Archive
Producing software for money and/or recognition
In the commercial environment money makes the world go around, while in academia recognition (e.g., number of times your work is cited, being fawned over at conferences, impressive job titles) is the coin of the realm (there are a few odd balls who do it out of love for the subject or a desire to understand how things work, but modern academia is a large bureaucracy whose primary carrot is recognition).
There is an incentive problem for those writing software in academia; software does not attract much, if any, recognition.
Does the lack of recognition for writing software matter? Surely what counts are the research results, not the tools used to get there (be they writing software or doing mathematics).
A recent paper bemoans the lack of recognition for the development of Python packages for Astronomy researchers. Well, its too late now, they have written the software and everybody gets to make perfect copies for free.
What the authors of Astropy want, is for researchers who use this software to include a citation to it in any published papers. Do all 162 authors deserve equal credit? If a couple of people add a new package, should they get a separate citation? What if a new group of people take over maintenance, when should the citation switch over from the old authors/maintainers to the new ones? These are a couple of the thorny questions that need to be answered.
R is perhaps the most widely used academic developed software ecosystem. A small dedicated group of people has invested a lot of their time over many years to make something special. A lot more people have invested effort to create a wide variety of add-on packages.
The base R library includes the citation function, which returns the BibTeX information for a given package; ready to be added to a research papers work flow.
Both commercial and academic producers need to periodically create new versions to keep ahead of the competition, attract more customers and obtain income. While they both produce software to obtain ‘income’, commercial and academic software systems have different incentives when it comes to support for end users of the software.
Keeping existing customers happy is the way to get them to pay for upgrades and this means maintaining compatibility with what went before. Managers in commercial companies make sure that developers don’t break backwards compatibility (developers hate having to code around what went before and would love to throw it all away).
In the academic world it does not matter whether end users upgrade, as long as they cite the package, the version used is irrelevant; so there is a lot less pressure to keep backwards compatibility. Academics are supposed to create new stuff, they are researchers after all, so the incentives are pushing them to create brand new packages/systems to be seen as doing new stuff (and obtain a whole new round of citations). A good example is Hadley Wickham, who has created some great R packages, who seems to be continually moving on, e.g., reshape -> reshape2 -> tidyr (which is what any good academic is supposed to do).
The run-time performance of a system is something end users always complain about, but often get used to. The reason is invariably that there is little or no incentive to address this issue (for both commercial and academic systems). Microsoft Windows is slower than it need be and the R interpreter could go a lot faster (the design of the interpreter looks like something out of the 1980s; I’m seeing a lot of packages in R only, so the idea that R programs spend all their time executing in C/Fortran libraries may be out of date. Where is the incentive to use post-2000 designs?)
How many new versions of a software package can be produced before enough people stop being willing to pay for an update? How many different packages solving roughly the same problem can academics produce?
I don’t think producing new packages for income has a long term future.
Amount of end-user usage of code in Firefox
How much end-user usage does the code in Firefox receive over time?
Short answer: The available data is very sparse and lots of hand waving is needed to concoct something.
The longer answer is below as another draft section from my book Empirical software engineering with R. As always comments and pointers to more data welcome. R code and data here.
Suggestions for alternative methods of calculation also welcome.
Amount of end-user usage of code in Firefox
Source code that is never executed will not have any faults reported against it while code that is very frequently executed is more likely to have a fault reported against it than less frequently executed code.
The Firefox browser has been the subject of several fault related studies. The study by Massacci, Neuhaus and Nguyen <book Massacci_11> is of interest here because it provides the information needed to attempt to build a fault model that takes account of the total amount of usage that code experiences from all end-users of a program. The data used by the study applies to 899 Mozilla Firefox-related Security Advisories (MFSA, a particular kind of fault), noting the earliest and latest versions of Firefox that exhibits each fault; six major releases (i.e., versions 1.0, 1.5, 2.0, 3.0, 3.5 and 3.6) were analysed; the amount of code in each version that originated in earlier versions was measured (see plot below).
Massacci et al make their raw data available under an agreement that does not permit your author to directly distribute it to readers <book ???>; the raw data for the following analysis was reverse engineered from the Massacci et al paper <book Massacci_11> or obtained from other sources.
The following analysis is an attempt to build a model of amount of Firefox code usage, by end-users, over time, i.e., number of lines of Firefox source code being executed per unit time summed over all end-users at a given moment in time. The intent is to couple this model with fault data, looking for a relationship of the form: an X% change in usage results in a Y% change in reported faults.
