Archive
Distribution of small project completion times
Records of project estimates and actual task times show that round numbers are very common. Various possible reasons have been suggested for why actual times are often reported as a round number. This post analyses the impact of round number reports of actual times on the accuracy of estimates.
The plot below shows the number of tasks having a given reported completion time for 1,525 tasks estimated to take 1-hour (code+data):
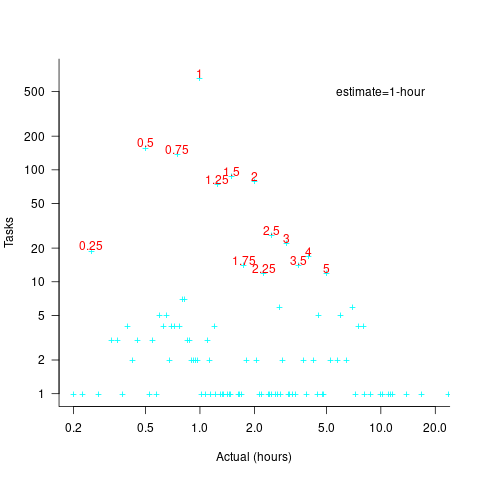
Of those 1,525 tasks estimated to take 1-hour, 44% had a reported completion time of 1-hour, 26% took less than 1-hour and 30% took more than 1-hour. The mean is 1.6 hours and the standard deviation 7.1. The spikiness of the distribution of actual times rules out analytical statistical analysis of the distribution.
If a large task is broken down into, say,  smaller tasks, all estimated to take the same amount of time
smaller tasks, all estimated to take the same amount of time  , what is the distribution of actual times for the large task?
, what is the distribution of actual times for the large task?
In the case of just two possible actual times to complete each smaller task, some percentage,  , of tasks are completed in actual time
, of tasks are completed in actual time  , and some percentage,
, and some percentage,  , completed in actual time
, completed in actual time  (with
(with  ). The probability distribution of the large task time,
). The probability distribution of the large task time, ") , for the two actual times case is:
, for the two actual times case is:
=(matrix{2}{1}{N k})(1-p_{t1})^k {p_{t1}}^{N-k}=(matrix{2}{1}{N k}){p_{t2}}^k (1-p_{t2})^{N-k}")
where:  , and
, and  .
.
The right-most equation is the probability distribution of the Binomial distribution, ") . The possible completion times for the large task start at
. The possible completion times for the large task start at  , followed by time increments of .
, followed by time increments of .
When there are three possible actual completion times for each smaller task, the calculation is complicated, and become more complicated with each new possible completion time.
A practical approach is to use Monte Carlo simulation. This involves simulating lots of large tasks containing smaller tasks. A sample of tasks is randomly drawn from the known 1,525 task actual times, and these actual times added to give one possible completion time. Running this process, say, 10,000 times produces what is known as the empirical distribution for the large task completion time.
The plot below shows the empirical distribution  smaller 1-hour tasks. The blue/green points show two peaks, the higher peak is a consequence of the use of round numbers, and the lower peak a consequence of the many non-round numbers. If the total times are rounded to 15 minute times, red points, a smoother distribution with a single peak emerges (code+data):
smaller 1-hour tasks. The blue/green points show two peaks, the higher peak is a consequence of the use of round numbers, and the lower peak a consequence of the many non-round numbers. If the total times are rounded to 15 minute times, red points, a smoother distribution with a single peak emerges (code+data):

When a large task involves smaller tasks estimated to take a variety of times, the empirical distribution of the actual time for each estimated time can be combined to give an empirical distribution of the large task (see sum_prob_distrib).
Provided enough information on task completion times is available, this technique works does what it says on the tin.
An evidence-based software engineering book from 2002
I recently discovered the book A Handbook of Software and Systems Engineering: Empirical Observations, Laws and Theories by Albert Endres and Dieter Rombach, completed in 2002.
