Archive
After 55.5 years the Fortran Specialist Group has a new home
In the 1960s and 1970s, new developments in Cobol and Fortran language standards and implementations regularly appeared on the front page of the weekly computer papers (Algol 60 news sometimes appeared). Various language user groups were created, which produced newsletters and held meetups (this term did not become common until a decade or two ago).
In January 1970 the British Computer Society‘s Fortran Specialist Group (FSG) held its first meeting and 55.5 years later (this month) this group has moved to a new parent organization the Society of Research Software Engineering. The FSG is distinct from BSI‘s Fortran Standards panel and the ISO Fortran working group, although they share a few members.
I believe that the FSG is the oldest continuously running language user group. Second place probably goes to the ACCU (Association on C and C++ Users) which was started in the late 1980s. Like me, both of these groups are based in the UK (the ACCU has offshoots in other countries). I welcome corrections from readers familiar with the language groups in other countries (there were many Pascal user groups created in the 1980s, but I don’t know of any that are still active). COBOL is a business language, and I have never seen a non-vendor meetup group that got involved with language issues.
The plot below shows estimated FSG membership numbers for various years, averaging 180 (thanks to David Muxworthy for the data; code+data):

My experience of national user groups is that membership tends to hover around a thousand. Perhaps the more serious, professional approach of the BCS deters the more casual members that haunt other user groups (whose membership fees help keep things afloat).
What are the characteristics of this Fortran group that have given it such a long and continuous life?
- It was started early. Fortran was one of the first, of two (perhaps three), widely used programming languages,
- Fortran continued to evolve in response to customer demand, which made it very difficult for new languages to acquire a share of Fortran’s scientific/engineering market. Compiler vendors have kept up, or at least those selling to high-end power customers have (the Open source Fortran compilers have lagged well behind).
Most developers don’t get involved with calculations using floating-point values, and so are unfamiliar with the multitude of issues that can have a significant impact on program output, e.g., noticeably inaccurate results. The Fortran Standard’s committee has spent many years making it possible to write accurate, portable floating-point code.
A major aim of the 1999 revision of the C Standard was to make its support for floating-point programming comparable to Fortran, to entice Fortran developers to switch to C,
- people being willing to dedicate their time, over a long period, to support the activities of this group.
The minutes of all the meetings are available. The group met four times a year until 1993, and then once or twice a year. Extracting (imperfectly) the attendance from the minutes finds around 525540 unique names, with 322350 attending once and one person attending 8155 meetings. The plot below shows the number of people who attended a given number of meetings (code+data):

The survival of any group depends on those members who turn up regularly and help out. The plot below shows a sorted list of FSG member tenure, in years, excluding single attendance members (code+data):

Will the FSG live on for another 55 years at the Society of Research Software Engineering?
Fortran continues to be used in a wide range of scientific/engineering applications. There is a lot of Fortran source out there, but it’s not a fashionable language and so rarely a topic of developer conversation. A group only lives because some members invest their time to make things happen. We will have to wait and see if this transplanted groups attracts a few people willing to invest in it.
Update the next day. Added attendance from pdf minutes, and removed any middle initials to improve person matching.
Long term growth of programming language use
The names of files containing source code often include a suffix denoting the programming language used, e.g., .c for C source code. These suffixes provide a cheap and cheerful method for estimating programming language use within a file system directory.
This method has its flaws, with two main factors introducing uncertainty into the results:
- The suffix denoting something other than the designated programming language.
- Developer choice of suffix can change over time and across development environments, e.g., widely used Fortran suffixes include
.f,.for,.ftn, and .f77(Fortran77 was the second revision of the ANSI, and the version I used intensely for several years; ChatGPT only lists later versions, i.e.,f90,f95, etc).
The paper: 50 Years of Programming Language Evolution through the Software Heritage looking glass by A. Desmazières, R. Di Cosmo, and V. Lorentz uses filename suffixes to track the use of programming languages over time. The suffix data comes from the Software Heritage, which aims to collect, and share all publicly available source code, and it currently hosts over 20 billion unique source files.
The authors extract and count all filename suffixes from the Software Heritage archive, obtaining 2,836,119 unique suffixes. GitHub’s linguist catalogue of file extensions was used to identify programming languages. The top 10 most used programming languages, since 2000, are found and various quantities plotted.
A 1976 report found that at least 450 programming languages were in use at the US Department of Defense, and as of 2020 close to 9,000 languages are listed on hopl.info. The linguist catalogue contains information on 512 programming languages, with a strong bias towards languages to write open source. It is missing entries for Cobol and Ada, and its Fortran suffix list does not include .for, .ftn and .f77.
The following analysis takes an all encompassing approach. All suffixes containing at up to three characters, the first of which is alphabetic, and occurring at least 1,000 times in any year, are initially assumed to denote a programming language; the suffixes .html, .java and .json are special cased (4,050 suffixes). This initial list is filtered to remove known binary file formats, e.g., .zip and .jar. The common file extensions listed on FileInfo were filtered using the algorithm applied to the Software Heritage suffixes, producing 3,990 suffixes (the .ftn suffix, and a few others, were manually spotted and removed). Removing binary suffixes reduced the number of assumed language suffixes from 4,050 (15,658,087,071 files) to 2,242 (9,761,794,979 files).
This approach is overly generous, and includes suffixes that have not been used to denote programming language source code.
