Archive
One code path dominates method execution
A recurring claim is that most reported faults are the result of coding mistakes in a small percentage of a program’s source code, with the 80/20 ‘rule’ being cited for social confirmation. I think there is something to this claim, but that the percentages are not so extreme.
A previous post pointed out that reported faults are caused by users. The 80/20 observation can be explained by users only exercising a small percentage of a program’s functionality (a tiny amount of data supports this observation). Surprisingly, there are researchers who believe that a small percentage of the code has some set of characteristics which causes it to contain most of a program’s coding mistakes (this belief has the advantage that a lot of source code is easily accessible and can be analysed to produce papers).
To what extent does user input direct program execution towards a small’ish subset of the code available to be executed?
The recent paper: Monitoring the Execution of 14K Tests: Methods Tend to Have One Path That Is Significantly More Executed by Andre Hora counted the number of times each path through a method’s source code was executed, when the method was called, for the 5,405 methods in 25 Python programs. These programs were driven by their 14,177 tests, rather than user input. The paper is focused on testing, in particular developer that developers tend to focus on positive tests.
Test suites are supposed to exercise all of a program’s source, so it is to be expected that these measurements will show a wider dispersion of code coverage than might be expected of typical user input.
The measurements also include a count of the lines executed/not executed along each executed method path. No information is provided on the number of unexecuted paths.
Within a method, there is always going to one path through the code that is executed more often than any other path. What this study found is that the most common path is often executed many more times than the other paths. The plot below shows, for each method (each +), the percentage of all calls to a method where the most common path was executed, against the total number of executed paths for that method; red/blue lines are fitted power law/exponential regression models, and the grey line shows the case where percentage executed is the fraction for a given number of paths (code+data):
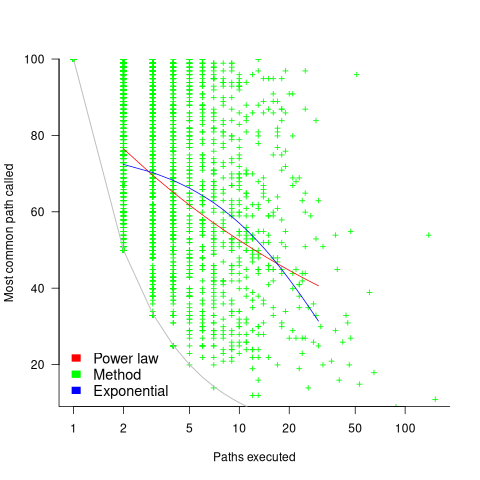
On average, the most common path is executed around four times more often than the second most commonly executed path.
While statistically significant, the fitted models do not explain much of the variance in the data. An argument can be made for either a power law and exponential distribution, and not having a feel for what to expect, I fitted both.
Non-error paths through a method have been found to be longer than the error paths. These measurements do not contain the information needed to attempt to replicate this finding.
New paths through a method are created by conditional statements, and the percentage of such statements in a method tends to be relatively constant across methods. The plot below shows the percentage of all calls to a method where the most common path was executed, where the method (each +) contains a given LOC; red/blue lines are fitted power law/exponential regression models (code+data):
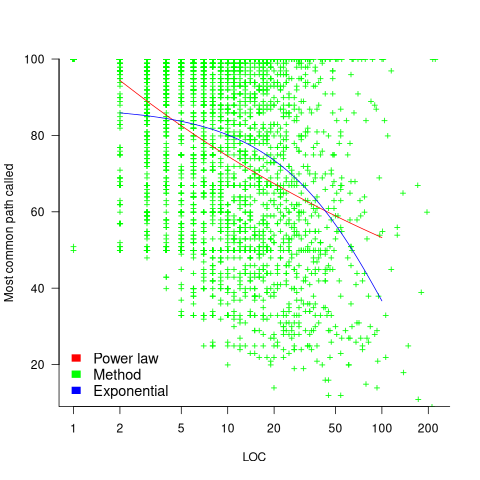
The models fitted to against LOC are better than those fitted against paths executed, but still not very good. A possible reason is that some methods will have unexecuted paths, LOC is a good proxy for total paths, and most common path percentage depends on total paths.
On average, 56% of a method’s LOC are executed along the most frequently executed path. When weighted by the number of method calls, the percentage is 48%.