The preface says: “This book is about the empirical aspects of computing. … we intend to look for rules and laws, and their underlying theories.” While this sounds a lot like my Evidence-based Software Engineering book, the authors take a very different approach.
The bulk of the material consists of a detailed discussion of 50 ‘laws’, 25 hypotheses and 12 conjectures based on the template: 1) a highlighted sentence making some claim, 2) Applicability, i.e., situations/context where the claim is likely to apply, 3) Evidence, i.e., citations and brief summary of studies.
As researchers of many years standing, I think the authors wanted to present a case that useful things had been discovered, even though the data available to them is nowhere near good enough to be considered convincing evidence for any of the laws/hypotheses/conjectures covered. The reasons I think this book is worth looking at are not those intended by the authors; my reasons include:
- the contents mirror the unquestioning mindset that many commercial developers have for claims derived from the results of software research experiments, or at least the developers I talk to about software research. I’m forever educating developers about the need for replications (the authors give a two paragraph discussion of the importance of replication), that sample size is crucial, and using professional developers as subjects.
Having spent twelve chapters writing authoritatively on 50 ‘laws’, 25 hypotheses and 12 conjectures, the authors conclude by washing their hands: “The laws in our set should not be seen as dogmas: they are not authoritatively asserted opinions. If proved wrong by objective and repeatable observations, they should be reformulated or forgotten.”
For historians of computing this book is a great source for the software folklore of the late 20th/early 21st century,
- the Evidence sections for each of the laws/hypotheses/conjectures is often unintentionally damming in its summary descriptions of short/small experiments involving a handful of people or a few hundred lines of code. For many, I would expect the reaction to be: “Is that it?”
Previously, in developer/researcher discussions, if a ‘fact’ based on the findings of long ago software research is quoted, I usually explain that it is evidence-free folklore; followed by citing The Leprechauns of Software Engineering as my evidence. This book gives me another option, and one with greater coverage of software folklore,
- the quality of the references, which are often to the original sources. Researchers tend to read the more recently published papers, and these are the ones they often cite. Finding the original work behind some empirical claim requires following the trail of citations back in time, which can be very time-consuming.
Endres worked for IBM from 1957 to 1992, and was involved in software research; he had direct contact with the primary sources for the software ‘laws’ and theories in circulation today. Romback worked for NASA in the 1980s and founded the Fraunhofer Institute for Experimental Software Engineering.
The authors cannot be criticized for the miniscule amount of data they reference, and not citing less well known papers. There was probably an order of magnitude less data available to them in 2002, than there is available today. Also, search engines were only just becoming available, and the amount of material available online was very limited in the first few years of 2000.
I started writing a book in 2000, and experienced the amazing growth in the ability of search engines to locate research papers (first using AltaVista and then Google), along with locating specialist books with Amazon and AbeBooks. I continued to use university libraries for papers, which I did not use for the evidence-based book (not that this was a viable option).
Evidence-based SE groups doing interesting work, 2021 version
Who are the research groups currently doing interesting work in evidenced-base software engineering (academics often use the term empirical software engineering)? Interestingness is very subjective, in my case it is based on whether I think the work looks like it might contribute something towards software engineering practices (rather than measuring something to get a paper published or fulfil a requirement for an MSc or PhD). I last addressed this question in 2013, and things have changed a lot since then.
This post focuses on groups (i.e., multiple active researchers), and by “currently doing” I’m looking for multiple papers published per year in the last few years.
As regular readers will know, I think that clueless button pushing (a.k.a. machine learning) in software engineering is mostly fake research. I tend to ignore groups that are heavily clueless button pushing oriented.
Like software development groups, research groups come and go, with a few persisting for many years. People change jobs, move into management, start companies based on their research, new productive people appear, and there is the perennial issue of funding. A year from now, any of the following groups may be disbanded or moved on to other research areas.