The plot below shows the number of assumed source code files created in each year (only 50% of files have a creation date), with a fitted regression line showing a 31% annual growth in files over 52 years (code+data):
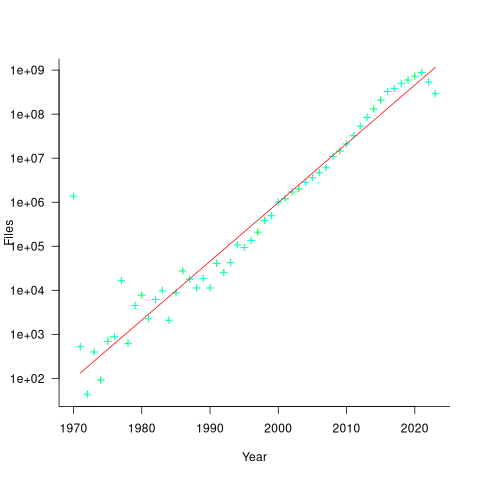
Some of the apparent growth is actually the result of older source being more likely to be lost.
Unix timestamps start on 1 Jan 1970. Most of the 1,411,277 files with a 1970 creation date probably acquired this date because of a broken conversion between version control systems.
The plot below shows the number of files assumed to contain source code in a given language per year, with some suffixes used before the language was invented (its starts in 1979, when total file counts stat always being over 1,000; code+data):
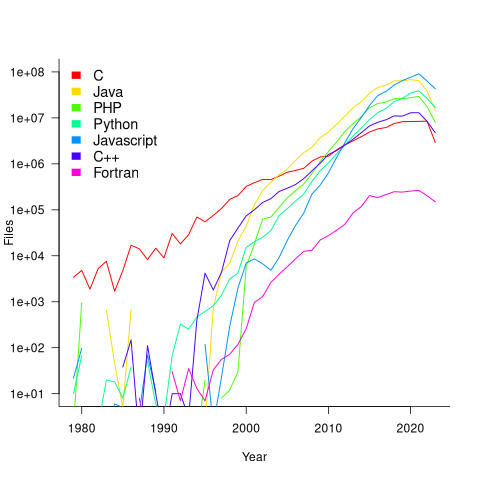
Over the last few years, survey results have been interpreted as showing declining use of C. This plot suggests that use of C is continuing to grow at around historical rates, but that use of other languages has grown rapidly to claim a greater percentage of developer implementation effort.
The major issue with this plot is what is not there. Where is the Cobol, once the most widely used language? Did Fortran only start to be used during the 1990s? Millions of lines of Cobol and Fortran were written between 1960 and 1985, but very little of this code is publicly available.
Procedure nesting a once common idiom
Structured programming was a popular program design methodology that many developers/managers claimed to be using in the 1970s and 1980s. Like all popular methodologies, everybody had/has their own idea about what it involves, and as always, consultancies sprang up to promote their take on things. The 1972 book Structured programming provides a taste of the times.
The idea underpinning structured programming is that it’s possible to map real world problems to some hierarchical structure, such as in the image below. This hierarchy model also provided a comforting metaphor for those seeking to understand software and its development.

The disadvantages of the Structured programming approach (i.e., real world problems often have important connections that cannot be implemented using a hierarchy) become very apparent as programs get larger. However, in the 1970s the installed memory capacity of most computers was measured in kilobytes, and a program containing 25K lines of code was considered large (because it was enough to consume a large percentage of the memory available). A major program usually involved running multiple, smaller, programs in sequence, each reading the output from the previous program. It was not until the mid-1980s…
At the coding level, doing structured programming involves laying out source code to give it a visible structure. Code blocks are indented to show if/for/while nesting and where possible procedure/functions are nested within the calling procedures (before C became widespread, functions that did not return a value were called procedures; Fortran has always called them subroutines).
Extensive nesting of procedures/functions was once very common, at least in languages that supported it, e.g., Algol 60 and Pascal, but not Fortran or Cobol. The spread of C, and then C++ and later Java, which did not support nesting (supported by gcc as an extension, nested classes are available in C++/Java, and later via lambda functions), erased nesting from coding consideration. I started life coding mostly in Fortran, moved to Pascal and made extensive use of nesting, then had to use C and not being able to nest functions took some getting used to. Even when using languages that support nesting (e.g., Python), I have not reestablished by previous habit of using nesting.
A common rationale for not supporting nested functions/methods is that it complicate the language specification and its implementation. A rather self-centered language designer point of view.
The following Pascal example illustrates a benefit of being able to nest procedures/functions:
procedure p1; var db :array[db_size] of char; procedure p2(offset :integer); function p3 :integer; begin (* ... *) return db[offset]; end; begin var off_val :char; off_val=p3; (* ... *) end; begin (* ... *) p2(3) end; |
The benefit of using nesting is in not forcing the developer to have to either define db at global scope, or pass it as an argument along the call chain. Nesting procedures is also a method of information hiding, a topic that took off in the 1970s.
To what extent did Algol/Pascal developers use nested procedures? A 1979 report by G. Benyon-Tinker and M. M. Lehman contains the only data I am aware of. The authors analysed the evolution of procedure usage within a banking application, from 1973 to 1978. The Algol 60 source grew from 35,845 to 63,843 LOC (657 procedures to 967 procedures). A large application for the time, but a small dataset by today’s standards.
