Archive
Number of parameters vs. accessing globals
I spend a lot of time looking at software engineering data, asking, what is the story here?
In a previous post I suggested that the distribution of the number of functions defined to have a given number of parameters, might be a signature of developer beliefs about the relative cost of parameter passing vs accessing globals.
Looking at the data that Iran Rodrigues Gonzaga Junior made available (good man), as part of his thesis Empirical Studies on Fine-Grained Feature Dependencies, I saw it contained information about the number of parameters in a function definition and whether functions accessed a global (Gonzaga’s research question is in another direction; I am always repurposing data).
Are functions that access globals, defined with fewer parameters, compared to those that do not contain any such access? The plot below shows a count of the number of functions defined to have a given number of parameters, for four systems written in C; the solid lines are functions that did not access globals, the dashed lines are functions that accessed globals (code+data).
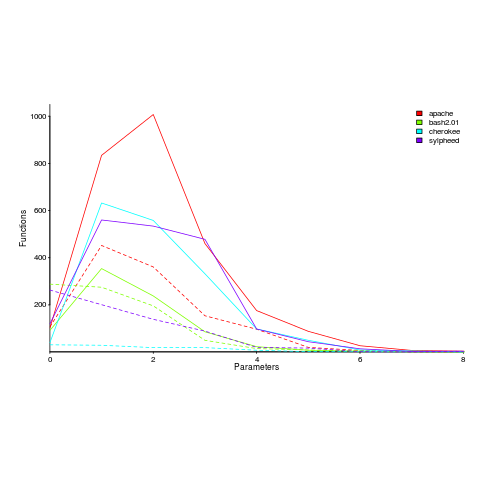
Over all 50 projects measured, functions that don’t access globals are defined, on average, to have an extra 0.7 parameters (the fitted Poisson regression models are better than a poke in the eye {i.e., the distribution is not really Poisson}, it’s more informative to look at the plotted data).
There is a lot of variation between projects (I picked these four because they were the larger projects and showed variation in behaviors). While the shape of the distributions varies a lot, there is always a noticeable difference in the mean.
Is this difference between projects a difference in developer beliefs, a difference in application requirements, a difference in developer coding habits (and parameter usage is a side effect; are there really that many getters and setters)?
I was hoping for a simple answer, and could not find one. Since I am writing a book and not researching individual issues in detail, it’s time to move on.
Ideas welcome.
A signature for the “embeddedness” of source code and developers?
Patterns in the use of source code can tell us a lot about the people who wrote the code, the characteristics of the hardware it runs on and what the application is all about.
Often the pattern of usage needs a lot of work to understand and many remain completely baffling, but every now and again the forces driving a pattern leap off the page. One such pattern is visible in the plot below; data courtesy of Jacob Engblom and the cbook data is from my C book (assuming you know something about the nitty gritty of embedded software development). It shows the percentage of functions defined to have a given number of parameters:
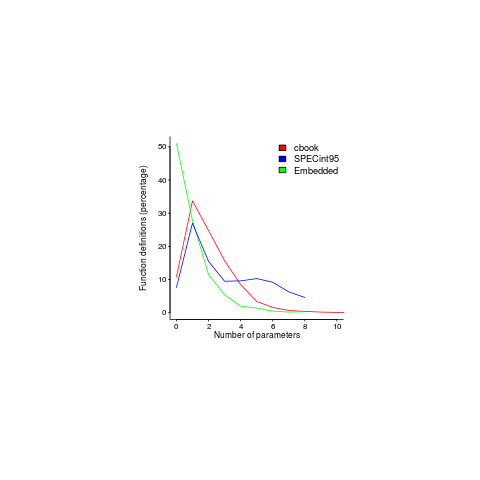
Embedded software has to run in very constrained environments. The hardware is often mass produced and saving a penny per device can add up to big savings, so the cheapest processor is chosen and populated with the smallest possible memory; developers have to work with what they are given. Power consumption may be down below one watt, so clock speeds are closer to 1 MHz than 1 GHz.
Parameter passing is a relatively expensive operation and there are major savings, relatively speaking, to be had by using global variables. Experienced embedded developers know this and this plot is telling us that they are acting on this knowledge.