Some researchers leave a group to set up their own group (even moving continents), and I know that many people in the 2013 survey have done this (many in the Microsoft group listed in 2013 are now scattered across the country). Most academic research is done by students studying for a PhD, and the money needed to pay for these students comes from research grants. Some researchers are willing to spend their time applying for grants to build a group (on average, around 40% of a group’s lead researcher’s time is spent applying for grants), while others are happy to operate on a smaller scale.
Evidence-based research has become mainstream in software engineering, but this is not to say that the findings or data have any use outside of getting a paper published. A popular tactic employed by PhD students appears to be to look for what they consider to be an interesting pattern in code appearing on Github, and write a thesis that associated this pattern with an issue thought to be of general interest, e.g., predicting estimates/faults/maintainability/etc. Every now and again, a gold nugget turns up in the stream of fake research.
Data is being made available via personal Github pages, figshare, osf, Zenondo, and project or personal University (generally not a good idea, because the pages often go away when the researcher leaves). There is no current systematic attempt to catalogue the data.
There has been a huge increase in papers coming out of Brazil, and Brazilians working in research groups around the world, since 2013. No major Brazilian name springs to mind, but that may be because I have not noticed that they are Brazilian (every major research group seems to have one, and many of the minor ones as well). I may have failed to list a group because their group page is years out of date, which may be COVID related, bureaucracy, or they are no longer active.
The China list is incomplete. There are Chinese research groups whose group page is hosted on Github, and I have failed to remember that they are based in China. Also, Chinese pages can appear inactive for a year or two, and then suddenly be updated with lots of recent information. I have not attempted to keep track of Chinese research groups.
Organized by country, groups include (when there is no group page available, I have used the principle’s page, and when that is not available I have used a group member page; some groups make no attempt to help others find out about their work):
Belgium (I cite the researchers with links to pdfs)
Brazil (Garcia, Steinmacher)
Canada (Antoniol, Data-driven Analysis of Software Lab, Godfrey and Ptidel, Robillard, SAIL; three were listed in 2013)
China (Lin Chen, Lu Zhang, Minghui Zhou)
Germany (Chair of Software Engineering, CSE working group, Software Engineering for Distributed Systems Group, Research group Zeller)
Greece (listed in 2013)
Italy (listed in 2013)
Japan (Inoue lab, Kamei Web, Kula, and Kusumoto lab)
Spain (the only member of the group listed in 2013 with a usable web page)
Sweden (Chalmers, KTH {Baudry and Monperrus, with no group page})
Switzerland (SCG and REVEAL; both listed in 2013)
USA (Devanbu, Foster, Maletic, Microsoft, PLUM lab, SEMERU, squaresLab, Weimer; two were listed in 2013)
Sitting here typing away, I have probably missed out some obvious candidates (particularly in the US). Suggestions for omissions welcome (remember, this is about groups, not individuals).
GDPR has a huge impact on empirical software engineering research
The EU’s General Data Protection Regulation (GDPR) is going to have a huge impact on empirical software engineering research. After 25 May 2018, analyzing source code will never be the same again.
I am not a lawyer and nothing qualifies me to talk about the GDPR.
People put their name in source code, bug tracking databases and discussion forums; this is personal identifying information.
Researchers use personal names to obtain information about a wide variety of activities, e.g., how much code did individuals write, how many bug reports did they process, contributions in discussions of one sort or another.
Open source licenses give others all kinds of rights (e.g., ability to use and modify source code), but they do not contain any provisions for processing personal data.
Adding a “I hereby give permission for anybody to process information about my name in any way they see fit.” clause to licenses is not going to help.
The GDPR requires (article 5: Principles relating to processing of personal data):
“Personal data shall be: … collected for specified, explicit and legitimate purposes and not further processed in a manner that is incompatible with those purposes;”
That is, personal data can only be processed for the specific reason it was collected, i.e., if you come up with another bright idea for analysis of data that has just been collected, it may be necessary to obtain consent, from those whose personal data it is, before trying out the bright idea.