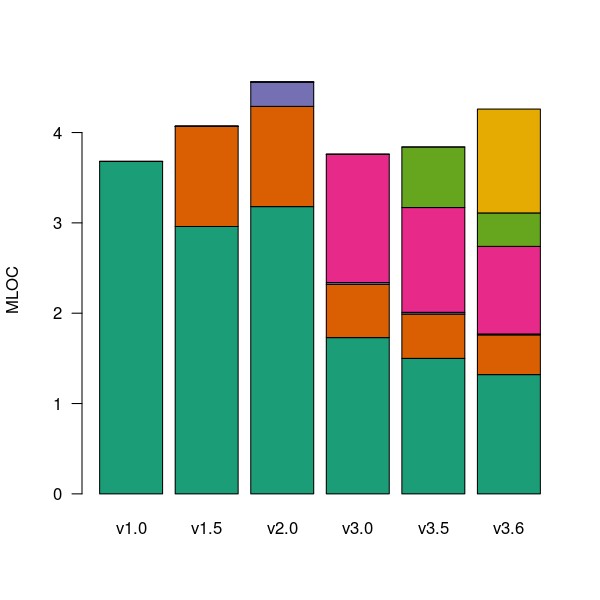
Figure 1. Amount of source (millions of lines) in each version broken down by the version in which it first appears. Data from Massacci, Neuhaus and Nguyen <book Massacci_11>.
As expected a large amount of code from previous versions appears in later versions.
Since we are interested in the relationship between end-user code usage and faults (MFSAs in this case) we are only interested in versions of Firefox that are actively maintained by Mozilla. Every version has a first official release date and an end-of-support date beyond which no faults reported against it are fixed; any usage of a version after the end-of-support date is not of interest in this analysis.
How many people are using each version of Firefox at any time?
A number of web sites list information on Firefox market share over time (as a percentage of all browsers measured), but only two known to your author break this information down by Firefox version. Massacci et al used url[netmarketshare.com] for Firefox version market share (data going back to November 2007), but your author found it easier to obtain information from url[www.w3schools.com] (data going back to May 2007). The W3schools data is obtained from the log of visitors to their site which will obviously be subject to fluctuations (of unknown magnitude).
For the period November 2004 to April 2007 the market share of each Firefox version was estimated as follows:
- total Firefox market share was based on that listed by url[marketshare.hitslink.com]
- during the period when only version 1.0 was available its market share was assumed to be the total Firefox market share,
- the market share for versions 1.5 and 2.0 was assumed to follow the trend of growth and decline seen in later releases for which data is available. Numbers were concocted that followed the version trend and summed to the known total market share.
The plot below shows the market share of the six versions of Firefox between official release and end-of-support. Estimated values appear to the left of the vertical red line, values from measurements to the right. It can be seen that at its end-of-support date version 2.0 still had a significant market share.
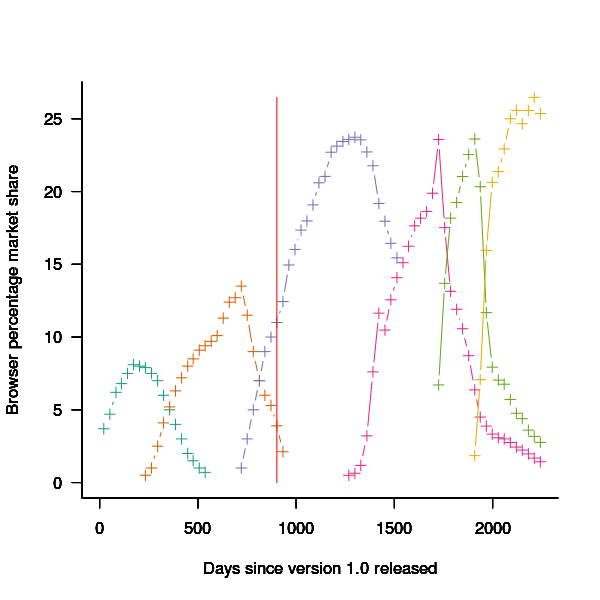
Figure 2. Market share of Firefox versions between official release and end-of-support. Data from url[www.w3schools.com].
The International Telecommunications Union publishers an estimate of the number of people per 100 head of population with Internet access for each year between 2003 and 2011 <book ITU_12>; the data is broken down by developed/developing countries and also by major world regions. Assuming that everybody who users the Internet uses a browser this information can be combined with market share and human population data to estimate the number of Firefox users.
The ITU do not provide much information about how the usage figure is calculated or even which month of the year it applies to (since we are interested in change over time knowing the month is not important and the start of the year is assumed). As the figure below shows the estimate over the period of interest can be accurately modeled by a straight line. A linear model was fitted to the data to predict usage between published estimates; over the period of interest the rate of growth in the Developed world has been almost twice as great as the rate in the whole world.
