Archive
Procedure nesting a once common idiom
Structured programming was a popular program design methodology that many developers/managers claimed to be using in the 1970s and 1980s. Like all popular methodologies, everybody had/has their own idea about what it involves, and as always, consultancies sprang up to promote their take on things. The 1972 book Structured programming provides a taste of the times.
The idea underpinning structured programming is that it’s possible to map real world problems to some hierarchical structure, such as in the image below. This hierarchy model also provided a comforting metaphor for those seeking to understand software and its development.

The disadvantages of the Structured programming approach (i.e., real world problems often have important connections that cannot be implemented using a hierarchy) become very apparent as programs get larger. However, in the 1970s the installed memory capacity of most computers was measured in kilobytes, and a program containing 25K lines of code was considered large (because it was enough to consume a large percentage of the memory available). A major program usually involved running multiple, smaller, programs in sequence, each reading the output from the previous program. It was not until the mid-1980s…
At the coding level, doing structured programming involves laying out source code to give it a visible structure. Code blocks are indented to show if/for/while nesting and where possible procedure/functions are nested within the calling procedures (before C became widespread, functions that did not return a value were called procedures; Fortran has always called them subroutines).
Extensive nesting of procedures/functions was once very common, at least in languages that supported it, e.g., Algol 60 and Pascal, but not Fortran or Cobol. The spread of C, and then C++ and later Java, which did not support nesting (supported by gcc as an extension, nested classes are available in C++/Java, and later via lambda functions), erased nesting from coding consideration. I started life coding mostly in Fortran, moved to Pascal and made extensive use of nesting, then had to use C and not being able to nest functions took some getting used to. Even when using languages that support nesting (e.g., Python), I have not reestablished by previous habit of using nesting.
A common rationale for not supporting nested functions/methods is that it complicate the language specification and its implementation. A rather self-centered language designer point of view.
The following Pascal example illustrates a benefit of being able to nest procedures/functions:
procedure p1; var db :array[db_size] of char; procedure p2(offset :integer); function p3 :integer; begin (* ... *) return db[offset]; end; begin var off_val :char; off_val=p3; (* ... *) end; begin (* ... *) p2(3) end; |
The benefit of using nesting is in not forcing the developer to have to either define db at global scope, or pass it as an argument along the call chain. Nesting procedures is also a method of information hiding, a topic that took off in the 1970s.
To what extent did Algol/Pascal developers use nested procedures? A 1979 report by G. Benyon-Tinker and M. M. Lehman contains the only data I am aware of. The authors analysed the evolution of procedure usage within a banking application, from 1973 to 1978. The Algol 60 source grew from 35,845 to 63,843 LOC (657 procedures to 967 procedures). A large application for the time, but a small dataset by today’s standards.
The plot below shows the number of procedures/functions having a particular lexical nesting level, with nesting level 1 is the outermost level (i.e., globally visible procedures), and distinct colors denoting successive releases (code+data):
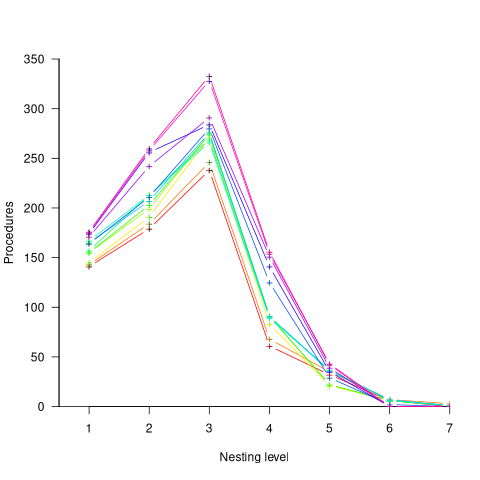
Just over 78% of procedures are nested within at least one other procedure. It’s tempting to think that nesting has a Poisson distribution, however, the distribution peaks at three rather than two. Perhaps it’s possible to fit an over-dispersed, but this feels like creating a just-so story.
What is the distribution of nested functions/methods in more recently written source? A study of 35 Python projects found 6.5% of functions nested and over twice as many (14.2%) of classed nested.
Are there worthwhile benefits to using nested functions/methods where possible, or is this once common usage mostly fashion driven with occasional benefits?
Like most questions involving cost/benefit analysis of language usage, it’s probably not sufficiently interesting for somebody to invest the effort required to run a reliable study.
The software heritage of K&R C
The mission statement of the Software Heritage is “… to collect, preserve, and share all software that is publicly available in source code form.”
What are the uses of the preserved source code that is collected? Lots of people visit preserved buildings, but very few people are interested in looking at source code.
One use-case is tracking the evolution of changes in developer usage of various programming language constructs. It is possible to use Github to track the adoption of language features introduced after 2008, when the company was founded, e.g., new language constructs in Java. Over longer time-scales, the Software Heritage, which has source code going back to the 1960s, is the only option.
One question that keeps cropping up when discussing the C Standard, is whether K&R C continues to be used. Technically, K&R C is the language defined by the book that introduced C to the world. Over time, differences between K&R C and the C Standard have fallen away, as compilers cease supporting particular K&R ways of doing things (as an option or otherwise).
