic (for those working in the compiler field; Csmith kicked off this interest). Compilers are large complicated programs, and they will always contain mistakes that lead to faults being experienced. Previous posts of mine have raised two issues on the use of automatically generated tests: a financial issue (i.e., fixing reported faults costs money {most of the work on gcc and llvm is done by people working for large companies}, and is intended to benefit users not researchers seeking bragging rights for their latest paper), and applicability issue (i.e., human written code has particular characteristics and unless automatically generated code has very similar characteristics the mistakes it finds are unlikely to commonly occur in practice).
My claim that mistakes in compilers found by automatically generated code are unlikely to be the kind of mistakes that often lead to a fault in the compilation of human written code is based on the observations (I don’t have any experimental evidence): the characteristics of automatically generated source is very different from human written code (I know this from measurements of lots of code), and this difference results in parts of the compiler that are infrequently executed by human written code being more frequently executed (increasing the likelihood of a mistake being uncovered; an observation based on my years working on compilers).
An interesting new paper, Compiler Fuzzing: How Much Does It Matter?, investigated the extent to which fault experiences produced by automatically generated source are representative of fault experiences produced by human written code. The first author of the paper, Michaël Marcozzi, gave a talk about this work at the Papers We Love workshop last Sunday (videos available).
The question was attacked head on. The researchers instrumented the code in the LLVM compiler that was modified to fix 45 reported faults (27 from four fuzzing tools, 10 from human written code, and 8 from a formal verifier); the following is an example of instrumented code:
warn ("Fixing patch reached"); if (Not.isPowerOf2()) { if (!(C-> getValue().isPowerOf2() // Check needed to fix fault && Not != C->getValue())) { warn("Fault possibly triggered"); } else { /* CODE TRANSFORMATION */ } } // Original, unfixed code |
The instrumented compiler was used to build 309 Debian packages (around 10 million lines of C/C++). The output from the builds were (possibly miscompiled) built versions of the packages, and log files (from which information could be extracted on the number of times the fixing patches were reached, and the number of cases where the check needed to fix the fault was triggered).
Each built package was then checked using its respective test suite; a package built from miscompiled code may successfully pass its test suite.
A bitwise compare was run on the program executables generated by the unfixed and fixed compilers.
The following (taken from Marcozzi’s slides) shows the percentage of packages where the fixing patch was reached during the build, the percentages of packages where code added to fix a fault was triggered, the percentage where a different binary was generated, and the percentages of packages where a failure was detected when running each package’s tests (0.01% is one failure):