It is not possible to obtain blanket permission (article 6, Lawfulness of processing):
“…the data subject has given consent to the processing of his or her personal data for one or more specific purposes;”, i.e., consent has to be obtained from the data subject for each specific purpose.
Github’s Global Privacy Practices shows that Github are intent on meeting the GDPR requirements, they include: “GitHub provides clear methods of unambiguous, informed consent at the time of data collection, when we do collect your personal data.”. Processing personal information, about an EU citizen, contained in source code appears to be a violation of Github’s terms of service.
The GDPR has many other requirements, e.g., right to obtain information on what information is held and right to be forgotten. But, the upfront killer is not being able to cheaply collect lots of code and then use personal information to help with the analysis.
There are exceptions for: Processing for archiving, scientific or historical research or statistical purposes. Can somebody who blogs and is writing a book claim to be doing scientific research? People who know more about these exceptions than me, tell me that there could be a fair amount of paperwork involved when making use of the exception, i.e., being able to show that privacy safeguards are in place.
Then, there is the issue of what constitutes personal information. Git’s hashing algorithm makes use of the committer’s name and/or email address. Is a git hash personal identifying information?
A good introduction to the GDPR for developers, and one for researchers.
Almost all published analysis of fault data is worthless
Faults are the subject of more published papers than any other subject in empirical software engineering. Unfortunately, over 98.5% of these fault related papers are at best worthless and at worst harmful, i.e., make recommendations whose impact may increase the number of faults.
The reason most fault papers are worthless is the data they use and the data they don’t to use.
The data used
Data on faults in programs used to be hard to obtain, a friend in a company that maintained a fault database was needed. Open source changed this. Now public fault tracking systems are available containing tens, or even hundreds, of thousands of reported faults. Anybody can report a fault, and unfortunately anybody does; there is a lot of noise mixed in with the signal. One study found 43% of reported faults were enhancement requests, the same underlying fault is reported multiple times (most eventually get marked as duplicate, at the cost of much wasted time) and …
Fault tracking systems don’t always contain all known faults. One study found that the really important faults are handled via email discussion lists, i.e., they are important enough to require involving people directly.
Other problems with fault data include: biased reported of problems, reported problem caused by a fault in a third-party library, and reported problem being intermittent or not reproducible.
Data cleaning is the essential first step that many of those who analyse fault data fail to perform.
The data not used
Users cause faults, i.e., if nobody ever used the software, no faults would be reported. This statement is as accurate as saying: “Source code causes faults”.
Reported faults are the result of software being used with a set of inputs that causes the execution of some sequence of tokens in the source code to have an effect that was not intended.
The number and kind of reported faults in a program depends on the variety of the input and the number of faults in the code.
Most fault related studies do not include any user related usage data in their analysis (the few that do really stand out from the crowd), which can lead to very wrong conclusions being drawn.
User usage data is very hard to obtain, but without it many kinds of evidence-based fault analysis are doomed to fail (giving completely misleading answers).
What is empirical software engineering?
Writing a book about empirical software engineering requires making decisions about which subjects to discuss and what to say about them.
The obvious answer to “which subjects” is to include everything that practicing software engineers do, when working on software systems; there are some obvious exclusions like traveling to work. To answer the question of what software engineers do, I have relied on personal experience, my own and what others have told me. Not ideal, but it’s the only source of information available to me.
The foundation of an empirical book is data, and I only talk about subjects for which public data is available. The data requirement is what makes writing this book practical; there is not a lot of data out there. This lack of data has allowed me to avoid answering some tricky questions about whether something is, or is not, part of software engineering.
What approach should be taken to discussing the various subjects? Economics, as in cost/benefit analysis, is the obvious answer.
