Archive
À la carte Entropy
My observation that academics treat Entropy as the go-to topic, when they have no idea what else to talk about, has ruffled a few feathers. David Clark, one of the organizers of a workshop on Information Theory and Software Testing has invited me to give a talk on Entropy (the title is currently Entropy for the uncertain, but this state might change :-).
Complaining about the many ways entropy is currently misused in software engineering would be like shooting fish in a barrel, and equally pointless. I want to encourage people to use entropy in a meaningful way, and to stop using Shannon entropy just because it is the premium brand of entropy.
Shannon’s derivation of the iconic formula  depends on various assumptions being true. While these conditions look like they might hold for some software engineering problems, they clearly don’t hold for others. It may be possible to use other forms of entropy for some of these other problems; Shannon became the premium brand of entropy because it was first to market, the other entropy products have not had anyone championing their use, and academics follow each other like sheep (it’s much easier to get a paper published by using the well-known brands).
depends on various assumptions being true. While these conditions look like they might hold for some software engineering problems, they clearly don’t hold for others. It may be possible to use other forms of entropy for some of these other problems; Shannon became the premium brand of entropy because it was first to market, the other entropy products have not had anyone championing their use, and academics follow each other like sheep (it’s much easier to get a paper published by using the well-known brands).
Shannon’s entropy has been generalized, with the two most well-known being (in the limit  , both converge to Shannon entropy):
, both converge to Shannon entropy):
Rényi entropy in 1961: ")
Tsallis entropy in 1988: ")
All of these formula reduce a list of probabilities to a single value. A weighting is applied to each probability, and this weighted value is summed to produce a single value that is further manipulated. The probability weighting functions are plotted below:
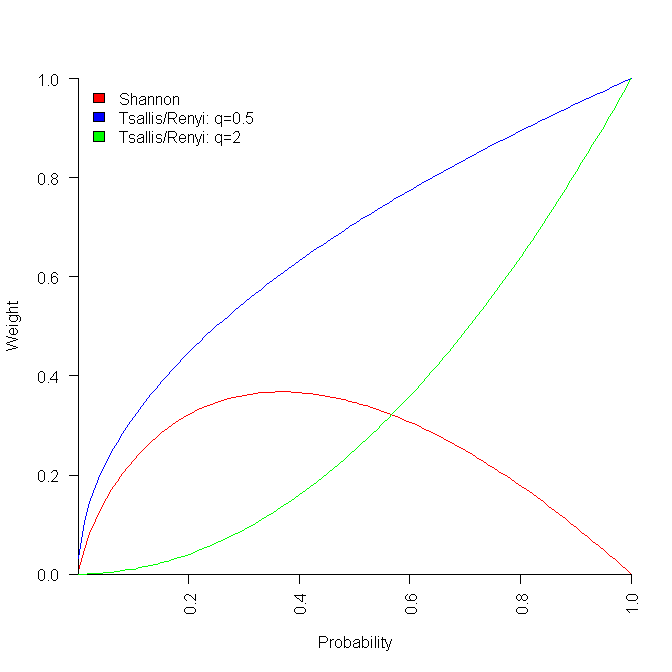
Under what conditions might one these two forms of entropy be used (there other forms)? I have been rummaging around looking for example uses, and could not find many.
There are some interesting papers about possible interpretations of the  parameter in Tsallis entropy: the most interesting paper I have found shows a connection with the correlation between states, e.g., preferential attachment in networks. This implies that Tsallis entropy is the natural first candidate to consider for systems exhibiting power law characteristics. Another paper suggests
parameter in Tsallis entropy: the most interesting paper I have found shows a connection with the correlation between states, e.g., preferential attachment in networks. This implies that Tsallis entropy is the natural first candidate to consider for systems exhibiting power law characteristics. Another paper suggests  derives from variation in the parameter of an exponential equation.
derives from variation in the parameter of an exponential equation.
Some computer applications: a discussion of Tsallis entropy and the concept of non-extensive entropy, along with an analysis of statistical properties of hard disc workloads, the same idea applied to computer memory.
Some PhD thesis: Rényi entropy, with  , for error propagation in software architectures, comparing various measures of entropy as a metric for the similarity of program execution traces, plus using Rényi entropy in cryptography
, for error propagation in software architectures, comparing various measures of entropy as a metric for the similarity of program execution traces, plus using Rényi entropy in cryptography
As you can see, I don’t have much to talk about. I’m hoping my knowledgeable readers can point me at some uses of entropy in software engineering where the author has put some thought into which entropy to use (which may have resulted in Shannon entropy being chosen; I’m only against this choice when it is made for brand name reasons).
Registration for the workshop is open, so turn up and cheer me on.
