Archive
What impact might my evidence-based book have in 2021?
What impact might the release of my evidence-based software engineering book have on software engineering in 2021?
Lots of people have seen the book. The release triggered a quarter of a million downloads, or rather it getting linked to on Twitter and Hacker News resulted in this quantity of downloads. Looking at the some of the comments on Hacker News, I suspect that many ‘readers’ did not progress much further than looking at the cover. Some have scanned through it expecting to find answers to a question that interests them, but all they found was disconnected results from a scattering of studies, i.e., the current state of the field.
The evidence that source code has a short and lonely existence is a gift to those seeking to save time/money by employing a quick and dirty approach to software development. Yes, there are some applications where a quick and dirty iterative approach is not a good idea (iterative as in, if we make enough money there will be a version 2), the software controlling aircraft landing wheels being an obvious example (if the wheels don’t deploy, telling the pilot to fly to another airport to see if they work there is not really an option).
There will be a few researchers who pick up an idea from something in the book, and run with it; I have had a couple of emails along this line, mostly from just starting out PhD students. It would be naive to think that lots of researchers will make any significant changes to their existing views on software engineering. Planck was correct to say that science advances one funeral at a time.
I’m hoping that the book will produce a significant improvement in the primitive statistical techniques currently used by many software researchers. At the moment some form of Wilcoxon test, invented in 1945, is the level of statistical sophistication wielded in most software engineering papers (that do any data analysis).
Software engineering research has the feeling of being a disjoint collection of results, and I’m hoping that a few people will be interested in starting to join the dots, i.e., making connections between findings from different studies. There are likely to be a limited number of major dot joinings, and so only a few dedicated people are needed to make it happen. Why hasn’t this happened yet? I think that many academics in computing departments are lifestyle researchers, moving from one project to the next, enjoying the lifestyle, with little interest in any research results once the grant money runs out (apart from trying to get others to cite it). Why do I think this? I have emailed many researchers information about the patterns I have found in the data they sent me, and a common response is almost completely disinterest (some were interested) in any connections to other work.
What impact do you think ‘all’ the evidence presented will have?
Predicting the future with data+logistic regression
Predicting the peak of data fitted by a logistic equation is attracting a lot of attention at the moment. Let’s see how well we can predict the final size of a software system, in lines of code, using logistic regression (code+data).
First up is the size of the GNU C library. This is not really a good test, since the peak (or rather a peak) has been reached.
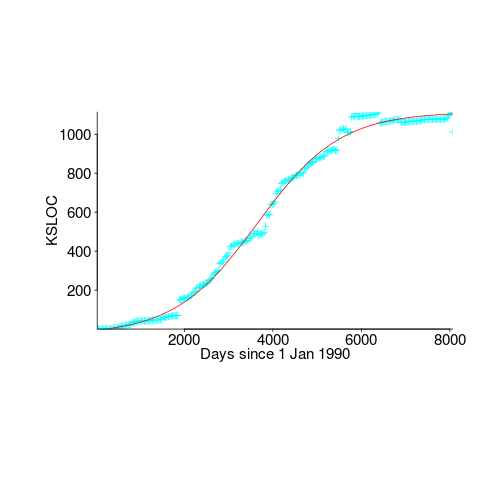
We need a system that has not yet reached an easily recognizable peak. The Linux kernel has been under development for many years, and lots of LOC counts are available. The plot below shows a logistic equation fitted to the kernel data, assuming that the only available data was up to day: 2,900, 3,650, 4,200, and 5,000+. Can you tell which fitted line corresponds to which number of days?
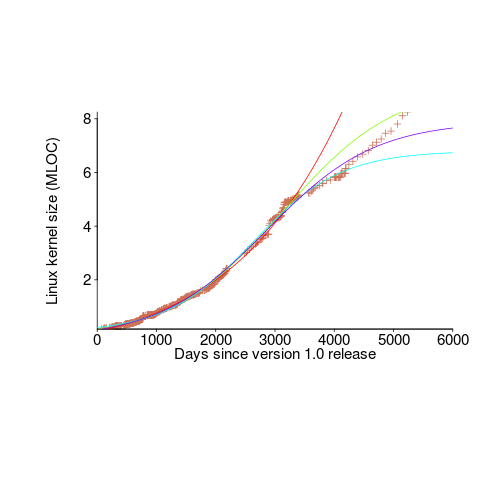
The underlying ‘problem’ is that we are telling the fitting software to fit a particular equation; the software does what it has been told to do, and fits a logistic equation (in this case).
A cubic polynomial is also a great fit to the existing kernel data (red line to the left of the blue line), and this fitted equation can be extended into future (to the right of the blue line); dotted lines are 95% confidence bounds. Do any readers believe the future size of the Linux kernel predicted by this cubic model?