The plot below shows the number of procedures/functions having a particular lexical nesting level, with nesting level 1 is the outermost level (i.e., globally visible procedures), and distinct colors denoting successive releases (code+data):
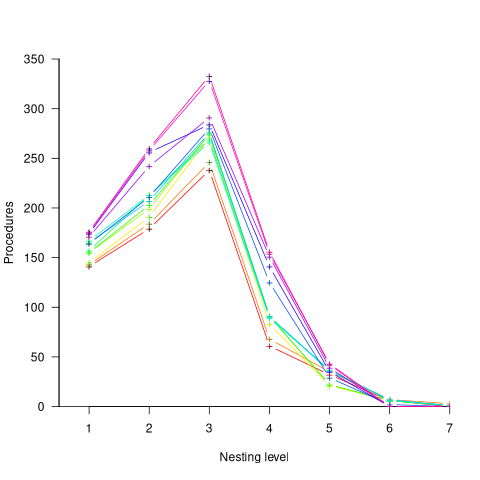
Just over 78% of procedures are nested within at least one other procedure. It’s tempting to think that nesting has a Poisson distribution, however, the distribution peaks at three rather than two. Perhaps it’s possible to fit an over-dispersed, but this feels like creating a just-so story.
What is the distribution of nested functions/methods in more recently written source? A study of 35 Python projects found 6.5% of functions nested and over twice as many (14.2%) of classed nested.
Are there worthwhile benefits to using nested functions/methods where possible, or is this once common usage mostly fashion driven with occasional benefits?
Like most questions involving cost/benefit analysis of language usage, it’s probably not sufficiently interesting for somebody to invest the effort required to run a reliable study.
Why did organizations fund the creation of the first computers?
What were the events that drove organizations to fund the creation of the first computers?
I suspect that many readers do not appreciate how long scientific/engineering calculations took before electronic computers became available, or the huge number of clerical staff employed to process the paperwork associated with running any sizeable business.
If somebody wanted to know the logarithm of some value, or the sine/cosine of an angle, they looked up the answer in a table. Individuals owned small booklets of tables supplying some level of granularity and number of significant digits. My school boy booklet contains 60-pages of tables, all to five digits of output accuracy, with logarithm supporting four-digit input values and the sine/cosine/tangent tables having an input granularity of hundredth of a degree.
The values in these tables were calculated by human computers; with the following being among the most well known (for more details, see Calculation and Tabulation in the Nineteenth Century: Airy versus Babbage by Doron Swade, and The History of Mathematical Tables: from Sumer to Spreadsheets edited by Campbell-Kelly, Croarken, Flood, and Robson):
- In 1624 Henry Briggs published logarithms for the integer ranges 1-20,000 and 90,001-100,000 (to 14 decimal places), followed some years later by tables of sine and logarithm of sine; in 1628 Adriaan Vlacq publishing tables that filled in the missing values (to 10 decimal places). In 1783 Jurij Vega published a bug-fixed and extended version of Vlacq’s tables.
In 1827 Charles Babbage (that Babbage) published Table of Logarithms of the Natural Numbers from 1 to 10800. These tables were based on corrected versions of these tables, a rigorous nine-stage proofreading process was followed to prevent new mistakes creeping in.
Today, one person can publish A reconstruction of the tables of Briggs’ Arithmetica logarithmica (1624), with an appendix containing 300 pages of calculated values,
- between 1794 and 1799, Gaspard de Prony employed sixty to eighty computers to calculate the logarithms of the integers from 1 to 200,000 to fifteen significant digits (rounding issues sometimes required calculating 25 decimal digits; published in eighteen volumes). Around 400 man-years.
Logarithms and trigonometric functions are very widely used, creating incentives for investing in calculating and publishing tables. While it may be financially worthwhile investing in producing tables for some niche markets (e.g. Life tables for insurance companies), there is an unmet demand that will only be filled by a dramatic drop in the cost of computing simple expressions.
Babbage’s Difference engine was designed to evaluate polynomial expressions and print the results; perfect for publishing tables. While Babbage did not build a Difference engine, starting in 1837, engines based on Babbage’s design were built and sold commercially by the Swede Per Georg Scheutz.
Mechanical calculators improve accuracy and speed the process up. Vacuum tubes are invented in 1904 and become widely used to process analogue signals. World War II created an urgent demand for the results of a variety of time-consuming calculations, e.g., accurate ballistic tables, and valve computers were built. The plot below shows the cost per million operations for manual, mechanical and valve computers (code+data):
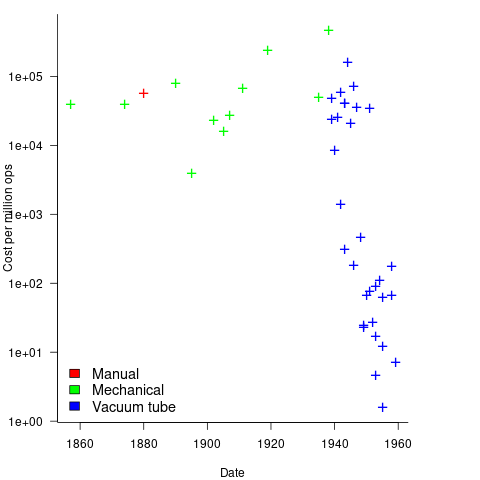
To many observers at the start of the 1950s, the market for electronic computers appeared to be organizations who needed to perform large amounts of scientific/engineering calculation.
Most businesses perform simple calculations on many unrelated values, e.g., banks have to credit/debit the appropriate account when money is deposited/withdrawn. There is no benefit in having a machine that can perform hundreds of calculations per second unless it can be fed data fast enough to keep it busy.