In my case, I am a developer and the target audience is developers, so the economic perspective is from the vendor side, not the customer side (e.g., maximizing profit, not minimizing cost or faults). Most other books have a customer oriented focus, e.g., high reliability is important (with barely a mention of the costs involved); this focus on a customer oriented approach comes from the early days of computing where the US Department of Defense funded a lot of software research driven by their needs as a customer.
Again the lack of data curtails any in depth analysis of the economic issues involved in software development. The data is like a patchwork of islands, the connections between them are under water and have to be guessed at.
Yes, I am writing a book on empirical software engineering that contains the sketchiest of outlines on what empirical software engineering is all about. But if the necessary data was available, I would not live long enough to get close to completing the book.
What of the academic take on empirical software engineering? Unfortunately the academic incentive structure strongly biases against doing work of interest to industry; some of the younger generation do address industry problems, but they eventually leave or get absorbed into the system. Academics who spend time talking to people in industry, to find out what problems exist, tend to get offered jobs in industry; university managers don’t like loosing their good people and are incentivized to discourage junior staff fraternizing with industry. Writing software is not a productive way of generating papers (academics are judged by the number and community assessed quality of papers they produce), so academics spend most of their work time babbling in front of spotty teenagers; the result is some strange ideas about what industry might find useful.
Academic software engineering exists in its own self-supporting bubble. The monkeys type enough papers that it is always possible to find some connection between an industry problem and published ‘research’.
I have been reading your interesting paper
In the last six years or so I have sent around 420 emails whose first line started: “I have been reading your interesting paper”, followed a few lines later by: “Would it be possible to obtain a copy of the data?”, and then some background and links to blog posts and my previous book.
The response break down is roughly as follows:
Received data 136 32% No reply 132 32% Pending (received a positive reply) 49 12% Confidential 42 10% No longer have the data 20 5% Best known address bounces 11 3% |
Thanks to those 136 researchers who took the time to collect together their data and send me a copy.
The “No reply” response get a second email 6-9 months after the first. I’m hoping that the availability of a draft of the book will generate some positive publicity that reminds researchers they have had an email from me and are missing out.
The “Confidential” case is relatively low because it is often obvious that the data is confidential and I don’t bother asking for a copy (I only use data that can be made public).
A common reason behind “No longer have the data” is a change of laptop and sometimes a change of jobs. If the paper is more than five years old, I tend not to ask unless the data looks very interesting. Mine and others’ experiences show that research data has a relatively short half-life.
I try quite hard to find a workable address, sometimes emailing supervisors and going via LinkedIn.
Empirical analysis of UK legislation started this weekend
Yesterday I was one of a dozen or so people at a hackathon hosted by the Ministry of Justice. I’m sure that the organizers would have liked a lot more people attending, but the McDonald’s hackathon across town was a bigger draw for most of the hackers I know.
The dataset was all UK legislation back to 1988, and a less complete set going back to 1267, in html and various flavors of xml; in all 20G of compressed files, with the compressed html files occupying 7G on my machine. As of this weekend the files are available online.
There were about half a dozen domain experts, in various aspects of the creation of UK legislation, present and they suggested lots of interesting questions that we (i.e., the attendees who could code) might like to try to answer.
I was surprised at the simplicity of some questions, e.g., volume (e.g., word count) of legislation over time and branch of government. The reason these question had not been answered before is that the data had not been available; empirical analysis of UK legislation started this weekend.
The most interesting question I heard involved the relative volume of primary and secondary legislation. Primary legislation is written by Parliament and in some cases creates a framework that is used by secondary legislation which contains the actual details. A lot of this secondary legislation is written by the Executive branch of government (by civil servants in the appropriate branch of government) and may not involve any parliamentary oversight. Comparing the relative volume of primary/secondary legislation over time would show if the Executive branch was gaining more powers to write laws, at the expense of Parliament.