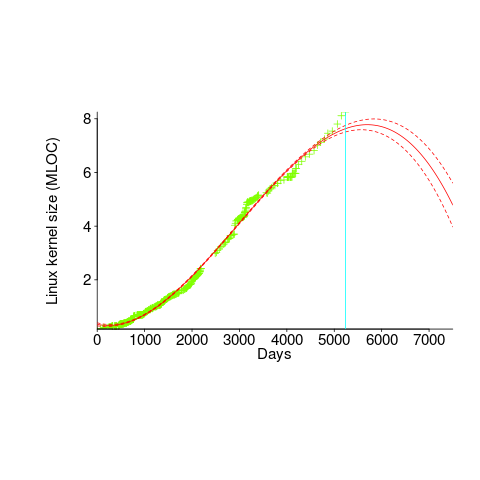
Predicting the future requires lots of data on the underlying processes that drive events. Modeling events is an iterative process. Build a model, check against reality, adjust model, rinse and repeat.
If the COVID-19 experience trains people to be suspicious of future predictions made by models, it will have done something positive.
Hedonism: The future economics of compiler development
In the past developers paid for compilers, then gcc came along (followed by llvm) and now a few companies pay money to have a bunch of people maintain/enhance/support a new cpu; developers get a free compiler. What will happen once the number of companies paying money shrinks below some critical value?
The current social structure has an authority figure (ISO committees for C and C++, individuals or companies for other languages) specifying the language, gcc/llvm people implementing the specification and everybody else going along for the ride.
Looking after an industrial strength compiler is hard work and requires lots of know-how; hobbyists have little chance of competing against those paid to work full time. But as the number of companies paying for support declines, the number of people working full-time on the compilers will shrink. Compiler support will become a part-time job or hobby.
What are the incentives for a bunch of people to get together and spend their own time maintaining a compiler? One very powerful incentive is being able to decide what new language features the compiler will support. Why spend several years going to ISO meetings arguing with everybody about whether the next version of the standard should support your beloved language construct, it’s quicker and easier to add it directly to the compiler (if somebody else wants their construct implemented, let them write the code).
The C++ committee is populated by bored consultants looking for an outlet for their creative urges (the production of 1,600 page documents and six extension projects is driven by the 100+ people who attend meetings; a lot fewer people would produce a simpler C++). What is the incentive for those 100+ (many highly skilled) people to attend meetings, if the compilers are not going to support the specification they produce? Cut out the middle man (ISO) and organize to support direct implementation in the compiler (one downside is not getting to go to Hawaii).
The future of compiler development is groups of like-minded hedonists (in the sense of agreeing what features should be in a language) supporting a compiler for the bragging rights of having created/designed the languages features used by hundreds of thousands of developers.
How will C code in 2045 look different from today?
What constructs will be in such common use in C source code written by developers in 2045 that people looking at C written in 2015 will know it comes from a much earlier era (a previous post looked back at C written in 1986)?
C is a high level language that allows developers to get close to the hardware, so to get some idea of what everyday C might be like in 2045 we have to ask what everyday hardware will be like 10-20 years from now (the C standard committee waits for hardware feature to become established before adding features to support them).
I think the following hardware trends will have a big impact on the future appearance of C source code:
Power consumption: Runtime performance is an integral part of the design of C. In the past performance has been about program execution time and/or memory usage; the spread of mobile computing has created a third strand: electrical power consumption. A variety of techniques have been proposed for reducing program power consumption, including: type specifiers that enable developers to tell the compiler accuracy can be traded off against power in calculations involving a given variable and scaling cpu voltage/frequency in non-time critical code (researchers are currently trying to do this without developer involvement, but a storage/type specifier like register or inline would provide useful information to the compiler),
Unreliable hardware: running hardware at lower voltages (to reduce power consumption) increases the probability of noise having an effect on program output, as does use of smaller line widths in cpu fabrication (more chips per die increases manufacturer profits). Proposed solutions include adding type specifiers to variables that can tolerate holding approximate values or more making probabilistic assertions.
Non-volatile memory: Like most languages C has an implicit model of programs sitting on a slow storage device, e.g., hard disk, and being loaded into very fast storage for execution. Non-volatile storage could have a very dramatic impact on this view of the world. For years gaming consoles have stored code+data as a memory image in ROM for rapid loading, but being able to write to storage that is only an order of magnitude slower than main memory opens up all sorts of interesting opportunities. The concept of named address spaces defined in Programming languages – C – Extensions to support embedded processors is waiting to expand out of its current niche of C on embedded processors.
There is at least one language construct that is likely to be rarely seen by developers working in 2045: inline. The reason that today’s developers have been given the ability to define functions inline is that compilers are not yet good enough to reliably make good function inlining decisions, rather like they were not good enough to reliability make good register allocation decisions 30 years ago (ok, register can still be useful for developers using weird and wonderful processor architectures or brain dead compilers).
I have not yet said anything about parallel processing or multiprocessor hardware. The C11 Standard updated C99 to provide generic support (i.e., _Atomic plus associated sequence point wording updates and the threads library) for this kind of hardware. Support for a specific parallel/multiprocessor model will happen if a specific model becomes the industry standard (rather like IEEE floating-point not being anointed by C90 because it was not yet what every hardware vendor used; other formats were on their last legs and by C99 could be treated as dead).
Recent Comments