It so happened that, at the start of the 1950s, the US banking system was facing a crisis, the growth in the number of cheques being written meant that it would soon take longer than one day to process all the cheques that arrived in one day. In 1950 Bank of America managed 4.6 million checking accounts, and were opening 23,000 new account per month. Bank of America was then the largest bank in the world, and had a keen interest in continued growth. They funded the development of a bespoke computer system for processing cheques, the ERMA Banking system, which went live in 1959. The plot below shows the number of cheques processed per year by US banks (code+data):
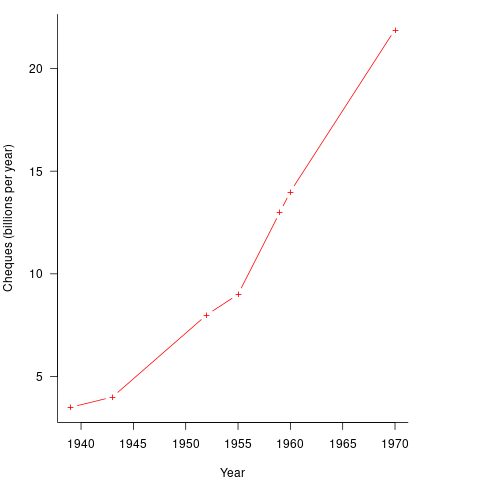
The ERMA system included electronic storage for holding account details, and data entry was speeded up by encoding account details on a magnetic strip included within every cheque.
Businesses are very interested in an integrated combination of input devices plus electronic storage plus compute. There are more commerce oriented businesses than scientific/engineering businesses, and commercial businesses usually have a lot more money to spend, i.e., the real money to be made by selling computers was the business data processing market.
The plot below shows the decreasing cost of hard disc storage (blue, right axis), along with the decreasing computing cost of valve based computers (red, left axis; code+data):
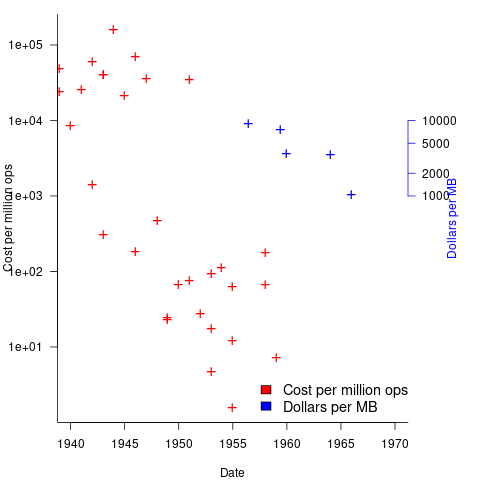
There was a larger business demand to be able to store information electronically, and the hard disc was invented by IBM, roughly 15 years after the first electronic computers.
The very different application demands of data processing and scientific/engineering are reflected in the features supported by the two languages designed in the 1950s, and widely used for the rest of the century: Cobol and Fortran.
Data processing involves simple operations on large quantities of data stored in a potentially huge number of different combinations (the myriad of mechanical point-of-sale terminals stored data in a myriad of different formats, which evolved over time, and the demand for backward compatibility created spaghetti data well before spaghetti code existed). Cobol has extensive functionality supporting the layout and format of input and output data, and simplistic coding constructs.
Scientific/engineering code involves complex calculations on some amount of input. Fortran has extensive functionality supporting program control flow, and relatively basic support for data input/output.
A third major application domain is real-time processing, such as SAGE. However, data on this domain is very hard to find, so it is not discussed.
First understand the structure of a standard, then read it
Extracting useful information from the text in an ISO programming language standard first requires an understanding of the stylized English in which it is written.
I regularly encounter people who cite wording from the C Standard to back up their interpretation of a particular language construct. My first thought when this happens is: Do I want to spend the time explaining how the standard ‘works’ to get to the point of dealing with the topic being discussed?
I am not aware of any “How to read the C Standard” guide, or such a guide for any language.
Explaining enough detail to have a sensible conversation about the text takes, maybe, 10-30 minutes. The interpretation of text in any standard can depend on the section in which it occurs, and particular phrases can be specified to have different interpretations in different contexts. For instance, in the C Standard, a source code construct that violates a “shall” requirement specified in a “Constraints” section is about as serious as things get (i.e., it’s a mandatory compile time error), while violating a “shall” requirement specified outside a “Constraints” is undefined behavior (i.e., the compiler can do what it likes, including nothing).
New readers also get hung up on footnotes, which are a great source of confusion. Footnotes have no normative meaning; technically, they are classified as informative (their real use is providing the committee a means to include wording in the document to satisfy some interested party, without the risk of breaking the standard {because this text has no normative status}).
Sometimes a person familiar with the C++ Standard applies the interpretation rules they have learned to the C Standard. This can work in limited cases, but the fundamental differences between how the two documents are structured requires a reorientation of thinking. For instance, the C Standard specifies the behavior of source code (from which the behavior of implementations has to be inferred), while the C++ Standard specifies the behavior of implementations (from which the behavior of source code constructs has to be inferred), and the C++ Standard does not contain “Constraints” sections.
The general committee response, at least in WG14, to complaints that the language standard requires effort to understand, is that the standard is not intended as a tutorial. At least there is a prose document to read, there are forms of language specification that don’t provide this luxury. At a minimum, a language standard first needs to be read two or three times before trying to answer detailed questions.