The results of this study show that a call to most methods is likely to be dominated by the execution of one sequence of code. Another way that in which a small amount of code can dominate program execution is when most calls are to a small subset of the available methods. The plot below shows a density plot for the total number of calls to each method (code+data):

Around 62% of methods are called less than 100 times, while 2.6% are called over 10,000 times.
Program fault reports are caused by its users
Faults are generated by users of the software; no users, no fault reports. Fault reports will be generated for software that is free of coding mistakes; one study found that 42.6% of fault reports were misclassified as either requests for an enhancement, changes to documentation, or a refactoring request, or not requiring changes to the code; a study of NASA spaceflight software found that 63% of reports in the defect tracking tool were change requests.
Is the number of reported faults proportional to the number of users, the log of the number of users, or perhaps it depends on the application, or who knows what?
Some users will only use some features, others other features. Some users will be occasional users, while some will be heavy users.
There are a handful of fault report datasets containing measurements of software usage. The largest, and most widely cited, is “Optimizing Preventive Service of Software Products” by E. N. Adams. The data is this paper lists the number of faults reported in eight time intervals (20 to 50,000 months), for nine applications running on IBM mainframes between 1975 and 1980. Traditionally, the licensing for many Mainframe applications charge customers a fee based on their usage. Does this usage data still exist? Perhaps there is some sitting on a shelf in court documents. Pointers to possible cases most welcome.
Early papers on software testing sometimes measured the amount of cpu, or elapsed time, between each fault experience. However, the raw data was rarely published.
Data is available, for the Debian and Ubuntu distributions, on the number of installs for each application (counts rely on local machine sending information on installs, which is now an opt-in process for Ubuntu).
The following analysis uses data from the paper Impact of Installation Counts on Perceived Quality: A Case Study on Debian by Herraiz, Shihab, Nguyen, and Hassan, and the Ubuntu popularity project.
The plot below shows the number of reported faults against number of installs for the 14,565 programs in the “wheezy” Debian release; red line is the fitted power law:  (code+data):
(code+data):
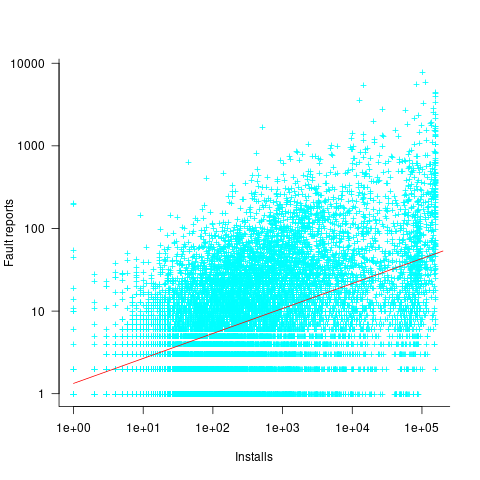
The huge variability in the number of fault reports for a given number of installs is likely driven by variability in the usage of the installed programs (or even no usage; I installed ImageMagick purely to use its convert program), the propensity of users of particular programs to report fault experiences (which in turn depends on the need for a fix, and the ease of reporting), and the number of coding faults in the source code.
The Debian installs/faults data does not include any usage information, however, the Ubuntu popularity data includes not only a count of installs, but the corresponding counts of regular users and non-usages. Given that Ubuntu is a fork of Debian, and has substantial usage, I’m assuming that the user base is sufficiently similar that the Ubuntu usage data at the time of the “wheezy” release can be applied to the “wheezy” Debian install/fault data.
The plot below shows, for 220,309 programs, the fraction of installs that are regularly used against the corresponding number of installs. The left-most line running top-left to bottom-right shows programs regularly used by one install, next line two regular users, etc (code+data):

Using the merged, by program name, Ubuntu usage/Debian fault counts, I built several regression models, along with plotting the data/fits. The quality of the models was worse than the original Debian model 🙁 . Two possibilities that spring to mind are: the correlation between usage and fault reports only becomes visible when the counts are divided into short periods (perhaps a year?), or the correlation is very weak. It is probably going to take a lot of time to work through this.
Likelihood of a fault experience when using the Horizon IT system
It looks like the UK Post Office’s Horizon IT system is going to have a significant impact on the prosecution of cases that revolve around the reliability of software systems, at least in the UK. I have discussed the evidence illustrating the fallacy of the belief that “most computer error is either immediately detectable or results from error in the data entered into the machine.” This post discusses what can be learned about the reliability of a program after a fault experience has occurred, or alleged to have occurred in the Horizon legal proceedings.