With all the interesting discussions going on, setting ourselves up and copying the data (from memory sticks, not the internet), coding did not really start until 11, and we had to have our projects ‘handed-in’ by 16:00, not enough time to be sure of getting even an approximate answer to the primary/secondary legislation question. So I plumped for solving a simpler problem that I was confident of completing.
Certain phrases are known to be frequently used in legislation, e.g., “for the purposes of”. What phrases are actually very common in practice? The domain experts were interested in phrases by branch of government and other subsets; I decided to keep it simple by processing every file and giving them the data.
Counting sequences of n words is a very well studied problem and it was straightforward to locate a program to do it for me. I used the Lynx web browser to strip out the html (the importance of making raw text available for this kind of analysis work was recognized and this will be available at some future date). I decided that counting all four word sequences ought to be doable on my laptop and did manage to get it all to work in the available time. Code and list of 4-grams over the whole corpus available on Github.
As always, as soon as they saw the results, the domain experts immediately starting asking new questions.
Regular readers of this blog will know of my long standing involvement in the structure and interpretation of programming language standards. It was interesting to hear those involved in the writing/interpretation of legislation having exactly the same issues, and coming up with very similar solutions, as those of us in the language standards world. I was surprised to hear that UK legislation has switched from using “shall” to using “must” to express requirements (one of the hacks plotted the use of shall/must over time and there has been an abrupt change of usage). One of the reasons given was that “must” is more modern; no idea how word modernness was measured. In the ISO standards’ world “shall” is mandated over “must”. Everybody was very busy in the short amount of time available, so I had to leave an insiders chat about shall/must to another time.
The availability of such a large amount of structured English documents having great import should result in some interesting findings and tools being produced.
Evidence for the benefits of strong typing, where is it?
It is often claimed that writing software using a strongly typed programming language bestows worthwhile benefits. Those making the claims can sometimes be rather vague about exactly what the benefits are, while at other times appear willing to claim almost any benefit. What does the empirical evidence have to say (let’s ignore the what languages are strongly typed elephant in the room)?
Until recently there had been two empirical studies (plus a couple of language comparison experiments; one of the better ones involves the researcher timing himself implementing various algorithms in various languages; Zislis “An Experiment in Algorithm Implementation”), while in the last few years a group has been experimenting away in Germany (three’ish published data sets).
Measuring changes in developer performance caused by the use of different programming languages is very hard, some of the problems include:
- every person is different: a way needs to be found to take account of differences in subject ability/knowledge/characteristics,
- every problem is different: it may be easier to write a program to solve a problem using language X than using language Y,
- it is difficult to obtain experimental subjects.
The experimental procedure adopted by all the experiments discussed here is to:
- select two different languages or the same language modified to not support some type constructs,
- get students (mostly upper-undergraduates+graduates) to volunteer as experimental subjects,
- have each subject use one language to solve a problem and then use the other language to solve the same problem. Each subject is randomly assigned to a group using a given language order (the experiments start out with an equal number of subjects in each group, but not all subjects complete every problem),
- in some cases the previous step is repeated for new problems.
Having subjects solve the same problem twice creates the opportunity for learning to occur during the implementation of the first program and for this learning to improve performance during the second implementation. The experimental procedures employed generate information that can be used during the analysis of the data (in my case using a mixed-model in R; download code and all data) to factor this ordering effect into the created model.
So what are the results? In chronological order we have (if you know of anymore published work please tell me):
- Gannon “An Experimental Evaluation of Data Type Conversions”: Implemented compilers for two simple languages (think BCPL and BCPL+a string type and simple structures; by today’s standards one language is not quiet as weakly typed as the other). One problem had to be solved and this was designed to require the use of features available in both languages, e.g., a string oriented problem (final programs were between 50-300 lines). The result data included number of errors during development and number of runs needed to create a working program (this all happened in 1977, well before the era of personal computers, when batch processing was king).