In general, once somebody has learned to interpret one ISO Standard, the know-how does not transfer to other ISO language standards, but they have an appreciation of the need for such an understanding.
In theory, know-how is supposed to be transferable; part 2 of the ISO directives, Principles and rules for the structure and drafting of ISO and IEC documents, “… stipulates certain rules to be applied in order to ensure that they are clear, precise and unambiguous.” There are also the technical reports: Guidelines for the Preparation of Conformity Clauses in Programming Language Standards (published in 1990), which I suspect few people have read, even within the standards’ programming language community, and Guidelines for the preparation of programming language standards (unchanged since the fourth edition in 2003).
In practice: The Fortran and Cobol standards were written before people had any idea which rules might be appropriate; I think the Pascal standard appeared just before the rules were formalised. Also, all three standards were created by National bodies (US, US, and UK respectively) as National standards, and then ‘promoted’ as-is to be ISO standards. ADA was a DoD standard that got ‘promoted’, and very much did its own thing with regard to stylized English.
The post-1990 language standards visually look as if they follow the ISO rules in force at the time they were first written (Directives, part 2 is on its ninth edition), i.e., the titles of clauses match the clause numbering scheme specified by ISO rules, e.g., clause 3 specifies “Terms and definitions”. However, readers are going to need some cultural background on the use of the language by its community, to figure out the intent of the text. For instance, the 1990 revision of the Pascal Standard contains extensive use of “shall”, but it is not clear how this is to be interpreted; I used Pascal extensively for 10-years, but never studied its ISO standard, and reading it now with my C Standard expertise is a strange experience, e.g., familiar language “constraints” do not appear to be specified in the text, and the compiler does not appear to be required to flag anything.
Two of the pre-1990 language standards, Fortran and Cobol, were initially written in the 1960s, and read like they are from another age (probably because of the way they are laid out, and the fonts used). The differences are so obvious that any readers with prior experience are likely to understand that they are going to have to figure out the structure from scratch. The formatting of post-1990 Fortran Standards lacks the 1960s vibe.
2021 in the programming language standards’ world
Last Tuesday I was on a Webex call (the British Standards Institute’s use of Webex for conference calls predates COVID 19) for a meeting of IST/5, the committee responsible for programming language standards in the UK.
There have been two developments whose effect, I think, will be to hasten the decline of the relevance of ISO standards in the programming language world (to the point that they are ignored by compiler vendors).
- People have been talking about switching to online meetings for years, and every now and again someone has dialed-in to the conference call phone system provided by conference organizers. COVID has made online meetings the norm (language working groups have replaced face-to-face meetings with online meetings). People are looking forward to having face-to-face meetings again, but there is talk of online attendance playing a much larger role in the future.
The cost of attending a meeting in person is the perennial reason given for people not playing an active role in language standards (and I imagine other standards). Online attendance significantly reduces the cost, and an increase in the number of people ‘attending’ meetings is to be expected if committees agree to significant online attendance.
While many people think that making it possible for more people to be involved, by reducing the cost, is a good idea, I think it is a bad idea. The rationale for the creation of standards is economic; customer costs are reduced by reducing
diversityincompatibilities across the same kind of product., e.g., all standard conforming compilers are consistent in their handling of the same construct (undefined behavior may be consistently different). When attending meetings is costly, those with a significant economic interest tend to form the bulk of those attending meetings. Every now and again somebody turns up for a drive-by-shooting, i.e., they turn up for a day to present a paper on their pet issue and are never seen again.Lowering the barrier to entry (i.e., cost) is going to increase the number of drive-by shootings. The cost of this spray of pet-issue papers falls on the regular attendees, who will have to spend time dealing with enthusiastic, single issue, newbies,
- The International Organization for Standardization (ISO is the abbreviation of the French title) has embraced the use of inclusive terminology. The ISO directives specifying the Principles and rules for the structure and drafting of ISO and IEC documents, have been updated by the addition of a new clause: 8.6 Inclusive terminology, which says:
“Whenever possible, inclusive terminology shall be used to describe technical capabilities and relationships. Insensitive, archaic and non-inclusive terms shall be avoided. For the purposes of this principle, “inclusive terminology” means terminology perceived or likely to be perceived as welcoming by everyone, regardless of their sex, gender, race, colour, religion, etc.
New documents shall be developed using inclusive terminology. As feasible, existing and legacy documents shall be updated to identify and replace non-inclusive terms with alternatives that are more descriptive and tailored to the technical capability or relationship.”
The US Standards body, has released the document INCITS inclusive terminology guidelines. Section 5 covers identifying negative terms, and Section 6 deals with “Migration from terms with negative connotations”. Annex A provides examples of terms with negative connotations, preceded by text in bright red “CONTENT WARNING: The following list contains material that may be harmful or
traumatizing to some audiences.”“Error” sounds like a very negative word to me, but it’s not in the annex. One of the words listed in the annex is “dummy”. One member pointed out that ‘dummy’ appears 794 times in the current Fortran standard, (586 times in ‘dummy argument’).
Replacing words with negative connotations leads to frustration and distorted perceptions of what is being communicated.
I think there will be zero real world impact from the use of inclusive terminology in ISO standards, for the simple reason that terminology in ISO standards usually has zero real world impact (based on my experience of the use of terminology in ISO language standards). But the use of inclusive terminology does provide a new opportunity for virtue signalling by members of standards’ committees.