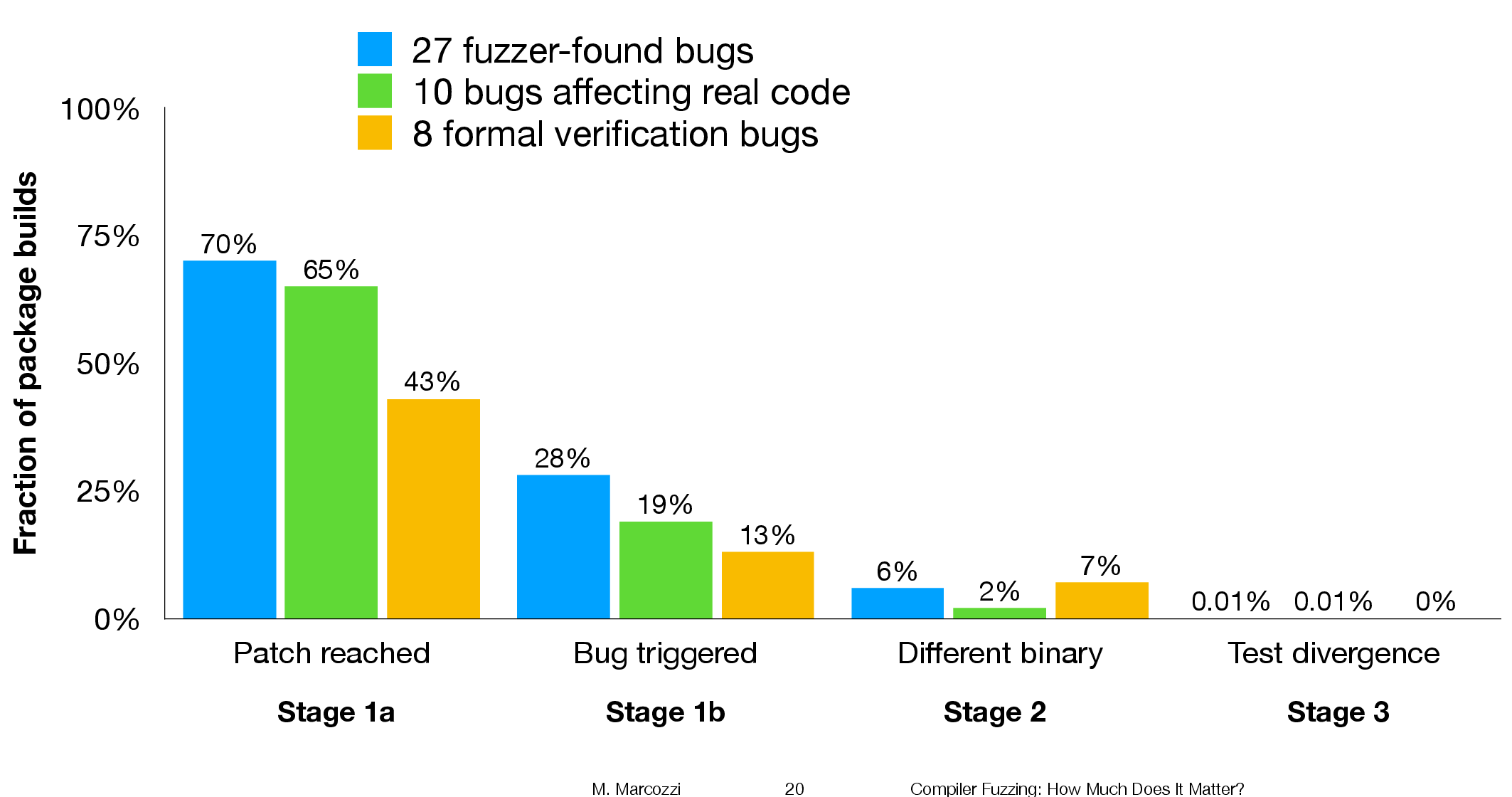
The takeaway from the above figure is that many packages are affected by the coding mistakes that have been fixed, but that most package test suites are not affected by the miscompilations.
To find out whether there is a difference, in terms of impact on Debian packages, between faults reported in human and automatically generated code, we need to compare number of occurrences of “Fault possibly triggered”. The table below shows the break-down by the detector of the coding mistake (i.e., Human and each of the automated tools used), and the number of fixed faults they contributed to the analysis.
Human, Csmith and EMI each contributed 10-faults to the analysis. The fixes for the 10-fault reports in human generated code were triggered 593 times when building the 309 Debian packages, while each of the 10 Csmith and EMI fixes were triggered 1,043 and 948 times respectively; a lot more than the Human triggers :-O. There are also a lot more bitwise compare differences for the non-Human fault-fixes.
Detector Faults Reached Triggered Bitwise-diff Tests failed Human 10 1,990 593 56 1 Csmith 10 2,482 1,043 318 0 EMI 10 2,424 948 151 1 Orange 5 293 35 8 0 yarpgen 2 608 257 0 0 Alive 8 1,059 327 172 0 |
Is the difference due to a few packages being very different from the rest?
The table below breaks things down by each of the 10-reported faults from the three Detectors.
Ok, two Human fault-fix locations are never reached when compiling the Debian packages (which is a bit odd), but when the locations are reached they are just not triggering the fault conditions as often as the automatic cases.
Detector Reached Triggered
Human
300 278
301 0
305 0
0 0
0 0
133 44
286 231
229 0
259 40
77 0
Csmith
306 2
301 118
297 291
284 1
143 6
291 286
125 125
245 3
285 16
205 205
EMI
130 0
307 221
302 195
281 32
175 5
122 0
300 295
297 215
306 191
287 10 |
It looks like I am not only wrong, but that fault experiences from automatically generated source are more (not less) likely to occur in human written code (than fault experiences produced by human written code).
This is odd. At best I would expect fault experiences from human and automatically generated code to have the same characteristics.
Ideas and suggestions welcome.
Update: the morning after
I have untangled my thoughts on how to statistically compare the three sets of data.
The bootstrap is based on the idea of exchangeability; which items being measured might we consider to be exchangeable, i.e., being able to treat the measurement of one as being the equivalent to measuring the other.
In this experiment the coding mistakes are not exchangeable, i.e., different mistakes can have different outcomes.
But we might claim that the detection of mistakes is exchangeable; that is, a coding mistake is just as likely to be detected by source code produced by an automatic tool as source written by a Human.
The bootstrap needs to be applied without replacement, i.e., each coding mistake is treated as being unique. The results show that for the sum of the Triggered counts (code+data):
- treating Human and Csmith as being equally likely to detect the same coding mistake, there is a 18% change of the Human results being lower than 593.