There was a small language difference in number of errors/batch submissions; the difference was about half the size of that due to the order in which languages were used by subjects, both of which were small in comparison to the variation due to subject performance differences. While the language effect was small, it exists. To what extent Can the difference be said to be due to stronger typing rather than only one language having built in support for a string type? Who knows, no more experiments like this were performed for 20 years
- Prechelt & Tichy A Controlled Experiment to Assess the Benefits of Procedure Argument Type Checking: Used two C compilers, one K&R C (i.e., no argument checking of function calls) and the other ANSI C, with subjects solving one problem using both compilers; available output data was time taken by subjects to solve the problem.
Using the no argument checking compiler slowed implementation time by around 10%, about five times smaller than the variation in subject performance (there was an ordering effect of around 30%).
- Mayer, Kleinschmager & Hanenberg: Two experiments used different languages (Java and Groovy) and multiple problems; result data was time for subjects to complete the task (Do Static Type Systems Improve the Maintainability of Software Systems? An Empirical Study and An Empirical Study of the Influence of Static Type Systems on the Usability of Undocumented Software). No significant difference due to just language (surprisingly) but differences due to language order, but big differences due to language/problem interaction with some problems solved more quickly in Java and other more quickly in Groovy. Again large variation due to subject performance.
Another experiment used a single language (Java) and multiple problems involving making use of either Java’s generic types or non-generic types (“Do Developers Benefit from Generic Types?”). Again the only significant language difference effects occurred through interaction with other variables in the experiment (e.g., the problem or the language ordering) and again there were large variations in subject performance.
In summary, when a language typing/feature effect has been found its contribution to overall developer performance has been small.
I think some reasons that the effects of typing have been so small, or non-existent, include (I should declare my belief that strong typing is useful):
- the use of students as subjects. Most students have very little programming experience relative to professional developers (i.e., under 100 hours vs. thousands of hours). I can easily imagine many student subjects often finding the warnings produced by the type system more confusing than helpful. More experienced developers are in a position to make full use of what a type system offers, and researchers should try to use professional developers as subjects (it is not that hard to obtain such volunteers)
- the small size of the problems. Typing comes into its own when used to organize and control large amounts of code. I understand the constraints of running an experiment limit the amount of code involved.
Success: Software engineering data is starting to become very dull
A few years ago it was unusual for the author(s) of a paper in software engineering to make their data public (and on top of that it was rare to encounter a paper that actually made use of empirical data). The situation now is that I am having trouble keeping up with all the papers that include a link to downloadable data. Part of the problem is that I will pay a lot more attention to papers that come with data, having lived through a long famine I have not yet adjusted to the greater abundance. I’m sure that journal editors and referees are in the same boat and are being lured by accompanying data to accept paper for publication that they would otherwise have rejected.
This growing quantity of empirical software engineering data means we can now start thinking about what data is useful to have and what data is not so useful. Data is useful if it highlights a pattern of behavior that can be used to help reduce the resources needed to create/maintain software.
To get a handle on estimating data usefulness we need a model of research in software engineering. While many have used Physics as the model for software engineering research (i.e., a few simple universal laws that apply everywhere), I think Biology is a much better fit.
Software is written in different habitats environments (e.g., small teams, large teams) and targets different habitats environments (e.g., embedded, desktop, mobile, supercomputer) using different techniques and driven by different predators/prey market forces (e.g., release first/quickly, be reliable). Yes there are common drivers, just as the living things studied by biologists share a common need to eat, sleep and reproduce.
Like biology, the bulk of software engineering research is about the study of niche topics, with some small percentage of researchers trying to build theories that tie everything together at one level or another to create bigger pictures.
This model of software engineering research means estimating the usefulness of data probably requires some knowledge of the niche to which it applies. It also means that a particular data set might not be useful yet because it needs to be combined with other data, that does not yet exist (perhaps it was collected first because it was easier to do).
So in a space of a few years most software engineering data has gone from being very interesting (because it is rare) to being very dull (because it is harder to stand out in a crowd).
Recent Comments