While use of inclusive terminology in ISO standards is unlikely to have any real world impact, the need to deal with suggested changes of terminology, and new terminology, will consume committee time. Most committee members tend to a rather pragmatic, but it only takes one or two people to keep a discussion going and going.
Over time, compiler vendors are going to become disenchanted with the increased workload, and the endless discussions relating to pet-issues and inclusive terminology. Given that there are so few industrial strength compilers for any language, the world no longer needs formally agreed language standards; the behavior that implementations have to support is controlled by the huge volume of existing code. Eventually, compiler vendors will sever the cord to the ISO standards process, and outside the SC22 bubble nobody will notice.
Widely used programming languages: past, present, and future
Programming languages are like pop groups in that they have followers, fans and supporters; new ones are constantly being created and some eventually become widely popular, while those that were once popular slowly fade away or mutate into something else.
Creating a language is a relatively popular activity. Science fiction and fantasy authors have been doing it since before computers existed, e.g., the Elf language Quenya devised by Tolkien, and in the computer age Star Trek’s Klingon. Some very good how-to books have been written on the subject.
As soon as computers became available, people started inventing programming languages.
What have been the major factors influencing the growth to widespread use of a new programming languages (I’m ignoring languages that become widespread within application niches)?
Cobol and Fortran became widely used because there was widespread implementation support for them across computer manufacturers, and they did not have to compete with any existing widely used languages. Various niches had one or more languages that were widely used in that niche, e.g., Algol 60 in academia.
To become widely used during the mainframe/minicomputer age, a new language first had to be ported to the major computers of the day, whose products sometimes supported multiple, incompatible operating systems. No new languages became widely used, in the sense of across computer vendors. Some new languages were widely used by developers, because they were available on IBM computers; for several decades a large percentage of developers used IBM computers. Based on job adverts, RPG was widely used, but PL/1 not so. The use of RPG declined with the decline of IBM.
The introduction of microcomputers (originally 8-bit, then 16, then 32, and finally 64-bit) opened up an opportunity for new languages to become widely used in that niche (which would eventually grow to be the primary computing platform of its day). This opportunity occurred because compiler vendors for the major languages of the day did not want to cannibalize their existing market (i.e., selling compilers for a lot more than the price of a microcomputer) by selling a much lower priced product on microcomputers.
BASIC became available on practically all microcomputers, or rather some dialect of BASIC that was incompatible with all the other dialects. The availability of BASIC on a vendor’s computer promoted sales of the hardware, and it was not worthwhile for the major vendors to create a version of BASIC that reduced portability costs; the profit was in games.
The dominance of the Microsoft/Intel partnership removed the high cost of porting to lots of platforms (by driving them out of business), but created a major new obstacle to the wide adoption of new languages: Developer choice. There had always been lots of new languages floating around, but people only got to see the subset that were available on the particular hardware they targeted. Once the cpu/OS (essentially) became a monoculture most new languages had to compete for developer attention in one ecosystem.
Pascal was in widespread use for a few years on micros (in the form of Turbo Pascal) and university computers (the source of Wirth’s ETH compiler was freely available for porting), but eventually C won developer mindshare and became the most widely used language. In the early 1990s C++ compiler sales took off, but many developers were writing C with a few C++ constructs scattered about the code (e.g., use of new, rather than malloc/free).
Next, the Internet took off, and opened up an opportunity for new languages to become dominant. This opportunity occurred because Internet related software was being made freely available, and established compiler vendors were not interested in making their products freely available.
There were people willing to invest in creating a good-enough implementation of the language they had invented, and giving it away for free. Luck, plus being in the right place at the right time resulted in PHP and Javascript becoming widely used. Network effects prevent any other language becoming widely used. Compatible dialects of PHP and Javascript may migrate widespread usage to quite different languages over time, e.g., Facebook’s Hack.
Java rode to popularity on the coat-tails of the Internet, and when it looked like security issues would reduce it to niche status, it became the vendor supported language for one of the major smart-phone OSs.
Next, smart-phones took off, but the availability of Open Source compilers closed the opportunity window for new languages to become dominant through lack of interest from existing compiler vendors. Smart-phone vendors wanted to quickly attract developers, which meant throwing their weight behind a language that many developers were already familiar with; Apple went with Objective-C (which evolved to Swift), Google with Java (which evolved to Kotlin, because of the Oracle lawsuit).
Where does Python fit in this grand scheme? I don’t yet have an answer, or is my world-view wrong to treat Python usage as being as widespread as C/C++/Java?
New programming languages continue to be implemented; I don’t see this ever stopping. Most don’t attract more users than their implementer, but a few become fashionable amongst the young, who are always looking to attach themselves to something new and shiny.
Will a new programming language ever again become widely used?
Like human languages, programming languages experience strong networking effects. Widely used languages continue to be widely used because many companies depend on code written in it, and many developers who can use it can obtain jobs; what company wants to risk using a new language only to find they cannot hire staff who know it, and there are not many people willing to invest in becoming fluent in a language with no immediate job prospects.
Today’s widely used programmings languages succeeded in a niche that eventually grew larger than all the other computing ecosystems. The Internet and smart-phones are used by everybody on the planet, there are no bigger ecosystems to provide new languages with a possible route to widespread use. To be widely used a language first has to become fashionable, but from now on, new programming languages that don’t evolve from (i.e., be compatible with) current widely used languages are very unlikely to migrate from fashionable to widely used.