These days, saying that code uses K&R C is taken to mean that it contains functions defined using the K&R style (see sentence 1818), e.g.,
writing:
int f(a, b) int a; float b; { /* declarations and statements */ } |
rather than:
int f(int a, float b) { /* declarations and statements */ } |
As well as the syntactic differences, there are semantic differences between the two styles of function definition, but these are not relevant here.
How much longer should the C Standard continue to support the K&R style of function definition?
The WG14 committee prides itself on not breaking existing code, or at least not lots of it. How much code is out there, being actively maintained, and containing K&R function definitions?
Members of the committee agree that they rarely encounter this K&R usage, and it would be useful to have some idea of the decline in use over time (with the intent of removing support in some future revision of the standard).
One way to estimate the evolution in the use/non-use of K&R style function definitions is to analyse the C source created in each year since the late 1970s.
The question is then: How representative is the Software Heritage C source, compared to all the C source currently being actively maintained?
The Software Heritage preserves publicly available source, plus the non-public, proprietary source forming the totality of the C currently being maintained. Does the public and non-public C source have similar characteristics, or are there application domains which are poorly represented in the publicly available source?
Embedded systems is a very large and broad application domain that is poorly represented in the publicly available C source. Embedded source tends to be heavily tied to the hardware on which it runs, and vendors tend to be paranoid about releasing internal details about their products.
The various embedded systems domains (e.g., 8, 16, 32, 64-bit processor) tend to be a world unto themselves, and I would not be surprised to find out that there are enclaves of K&R usage (perhaps because there is no pressure to change, or because the available tools are ancient).
At the moment, the Software Heritage don’t offer code search functionality. But then, the next opportunity for major changes to the C Standard is probably 5-years away (the deadline for new proposals on the current revision has passed); plenty of time to get to a position where usage data can be obtained 🙂
C++ template usage
Generics are a programming construct that allow an algorithm to be coded without specifying the types of some variables, which are supplied later when a specific instance (for some type(s)) is instantiated. Generics sound like a great idea; who hasn’t had to write the same function twice, with the only difference being the types of the parameters.
All of today’s major programming languages support some form of generic construct, and developers have had the opportunity to use them for many years. So, how often generics are used in practice?
In C++, templates are the language feature supporting generics.
The paper: How C++ Templates Are Used for Generic Programming: An Empirical Study on 50 Open Source Systems contains lots of interesting data 🙂 The following analysis applies to the five largest projects analysed: Chromium, Haiku, Blender, LibreOffice and Monero.
As its name suggests, the Standard Template Library (STL) is a collection of templates implementing commonly used algorithms+other stuff (some algorithms were commonly used before the STL was created, and perhaps some are now commonly used because they are in the STL).
It is to be expected that most uses of templates will involve those defined in the STL, because these implement commonly used functionality, are documented and generally known about (code can only be reused when its existence is known about, and it has been written with reuse in mind).
The template instantiation measurements show a 17:1 ratio for STL vs. developer-defined templates (i.e., 149,591 vs. 8,887).
What are the usage characteristics of developer defined templates?
Around 25% of developer defined function templates are only instantiated once, while 15% of class templates are instantiated once.
Most templates are defined by a small number of developers. This is not surprising given that most of the code on a project is written by a small number of developers.
The plot below shows the percentage instantiations (of all developer defined function templates) of each developer defined function template, in rank order (code+data):
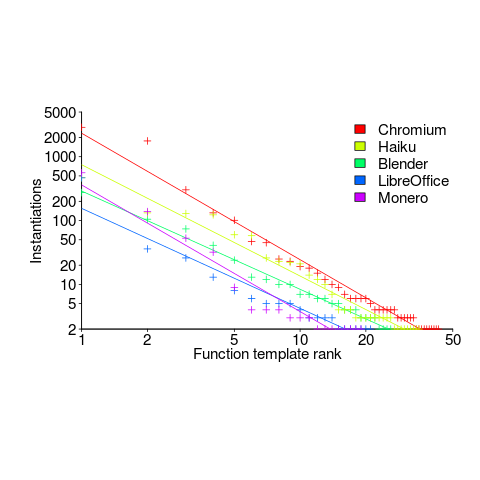
Lines are each a fitted power law, whose exponents vary between -1.5 and -2. Is it just me, or are these exponents surprising close?
The following is for developer defined class templates. Lines are fitted power law, whose exponents vary between -1.3 and -2.6. Not so close here.
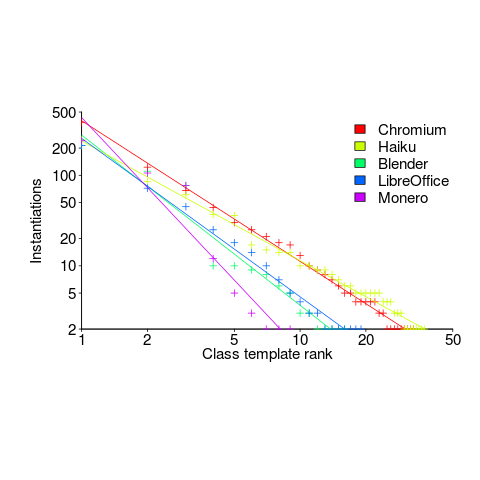
What processes are driving use of developer defined templates?
