Archive
Unique bytes in a sliding window as a file content signature
I was at a workshop a few months ago where a speaker pointed out a useful technique for spotting whether a file contains compressed data, e.g., a virus hidden in a script by compressing it to look like a jumble of numbers. Compressed data contains a uniform distribution of byte values (after all, compression is achieved by reducing apparent information content), your mileage may vary between compression techniques. The thought struck me that it would only take a minute to knock up an R script to check out this claim (my use of R is starting to branch out into solving certain kinds of general coding problems) and here it is:
window_width=256 # if this is less than 256 divisor has to change in call to plot
plot_unique=function(filename)
{
t=readBin(filename, what="raw", n=1e7)
# Sliding the window over every point is too much overhead
cnt_points=seq(1, length(t)-window_width, 5)
u=sapply(cnt_points, function(X) length(unique(t[X:(X+window_width)])))
plot(u/256, type="l", xlab="Offset", ylab="Fraction Unique", las=1)
return(u)
}
dummy=plot_unique("http://shape-of-code.com/2013/05/17/preferential-attachment-applied-to-frequency-of-accessing-a-variable/")
dummy=plot_unique("http://www.shape-of-code.com/R_code/requirements.tgz") |
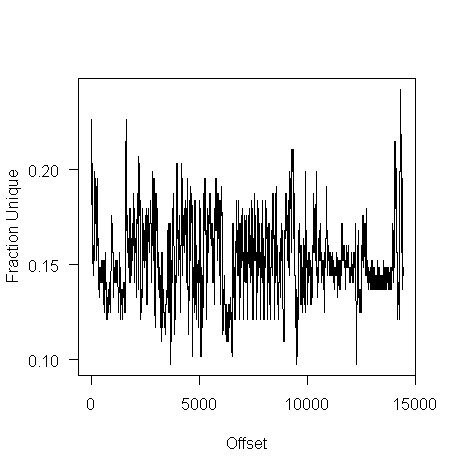
The unique bytes per window (256 bytes wide) of a HTML file has a mean around 15% (sd 2):
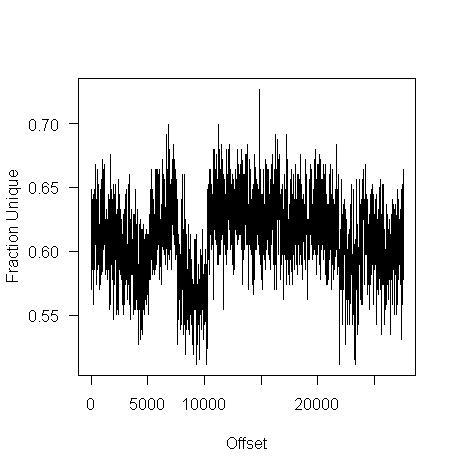
while for a tgz file the mean is 61% (sd 2.9):
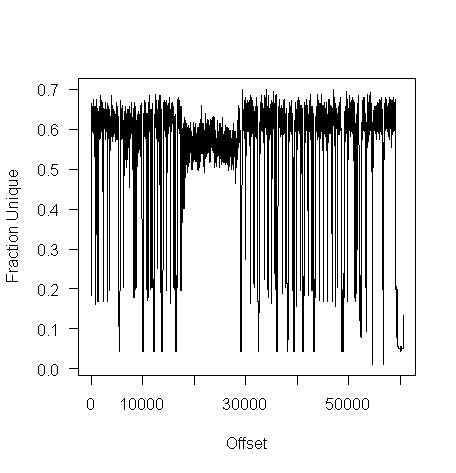
I don’t have any scripts containing a virus, but I do have a pdf containing lots of figures (are viruses hidden in pieces all all together?):
Do let me know if you find any interesting ‘unique byte’ signatures for file contents.
Recent Comments