Sub-postmasters used the Horizon IT system to handle their accounts with the Post Office. In some cases money that sub-postmasters claimed to have transferred did not appear in the Post Office account. The sub-postmasters claimed this was caused by incorrect behavior of the Horizon system, the Post Office claimed it was due to false accounting and prosecuted or fired people and sometimes sued for the ‘missing’ money (which could be in the tens of thousands of pounds); some sub-postmasters received jail time. In 2019 a class action brought by 550 sub-postmasters was settled by the Post Office, and the presiding judge has passed a file to the Director of Public Prosecutions; the Post Office may be charged with instituting and pursuing malicious prosecutions. The courts are working their way through reviewing the cases of the sub-postmasters charged.
How did the Post Office lawyers calculate the likelihood that the missing money was the result of a ‘software bug’?
Horizon trial transcript, day 1, Mr De Garr Robinson acting for the Post Office: “Over the period 2000 to 2018 the Post Office has had on average 13,650 branches. That means that over that period it has had more than 3 million sets of monthly branch accounts. It is nearly 3.1 million but let’s call it 3 million and let’s ignore the fact for the first few years branch accounts were weekly. That doesn’t matter for the purposes of this analysis. Against that background let’s take a substantial bug like the Suspense Account bug which affected 16 branches and had a mean financial impact per branch of £1,000. The chances of that bug affecting any branch is tiny. It is 16 in 3 million, or 1 in 190,000-odd.”
That 3.1 million comes from the calculation: 19-year period times 12 months per year times 13,650 branches.
If we are told that 16 events occurred, and that there are 13,650 branches and 3.1 million transactions, then the likelihood of a particular transaction being involved in one of these events is 1 in 194,512.5. If all branches have the same number of transactions, the likelihood of a particular branch being involved in one of these 16 events is 1 in 853 (13650/16 -> 853); the branch likelihood will be proportional to the number of transactions it performs (ignoring correlation between transactions).
This analysis does not tell us anything about the likelihood that 16 events will occur, and it does not tell us anything about whether these events are the result of a coding mistake or fraud.
We don’t know how many of the known 16 events are due to mistakes in the code and how many are due to fraud. Let’s ask: What is the likelihood of one fault experience occurring in a software system that processes a total of 3.1 million transactions (the number of branches is not really relevant)?
The reply to this question is that it is not possible to calculate an answer, because all the required information is not specified.
A software system is likely to contain some number of coding mistakes, and given the appropriate input, any of these mistakes may produce a fault experience. The information needed to calculate the likelihood of one fault experience occurring is:
- the number of coding mistakes present in the software system,
- for each coding mistake, the probability that an input drawn from the distribution of input values produced by users of the software will produce a fault experience.
Outside of research projects, I don’t know of any anyone who has obtained the information needed to perform this calculation.
The Technical Appendix to Judgment (No.6) “Horizon Issues” states that there were 112 potential occurrences of the Dalmellington issue (paragraph 169), but does not list the number of transactions processed between these ‘issues’ (which would enable a likelihood to be estimated for that one coding mistake).
The analysis of the Post Office expert, Dr Worden, is incorrect in a complicated way (paragraphs 631 through 635). To ‘prove’ that the missing money was very unlikely to be the result of a ‘software bug’, Dr Worden makes a calculation that he claims is the likelihood of a particular branch experiencing a ‘bug’ (he makes the mistake of using the number of known events, not the number of unknown possible events). He overlooks the fact that while the likelihood of a particular branch experiencing an event may be small, the likelihood of any one of the branches experiencing an event is 13,630 times higher. Dr Worden’s creates complication by calculating the number of ‘bugs’ that would have to exist for there to be a 1 in 10 chance of a particular branch experiencing an event (his answer is 50,000), and then points out that 50,000 is such a large number it could not be true.
As an analogy, let’s consider the UK National Lottery, where the chance of winning the Thunderball jackpot is roughly 1 in 8-million per ticket purchased. Let’s say that I bought a ticket and won this week’s jackpot. Using Dr Worden’s argument, the lottery could claim that my chance of winning was so low (1 in 8-million) that I must have created a counterfeit ticket; they could even say that because I did not buy 0.8 million tickets, I did not have a reasonable chance of winning, i.e., a 1 in 10 chance. My chance of winning from one ticket is the same as everybody else who buys one ticket, i.e., 1 in 8-million. If millions of tickets are bought, it is very likely that one of them will win each week. If only, say, 13,650 tickets are bought each week, the likelihood of anybody winning in any week is very low, but eventually somebody will win (perhaps after many years).