- treating Human and EMI as being equally likely to detect the same coding mistake, there is a 12% change of the Human results being lower than 593.
So the likelihood of the lower value, 593, of Human Triggered events is expected to occur quite often (i.e., 12% and 18%). Automatically generated code is not more likely to detect coding mistakes than human written code (at least based on this small sample set).
Student projects for 2019/2020
It’s that time of year when students are looking for an interesting idea for a project (it might be a bit late for this year’s students, but I have been mulling over these ideas for a while, and might forget them by next year). A few years ago I listed some suggestions for student projects, as far as I know none got used, so let’s try again…
Checking the correctness of the Python compilers/interpreters. Lots of work has been done checking C compilers (e.g., Csmith), but I cannot find any serious work that has done the same for Python. There are multiple Python implementations, so it would be possible to do differential testing, another possibility is to fuzz test one or more compiler/interpreter and see how many crashes occur (the likely number of remaining fault producing crashes can be estimated from this data).
Talking to the Python people at the Open Source hackathon yesterday, testing of the compiler/interpreter was something they did not spend much time thinking about (yes, they run regression tests, but that seemed to be it).
Finding faults in published papers. There are tools that scan source code for use of suspect constructs, and there are various ways in which the contents of a published paper could be checked.
Possible checks include (apart from grammar checking):
- incorrect or inaccurate numeric literals.
Checking whether the suspect formula is used is another possibility, provided the formula involved contains known constants.
- inconsistent statistics reported (e.g., “8 subjects aged between 18-25, average age 21.3″ may be correct because 21.3*8 == 170.4, ages must add to a whole number and the values 169, 170 and 171 would not produce this average), and various tools are available (e.g., GRIMMER).
Citation errors are relatively common, but hard to check automatically without a good database (I have found that a failure of a Google search to return any results is a very good indicator that the reference does not exist).
There are lots of tools available for taking pdf files apart; I use pdfgrep a lot
Number extraction. Numbers are some of the most easily checked quantities, and anybody interested in fact checking needs a quick way of extracting numeric values from a document. Sometimes numeric values appear as numeric words, and dates can appear as a mixture of words and numbers. Extracting numeric values, and their possible types (e.g., date, time, miles, kilograms, lines of code). Something way more sophisticated than pattern matching on sequences of digit characters is needed.
spaCy is my tool of choice for this sort of text processing task.
The shadow of the input distribution
Two things need to occur for a user to experience a fault in a program:
- a fault has to exist in the code,
- the user has to provide input that causes program execution to include the faulty code in a way that exhibits the incorrect behavior.
Data on the distribution of user input values is extremely rare, and we are left having to look for the shadows that the input distribution creates.
Csmith is a well-known tool for generating random C source code. I spotted an interesting plot in a compiler fuzzing paper and Yang Chen kindly sent me a copy of the data. In compiler fuzzing, source code is automatically generated and fed to the compiler, various techniques are used to figure out when the compiler gets things wrong.
The plot below is a count of the number of times each fault in gcc has been triggered (code+data). Multiple occurrences of the same fault are experienced because the necessary input values occur multiple times in the generated source code (usually in different files).
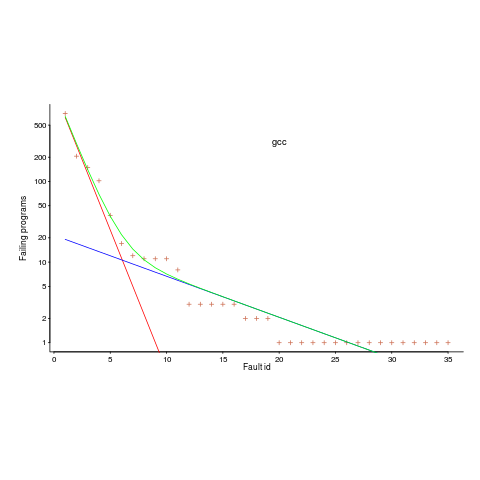
The green line is a fitted regression model, it’s a bi-exponential, i.e., the sum of two exponentials (the straight lines in red and blue).
The obvious explanation for this bi-exponential behavior (explanations invented after seeing the data can have the flavor of just-so stories, which is patently not true here 🙂 is that one exponential is driven by the presence of faults in the code and the other exponential is driven by the way in which Csmith meanders over the possible C source.
So, which exponential is generated by the faults and which by Csmith? I’m still trying to figure this out; suggestions welcome, along with alternative explanations.
Is the same pattern seen in duplicates of user reported faults? It does in the small amount of data I have; more data welcome.
Recent Comments