Roll your own weighting plot:
p_vals=seq(0.001, 1.001, by=0.01) plot(p_vals, -p_vals*log(p_vals), type="l", col="red", ylim=c(0, 1), xaxs="i", yaxs="i", xlab="Probability", ylab="Weight") q=0.5 lines(p_vals, p_vals^q, type="l", col="blue") q=2 lines(p_vals, p_vals^q, type="l", col="green") |
Entropy: Software researchers go to topic when they have no idea what else to talk about
If I’m reading a software engineering paper or blog and it starts discussing entropy my default behavior is to stop reading and move along. Entropy is what software researchers talk about when they cannot think of anything else to say about a topic.
The term entropy was first used in thermodynamics, around the mid-1800s, to define the relationship between the temperature of a body and its heat content. Once people found out that molecules could exist in different energy states within solids they realized that temperature was actually an average of the different energies of the molecules in a body and that heat content was the sum of the vibrational and kinetic energies of the molecules within a body. These insights enabled entropy to also be defined in terms of the number of states that the molecules within a body could exist in, and the probability of these states being occupied; statistical mechanics, a specialist field within thermodynamics, was born. Note, it is a common mistake to associate entropy with disorder (and lets bang that point home).
The problem with the term Entropy, outside of thermodynamics, is that people conflate, confuse and co-mingle various concepts associated with it. In fact this is one of the reasons Shannon chose to associate the word Entropy with his new theory of information, as he told it: Von Neumann told me, “You should call it entropy, for two reasons. In the first place your uncertainty function has been used in statistical mechanics under that name, so it already has a name. In the second place, and more important, nobody knows what entropy really is, so in a debate you will always have the advantage.”
While Shannon’s paper A Mathematical Theory of Communication is his most cited work, the second paper Prediction and Entropy of English has probably had a bigger impact in the world of techno-babble.
Shannon’s famous entropy formula is  , where there are
, where there are  possible events with
possible events with  the probability of event
the probability of event  occurring and
occurring and  some constant. The derivation and use of this formula depends on various assumptions being true, perhaps the most important being that successive symbols are independent; if the next symbol depends on what went before it the formula is more complicated and we are now dealing with conditional entropy.
some constant. The derivation and use of this formula depends on various assumptions being true, perhaps the most important being that successive symbols are independent; if the next symbol depends on what went before it the formula is more complicated and we are now dealing with conditional entropy.
Source code, to quiet a good approximation, consists of a sequence of symbols that alternate between symbols selected from two separate alphabets, the alphabet of punctuators/operators and the alphabet of ‘words’. The following shows the source of a program separated into these two sets of symbols.

Source code, created as it is from an alternating sequence of two different symbol sets, has none of the characteristics assumed in Shannon’s formula derivation or by Maxwell & Boltzmann in their statistical mechanics derivation. Now source code might be usefully analysed using n-grams, but unless we let the  go to infinity
go to infinity  does not get a look-in.
does not get a look-in.
Lets drive another nail into this source code entropy nonsense.
Entropy techno-babble and the second law of thermodynamics are frequent bedfellows. This law specifies that the entropy of a closed system never decreases, it either stays the same or increases. Now very many source code attributes have been found to be proportional to the log of the amount of code (as measured in lines); this is potentially a big problem for those wanting to calculate the entropy of source (it is a repeat of the Gibbs paradox).
If a function (which is claimed to have entropy  ) is split in half to create two functions, the second law of thermodynamics requires that the sum of the entropies of the two new functions should be at least . Entropy cannot scale logarithmically because splitting a function in two would reduce total entropy (i.e.,
) is split in half to create two functions, the second law of thermodynamics requires that the sum of the entropies of the two new functions should be at least . Entropy cannot scale logarithmically because splitting a function in two would reduce total entropy (i.e.,  , when
, when  ). So source code entropy has to be an attributes that does not scale logarithmically, which goes against most of what is known about source.
). So source code entropy has to be an attributes that does not scale logarithmically, which goes against most of what is known about source.
If source code does not follow Maxwell–Boltzmann statistics (the equations obtained by working through the ideas behind statistical mechanics), what kind of statistics might it follow? Strange as it might sound, quantum mechanics offers some pointers. Fermi–Dirac and Bose–Einstein statistics are the result of working through the mathematics of small numbers of particles having particular attributes; most functions are small and far removed from the large number of items assumed in the derivation of Maxwell–Boltzmann statistics.
I appreciate that by pointing out the parallel with quantum mechanics I am running the risk of entanglement replacing entropy as the go to topic for researchers scraping the barrel for something to talk about. But at least the mathematics of small numbers of items obeying certain rules is a model that is closer to source code.
Recent Comments