The difference between the likelihood of winning the Thunderball jackpot and the likelihood of a Horizon fault experience is that we have enough information to calculate one, but not the other.
The analysis by the defence team produced different numbers, i.e., did not conclude that there was not enough information to perform the calculation.
Is there any way that the information needed to calculate the likelihood of a fault experience occurring?
In theory fuzz testing could be used. In practice this is probably completely impractical. Horizon is a data driven system, and so a copy of the database would need to be used, along with a copy of all the Horizon software. Where is the computer needed to run this software+database? Yes, use of the Post Office computer system would be needed, along with all the necessary passwords.
Perhaps, if we wait long enough, a judge will require that one party make all the software+database+computer+passwords available to the other party.
Source code discovery, skipping over the legal complications
The 2020 US elections introduced the issue of source code discovery, in legal cases, to a wider audience. People wanted to (and still do) check that the software used to register and count votes works as intended, but the companies who wrote the software wouldn’t make it available and the courts did not compel them to do so.
I was surprised to see that there is even a section on “Transfer of or access to source code” in the EU-UK trade and cooperation agreement, agreed on Christmas Eve.
I have many years of experience in discovering problems in the source code of programs I did not write. This experience derives from my time as a compiler implementer (e.g., a big customer is being held up by a serious issue in their application, and the compiler is being blamed), and as a static analysis tool vendor (e.g., managers want to know about what serious mistakes may exist in the code of their products). In all cases those involved wanted me there, I could talk to some of those involved in developing the code, and there were known problems with the code. In court cases, the defence does not want the prosecution looking at the code, and I assume that all conversations with the people who wrote the code goes via the lawyers. I have intentionally stayed away from this kind of work, so my practical experience of working on legal discovery is zero.
The most common reason companies give for not wanting to make their source code available is that it contains trade-secrets (they can hardly say that it’s because they don’t want any mistakes in the code to be discovered).
What kind of trade-secrets might source code contain? Most code is very dull, and for some programs the only trade-secret is that if you put in the implementation effort, the obvious way of doing things works, i.e., the secret sauce promoted by the marketing department is all smoke and mirrors (I have had senior management, who have probably never seen the code, tell me about the wondrous properties of their code, which I had seen and knew that nothing special was present).
Comments may detail embarrassing facts, aka trade-secrets. Sometimes the code interfaces to a proprietary interface format that the company wants to keep secret, or uses some formula that required a lot of R&D (management gets very upset when told that ‘secret’ formula can be reverse engineered from the executable code).
Why does a legal team want access to source code?
If the purpose is to check specific functionality, then reading the source code is probably the fastest technique. For instance, checking whether a particular set of input values can cause a specific behavior to occur, or tracing through the logic to understand the circumstances under which a particular behavior occurs, or in software patent litigation checking what algorithms or formula are being used (this is where trade-secret claims appear to be valid).
If the purpose is a fishing expedition looking for possible incorrect behaviors, having the source code is probably not that useful. The quantity of source contained in modern applications can be huge, e.g., tens to hundreds of thousands of lines.
In ancient times (i.e., the 1970s and 1980s) programs were short (because most computers had tiny amounts of memory, compared to post-2000), and it was practical to read the source to understand a program. Customer demand for more features, and the fact that greater storage capacity removed the need to spend time reducing code size, means that source code ballooned. The following plot shows the lines of code contained in the collected algorithms of the Transactions on Mathematical Software, the red line is a fitted regression model of the form:  (code+data):
(code+data):
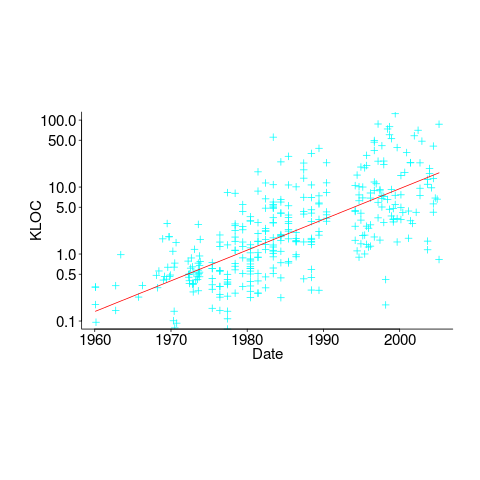
How, by reading the source code, does anybody find mistakes in a 10+ thousand line program? If the program only occasionally misbehaves, finding a coding mistake by reading the source is likely to be very very time-consuming, i.e, months. Work it out yourself: 10K lines of code is around 200 pages. How long would it take you to remember all the details and their interdependencies of a detailed 200-page technical discussion well enough to spot an inconsistency likely to cause a fault experience? And, yes, the source may very well be provided as a printout, or as a pdf on a protected memory stick.