The following are two ways of interpreting the embedded data (I cannot think of any others that make sense):
- the time/resource critical functions use globals rather than parameters and all the other functions are written more or less the same as in a non-embedded environment. In statistical terms this behavior is described by a zero-inflated model,
- there is pressure on the developer to reduce the number of parameters in all function definitions.
This data contains counts, so a Poisson distribution is the obvious candidate for our model.
My attempts to fit a zero-inflated model failed miserably (code+data). A basic Poisson distribution fitted everything reasonably well (let’s ignore that tiresome bump in the blue line); plus signs are the predictions made from each fitted model.
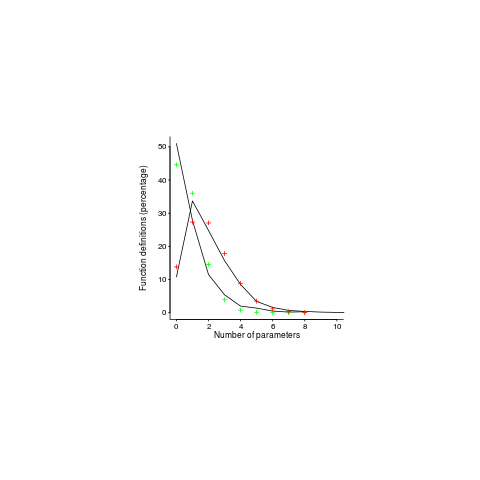
For desktop developers, the distribution of function definitions having a given number of parameters follows a Poisson distribution with a λ of 2, while for embedded developers λ is 0.8.
What about values of λ between 0.8 and 2; perhaps the λ of a project’s, or developer’s, code parameter count can be used as an indicator of ’embeddedness’?
What is needed to parameter count data from a range of 4-bit, 8-bit and 16-bit systems and measurements of developers who have been working in the field for, say, 4, 8, 16 years. Please let me know.
The data is from a Masters thesis written in 1999, is it still relevant today? Have modern companies become kinder to developers and stopped making their life so hard by saving pennies when building mass produced products; are modern low-power devices being used so values can be passed via parameters rather than via globals, or are they being used for applications where even less power is available?
One difference from 20 years ago is that embedded devices are more mainstream, easier to get hold of and sales opportunities abound. This availability creates an environment where developers with a desktop development mentality (which developers new to embedded always seem to have had) don’t get to learn about the overheads of parameter passing.
Have compilers gotten better at reducing the function parameter overhead? The most obvious optimization is inlining a function at the point of call. If the function is only called once, this works fine, with multiple calls the generated code can get larger (one of the things we are trying to avoid). I don’t have any reliable data on modern compiler performance int his area, but then I have not looked hard. Pointers to benchmarks welcome.
Does embedded software have any other signatures that differentiate it from desktop software (other than the obvious one of specifying address in definitions of global variables)? Suggestions welcome.
Unused function parameters
I have started redoing the source code measurements that appear in my C book, this time using a lot more source, upgraded versions of existing tools, plus some new tools such as Coccinelle and R. The intent is to make the code and data available in a form that is easy for others to use (I am hoping that one or more people will measure the same constructs in other languages) and to make some attempt at teasing out relationships in the data (previously the data was simply plotted with little or no explanation).
While it might be possible to write a paper on every language construct measured, I don’t have the time to do the work. Instead, I will use this blog to make a note of the interesting things that crop up during the analysis of each construct I measure.
First up are unused function parameters (code and data), which at around 11% of all parameters are slightly more common than unused local variables (Figure 190.1). In the following plot black circles are the total number of functions having a given number of parameters, red circles a given number of unused parameters, blue line a linear regression fit of the red circles, and the green line is derived from black circle values using a formula I concocted to fit the data and have no theoretical justification for it.