It has always been possible for a proficient developer to dedicate a year+ of effort to create a new language implementation. Adding the polish need to make it production ready used to take much longer, but these days tool chains such as LLVM supply a lot of the heavy lifting. The problem for almost all language creators/implementers is community building; they are terrible at dealing with other developers.
It’s no surprise that nearly all the new languages that become fashionable originate with language creators who work for a company that happens to feel a need for a new language. Examples include:
- Go created by Google for internal use, and attracted an outside fan base. Company languages are not new, with IBM’s PL/1 being the poster child (or is there a more modern poster child). At the moment Go is a trendy language, and this feeds a supply of young developers willing to invest in learning it. Once the trendiness wears off, Google will start to have problems recruiting developers, the reason: Being labelled as a Go developer limits job prospects when few other companies use the language. Talk to a manager who has tried to recruit developers to work on applications written in Fortran, Pascal and other once-widely used languages (and even wannabe widely used languages, such as Ada),
- Rust a vanity project from Mozilla, which they have now
abandonedcast adrift. Did Rust become fashionable because it arrived at the right time to become the not-Google language? I await a PhD thesis on the topic of the rise and fall of Rust, - Microsoft’s C# ceased being trendy some years ago. These days I don’t have much contact with developers working in the Microsoft ecosystem, so I don’t know anything about the state of the C# job market.
Every now and again a language creator has the social skills needed to start an active community. Zig caught my attention when I read that its creator, Andrew Kelley, had quit his job to work full-time on Zig. Two and a-half years later Zig has its own track at FOSEM’21.
Will Zig become the next fashionable language, as Rust/Go popularity fades? I’m rooting for Zig because of its name, there are relatively few languages whose name starts with Z; the start of the alphabet is over-represented with language names. It would be foolish to root for a language because of a belief that it has magical properties (e.g., powerful, readable, maintainable), but the young are foolish.
Enthusiasm on the Fortran standards committee
The Fortran language standards committee, SC22/WG5, has an unusual situation on its hands. Two people have put themselves forward to chair the committee, when the current chairman’s three year term ends. What is unusual is that it is often difficult to find anybody willing to do the job.
The two candidates are the outgoing chair (the person who invariably does the job, until they decide they have had enough, or can arm wrestle someone else to do it), and a scientist at Los Alamos; I don’t know either person.
SC22 (the ISO committee responsible for language standards), and INCITS (the US Standards body; the US is the Fortran committee secretariate) will work something out.
I had heard that the new guy was ruffling some feathers, and I thought good for him (committees could do with having their feathers ruffled every now and again). Then I read the running for convenor announcement; oh dear. Every committee has a way of working: the objectives listed in this announcement would go down really well with the C++ committee (which already does many of the points listed), but the Fortran committee don’t operate this way.
The language standards world appears to be very similar to the open source world, in that they are both driven by the people who do the work. One person can have a big impact in the open source world, simply by doing the work, but in the language standards world there is voting (people can vote in the open source world by using software or not). One person can write papers and propose lots of additions to a standard, but the agreement of committee members is needed before any wording is added to a draft standard, which eventually goes out for a round of voting by national bodies.
Over the years I have seen several people on a standards committee starting out very enthusiastic, writing proposals and expounding them at meetings; then after a year or two becoming despondent because nothing has happened. If committee members don’t like your proposal (or choose to spend their time on other proposals), they do nothing. A majority doing nothing is enough to stop something happening.
Once a language has become established, many of its users want the committee to move slowly. Compiler vendors don’t want to spend all their time keeping up with language updates (which rarely help sell more product), and commercial users don’t want the hassle of having to spend time working out how a new standard might impact them (having zero impact on existing is a common aim of language committees).
The young, the enthusiastic, and magazines looking to sell clicks are excited by change. An ISO language committee is generally not the place to find it.
Update
INCITS have nominated the current chair for the next three-year term.
Influential programming languages: some of the considerations
Which programming languages have been the most influential?
Let’s define an influential language as one that has had an impact on lots of developers. What impact might a programming language have on developers?
To have an impact a language needs to be used by lots of people, or at least have a big impact on a language that is used by lots of people.
Figuring out the possible impacts a language might have had is very difficult, requiring knowledge of different application domains, software history, and implementation techniques. The following discussion of specific languages illustrate some of the issues.
Simula is an example of a language used by a handful of people, but a few of the people under its influence went on to create Smalltalk and C++. Some people reacted against the complexity of Algol 68, creating much simpler languages (e.g., Pascal), while others thought some of its feature were neat and reused them (e.g., Bourne shell).
Cobol has been very influential, at least within business computing (those who have not worked in business computing complain about constructs handling uses that it was not really designed to handle, rather than appreciating its strengths in doing what it was designed to do, e.g., reading/writing and converting a wide range of different numeric data formats). RPG may have been even more influential in this usage domain (all businesses have to specific requirements on formatting reports).
I suspect that most people could not point to the major influence C has had on almost every language since. No, not the use of { and }; if a single character is going to be used as a compound statement bracketing token, this pair are the only available choice. Almost every language now essentially uses C’s operator precedence (rather than Fortran‘s, which is slightly different; R follows Fortran).
Algol 60 has been very influential: until C came along it was the base template for many languages.
Fortran is still widely used in scientific and engineering software. Its impact on other languages may be unknown to those involved. The intricacies of floating-point arithmetic are difficult to get right, and WG5 (the ISO language committee, although the original work was done by the ANSI committee, J3). Fortran code is often computationally intensive, and many optimization techniques started out optimizing Fortran (see “Optimizing Compilers for Modern Architectures” by Allen and Kennedy).