From my limited reading of accounts of software discovery, the time available to study the code may be just days or maybe a week or two.
Reading large quantities of code, to discover possible coding mistakes, are an inefficient use of human time resources. Some form of analysis tool might help. Static analysis tools are one option; these cost money and might not be available for the language or dialect in which the source is written (there are some good tools for C because it has been around so long and is widely used).
Character assassination, or guilt by innuendo is another approach; the code just cannot be trusted to behave in a reasonable manner (this approach is regularly used in the software business). Software metrics are deployed to give the impression that it is likely that mistakes exist, without specifying specific mistakes in the code, e.g., this metric is much higher than is considered reasonable. Where did these reasonable values come from? Someone, somewhere said something, the Moon aligned with Mars and these values became accepted ‘wisdom’ (no, reality is not allowed to intrude; the case is made by arguing from authority). McCabe’s complexity metric is a favorite, and I have written how use of this metric is essentially accounting fraud (I have had emails from several people who are very unhappy about me saying this). Halstead’s metrics are another favorite, and at least Halstead and others at the time did some empirical analysis (the results showed how ineffective the metrics were; the metrics don’t calculate the quantities claimed).
The software development process used to create software is another popular means of character assassination. People seem to take comfort in the idea that software was created using a defined process, and use of ad-hoc methods provides an easy target for ridicule. Some processes work because they include lots of testing, and doing lots of testing will of course improve reliability. I have seen development groups use a process and fail to produce reliable software, and I have seen ad-hoc methods produce reliable software.
From what I can tell, some expert witnesses are chosen for their ability to project an air of authority and having impressive sounding credentials, not for their hands-on ability to dissect code. In other words, just the kind of person needed for a legal strategy based on character assassination, or guilt by innuendo.
What is the most cost-effective way of finding reliability problems in software built from 10k+ lines of code? My money is on fuzz testing, a term that should send shivers down the spine of a defense team. Source code is not required, and the output is a list of real fault experiences. There are a few catches: 1) the software probably to be run in the cloud (perhaps the only cost/time effective way of running the many thousands of tests), and the defense is going to object over licensing issues (they don’t want the code fuzzed), 2) having lots of test harnesses interacting with a central database is likely to be problematic, 3) support for emulating embedded cpus, even commonly used ones like the Z80, is currently poor (this is a rapidly evolving area, so check current status).
Fuzzing can also be used to estimate the numbers of so-far undetected coding mistakes.
Reliability chapter added to “Empirical software engineering using R”
The Reliability chapter of my Empirical software engineering book has been added to the draft pdf (download here).
I have been working on this draft for four months and it still needs lots of work; time to move on and let it stew for a while. Part of the problem is lack of public data; cost and schedule overruns can be rather public (projects chapter), but reliability problems are easier to keep quiet.
Originally there was a chapter covering reliability and another one covering faults. As time passed, these merged into one. The material kept evaporating in front of my eyes (around a third of the initial draft, collected over the years, was deleted); I have already written about why most fault prediction research is a waste of time. If it had not been for Rome I would not have had much to write about.
Perhaps what will jump out at people most, is that I distinguish between mistakes in code and what I call a fault experience. A fault_experience=mistake_in_code + particular_input. Most fault researchers have been completely ignoring half of what goes into every fault experience, the input profile (if the user does not notice a fault, I do not consider it experienced) . It’s incredibly difficult to figure out anything about the input profile, so it has been quietly ignored (one of the reasons why research papers on reported faults are such a waste of time).
I’m also missing an ‘interesting’ figure on the opening page of the chapter. Suggestions welcome.