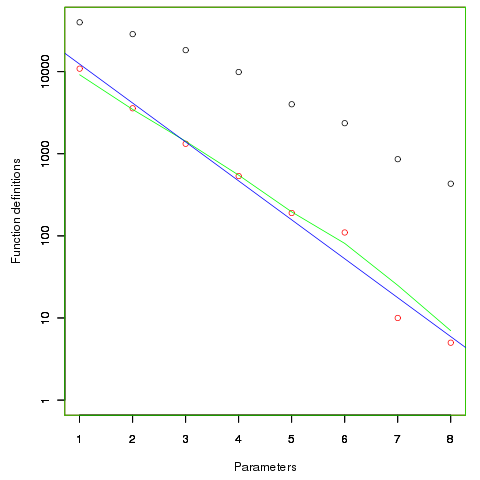
The number of functions containing a given number of unused parameters drops by around a factor of three for each additional unused parameter. Why is this? The formula I came up with for estimating the number of functions containing  unused parameters is:
unused parameters is:  , where
, where  is the total number of function definitions containing
is the total number of function definitions containing  parameters.
parameters.
Which parameter, for those functions defined with more than one, is most likely to be unused? My thinking was that the first parameter might either hold the most basic information (and so rarely be unused) or hold information likely to be superseded when new parameters are added (and so commonly be unused), either way I considered later parameters as often being put there for later use (and therefore more likely to be unused). The following plot is for eight programs plus the sum of them all; for all functions defined with between one and eight parameters, the percentage of times the  ‘th parameter is unused is given. The source measured contained 104,493 function definitions containing more than one parameter with 16,643 of these functions having one or more unused parameter, there were a total of 235,512 parameters with 25,886 parameters being unused.
‘th parameter is unused is given. The source measured contained 104,493 function definitions containing more than one parameter with 16,643 of these functions having one or more unused parameter, there were a total of 235,512 parameters with 25,886 parameters being unused.
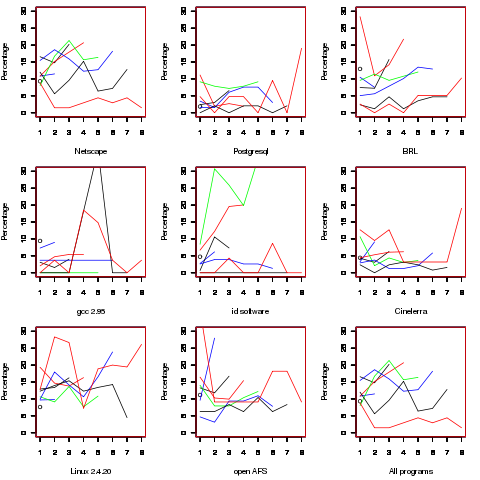
There is no obvious pattern to which parameters are likely to be unused, although a lot of the time the last parameter is more likely to be unused than the penultimate one.
Looking through the raw data I noticed that there seemed to be some clustering of names of unused parameters, in particular if the ‘th parameter was unused in two adjacent ‘unused parameter’ functions they often had the same name. The following plot is for all measured source and gives the percentage of same name occurrences; the matching process analyses function definitions in the order they occur within a source file and having found one unused parameter its name is compared against the corresponding parameter in the next function definition with the same number of parameters and having an unused parameter at the same position.
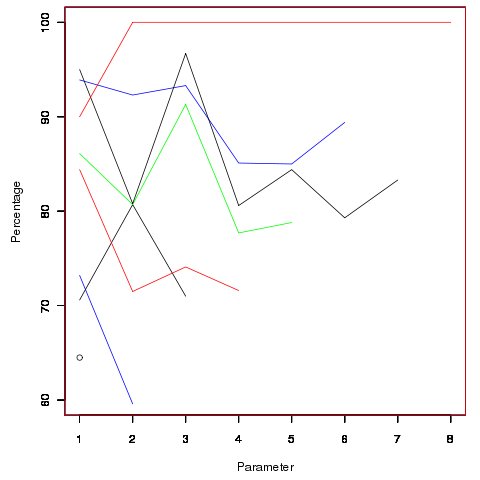
Before getting too excited about this pattern, we should ask if something similar exists for the used parameters. When I get around to redoing the general parameter measurements, I will look into this question. The numbers of occurrences for functions containing eight parameters is close to minimal.
The functions containing these same-name unused parameters appear to also have related function names. Is this a case of related function being grouped together, often sharing parameter names, and when one of them has an unused parameter the corresponding parameter in the others is also unused?
Is there a correlation between number of parameters and number of statements, are functions containing lots of statements less likely to have unused parameters? What effect does software evolution have (most of this kind of research measures executable code, not variable definitions)?
Recent Comments