Every project has its own specific few templates that get used everywhere, by all developers. I imagine these are tailored to the project, and are widely advertised to developers who work on the project.
Perhaps some developers don’t define templates, because that’s not what they do. Is this because they work on stuff where templates don’t offer much benefit, or is it because these developers are stuck in their ways (if so, is it really worth trying to change them?)
The probability of encountering a given variable
If I am reading through the body of a function, what is the probability of a particular variable being the next one I encounter? A good approximation can be calculated as follows: Count the number of occurrences of all variables in the function definition up to the current point and work out the percentage occurrence for each of them, the probability of a particular variable being seen next is approximately equal to its previously seen percentage. The following graph is the evidence I give for this approximation.
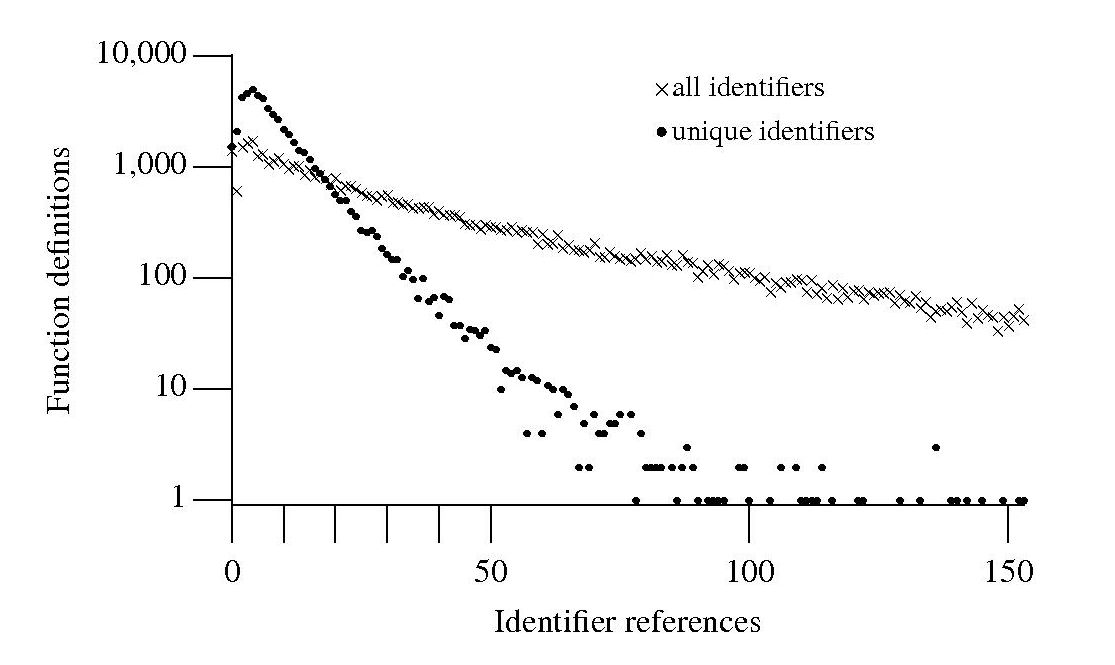
The graph shows a count of the number of C function definitions containing identifiers that are referenced a given number of times, e.g., if the identifier x is referenced five times in one function definition and ten times in another the function definition counts for five and ten are both incremented by one. That one axis is logarithmic and the bullets and crosses form almost straight lines hints that a Zipf-like distribution is involved.
There are many processes that will generate a Zipf distribution, but the one that interests me here is the process where the probability of the next occurrence of an event occurring is proportional to the probability of it having previously occurred (this includes some probability of a new event occurring; follow the link to Simon’s 1955 paper).
One can think of the value (i.e., information) held in a variable as having a given importance and it is to be expected that more important information is more likely to be operated on than less important information. This model appeals to me. Another process that will generate this distribution is that of Monkeys typing away on keyboards and while I think source code contains lots of random elements I don’t think it is that random.
The important concept here is operated on. In x := x + 1; variable x is incremented and the language used requires (or allowed) that the identifier x occur twice. In C this operation would only require one occurrence of x when expressed using the common idiom x++;. The number of occurrences of a variable needed to perform an operation on it, in a given languages, will influence the shape of the graph based on an occurrence count.
One graph does not provide conclusive evidence, but other measurements also produce straightish lines. The fact that the first few entries do not form part of an upward trend is not a problem, these variables are only accessed a few times and so might be expected to have a large deviation.
More sophisticated measurements are needed to count operations on a variable, as opposed to occurrences of it. For instance, few languages (any?) contain an indirection assignment operator (e.g., writing x ->= next; instead of x = x -> next;) and this would need to be adjusted for in a more sophisticated counting algorithm. It will also be necessary to separate out the effects of global variables, function calls and the multiple components involved in a member selection, etc.
Update: A more detailed analysis is now available.
Recent Comments