I have not said much about source code characteristics. There is a chapter covering source code, perhaps some of this material will migrate to reliability.
All sorts of interesting bits and pieces have been added to earlier chapters. Ecosystems keeps growing and in years to come somebody will write a multi-volume tomb on software ecosystems.
I have been promised all sorts of data. Hopefully some of it will arrive.
As always, if you know of any interesting software engineering data, please tell me.
Source code chapter next.
Top, must-read paper on software fault analysis
What is the top, must read, paper on software fault analysis?
Software Reliability: Repetitive Run Experimentation and Modeling by Phyllis Nagel and James Skrivan is my choice (it’s actually a report, rather than a paper). Not only is this report full of interesting ideas and data, but it has multiple replications. Replication of experiments in software engineering is very rare; this work was replicated by the original authors, plus Scholz, and then replicated by Janet Dunham and John Pierce, and then again by Dunham and Lauterbach!
I suspect that most readers have never heard of this work, or of Phyllis Nagel or James Skrivan (I hadn’t until I read the report). Being published is rarely enough for work to become well-known, the authors need to proactively advertise the work. Nagel, Dunham & co worked in industry and so did not have any students to promote their work and did not spend time on the academic seminar circuit. Given enough effort it’s possible for even minor work to become widely known.
The study run by Nagel and Skrivan first had three experienced developers independently implement the same specification. Each of these three implementations was then tested, multiple times. The iteration sequence was: 1) run program until fault experienced, 2) fix fault, 3) if less than five faults experienced, goto step (1). The measurements recorded were fault identity and the number of inputs processed before the fault was experienced.
This process was repeated 50 times, always starting with the original (uncorrected) implementation; the replications varied this, along with the number of inputs used.
For a fault to be experienced, there has to be a mistake in the code and the ‘right’ input values have to be processed.
How many input values need to be processed, on average, before a particular fault is experienced? Does the average number of inputs values needed for a fault experience vary between faults, and if so by how much?
The plot below (code+data) shows the numbers of inputs processed, by one of the implementations, before individual faults were experienced, over 50 runs (sorted by number of inputs):
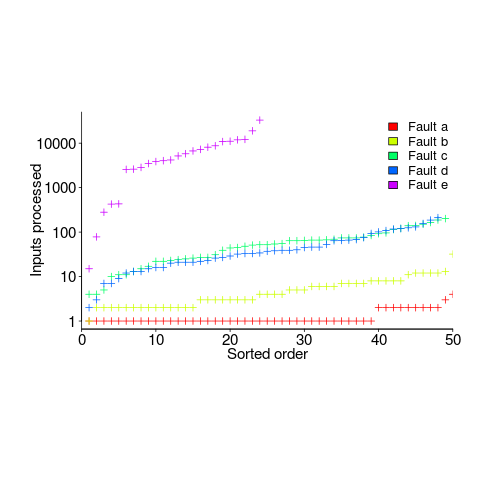
Different faults have different probabilities of being experienced, with fault a being experienced on almost any input and fault e occurring much less frequently (a pattern seen in the replications). There is an order of magnitude variation in the number of inputs processed before particular faults are experienced (this pattern is seen in the replications).
Faults were fixed as soon as they were experienced, so the technique for estimating the total number of distinct faults, discussed in a previous post, cannot be used.
A plot of number of faults found against number of inputs processed is another possibility. More on that another time.
Suggestions for top, must read, paper on software faults, welcome (be warned, I think that most published fault research is a waste of time).
Estimating the number of distinct faults in a program
In an earlier post I gave two reasons why most fault prediction research is a waste of time: 1) it ignores the usage (e.g., more heavily used software is likely to have more reported faults than rarely used software), and 2) the data in public bug repositories contains lots of noise (i.e., lots of cleaning needs to be done before any reliable analysis can done).
Around a year ago I found out about a third reason why most estimates of number of faults remaining are nonsense; not enough signal in the data. Date/time of first discovery of a distinct fault does not contain enough information to distinguish between possible exponential order models (technical details; practically all models are derived from the exponential family of probability distributions); controlling for usage and cleaning the data is not enough. Having spent a lot of time, over the years, collecting exactly this kind of information, I was very annoyed.
The information required, to have any chance of making a reliable prediction about the likely total number of distinct faults, is a count of all fault experiences, i.e., multiple instances of the same fault need to be recorded.