BASIC showed how it was possible to create a usable interactive language system. The compactness of its many, and varied, implementations were successful because they did not take up much storage and were immediately usable.
Forth has been influential in the embedded systems domain, and also people fall in love with threaded code as an implementation technique (see “Threaded Interpretive Languages” by Loeliger).
During the mid-1990s the growth of the Internet enabled a few new languages to become widely used, e.g., PHP and Javascript. It’s difficult to say whether these were more influenced by what their creators ate the night before or earlier languages. PHP and Javascript are widely used, and they have influenced the creation of many languages designed to fix their myriad of issues.
First language taught to undergraduates in the 1990s
The average new graduate is likely to do more programming during the first month of a software engineering job, than they did during a year as an undergraduate. Programming courses for undergraduates is really about filtering out those who cannot code.
Long, long ago, when I had some connection to undergraduate hiring, around 70-80% of those interviewed for a programming job could not write a simple 10-20 line program; I’m told that this is still true today. Fluency in any language (computer or human) takes practice, and the typical undergraduate gets very little practice (there is no reason why they should, there are lots of activities on offer to students and programming fluency is not needed to get a degree).
There is lots of academic discussion around which language students should learn first, and what languages they should be exposed to. I have always been baffled by the idea that there was much to be gained by spending time teaching students multiple languages, when most of them barely grasp the primary course language. When I was at school the idea behind the trendy new maths curriculum was to teach concepts, rather than rote learning (such as algebra; yes, rote learning of the rules of algebra); the concept of number-base was considered to be a worthwhile concept and us kids were taught this concept by having the class convert values back and forth, such as base-10 numbers to base-5 (base-2 was rarely used in examples). Those of us who were good at maths instantly figured it out, while everybody else was completely confused (including some teachers).
My view is that there is no major teaching/learning impact on the choice of first language; it is all about academic fashion and marketing to students. Those who have the ability to program will just pick it up, and everybody else will flounder and do their best to stay away from it.
Richard Reid was interested in knowing which languages were being used to teach introductory programming to computer science and information systems majors. Starting in 1992, he contacted universities roughly twice a year, asking about the language(s) used to teach introductory programming. The Reid list (as it became known), was regularly updated until Reid retired in 1999 (the average number of universities included in the list was over 400); one of Reid’s ex-students, Frances VanScoy, took over until 2006.
The plot below is from 1992 to 2002, and shows languages in the top with more than 3% usage in any year (code+data):
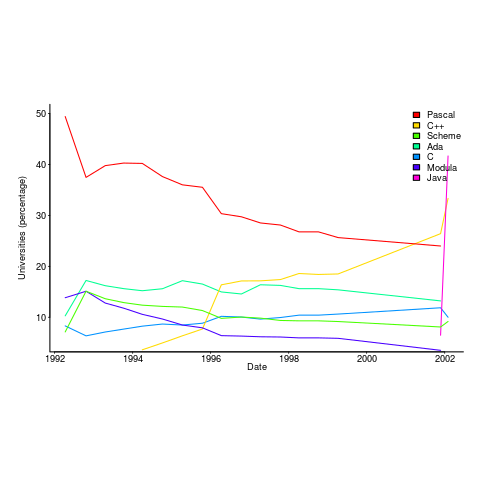
Looking at the list again reminded me how widespread Pascal was as a teaching language. Modula-2 was the language that Niklaus Wirth designed as the successor of Pascal, and Ada was intended to be the grown up Pascal.
While there is plenty of discussion about which language to teach first, doing this teaching is a low status activity (there is more fun to be had with the material taught to the final year students). One consequence is lack of any real incentive for spending time changing the course (e.g., using a new language). The Open University continued teaching Pascal for years, because material had been printed and had to be used up.
C++ took a while to take-off because of its association with C (which was very out of fashion in academia), and Java was still too new to risk exposing to impressionable first-years.
A count of the total number of languages listed, between 1992 and 2002, contains a few that might not be familiar to readers.
Ada Ada/Pascal Beta Blue C
1087 1 10 3 667
C/Java C/Scheme C++ C++/Pascal Eiffel
1 1 910 1 29
Fortran Haskell HyperTalk ISETL ISETL/C
133 12 2 30 1
Java Java/Haskell Miranda ML ML/Java
107 1 48 16 1
Modula-2 Modula-3 Oberon Oberon-2 ObjPascal
727 24 26 7 22
Orwell Pascal Pascal/C Prolog Scheme
12 2269 1 12 752
Scheme/ML Scheme/Turing Simula Smalltalk SML
1 1 14 33 88
Turing Visual-Basic
71 3 |
I had never heard of Orwell, a vanity language foisted on Oxford Mathematics and Computation students. It used to be common for someone in computing departments to foist their vanity language on students; it enabled them to claim the language was being used and stoked their ego. Is there some law that enables students to sue for damages?
The 1990s was still in the shadow of the 1980s fashion for functional programming (which came back into fashion a few years ago). Miranda was an attempt to commercialize a functional language compiler, with Haskell being an open source reaction.
I was surprised that Turing was so widely taught. More to do with the stature of where it came from (university of Toronto), than anything else.
Fortran was my first language, and is still widely used where high performance floating-point is required.
ISETL is a very interesting language from the 1960s that never really attracted much attention outside of New York. I suspect that Blue is BlueJ, a Java IDE targeting novices.
Recent Comments