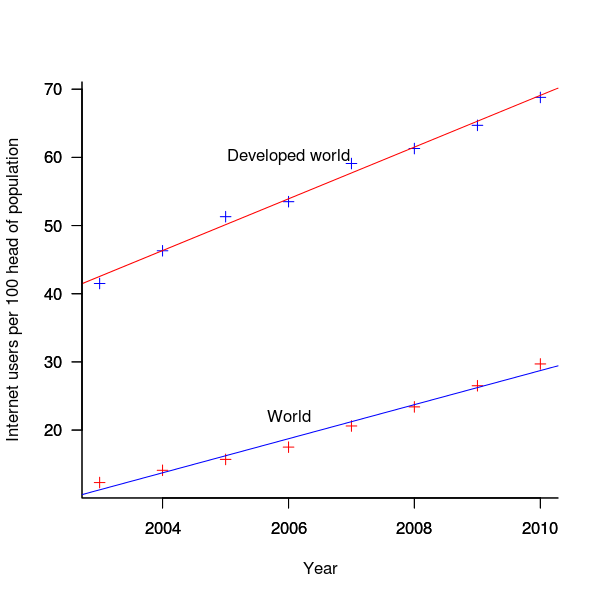
Figure 3. Number of people with Internet access per 100 head of population in the developed world and the whole world. Data from ITU <book <ITU_12>.
We are interested in relative change in total user population and this can be obtained by multiplying the per-head of population value by the change in population (a 0.8% yearly growth is assumed for the developed world).
Possible significant factors for why the formula  might not accurately reflect the probability of a MFSA being reported include:
might not accurately reflect the probability of a MFSA being reported include:
- the characteristics of people who started using the Internet in 2004 may be different from those who first started in 2010:
- there will be variation in the amount of time people spend browsing, does the distribution of time usage differ between early and late adopters?
- some people are more likely than others to report a fault (e.g., my mum is a late adopter and extremely unlikely to report a fault whereas I might report a fault),
- there may be significant regional differences, e.g., European users vs. Chinese users. These differences include the Internet sites visited (the behavior of Firefox will depend on the content of the web page visited) and may affect their propensity to report a problem (e.g., do the cultural stereotypes of Chinese acceptance of authority mean they are unlikely to report a fault while those noisy Americans complain about everything?)
The end-user usage for code originally written for a particular version, at a point in time, is calculated as follows:
- number of lines of code originally written for a particular version that is contained within the code used to build a later version, or that particular version; call this the build version,
- times the market share of the build version,
- times the number of Internet users of the build version (users in the Developed world was used).
The plot below is an example using the source code originally written for Firefox version 1.0. The green points are the code usage for version 1.0 code executing in Firefox build version 1.0, the orange points the code usage for version 1.0 code executing in build version 1.5 and so on to the yellow points which is the code usage for version 1.0 code executing in build version 3.6. The black points are the sum over all build versions.
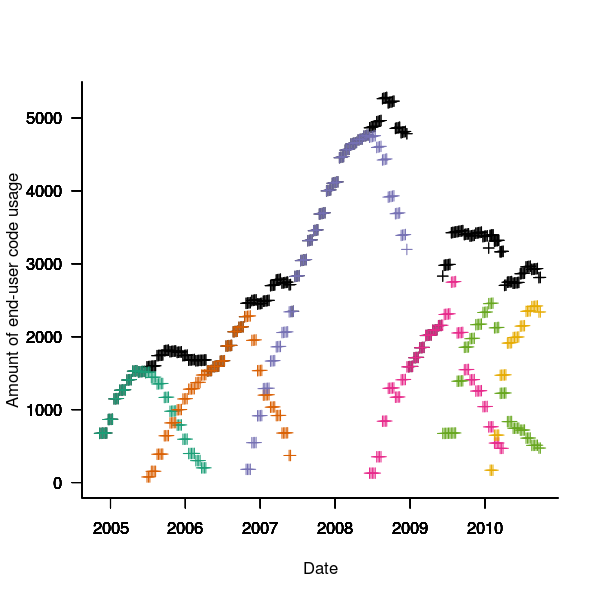
Figure 4. Amount of end-user usage of code originally written for Firefox version 1.0 by various other versions.
Much of the overall growth comes from growth in Internet usage, and in the early years there is also substantial growth in browser market share.
An analysis that attempts to connect Firefox usage with reported MFSAs will appear shortly (it would be surprising if fault report rate scaled linearly with end-user usage).
Recent Comments