The correct techniques to use are based on work that dates back to Turing’s work breaking the Enigma codes; people have probably heard of Good-Turing smoothing, but the slightly later work of Good and Toulmin is applicable here. The person whose name appears on nearly all the major (and many minor) papers on population estimation theory (in ecology) is Anne Chao.
The Chao1 model (as it is generally known) is based on a count of the number of distinct faults that occur once and twice (the Chao2 model applies when presence/absence information is available from independent sites, e.g., individuals reporting problems during a code review). The estimated lower bound on the number of distinct items in a closed population is:

and its standard deviation is:
![S_{sd-est}={f_1}/{f_2}k sqrt{f_2(0.5/{k}+{f_1}/{f_2} [1+0.25 {f_1}/{f_2}])}](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_977.5_e69346120e72f31d04a47c9fcf64c4dd.png "S_{sd-est}={f_1}/{f_2}k sqrt{f_2(0.5/{k}+{f_1}/{f_2} [1+0.25 {f_1}/{f_2}])}")
where:  is the estimated number of distinct faults,
is the estimated number of distinct faults,  the observed number of distinct faults,
the observed number of distinct faults,  the total number of faults,
the total number of faults,  the number of distinct faults that occurred once,
the number of distinct faults that occurred once,  the number of distinct faults that occurred twice,
the number of distinct faults that occurred twice,  .
.
A later improved model, known as iChoa1, includes counts of distinct faults occurring three and four times.
Where can clean fault experience data, where the number of inputs have been controlled, be obtained? Fuzzing has become very popular during the last few years and many of the people doing this work have kept detailed data that is sometimes available for download (other times an email is required).
Kaminsky, Cecchetti and Eddington ran a very interesting fuzzing study, where they fuzzed three versions of Microsoft Office (plus various Open Source tools) and made their data available.
The faults of interest in this study were those that caused the program to crash. The plot below (code+data) shows the expected growth in the number of previously unseen faults in Microsoft Office 2003, 2007 and 2010, along with 95% confidence intervals; the x-axis is the number of faults experienced, the y-axis the number of distinct faults.
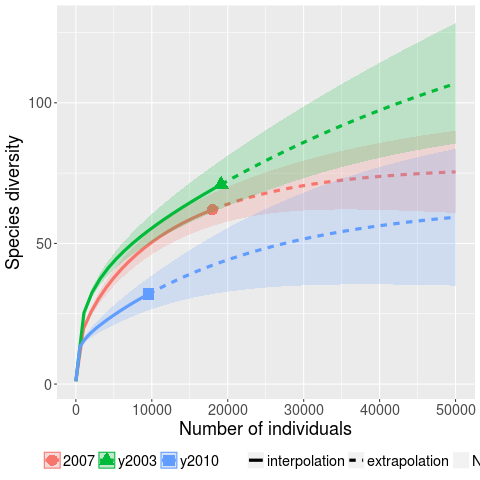
The take-away point: if you are analyzing reported faults, the information needed to build models is contained in the number of times each distinct fault occurred.
Mathematical proofs contain faults, just like software
The idea of proving programs correct, like mathematical proofs, is appealing, but is based on an incorrect assumption often made by non-mathematicians, e.g., mathematical proofs are fault free. In practice, mathematicians make mistakes and create proofs that contain serious errors; those of us who are taught mathematical techniques, but are not mathematicians, only get to see the good stuff that has been checked over many years.
An appreciation that published proofs contain mistakes is starting to grow, but Magnificent mistakes in mathematics is an odd choice for a book title on the topic. Quotes from De Millo’s article on “Social Processes and Proofs of Theorems and Programs” now appear regularly; On proof and progress in mathematics is worth a read.
Are there patterns to the faults that appear in claimed mathematical proofs?
- The difficulty of the problem is one obvious issue, as shown by the faulty proofs of the N vs. NP problem,
- the size of the proof, in number of pages, is a common problem, with Mochizuki’s ‘proof’ of the ABC conjecture being a recent example and the Hales-Ferguson proof of the Kepler conjecture has a whole book dedicated to trying to figure out if the proof is correct,
- number of people involved: some of the 100+ mathematicians responsible for proving components of the classification of finite simple groups died before the proof was claimed to be complete; the proofs of the various components created the largest known claimed proof, at tens of thousands of pages.
A surprisingly common approach, used by mathematicians to avoid faults in their proofs, is to state theorems without giving a formal proof (giving an informal one is given instead). There are plenty of mathematicians who don’t think proofs are a big part of mathematics (various papers from the linked-to book are available as pdfs).
Next time you encounter an advocate of proving programs correct using mathematics, ask them what they think about the uncertainty about claimed mathematical proofs and all the mistakes that have been found in published proofs.
Almost all published analysis of fault data is worthless
Faults are the subject of more published papers than any other subject in empirical software engineering. Unfortunately, over 98.5% of these fault related papers are at best worthless and at worst harmful, i.e., make recommendations whose impact may increase the number of faults.
The reason most fault papers are worthless is the data they use and the data they don’t to use.
The data used
Data on faults in programs used to be hard to obtain, a friend in a company that maintained a fault database was needed. Open source changed this. Now public fault tracking systems are available containing tens, or even hundreds, of thousands of reported faults. Anybody can report a fault, and unfortunately anybody does; there is a lot of noise mixed in with the signal. One study found 43% of reported faults were enhancement requests, the same underlying fault is reported multiple times (most eventually get marked as duplicate, at the cost of much wasted time) and …
Fault tracking systems don’t always contain all known faults. One study found that the really important faults are handled via email discussion lists, i.e., they are important enough to require involving people directly.
Other problems with fault data include: biased reported of problems, reported problem caused by a fault in a third-party library, and reported problem being intermittent or not reproducible.
Data cleaning is the essential first step that many of those who analyse fault data fail to perform.
The data not used
Users cause faults, i.e., if nobody ever used the software, no faults would be reported. This statement is as accurate as saying: “Source code causes faults”.
Reported faults are the result of software being used with a set of inputs that causes the execution of some sequence of tokens in the source code to have an effect that was not intended.
The number and kind of reported faults in a program depends on the variety of the input and the number of faults in the code.
Most fault related studies do not include any user related usage data in their analysis (the few that do really stand out from the crowd), which can lead to very wrong conclusions being drawn.
User usage data is very hard to obtain, but without it many kinds of evidence-based fault analysis are doomed to fail (giving completely misleading answers).
The shadow of the input distribution
Two things need to occur for a user to experience a fault in a program:
- a fault has to exist in the code,
- the user has to provide input that causes program execution to include the faulty code in a way that exhibits the incorrect behavior.
Data on the distribution of user input values is extremely rare, and we are left having to look for the shadows that the input distribution creates.
Csmith is a well-known tool for generating random C source code. I spotted an interesting plot in a compiler fuzzing paper and Yang Chen kindly sent me a copy of the data. In compiler fuzzing, source code is automatically generated and fed to the compiler, various techniques are used to figure out when the compiler gets things wrong.
The plot below is a count of the number of times each fault in gcc has been triggered (code+data). Multiple occurrences of the same fault are experienced because the necessary input values occur multiple times in the generated source code (usually in different files).
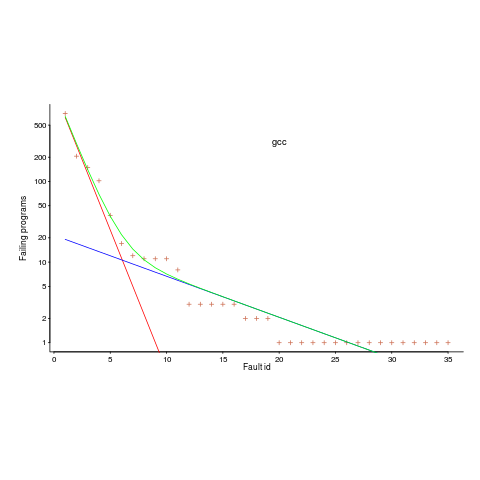
The green line is a fitted regression model, it’s a bi-exponential, i.e., the sum of two exponentials (the straight lines in red and blue).
The obvious explanation for this bi-exponential behavior (explanations invented after seeing the data can have the flavor of just-so stories, which is patently not true here 🙂 is that one exponential is driven by the presence of faults in the code and the other exponential is driven by the way in which Csmith meanders over the possible C source.
So, which exponential is generated by the faults and which by Csmith? I’m still trying to figure this out; suggestions welcome, along with alternative explanations.
Is the same pattern seen in duplicates of user reported faults? It does in the small amount of data I have; more data welcome.
Recent Comments